
한권으로 읽는 컴퓨터 구조와 프로그래밍의 내용을 기반으로 작성한 포스팅입니다.
들어가기 전에
책을 읽으며 나는 대학에서 주입식 교육을 받았구나 하는 생각을 하게 되었다.
교수자의 책임이 아니라 강의 교재로 선정된 도서의 탓인 것 같다.
강의 교재는 공식을 외우며 공부하도록 했지만 이 책은 그렇지 않다.
프로그래밍적으로 사고 할 수 있도록 유도한다.
책을 읽으며 대학에서 주입 받았던 지식과 책의 내용을 비교하는 식으로 읽었더니 이해가 더 잘됐고 재밌게 읽을 수 있었던 것 같다.
서론을 뒤로하고 포스팅을 시작한다.
언어란?
살아가면서 가장 중요한게 언어 능력이 아닐까 싶다. 언어는 여러가지 형태로 존재한다.
글쓰기, 말하기, 몸짓, 행위 등 어떤 개념을 전달할 수 있다면 그것은 언어가 된다.
언어는 기호의 집합이다.
언어를 글자로 표현할 수 있는데 글자를 언어를 표현하는 글자를 기호라고 한다.
그리고 언어의 뜻은 보존하면서 형태만 변경하는 것을 인코딩**이라고 한다.
언어를 기호로 인코딩 하는 것만으로는 충분하지 않다. 예를들어, "사과" 라는 기호는 과일을 의미할 수 있고, 용서를 구하는 것을 의미할 수 있다.
하나의 기호가 다른 뜻으로 해석될 수 있다는 뜻이다. 이것은 어떻게 해결할 수 있을까?
언어와 문맥
의사소통 당사자들은 모두 같은 문맥(context)을 공유해야 한다.
두 사람이 다툰 후의 "사과"라는 기호는 용서를 구하는 것을 의미한다.
과일 가게 안에서의 "사과"라는 기호는 과일을 의미한다.
이렇듯 언어(기호)가 기능을 발휘하려면 의사소통 당사자들이 같은 문맥을 공유해야 한다.
서로 다른 문맥에 있다면 언어는 무용지물이다.
컴퓨터와 인간이 의사소통하려면 어떻게 해야 할까?
컴퓨터와 인간은 서로 다른 문맥에 있기 때문에 누군가가 상대방의 문맥으로 들어가야 한다.
당연히 인간이 컴퓨터의 문맥으로 들어간다. 컴퓨터의 문맥을 알아보자.
컴퓨터의 언어 "비트(bit)"
비트(bit)는 2진법(binary)와 숫자(digit)이 합쳐진 말이다. 비트는 2진법을 사용한다.
비트를 왜 사용할까? 비트를 사용하면 적은 비용으로 편리하게 기호를 담을 수 있기 때문이다.
비트는 0과 1의 값만 가질 수 있다. 그리고 컴퓨터는 비트의 여러가지 조합으로 언어를 표현한다.
비트는 0과 1의 값만 가지고 있지만 모스 부호는 점(.)과 선(-)만 사용하는 2진법 언어이다.
모스부호로 A를 표현하면 .- 이다. 비트로 A를 표현하면 1000000 이다.
같은 A를 표현하지만 서로 다른 기호로 구성된다. 우리는 문맥을 파악해서 .- 도 A이고 1000000도 A라는 것을 알 수 있다.
컴퓨터도 문맥을 통해서 같은 기호로 구성된 비트지만 문자, 정수, 사진 등을 표현한다.
그렇다면 컴퓨터는 비트를 사용해서 현실 세계의 언어를 어떻게 표현하는지 자세히 알아보자.
정수를 비트로 표현하기
2진수, 8진수, 10진수 표현법은 알고 있다고 가정하고 포스팅한다. 모르면 위키 백과 참고
컴퓨터의 언어는 비트이기 때문에 항상 정수도 비트로 표현한다.
다행히 비트는 2진법을 기반으로 하기 때문에 2진수를 10진수로 변환하는 방법으로 쉽게 정수를 표현할 수 있다.
문제는 다른 곳에 있다. 컴퓨터는 한정적인 자원인 하드웨어로 구성되어 있다.
값 비싼 하드웨어는 비트를 많이 가지고 있지만 저렴한 하드웨어는 그렇지 못하다.
그렇기 때문에 정수를 표현하기에 가장 효율적인 비트의 수를 찾아야 했다.
