FIFO와 Priority 알고리즘을 사용하여 가상의 GPU 처리 시간, 우선순위에 따른 소요시간을 시뮬레이션 해보았습니다.
정글에서 배웠던 우선순위 알고리즘과 GPU 클러스터 소요시간을 연관지어 설명하겠습니다.
1. 프로젝트 생성
- 프로젝트 생성: 원하는 이름으로 폴더를 생성합니다. Java 프로젝트로 만들 것이며 프로젝트 생성으로 만들지 않아도 됩니다.
- 패키지 생성:
com.scheduler.sim의 이름으로 패키지를 생성합니다. - 클래스 파일 생성: 총 3개의 핵심 클래스 파일을 생성합니다.
Job.java: AI 작업의 정보를 담는 데이터 클래스GPU_Cluster.java: GPU 클러스터의 상태를 관리하는 클래스Simulator.java: 시뮬레이션의 메인 로직을 실행하는 클래스
2. 핵심 데이터 모델링 (Job, GPU_Cluster 클래스 구현)
시뮬레이션에 필요한 요소들을 설계합니다.
Job.java (작업 정보)
Ai 작업 하나의 모든 정보를 담게됩니다. Comparable 인터페이스를 구현하여 나중에 우선순위에 따라 쉽게 정렬할 수 있도록 합니다.
package com.scheduler.sim;
public class Job implements Comparable<Job> {
String jobId;
int gpusRequired;
int duration;
int priority;
// 시뮬레이션 중 사용될 변수들
int arrivalTime;
int startTime = -1; // -1은 아직 시작 안 됐음을 의미
public Job(String jobId, int gpusRequired, int duration, int priority, int arrivalTime) {
this.jobId = jobId;
this.gpusRequired = gpusRequired;
this.duration = duration;
this.priority = priority;
this.arrivalTime = arrivalTime;
}
// 우선순위에 따라 Job 객체를 정렬하기 위한 비교 메서드
// priority 값이 낮을수록 높은 우선순위를 갖도록 설정 (숫자 1이 가장 높음)
@Override
public int compareTo(Job other) {
return Integer.compare(this.priority, other.priority);
}
@Override
public String toString() {
return String.format("Job[%s, GPUs:%d, Duration:%d, Prio:%d]", jobId, gpusRequired, duration, priority);
}
}GPU_Cluster.java (GPU 클러스터 관리)
클러스터의 전체 GPU 수와 현재 사용 가능한 GPU 수를 관리합니다.
package com.scheduler.sim;
public class GPU_Cluster {
int totalGpus;
int availableGpus;
public GPU_Cluster(int totalGpus) {
this.totalGpus = totalGpus;
this.availableGpus = totalGpus;
}
// 작업을 스케줄링할 때 GPU를 할당하는 메서드
public boolean allocateGpus(Job job) {
if (availableGpus >= job.gpusRequired) {
availableGpus -= job.gpusRequired;
return true; // 할당 성공
}
return false; // 할당 실패
}
// 작업이 끝나면 GPU를 반환하는 메서드
public void releaseGpus(Job job) {
availableGpus += job.gpusRequired;
}
}3. 메인 시뮬레이션 및 스케줄러 로직 구현
실제 시뮬레이션이 동작하는 메인 클래스와 스케줄링 알고리즘을 구현합니다.
Simulator.java (시뮬레이션 실행 및 알고리즘)
FIFO와 Priority 알고리즘을 큐와 리스트를 활용하여 구현하고 GPU 갯수와 시뮬레이션 시간을 기본적으로 설계합니다. 이후 가상의 작업 데이터를 생성하고 대기 큐와 실행/완료 작업을 리스트로 환경을 준비합니다.
메인 시뮬레이션루프를 통해 계산하여 평균 작업 대기 시간, GPU 사용률 등의 지표를 결과 값으로 산출하게 됩니다.
