import pandas as pd실습파일 pandas2의 국내 아이돌 평판지수 (csv)
DataFrame 로드
df = pd.read_csv('https://bit.ly/ds-korean-idol')df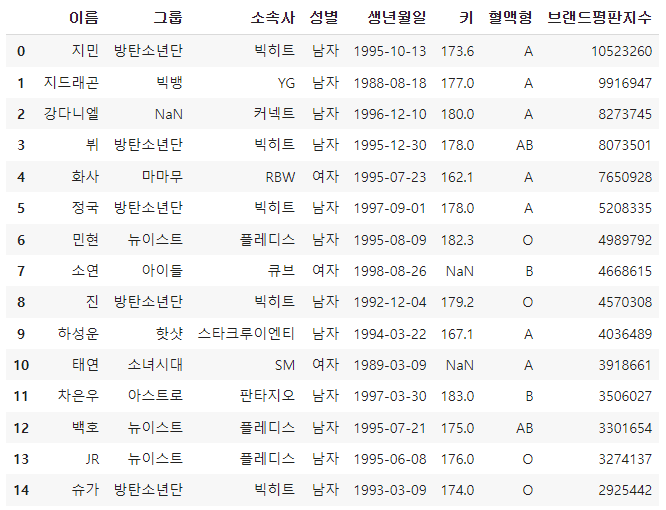
1. Column을 선택하는 방법
df.head()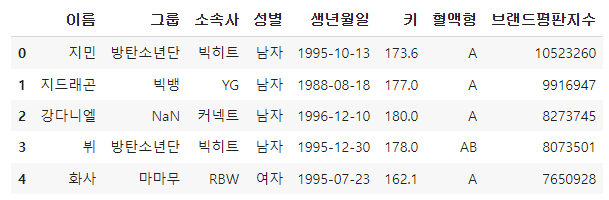
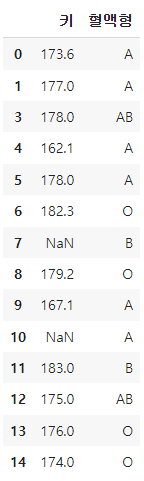
df['혈액형']
type(df['혈액형'])
df['이름']
df.이름
df.키
2. 범위 선택 (range selection)
df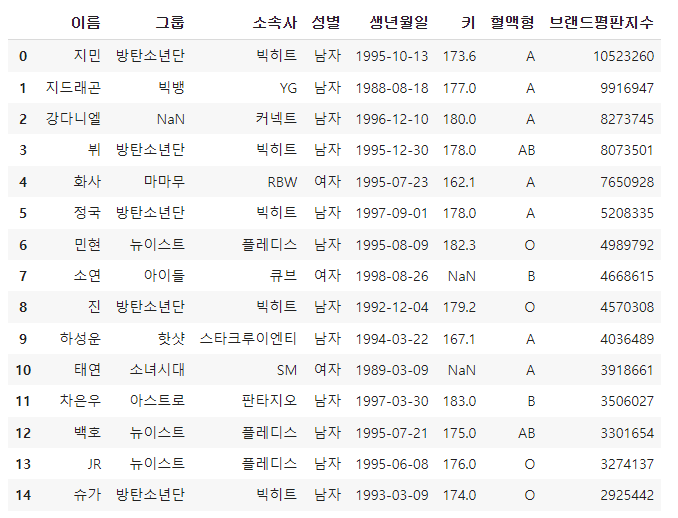
2-1. 단순 index에 대한 범위 선택
df[:3] #행 시작값 설정 o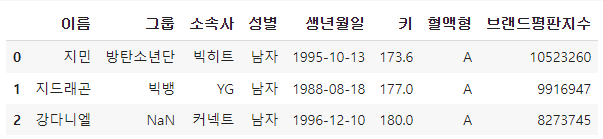
df.head(3) # 시작값 설정 x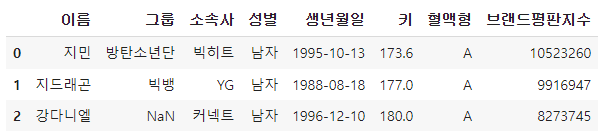
2-2. loc
컬럼명을 다룬다.
앞으로 굉장히 자주 사용합니다. 반드시 손에 익숙해 지도록 합시다!
df.loc[:, '이름'] #loc 컬럼명 iloc 열의 번호로 처리
df.loc[:, ['이름', '생년월일']]
df.loc[3:8, ['이름', '생년월일']]
df.head()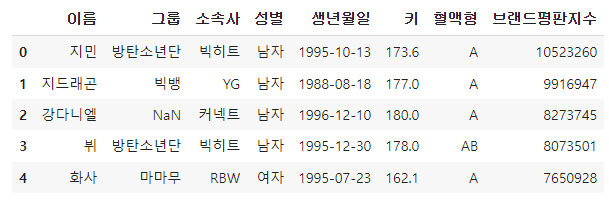
# 2행~5행, '이름' 컬럼 ~ '생년월일' 컬럼까지
df.loc[2:5, '이름':'생년월일']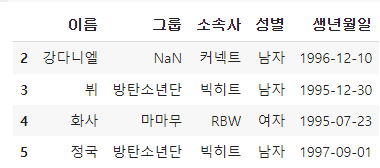
2-3. iloc (position으로 색인)
숫자로 다룬다
df.head()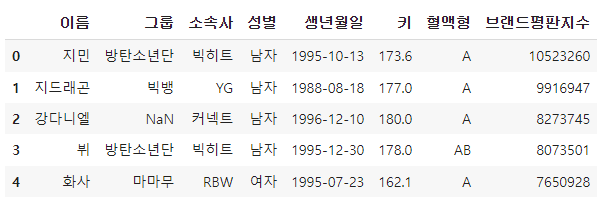
df.iloc[:, [0, 2]]
df.iloc[1:5, [0, 2]]
df.iloc[1:5, 1:4]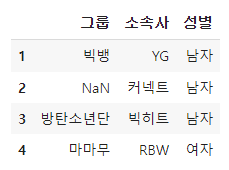
3. Boolean Indexing - 조건을 활용한 색인
Boolean indexing은 Numpy에서 배웠던 Boolean 인덱싱과 같은 원리입니다.