2진수 0001 과 2진수 1은 똑같이 1을 의미한다. 그러나 0001은 4비트를 사용하고 1은 1비트만 사용한다.
1을 표현하기 위해서는 하나의 비트만 필요하지만 하나의 비트로는 2이상을 표현할 수 없다.
확장성과 효율성 사이의 트레이드오프가 반드시 필요했고 결론만 말하자면 8의 배수인 32비트(int)와 64비트(long)가 널리 사용되고 있다.
2진수를 10진수로 변환해보면 항상 양수이다. 음수는 어떻게 표현해야 할까? 알아보자.
비트의 개수가 많아지면서 LSB, MSB라는 개념을 도입했다.
Most Significant Bit(MSB)는 가장 왼쪽에 위치한 비트를 나타낸다. 따라서 가장 큰 수이다.
Least Significant Bit(LSB)는 가장 오른쪽에 위치한 비트를 나타낸다. 따라서 가장 작은 수이다.
음수 정수로 표현하기
간단하다. 컴퓨터는 음수를 표현하기 위해서 MSB를 1로 고정한다.
즉, 가장 왼쪽의 비트가 1이면 음수라는 뜻이다.
대학교 1학년 때 컴퓨터 개론 수업을 들으면서 의문이 들었다.
아까까지는 1001 이 9였는데 지금은 -1이라고?
그래서 교수님께 질문을 했다.
그러면 1001이 언제는 9이고 언제는 -1인가요?
교수님께서는 대답을 하지 못하셨다. 얼버무리고 넘어갔다.
이제는 내가 답변할 수 있을 것 같다.
문맥에 따라 달라집니다
컴퓨터에서 정수를 효율적으로 표현하기 위해서 이미 규칙이 정의되어 있다.
이 규칙들이 문맥이 되었다.
- 정수를 표현할 때 32비트 혹은 64비트를 사용한다.
- MSB가 1인 정수는 음수이다.
이 두 가지 문맥으로 우리는 충분히 음수를 표현할 수 있게 되었다.
JAVA의 int 타입을 살펴보자.
| 10진수 | 2진수 |
|---|---|
| -2147483648 ~ 2147483647 | -2^31 ~ 2^31-1 |
int 타입은 32 비트를 사용한다. 하지만 MSB를 음수를 표현하기 위한 비트로 사용하기 때문에 31개의 비트만 숫자를 표현하기 위해서 사용한다.
그렇기 때문에 음/양 모두 31 거듭제곱의 범위를 가진다.
문맥을 통해 인간과 컴퓨터는 음수와 양수를 모두 사용해서 의사소통 할 수 있게 되었다.
실수를 비트로 표현하기
PC가 보급되면서 컴퓨터는 게임기 혹은 미디어 감상, 웹 서핑 등 다양한 용도로 사용되고 있지만 컴퓨터의 탄생의 목적은 계산이었다.
64비트 정도면 꽤 큰 정수를 표현할 수 있다. 그런데 실수는 64비트로는 모자르다.
그러면 실수는 몇 비트를 사용해서 표현하고 있을까? 놀랍게도 실수 또한 32비트와 64비트로 표현하고 있다.
사용하는 비트의 수는 정수와 같지만 문맥이 다르다. 실수를 표현하는 문맥을 알아보자.
IEEE 754
IEEE 754는 부동 소수점 수를 표현하는 문맥을 표준화한 것이다.
최소한의 비트로 최대한의 정밀도로 표현하기 위해서 여러가지 트릭을 사용한다.
그 중 한 가지는 정규화이다. 정규화는 왼쪽의 자릿 수를 위한 0을 없게 만드는 것이다. 정규화를 거치면 가장 왼쪽은 항상 1이 된다.
가장 왼쪽이 1이 되는 특징을 기반으로 두 번째 트릭을 사용한다. 가장 왼쪽이 항상 1이기 때문에 가장 왼쪽을 생략하는 것이다.
이 외에도 지수를 표현하는 문맥, 가수를 표현하는 문맥, 부호를 표현하는 문맥 등 실수를 표현할 때 비트를 해석하는 또 다른 문맥들이 정의가 되어 있다.
중요한 것은 문맥에 따라 같은 비트가 다른 값을 가질 수 있다는 점이다.
세상에는 숫자만 존재하는 것이 아니다. 문자도 존재하는데 문자는 어떻게 표현하는지 알아보자.
