[목표]
벨로그 정리
리드미 작성
취업준비
QnA 뽑기
내 Summary Ai 커밋 가져오는 기준 강화 및 정리
welcome 페이지의 코드 품질 검사 수정
postgreSQL을 쓴이유는 무엇인가?
내일 와서 커밋있는 프로젝트 가져와서 잘 출력되는지 확인
12:00 ~ 13:00
식사를 하고 왔다.

13:00 ~ 14:00
차차 현대 오토에버 지원서의 기본 작성항목을 작성하면서 입사지원서를 작성하고 있다.
또한 Welcome 페이지의 소개 내용을 수정하고 있다.
14:00 ~ 15:30
옷을 정리하고 왔다. 부모님하고 전화통화도 하고 왔다.
15:00 ~ 17:30
Welcome페이지 기능 설명과 Summary Ai 가중치 알고리즘을 추가했다.
다음과 같은 내역을 새로 패치했다. 마지막 패치가 될것이다.
25/07/25 Summary Ai에 들어가는 이슈/커밋 데이터 기준(30개)을 가중치 알고리즘에 따라 산정, 핫픽스 태그 시 15점, 댓글 수당 3점, 참여자 수 당 3점, 보드 이슈 우선순위에 따라 0순위부터 20점~1점, 커밋메시지 길이당 0.5점, 커밋 변경당 0.2점 으로 산정하여 높은 가중치부터 30개를 선별합니다.
// 이슈 중요도 계산 함수
function calcIssueImportance(issue: any): number {
let score = 0;
// 1. status가 'story'면 핫픽스 간주
if (issue.status === 'story') {
score += 15;
}
// 2. 제목에 '핫픽스' 또는 'hotfix' 포함 시 가중치 15
if (issue.title && (/핫픽스/i.test(issue.title) || /hotfix/i.test(issue.title))) {
score += 15;
}
// 3. 댓글 수 * 2
score += (issue.commentCount || 0) * 2;
// 4. 참여자 수 * 3
score += (issue.participantCount || 0) * 3;
// 5. position 가중치 (0이면 20, 1이면 19, ... 19면 1, 20 이상이면 0)
if (typeof issue.position === 'number' && issue.position >= 0 && issue.position < 20) {
score += 20 - issue.position;
}
return score;
}
// 커밋 중요도 계산 함수
function calcCommitImportance(commit: any): number {
let score = 0;
score += (commit.title?.length || 0) * 0.5;
if (commit.stats && typeof commit.stats.total === 'number') {
score += commit.stats.total * 0.2;
}
return score;
}
// 이슈별 중요도 계산 및 정렬
const issues = events
.filter(e => e.type === 'issue')
.map(issue => ({ ...issue, importance: calcIssueImportance(issue), tag: (issue as any).tag ?? '', assigneeId: (issue as any).assigneeId ?? '' }))
.sort((a, b) => b.importance - a.importance);
// 중요도 높은 이슈 30개 선정
const topIssues = issues.slice(0, 30);
// top 이슈의 tag값 모음 (tag가 없으면 빈 문자열)
const topIssueTags = topIssues.map(i => (typeof i.tag === 'string' ? i.tag : '')).filter(tag => tag);
// 해당 이슈에 연결된 커밋만 추출 (커밋 메시지 맨 앞이 '#[tag]'로 시작하면 연결된 것으로 간주)
let relatedCommits = events
.filter(e => e.type === 'commit')
.filter(commit => {
return topIssueTags.some(tag =>
commit.title && commit.title.startsWith(`#${tag}`)
);
})
.map(commit => ({ ...commit, importance: calcCommitImportance(commit) }))
.sort((a, b) => b.importance - a.importance)
.slice(0, 30);
// 만약 연결된 커밋이 30개 미만이면, 중요도 높은 커밋을 추가로 채움
if (relatedCommits.length < 30) {
const extraCommits = events
.filter(e => e.type === 'commit' && !relatedCommits.some(c => c.id === e.id))
.map(commit => ({ ...commit, importance: calcCommitImportance(commit) }))
.sort((a, b) => b.importance - a.importance)
.slice(0, 30 - relatedCommits.length);
relatedCommits = relatedCommits.concat(extraCommits);
}위에는 안적었는데, welcome 페이지의 내용도 다음과 같이 수정했다.
!
