실습자료: http://bit.ly/ds-korean-idol
국내 아이돌 평판지수 (csv)
import pandas as pdDataFrame 로드
df = pd.read_csv('https://bit.ly/ds-korean-idol')1. copy (복사)
copy는 단어 그대로, dataframe을 복사할 때 사용합니다.
df.head()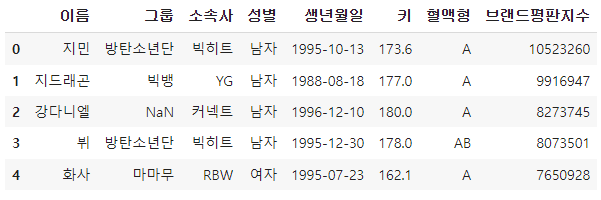
df를 새로운 변수(new_df)에 대입해 주고, 새로운 변수에서 값을 바꾼다면, 원래의 DataFrame의 값은 어떻게 될까요?ㄴ
# 아래와 같이 복사할 경우는 데이터는 복사X, 데이터의 주소만 복사가 된다.
new_df = dfnew_df.head()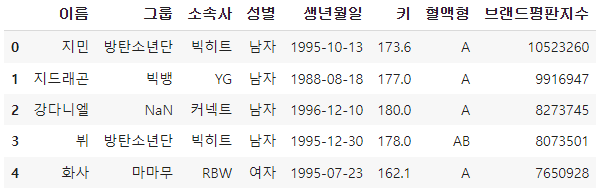
df.head()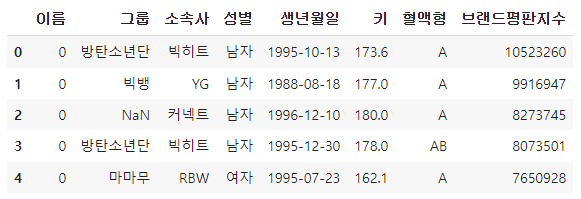
이렇게 되는 이유는 같은 메모리 주소를 참조하기 때문입니다.
# 메모리 주소값을 확인
id(df)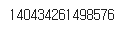
# 일반적으로 컴퓨터의 메모리 주소값은 16진수로 표현
hex(id(new_df))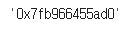
# 아래 코드를 통해 같은 메모리 주소값을 참조하는 것을 확인
hex(id(df))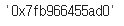
굉장히 많은 분들이 실수를 하시는 부분입니다.
원본 데이터를 유지 시키고, 새로운 변수에 복사할 때는 copy()를 사용해 주세요
df = pd.read_csv('https://bit.ly/ds-korean-idol')# python에서 얕은 복사((Shallow Copy 주소값만 복사), 깊은 복사(deep copy 데이터를 통채로 복사)
copy_df = df.copy()hex(id(df))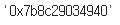
hex(id(copy_df))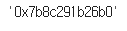
df.head()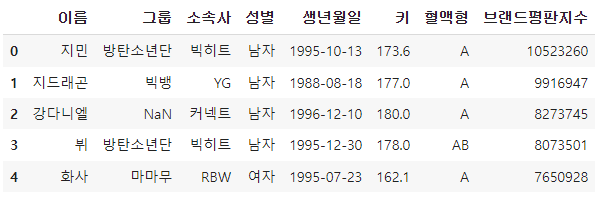
copy_df.head()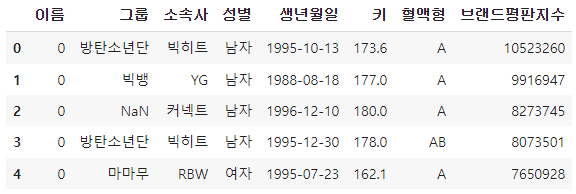
copy_df['이름'] = 0copy_df.head()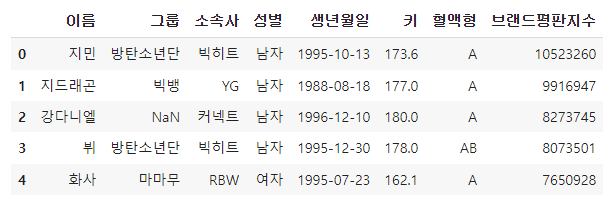
df.head()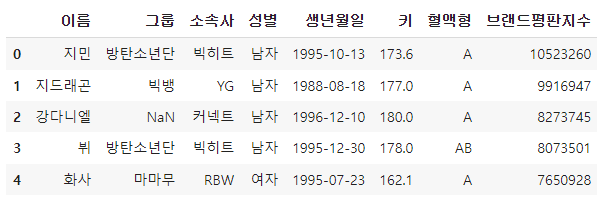
df.tail()
2. dataFrame에 row, column 추가 및 삭제
2-1. row의 추가
df.head()
dictionary 형태의 데이터를 만들어 준다음 append() 함수를 사용하여 데이터를 추가할 수 있습니다. 반드시, ignore_index=True 옵션을 같이 추가해 주셔야 에러가 안납니다!
# df라는 데이터프레임에 한 행(row)을 추가(append)
df.append({'이름': '민영', '그룹': '브레이브 걸스', '소속사': '브레이브 엔터', '성별': '여자', '생년월일': '1990-09-12', '키': 165.0, '혈액형': 'AB', '브랜드평판지수': 12345678}, ignore_index=True)
df.tail()
또한, append() 한 뒤 다시 df에 대입해줘야 변경한 값이 유지 됩니다.
df = df.append({'이름': '테디', '그룹': '테디그룹', '소속사': '끝내주는소속사', '성별': '남자', '생년월일': '1970-01-01', '키': 195.0, '혈액형': 'O', '브랜드평판지수': 12345678}, ignore_index=True)#결과
#<ipython-input-149-3b24ec9ed5b8>:1: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
# df = df.append({'이름': '테디', '그룹': '테디그룹', '소속사': '끝내주는소속사', '성별': '남자', '생년월일': '1970-01-01', '키': 195.0, '혈액형': 'O', '브랜드평판지수': 12345678}, ignore_index=True)hex(id(df))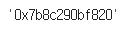
df.tail()
2-2. column 추가
column 추가는 매우 쉽습니다. 단순히 새로운 column을 만들고 값을 대입해주면, 자동으로 생성합니다.
df.head()# df dataframe에 '국적'이라는 이름으로 column추가
df['국적'] = '대한민국'df.loc[ df['이름'] == '지드래곤' , '국적'] = 'korea'df.head()