텍스트를 비트로 표현하기
텍스트를 표현하기 위한 문맥들은 몇 가지 아이디어가 서로 경쟁했다.
시대의 흐름에 따라 승리한 아이디어의 역사를 살펴보자.
아스키코드
초기에는 컴퓨터가 미국, 영국에서 대부분 사용 했기 때문에 영어를 표현하기 적합한 아스키코드가 표준으로 사용됐다.
아스키 코드는 0~9, a~z, A~Z 특수문자, 제어문자를 10진수와 매칭시킨 코드이다.
제어 문자의 대부분은 HTTP 통신을 위해 사용된다고 한다. 다시 보니 ACK 라는 제어문자를 네트워크 수업에서 본 기억이 난다.
아스키 코드는 키보드에 있는 모든 기호를 표현할 수 있고 7비트를 사용한다.
컴퓨터는 8의 배수를 처리하도록 설계되었기 때문에 아스키 문자는 8비트를 사용해서 저장된다.
유니코드
아스키 코드는 영어만 표현할 수 있었다. 컴퓨터가 전 세계로 보급되면서 영어 외의 언어들도 표현해야하는 상황이 왔다.
다른 언어들을 표현하기 위해 도입된 것이 유니코드이다. 유니코드는 영어 이외의 언어들을 표현하기 위해서 더 많은 비트를 사용한다.
유니코드가 도입 될 때에는 비트가 충분히 저렴해졌기 때문에 큰 문제가 안됐다.
초기의 유니코드는 16비트를 사용 했지만 그 마저도 부족해졌고 지금은 21비트를 사용한다.
UTF-8
유니 코드를 사용하는 것은 표준이 되었지만, 유니코드를 그대로 사용한다면 너무 많은 비트를 사용하기 때문에 효율적이지 않다.
그래서 반드시 인코딩을 거친 후 사용하게 된다. 대표적인 유니코드 인코딩 방식은 EUC-KR, CP949, UTF-8이 있다.
한국의 개발자들은 UTF-8이 익숙한텐데.. 뭔가 한글이 깨진다 싶으면 인코딩 방식을 UTF-8로 변경하는 식으로 해결해왔다.
UTF-8은 연속적인 8비트 단위의 덩어리로 표현된다.
UTF-8에는 아스키 코드 -> UTF-8 의 문맥과 !아스키 코드 -> UTF-8 문맥이 있다.
아스키 코드 -> UTF-8 일 때는 아스키 코드의 7비트를 그대로 사용하면서 MSB만 0비트로 채워준다.
그림을 살펴보자.
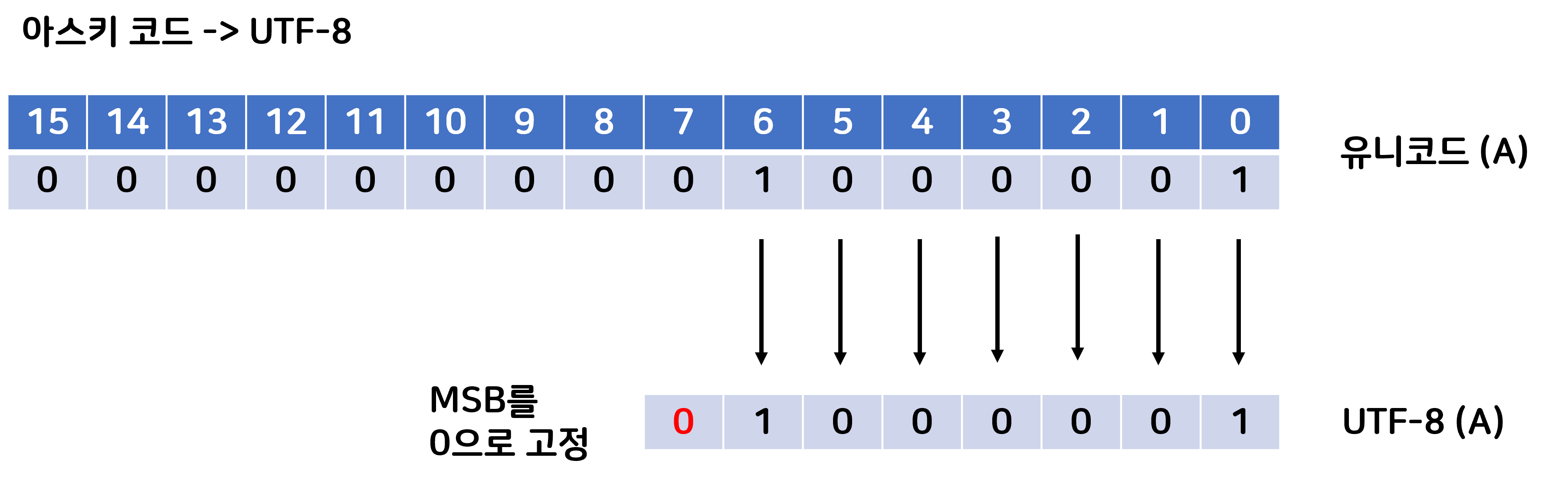
MSB가 0비트인 것의 의미는 해당 문자가 1바이트(bit)를 초과하지 않는다는 뜻이다.