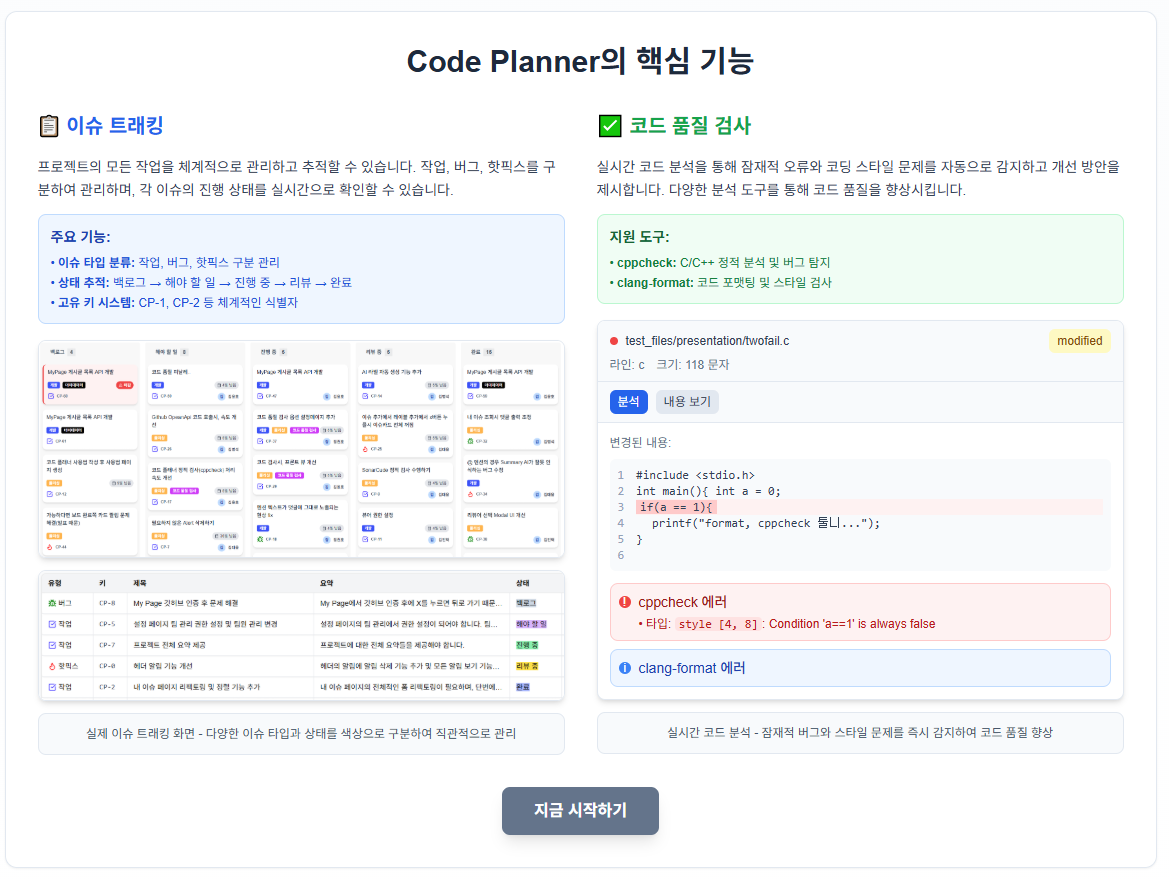
해당 내역을본서버와 오토스케일링 서버 둘다 업데이트 했다.
17:30 ~ 18:00
포스터를 정글 스테이지에 개제하고 왔다.
18:00 ~ 19:00
식사를 하고 왔다.

19:00 ~ 21:00
내일 발표를 위해 Q&A 질문지 리스트와 대본을 외우고 있다.
우선적으로 Q&A를 작성해봐야겠다.