// Simulator.java
package com.scheduler.sim;
import java.util.*;
public class Simulator {
// --- 알고리즘 1: FIFO 스케줄러 ---
public static void scheduleFifo(Queue<Job> jobQueue, GPU_Cluster cluster, List<Job> runningJobs, int currentTime) {
// 큐의 맨 앞 작업을 확인 (제거하지 않음)
Job nextJob = jobQueue.peek();
if (nextJob != null) {
// 클러스터에 자원이 충분하면 작업을 스케줄링
if (cluster.allocateGpus(nextJob)) {
// 큐에서 작업을 제거하고 시작 시간 기록
Job jobToRun = jobQueue.poll();
jobToRun.startTime = currentTime;
runningJobs.add(jobToRun);
System.out.printf("Time %d: %s STARTED.\n", currentTime, jobToRun);
}
}
}
// --- 알고리즘 2: Priority 스케줄러 ---
public static void schedulePriority(Queue<Job> jobQueue, GPU_Cluster cluster, List<Job> runningJobs, int currentTime) {
// 자바의 LinkedList는 정렬 기능이 없으므로, 리스트로 변환 후 정렬
List<Job> sortedQueue = new ArrayList<>(jobQueue);
Collections.sort(sortedQueue); // Job 클래스의 compareTo 메서드에 따라 우선순위로 정렬됨
// 정렬된 리스트의 첫 번째 작업(가장 높은 우선순위)을 확인
if (!sortedQueue.isEmpty()) {
Job nextJob = sortedQueue.get(0);
// 클러스터에 자원이 충분하면 작업을 스케줄링
if (cluster.allocateGpus(nextJob)) {
// **원본 큐에서** 해당 작업을 제거
jobQueue.remove(nextJob);
nextJob.startTime = currentTime;
runningJobs.add(nextJob);
System.out.printf("Time %d: %s STARTED.\n", currentTime, nextJob);
}
}
}
public static void main(String[] args) {
// --- 1. 시뮬레이션 기본 설정 ---
final int TOTAL_GPUS = 16;
final int SIMULATION_TIME = 200;
GPU_Cluster cluster = new GPU_Cluster(TOTAL_GPUS);
// --- 2. 가상 작업 데이터 생성 ---
List<Job> allJobs = new ArrayList<>(Arrays.asList(
new Job("J1", 8, 20, 2, 0),
new Job("J2", 4, 30, 1, 0),
new Job("J3", 4, 25, 3, 5),
new Job("J4", 2, 50, 2, 10),
new Job("J5", 8, 15, 1, 15)
));
// --- 3. 시뮬레이션 환경 준비 ---
Queue<Job> jobQueue = new LinkedList<>(); // 대기 큐
List<Job> runningJobs = new ArrayList<>(); // 실행 중인 작업
List<Job> completedJobs = new ArrayList<>(); // 완료된 작업
// --- 4. 메인 시뮬레이션 루프 ---
System.out.println("--- FIFO Scheduling Simulation START ---");
// TODO: 나중에 Priority로 바꾸려면 이 부분을 schedulePriority로 변경
String schedulerType = "FIFO";
for (int currentTime = 0; currentTime < SIMULATION_TIME; currentTime++) {
// (1) 도착한 작업이 있으면 대기 큐에 추가
for (Job job : allJobs) {
if (job.arrivalTime == currentTime) {
jobQueue.add(job);
System.out.printf("Time %d: %s arrived in queue.\n", currentTime, job);
}
}
// (2) 실행 중인 작업이 끝났는지 확인
Iterator<Job> iterator = runningJobs.iterator();
while (iterator.hasNext()) {
Job runningJob = iterator.next();
if (currentTime >= runningJob.startTime + runningJob.duration) {
cluster.releaseGpus(runningJob);
completedJobs.add(runningJob);
iterator.remove(); // 실행 목록에서 제거
System.out.printf("Time %d: %s FINISHED. Available GPUs: %d\n", currentTime, runningJob, cluster.availableGpus);
}
}
// (3) 선택된 스케줄러 실행
if (!jobQueue.isEmpty()) {
if (schedulerType.equals("FIFO")) {
scheduleFifo(jobQueue, cluster, runningJobs, currentTime);
} else if (schedulerType.equals("PRIORITY")) {
schedulePriority(jobQueue, cluster, runningJobs, currentTime);
}
}
// 모든 작업이 완료되면 시뮬레이션 조기 종료
if (completedJobs.size() == allJobs.size()) {
System.out.println("All jobs completed. Simulation finished at time " + currentTime);
break;
}
}
// --- 5. 최종 결과 리포트 (간단하게) ---
// TODO: 평균 대기 시간, GPU 사용률 등 지표 계산
}
}4. 실행 시키고 결과값 산출
FIFO 결과값 확인하기
해당 프로젝트 폴더에서 컴파일과 실행을 합니다.