그렇다면 이제 !아스키 코드 문자들을 보자
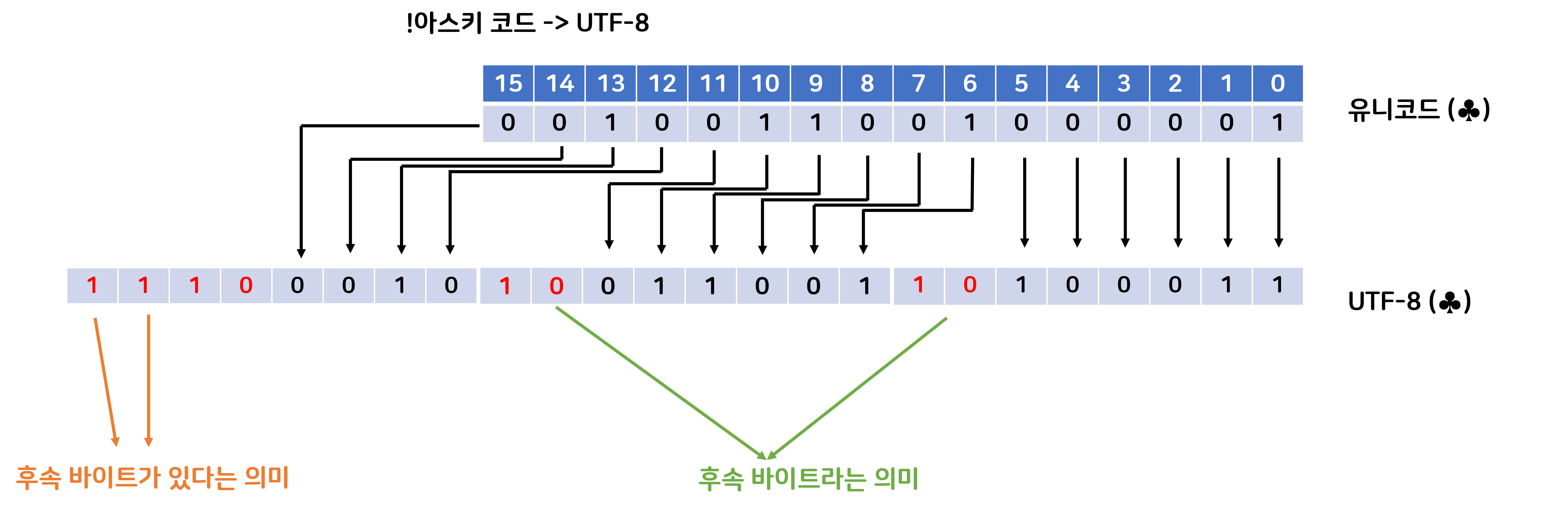
가장 왼쪽에 바이트는 후속 바이트가 있는 만큼 1을 포함한다. 그림에서는 후속 바이트가 2개 있으니 1이 두개가 왔다.
그리고 후속 바이트들은 10을 가장 왼쪽 비트에 포함함으로써 후속 바이트라는 것을 알린다.
유니 코드는 21비트를 사용하기 때문에 UTF-8로 인코딩 했을 시 최대 4바이트의 문자를 가질 수 있다.
각 바이트들의 관계를 알기 위해서 이런 문맥이 필요하게 된 것이다.
결론
앞에서 살펴본 인코딩 방식 외에도 Base64, RGB와 ARGB, URL 인코딩 등 많은 인코딩 방식이 있다.
이번 챕터에서는 인코딩이 구체적으로 어떻게 이뤄지는지보다는 "비트가 문맥에 따라서 다르게 해석되는 것"을 이해하는게 중요한 것 같아 보인다.
.jpg)