1. Summary Ai의 커밋 30개를 가져오는 로직이 어떻게되나요?
이슈 중요도 산정 방식 개선
핫픽스 이슈 가중치
- 이슈의 status가 'story'이면 15점(핫픽스 간주)
- 이슈 제목에 '핫픽스' 또는 'hotfix'가 포함되어 있으면 15점 추가
- 댓글 수, 참여자 수 가중치
- 댓글 수 × 2점
- 참여자 수 × 3점
- 이슈 우선순위(position) 가중치
- position이 0이면 20점, 1이면 19점, 2면 18점 ... 19면 1점, 20 이상이거나 undefined면 0점
- 최종적으로 위 항목을 모두 합산하여 이슈별 중요도 점수 산출
2. 커밋 중요도 산정 방식
커밋 메시지 길이
- 메시지 길이 × 0.5점
커밋 양
- 커밋 stats.total(변경량) × 0.2점
3. 이슈-커밋 연결 기준
- 커밋 메시지의 맨 앞이 #[tag]로 시작하면,
- 해당 tag가 issue 테이블의 tag 컬럼 값과 일치하는 이슈에 연결된 커밋으로 간주
4. AI 요약에 반영되는 데이터 선정 방식
- 중요도 점수가 높은 이슈 30개 선정
- 각 이슈에 연결된 커밋 중 중요도(메시지 길이, 변경량) 기준 상위 30개 선정
- 만약 연결된 커밋이 30개 미만이면, 남은 커밋 중 중요도 높은 순으로 추가
- 이렇게 선별된 이슈/커밋만 AI 요약 프롬프트에 포함
5. 기대 효과
- 프로젝트의 실제 임팩트가 큰 이슈와 커밋 위주로 요약이 생성됨
- 불필요한 데이터/덜 중요한 작업이 AI 요약에 포함되는 비율 감소
- 토큰/처리시간 효율화 및 요약 품질 향상
2. CI/CD 와 인프라에 대해서 설명해주세요.
이건 포스터보고 잘 설명하면됨.
3. 기여도와 협업 스타일 분석을 어떻게 하나요?
- 알고리즘
ContributionAnalyzer 개요
ContributionAnalyzer는 프로젝트 내 사용자의 다양한 활동 데이터를 단순 집계가 아닌 행동 패턴, 품질, 협업, 시간/요일별 습관까지 다각도로 분석하여 실질적인 피드백을 제공하는 고급 통계·분석 엔진입니다.1. 설계 목적 및 개요
-
목표
- 커밋, 이슈, PR, 댓글 등 모든 활동 데이터를 통합 관리
- 단순 수치 집계를 넘어 ‘협업 스타일’, ‘강점/약점’, ‘개선 제안’ 등 실질적 인사이트 제공
-
핵심 특징
1. 활동 분포 및 패턴 분석
2. 품질 및 협업 지표 산출
3. 자동 스타일 분류 및 개인화된 피드백
2. 주요 분석 로직 및 산출 지표
-
활동량 지표
- 전체 활동량, 고유 활동일수, 일평균 활동량
-
활동 유형별 분포
- 커밋 / 이슈 / PR / 댓글 비율
-
시간·요일 패턴
- 시간대(아침·오후·저녁·밤)별 활동 빈도
- 요일(月~日)별 활동 분포
-
품질 지표
- 커밋 메시지 품질 (길이, 컨벤션 준수)
- 이슈 완료율 (Closed 비율)
- PR 머지율 (closed=merged 가정)
- 평균 응답 시간 (이슈 생성→첫 댓글)
-
협업 지표
- 댓글 참여도
- 타인 이슈 참여 비율
- 팀원 간 상호작용 (유니크 author 수)
-
자동 스타일 분류
- 코드 중심형 / 이슈 중심형 / 소통 중심형 / 균형형 / 개별형
-
피드백 생성
- 각 지표별 강점·약점 진단
- 개인화된 개선 제안
3. 기술적 챌린지 및 해결 방안
챌린지 해결 방식 비고 정확한 활동 분류 공통 필드(author, createdAt, status) 표준화 통합된 ActivityData 사용 품질·패턴 분석 한계 - 메시지 품질: 단순 길이·컨벤션 체크- PR 머지율: closed=merged 가정 실제 맥락·merged 여부 반영 어려움 시간·요일 패턴 왜곡 JS Date변환 후 카운트타임존 이슈 예외 처리 로직 도입휴일·샘플 부족 시 편향 가능성 존재 협업 깊이 측정 한계 유니크 author 수로 근사 정성적 상호작용 깊이 미반영 응답 시간 산출 예외 처리 댓글 없는 이슈, 중복 댓글 필터링최초 댓글 시점 사용 실제 커뮤니케이션 질 반영 어려움 데이터 불균형·샘플 부족 최소값·최대값 하드캡, 빈 메트릭 반환 신뢰도 저하 시 결과 가중치 적용 필요
4. 실무적 한계 및 향후 개선 포인트
-
한계
- 커밋 메시지·PR 머지율 등 지표가 프로젝트 문화에 따라 달라짐
- 네트워크 깊이·정서적 요소(감정, 톤) 미반영
- 시간·요일 패턴이 외부 요인(휴일, 타임존)에 민감
-
개선 방향
1. 자연어 처리 기반 커밋·이슈·댓글 내용 심층 분석
2. 실제 머지 여부, 리뷰·코멘트 등 PR 상세 데이터 활용
3. Network Analysis: 팀원 간 상호작용 네트워크·감정 분석
4. 계량 지표에 신뢰도 가중치 적용
5. 요약
ContributionAnalyzer는 단순 집계를 넘어 사용자의 활동 패턴·품질·협업 관계를 종합 분석하여, 개인화된 협업 스타일 분류와 구체적인 개선 제안을 제공합니다. 다만, 현재 지표가 지닌 한계(정성적 요소 미반영, 데이터 편향 등)를 극복하기 위해 자연어 처리, 네트워크 분석, 정성적 데이터 가중치 등의 기술 고도화가 필요합니다.