javac -encoding UTF-8 com/scheduler/sim/*.java컴파일에 성공하면 다음과 같이 실행해 실행합니다.
java com.scheduler.sim.SimulatorFIFO의 결과를 확인했으면 Prioity로 코드를 바꿔 재실행해봅니다.
Priority로 실행하기
Simulator.java를 다음과 같이 변경합니다.
변경전
// ...
System.out.println("--- FIFO Scheduling Simulation START ---");
// TODO: 나중에 Priority로 바꾸려면 이 부분을 schedulePriority로 변경
String schedulerType = "FIFO"; // <-- 이 부분을 바꾸세요!
// ...변경후
**// ...
System.out.println("--- Priority Scheduling Simulation START ---"); // 출력 메시지도 바꿔주면 좋겠죠?
String schedulerType = "PRIORITY"; // <-- 이렇게 변경!
// ...**재컴파일하기
# 1. 컴파일 (한글 주석이 있으니 -encoding UTF-8 옵션 유지)
javac -encoding UTF-8 com/scheduler/sim/*.java
# 2. 실행
java com.scheduler.sim.Simulator결과 분석
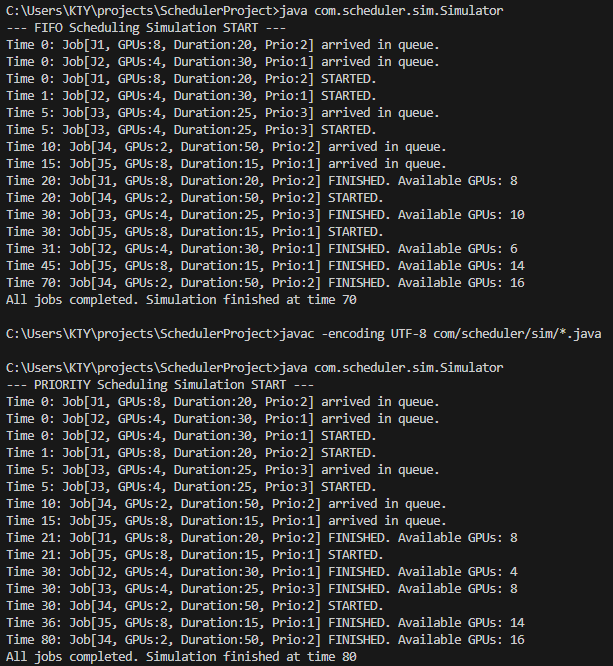
위 결과를 보면 FIFO는 70초에 모든 작업이 끝났지만, Priority는 80초가 걸리면서 결과적으로 FIFO가 더 빠름을 알 수 있습니다. 이유는 중요한 작업을 먼저 처리하려다 보니, 전체적인 자원(GPU) 사용 효율이 떨어지는 순간이 발생했기 때문입니다.
