머신 러닝에서 과적합(Overfitting)이란 훈련 데이터를 과하게 학습한 경우를 말한다. 머신 러닝 모델이 학습에 사용하는 훈련 데이터는 극히 일부의 데이터이다. 그런데 이 훈련 데이터만 너무 과하게 학습한 나머지 테스트 데이터, 그리고 실제 서비스에 적용해 보았을 때 정확도가 현저히 떨어지는 것이다. 마치 수학문제집 한 권을 여러번 풀어 마스터 했더라도, 실제 수학시험에서 전혀 다른 문제가 나오면 대응하지 못하는 경우를 생각하면 쉽다.
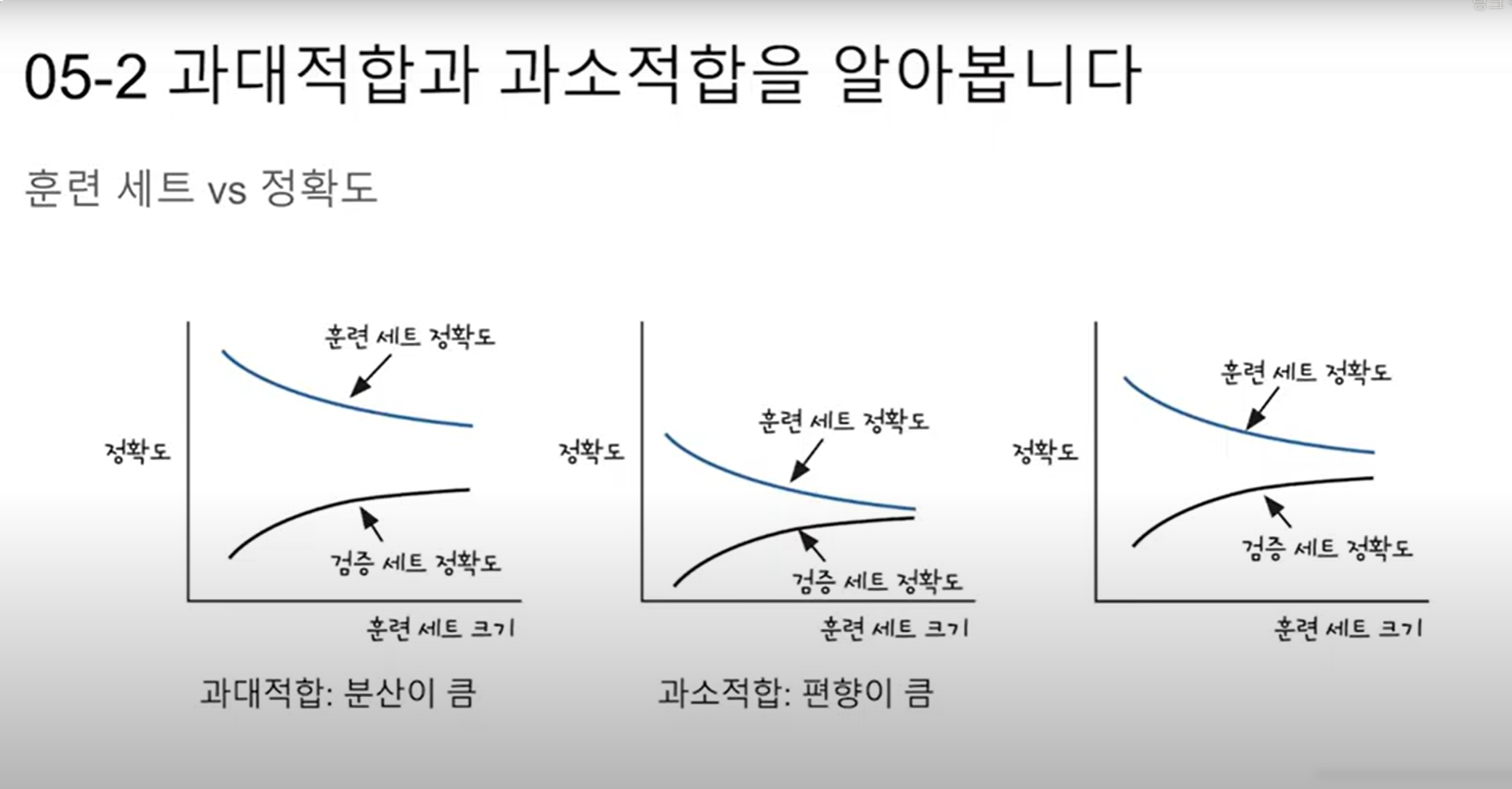
과적합 상황에서는 훈련 데이터에 대해서는 오차가 낮지만(높은 정확도를 보이지만), 테스트 데이터에 대해서는 오차가 커진다.(정확도가 낮아진다). 아래의 그래프는 과적합 상황에서 발생할 수 있는 훈련 데이터에 대한 훈련 횟수에 따른 훈련 데이터의 오차와 테스트 데이터의 오차(또는 손실)의 변화를 보여준다.