-
4. 왜 하나의 EC2에 프론트와 백엔드를 올렸나요?
- 운영 효율성
- 장점:
- 초기 환경 구축이 단순하고, 서버 수가 적어 운영·모니터링 부담이 낮음
- 방화벽, 로깅, 백업 같은 공통 인프라를 한 번만 설정하면 됨
- 단점:
- 설정 변경 시 프론트·백엔드 모두 재배포가 필요해 중단 범위가 넓어짐
- 장점:
- 성능 및 자원 분리
- 단점:
- CPU·메모리를 프론트엔드 정적 파일 서빙과 API 처리에서 동시에 공유 ⇒ 한 쪽 부하가 높으면 다른 쪽 성능 저하
- 트래픽 급증 시 스케일링 단위가 서버 전체이므로 비용 효율적이지 않음
- 단점:
- 확장성(Scalability)
- 단점:
- 트래픽 패턴이 다른 두 애플리케이션을 개별적으로 수평 확장 불가능
- 프론트엔드는 CDN·정적호스팅, 백엔드는 오토스케일링 그룹 등 별도 확장 전략 적용 어려움
- 단점:
- 보안 경계(Isolation)
- 단점:
- 취약점 발생 시 서버 전체가 노출될 위험
- 권한 분리(예: 백엔드만 DB 접근)를 EC2 내부 네트워크 수준에서만 구현해야 해 설정 복잡도 증가
- 단점:
- 배포 및 CI/CD 파이프라인 복잡도
- 단점:
- 단일 서버에 두 애플리케이션을 함께 배포하면, 각각의 배포 스크립트가 서로 충돌할 가능성
- 롤백 시점이 달라졌을 때 복구가 번거로움
- 단점:
- 유지보수 및 운영 분리
- 단점:
- 프론트엔드 개발자와 백엔드 개발자가 서로 다른 스택(웹서버 vs. 애플리케이션 서버) 관리를 동시에 해야 함
- 로깅·모니터링 도구를 분리 설정하기 어려워, 장애 원인 분석 시 혼선 발생
- 단점:
- 비용 관점
- 장점:
- 작은 프로젝트나 PoC 단계에서는 인스턴스 비용을 절감할 수 있음
- 단점:
- 트래픽이 늘어날 경우, 프론트엔드만 CDN + 정적호스팅으로 분리하면 더 저렴한 운용이 가능
- 장점:
21:00 ~ 21:40
긴급한 서버 에러를 고치다.
권호형이 갑자기 서버가 500에러가 걸린다고 해서, 문제를 추적했다.
서버 로그에는 정상으로 출력되는데, 500 에러 창이 떠서 확인을 해보았다.
오토스케일링 서버에 혹시 몰라 main pull을 해봤는데, 변경 내역을 가져왔다. 어제 새로 npm을 실행하기만 하고, 업데이트를 안한 것이었다. 그래서 새롭게 패치하고 프로세스를 재실행했다.
이후에 혹시 몰라 오토스케일링도 제거하고 다시 연결하고, CloudFront도 무효화를 진행했다.
→ 조치한 결과 아직까지는 오류가 발생하지 않는다. 미리 찾아서 다행이다… 시연때 그랬으면, 생각만해도 끔찍하다.
21:40 ~ 01:00
PPT와 대본을 약간 수정하였다. 시뮬레이션 해보고 더 축약할지 고민해봐야겠다.
시연용 노트북 가져가자. 세팅 한 8번 정도한것 같다.
연습을 한 후에 잘 안외워지거나, 불편한 대본 부분은 수정했다. PPT 또한 조건과 내용에 부합하게 수정했다.