로그를 분석하면 다음과 같습니다.
| 시간 (Time) | FIFO 스케줄링 | Priority 스케줄링 |
|---|---|---|
| 0 | J1 (Prio:2, GPU:8) 시작 | J2 (Prio:1, GPU:4) 시작 (우선순위가 높으므로) |
| 1 | J2 (Prio:1, GPU:4) 시작 | J1 (Prio:2, GPU:8) 시작 |
| ... | (진행) | (진행) |
| 20 | J1 종료 (남은 GPU: 8) 큐 대기: [J4, J5] J4 (GPU:2) 시작 | |
| 21 | J1 종료 (남은 GPU: 8) | |
| 큐 대기: [J4, J5] | ||
| 21 | 큐에서 우선순위 높은 J5(GPU:8) 시작 | |
| ... | (진행) | (진행) |
| 30 | J2, J3 종료 (남은 GPU: 8) | |
| J4(GPU:2) 시작 |
20에서 21 사이에 두 알고리즘에 차이가 있습니다.
- FIFO의 선택: Time 20에 J1이 끝나자 8개의 GPU가 확보됩니다. FIFO는 큐에 먼저 들어온 J4(GPU 2개 필요)를 바로 실행시켰습니다. 자원을 효율적으로 사용했습니다.
- Priority의 선택: Time 21에 J1이 끝나자 똑같이 8개의 GPU가 확보됩니다. 하지만 Priority 스케줄러는 큐에 있는 작업(J4, J5)들 중 우선순위가 더 높은 J5(GPU 8개 필요)를 실행시켰습니다.
→ 그러나 둘 중 빨리 끝난 FIFO가 무조건 좋다고 할 수는 없습니다. Task의 중요도에 따라 우선시 해야될 수도 있기 때문입니다. 시스템 설계를 할 때 어떤 관점에 초점을 맞출지에 따라 어떤 알고리즘을 선택할지가 달라지게 됩니다.
[추가] Backfilling 알고리즘
백필링(Backfilling) 알고리즘이란?
백필링은 "큐의 첫 번째 작업 시작을 늦추지 않는다면, 뒤에 있는 작은 작업들을 앞으로 당겨와 먼저 실행"하는 기법입니다. 큐가 꽉 막혀있을 때 발생하는 GPU 유휴 시간, 즉 '구멍'을 작은 작업들로 채워 넣어 전체 시스템의 효율을 높이는 것이 핵심입니다.
핵심 아이디어: 테트리스(Tetris)처럼
백필링은 마치 테트리스와 같습니다. 큰 블록(첫 번째 작업)이 내려올 자리를 비워두면서, 그 옆에 남는 작은 공간들을 작은 블록(뒤이은 작은 작업)들로 계속 채워 넣어 빈틈을 없애는 것과 같습니다.
백필링 알고리즘 구현 아이디어 (EASY Backfilling 기준)
가장 기본적인 형태의 'EASY Backfilling' 알고리즘은 다음 논리를 따릅니다.
- 첫 번째 작업(Head of Queue) 우선: 큐의 맨 앞에 있는 작업(
J_first)을 확인합니다. - 자원 확인: 만약 현재 자원으로
J_first를 실행할 수 있다면, 즉시 실행합니다. (이 부분은 FIFO와 동일) - 예약 및 BackFilling 시작: 만약
J_first가 당장 실행될 수 없다면(자원 부족), 시스템은J_first를 위해 자원을 '예약'합니다. - 뒷 작업 검사: 이제 큐의 두 번째 작업부터 순서대로 검사하며 아래 조건을 만족하는 작업을 찾습니다.
- 조건: 이 작은 작업(
J_small)이 지금 당장 시작해서 끝나더라도, 예약된J_first의 시작 시간을 지연시키지 않는다.
- 조건: 이 작은 작업(
- 새치기 실행: 위 조건을 만족하는
J_small을 발견하면, 순서를 무시하고 즉시 실행합니다.