# 검색조건
df['키'] > 180
Boolean Index 로 받은 Index 를 활용해서 True인 값만 색인해 낼 수 있습니다.
df[] 꺾쇠로 감싸주고, 그안에 Boolean Index를 넣어주시면 됩니다.
# df[검색조건]을 이런 형태로 사용
df[ df['키'] < 170]
df[ df['키'] > 180 ]
위와 같은 방법이 매우 간편한 방법이기는 하지만, 모든 column을 출력해야만 한다는 한계가 있습니다.
- 특정 column과 같이 색인해 내고 싶을땐 어떻게 할까요?
# df[ df['키'] > 180, '이름']해결 방법 1. 맨 뒤에 출력할 column 붙히기
df[ df['키'] > 180 ]['이름']
#주의할 것은 '이름','키'를 2차원 리스트형태로 사용
df[ df['키'] > 180 ][['이름', '키']]
해결 방법 2. loc를 활용
df.loc[ df['키'] > 180, '이름']
df.loc[ df['키'] > 180, '이름': '성별'] #이름에서 부터 성별까지 출력
df.loc[ df['키'] > 180, ['이름', '키']]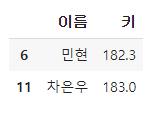
저는 방법 2를 추천 합니다.
4. isin을 활용한 색인
데이터 값이 있는지
isin을 활용한 색인은 내가 조건을 걸고자 하는 값이 내가 정의한 list에 있을 때만 색인하려는 경우에 사용합니다.
my_condition = ['플레디스', 'SM']# 검색조건 -> 소속사중에 플레디스 or SM이 있는지
df['소속사'].isin(my_condition)
df.loc[ df['소속사'].isin(my_condition) ]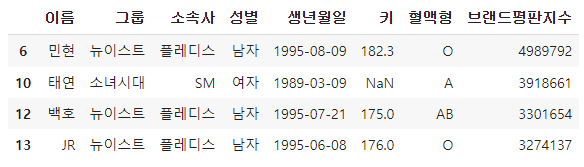
df.loc[ df['소속사'].isin(my_condition),'이름' ]
df.loc[ df['소속사'].isin(my_condition), '소속사' ]
5. 결측값(Null) 알아보기
5-1. NaN 값에 대하여
- Null 값은 비어있는 값, 고~급 언어로 결측값입니다.
- pandas 에서는 NaN => Not a Number 로 표기 된 것을 확인해 볼 수 있습니다.
df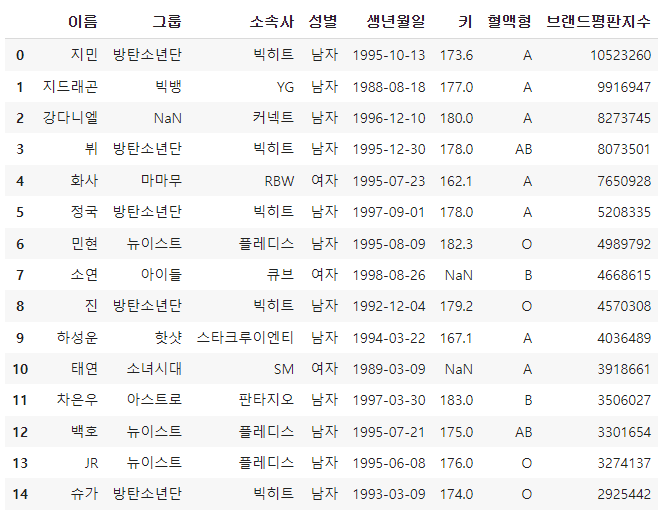
info() 로 NaN 값, 즉 빠진 데이터가 어디에 있는지 쉽게 요약정보로 확인할 수 있습니다.
df.info()
5-2. 결측 값 다루기
Boolean 인덱싱
# 데이터프레임 전체에서 결측치가 있는지 확인할때 isna()
df.isna()
info() 메소드를 통해서 전체적으로 어떤 column에 빠진 데이터가 있는지 알아 보았습니다.
또한, 다음과 같이 특정 column에서 빠진 값을 색출해 낼 수 있습니다.
1. Boolean 인덱싱으로 True가 return 되는 값이 NaN이라는 것을 알 수 있습니다.
# series에서 null값을 확인
df['그룹'].isnull()
2. NaN 값만 색출해내기
df['그룹'][df['그룹'].isnull()] #null인 데이터만 보기
df['그룹'][df['그룹'].isna()]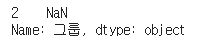
3. NaN이 아닌 값에 대하여 Boolean 인덱싱
df['그룹'].notnull() # isnull과 결과 값이 반대로
4. NaN이 아닌 값만 색출해내기
df['그룹'][df['그룹'].notnull()]
df.loc[ df['그룹'].notnull(), ['키', '혈액형'] ]
#null이 아닌 행 중에 키와 혈액형만 출력