spark.read 관련
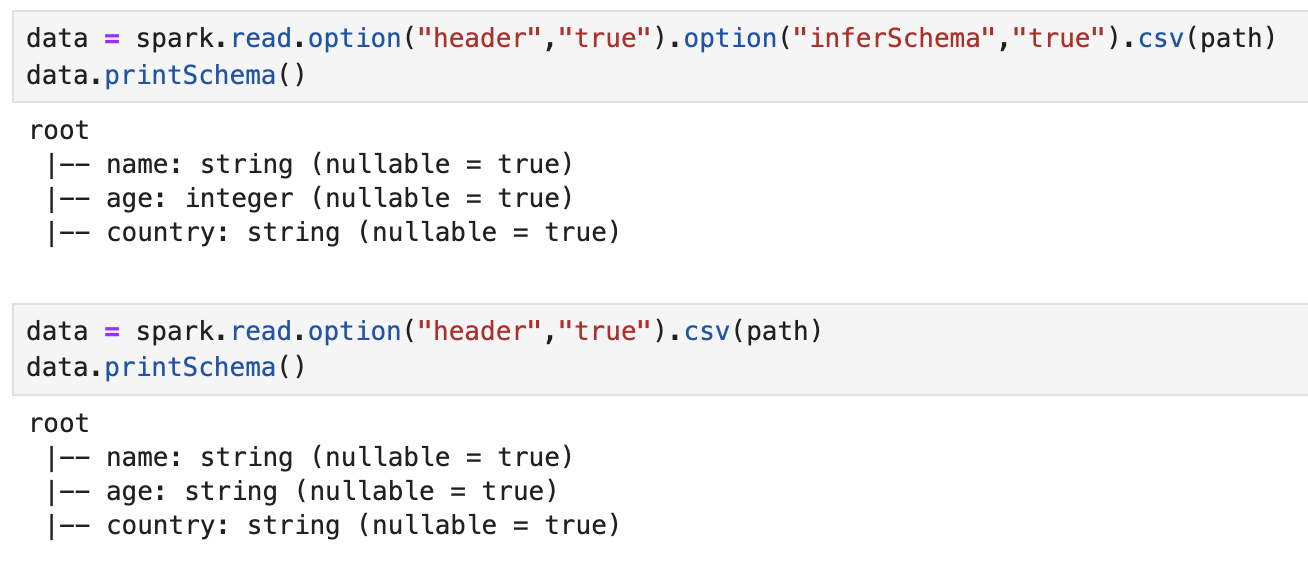
data = spark.read.option("header","true").option("inferSchema","true").csv(path)
-
리턴값
spark.read에 return 값은 디폴로 DataFrame이다 . 앞에 txt파일들을 읽어 왔을때랑 다르게 별도로 createDataFrame을 할 필요가 없다. -
다양한 .option 종류
.option("header","true")
먼저 csv에 헤더 파일을 자동으로 읽어와 사용가능
.option("inferSchema","true")
컬럼 별 타입을 추론 해서 자동 기입, 옵션을 주지 않으면 전부 string으로 처리 + printSchema()함수
DataFrame 함수 활용
임시 뷰 생성 후 SQL 쿼리 사용 (spark.sql) vs DataFrame 함수 사용
| 특징 | 임시 뷰 (spark.sql) | DataFrame API |
|---|---|---|
| 장점 |
|
|
| 단점 |
|
|
| 활용 시나리오 |
|
|
임시뷰 (sql)
장점 :
SQL 친숙성: SQL 문법에 익숙한 사용자에게 직관적이고 편리합니다.
복잡한 쿼리: JOIN, 서브쿼리 등 복잡한 쿼리를 표현하기 용이합니다.
재사용성: 임시 뷰를 생성하면 동일한 쿼리를 여러 번 사용할 수 있습니다.
단점:
성능: DataFrame API에 비해 쿼리 최적화가 덜 이루어져 성능이 낮을 수 있습니다.
유연성: DataFrame API의 다양한 함수를 활용하기 어렵습니다.
활용 시나리오:
SQL 문법에 익숙하고 복잡한 쿼리를 작성해야 하는 경우
BI(Business Intelligence) 도구와 연동하여 데이터 분석을 수행하는 경우
데이터 엔지니어링 팀과 협업하여 SQL 기반 데이터 파이프라인을 구축하는 경우
DataFrame API 직접 사용 (예: schema_income.groupBy("country").count())
장점:
성능: DataFrame API는 Catalyst Optimizer를 통해 쿼리 최적화가 이루어져 SQL 쿼리보다 성능이 우수할 수 있습니다.
유연성: 다양한 함수 (groupBy, agg, filter 등)를 조합하여 복잡한 데이터 처리를 수행할 수 있습니다.
타입 안정성: 컴파일 타임에 오류를 확인할 수 있어 안정적인 코드 작성이 가능합니다.
단점:
학습 곡선: DataFrame API의 다양한 함수를 익히는 데 시간이 필요합니다.
가독성: 복잡한 연산을 수행할 때 코드가 길어지고 가독성이 떨어질 수 있습니다.
활용 시나리오:
DataFrame API에 익숙하고 성능이 중요한 경우
유연하고 복잡한 데이터 처리 작업을 수행해야 하는 경우
머신 러닝 파이프라인과의 통합이 필요한 경우
사용법
1. select a, b
칼럼 이름을 '' 안에 써야 해서 조금 불편해 , data.a 로 사용가능
data.select('name','age').show()
data.select(data.name,data.age).show()
2. where 조건
원하는 칼럼 넣고, .filter로 조건 추가
data.filter(data.age > 20).show()
data.select(data.name, data.age).filter(data.age > 70).show()
3. groupby
age 별 count 수
data.groupBy("age").count().show()
3. custom 변수 + .alias()
data.select(data.name, data.age, (data.age - 10).alias('new_age')).show()
3. groupby + avg + sort
step 1. 원하는 컬럼 모수 줄여놓고
data.select(data.name, data.age, data.country)
step 2. 집계하고 싶은 변수 선택 + avg / sum 등 집계함수 컬럼 선택
step 3. sorting할 변수 선택
data.select(data.name, data.age, data.country)\
.groupBy("country").avg("age").sort("avg(age)").show()