Simulator.java 수정
기존 scheduleFifo, schedulePriority와 같이 scheduleBackfilling 메소드를 새로 만들어 적용할 수 있습니다. 로직은 조금 더 복잡해집니다. 아래와 같이 3 부분을 수정하면 됩니다.
public static void scheduleBackfilling(Queue<Job> jobQueue, GPU_Cluster cluster, List<Job> runningJobs, int currentTime) {
if (jobQueue.isEmpty()) {
return;
}
boolean jobScheduledInThisTick = false;
// 1. 백필링을 먼저 시도 (큐의 두 번째 작업부터)
// 큐를 리스트로 복사해서 순회 (ConcurrentModificationException 방지)
List<Job> potentialBackfillJobs = new ArrayList<>(jobQueue);
if (potentialBackfillJobs.size() > 1) {
for (int i = 1; i < potentialBackfillJobs.size(); i++) {
Job smallJob = potentialBackfillJobs.get(i);
if (cluster.allocateGpus(smallJob)) {
jobQueue.remove(smallJob); // 원본 큐에서 제거
smallJob.startTime = currentTime;
runningJobs.add(smallJob);
System.out.printf("Time %d: %s STARTED (Backfilled).\n", currentTime, smallJob);
jobScheduledInThisTick = true;
break; // 한 타임에 하나만 백필링
}
}
}
// 2. 백필링이 없었다면, 이제 첫 번째 작업을 시작할 수 있는지 확인 (FIFO 방식)
if (!jobScheduledInThisTick) {
Job firstJob = jobQueue.peek();
if (firstJob != null && cluster.allocateGpus(firstJob)) {
jobQueue.poll();
firstJob.startTime = currentTime;
runningJobs.add(firstJob);
System.out.printf("Time %d: %s STARTED (Head of Queue).\n", currentTime, firstJob);
} else if (firstJob != null) {
// 첫 작업이 여전히 대기 중일 때만 메시지 출력
System.out.printf("Time %d: %s is waiting. Checking for backfill candidates...\n", currentTime, firstJob);
}
}
}
.
.
.
// --- 4. 메인 시뮬레이션 루프 ---
System.out.println("--- BACKFILLING Scheduling Simulation START ---");
// TODO: 나중에 Priority로 바꾸려면 이 부분을 schedulePriority로 변경
String schedulerType = "BACKFILLING";
.
.
.
// (3) 선택된 스케줄러 실행
if (!jobQueue.isEmpty()) {
if (schedulerType.equals("FIFO")) {
scheduleFifo(jobQueue, cluster, runningJobs, currentTime);
} else if (schedulerType.equals("PRIORITY")) {
schedulePriority(jobQueue, cluster, runningJobs, currentTime);
} else if (schedulerType.equals("BACKFILLING")) {
scheduleBackfilling(jobQueue, cluster, runningJobs, currentTime);
}
}결과 분석
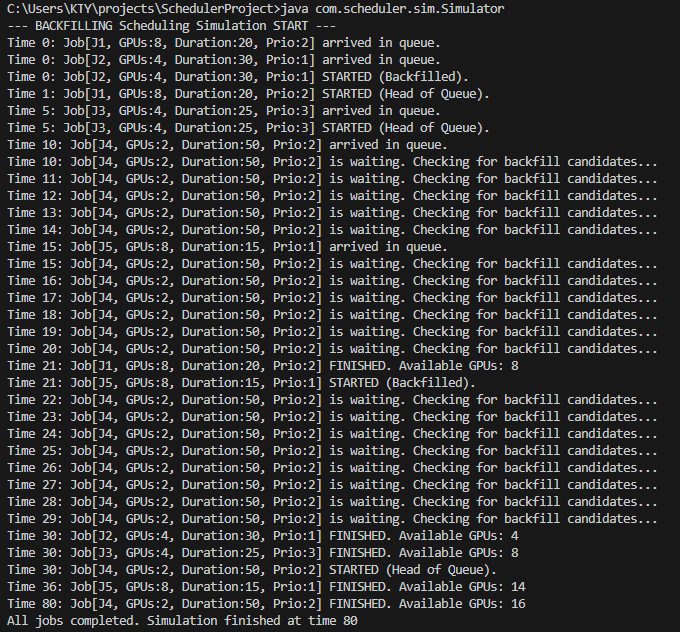
시간만 보면 FIFO보다 10 더걸립니다. 그러나 이 현상은 당연한 현상입니다. 백필링 알고리즘의 목표가 GPU의 사용률을 더 효과적으로 사용하기 때문입니다.