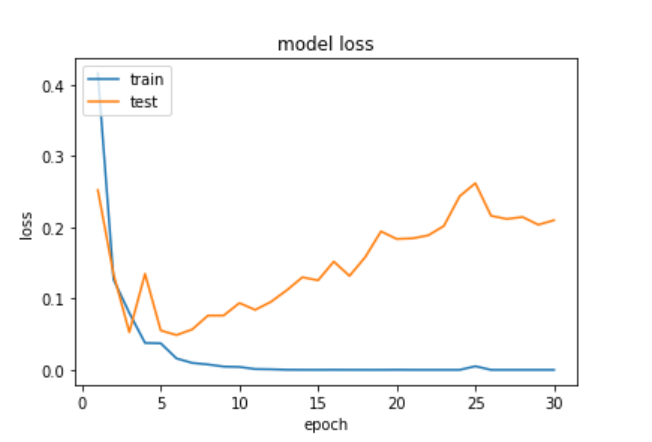
출처: https://wikidocs.net/32012
위 그래프는 뒤의 RNN을 이용한 텍스트 분류 챕터의 스팸 메일 분류하기 실습에서 훈련 데이터에 대한 훈련 횟수를 30 에포크로 주어서 의도적으로 과적합을 발생시킨 그래프인데, y축은 오차(loss), X축의 에포크(epoch)는 전체 훈련 데이터에 대한 훈련 횟수를 의미하며, 사람으로 비유하면 동일한 문제(훈련 데이터)를 반복해서 푼 횟수와 같다. 에포크가 지나치게 크면 훈련 데이터에 과적합이 발생한다.
스팸 메일 분류하기 실습은 에포크가 3~4에서 테스트 데이터에 대한 정확도가 가장 높고, 에포크가 그 이상을 넘어가면 과적합이 발생한다. 위의 그래프는 에포크가 증가할수록 테스트 데이터에 대한 오차가 점차 증가하는 양상을 보여준다. 과적합은 다르게 설명하면 훈련 데이터에 대한 정확도는 높지만, 테스트 데이터는 정확도가 떨어진다. 이런 상황을 방지하기 위해서는 테스트 데이터의 오차가 증가하기 전이나, 정확도가 감소하기 전에 훈련을 멈추는 것이 바람직하다.
반면, 테스트 데이터의 성능이 올라갈 여지가 있음에도 훈련을 덜 한 상태를 과소적합(Underfitting) 이라고 한다. 과소 적합은 훈련 자체가 부족한 상태이므로 훈련 횟수인 에포크가 지나치게 적으면 발생할 수 있습니다. 과대 적합과는 달리 과소 적합은 훈련 자체를 너무 적게한 상태이므로 훈련 데이터에 대해서도 정확도가 낮다는 특징이 있다. 이는 훈련 횟수를 늘려주는 방식으로 해결할 수 있다.
이러한 두 가지 현상을 과적합과 과소 적합이라고 부르는 이유는 머신 러닝에서 학습 또는 훈련이라고 하는 과정을 적합(fitting)이라고도 부르기 때문이라고 한다.. 모델이 주어진 데이터에 대해서 적합해져가는 과정이므로, 케라스에서는 기계를 학습시킬 때 fit()을 호출한다.
딥 러닝을 할 때는 과적합을 막을 수 있는 드롭 아웃(Dropout), 조기 종료(Early Stopping) 등의 방법도 존재하는데, 나중에 딥러닝 챕터에서 소개해도 좋을 것 같고, 에포크에 대한 설명이 부실한 듯 하여 나중에 딥러닝 챕터에서 보완해야겠다.