위의 결과에서 실행 시간이 매우 긴 J4가 뒤로 밀렸기 때문입니다.
- FIFO 시나리오
J4는Time 20에 시작해서Time 70에 끝났습니다. 이 작업이 전체 시뮬레이션의 종료 시간을 결정했습니다.
- 백필링 시나리오
Time 0에는J2가J1을 제치고 먼저 시작했습니다 (첫 번째 백필링).Time 21에는J5가J4를 제치고 먼저 시작했습니다 (두 번째 백필링).- 결과적으로
J4는Time 30이 되어서야 시작할 수 있었고,30 + 50 = 80초에 끝나게 되었습니다.
즉, 백필링 알고리즘이 유휴 GPU를 채우기 위해 작은 작업들(J2, J5)에게 새치기를 허용해 준 대가로, 오래 걸리는 J4의 대기 시간이 길어진 것입니다.
→ 결론적으로는 Backfilling 알고리즘은 총 소요시간을 희생해서 GPU 사용률과 평균 응답 시간을 향상 시킵니다.
1. GPU 사용률 (Utilization) - 가장 중요한 목표 달성
백필링의 제1 목표는 비싼 GPU를 단 1초라도 덜 놀게 하는 것입니다.
- 로그를 다시 보시면,
Time 21에 J1이 끝나자마자 단 1초의 지연도 없이J5가 그 자리를 채워 GPU를 100% 사용 상태로 만들었습니다. - FIFO였다면
J4가 시작되고 남은 6개의 GPU는Time 30까지 계속 유휴 상태였을 겁니다.
이것이 백필링의 핵심입니다. 전체 종료 시간이 조금 늘어나더라도, 시스템 전체적으로는 더 많은 시간 동안 더 많은 작업을 처리하게 되어 효율이 높아집니다.
2. 평균 응답 시간 (Average Response Time)
시스템을 사용하는 사용자 입장에서는 어떨까요? 내가 제출한 작은 작업이 빨리 처리되는 것을 선호할 것입니다.
J2는 FIFO에서 1초를 기다렸지만, 백필링에서는 기다림 없이 즉시 시작했습니다.J5는 FIFO에서 15초(30-15)를 기다렸지만, 백필링에서는 단 6초(21-15)만 기다렸습니다.
이처럼 백필링은 시스템의 전반적인 반응성을 높여줍니다.
Backfilling 트레이드오프
결과를 통해 알고리즘의 트레이드오프 중 하나임을 알 수 있습니다.
- 얻은 것 (Gain)
- 높은 자원 사용률: GPU가 쉬는 시간이 줄었습니다.
- 빠른 응답성: 작은 작업들이 더 빨리 처리되었습니다.
- 잃은 것 (Loss)
- 총 작업 시간 (Makespan): 가장 긴 작업(
J4)의 지연으로 인해 전체 종료 시간이 늘어났습니다.
- 총 작업 시간 (Makespan): 가장 긴 작업(
실제 수많은 컴퓨터가 연결된 클러스터 환경에서는 작업 소요 시간보다 자원 사용률과 평균 응답 시간이 훨씬 더 중요한 지표일 때가 많습니다. 그런 의미에서 이번 백필링 시뮬레이션은 아주 성공적이라고 할 수 있습니다.
