
데이터활용능력 (Lv.1 SQL 이론) - 참고자료
패스트캠퍼스 실습 코치님이 제공하는 참고자료 (slack)
1. SQL이란 무엇인가요?
SQL이 무엇인지 쉽고 간단하게 소개하는 아티클
AWS - SQL이란 무엇입니까?
https://aws.amazon.com/ko/what-is/sql/
2. Oracle과 MySQL의 차이점
SQL을 공부하시다 보면 오라클과 MySQL의 차이점에 대한 궁금증을 해결하는 아티클
Oracle과 MySQL의 차이점
https://velog.io/@alicesykim95/Oracle%EA%B3%BC-MySQL%EC%9D%98-%EC%B0%A8%EC%9D%B4%EC%A0%90
3. 데이터베이스 JOIN
데이터 관리에서 중요하다고 할 수 있는 JOIN에 대해 간단히 소개하는 아티클
DB JOIN 정리 (INNER/LEFT/RIGHT/OUTER)
https://pearlluck.tistory.com/46
4. 데이터 리터러시
데이터 리터러시가 무엇이고, 화해에서는 어떻게 데이터를 활용하고 있는지 살펴보는 아티클
데이터 리터러시(Data Literacy)를 올리는 방법 - 화해 기술 블로그
http://blog.hwahae.co.kr/all/tech/tech-tech/9757/
5. A/B Test
당근마켓에서 데이터를 통해 어떻게 실험을 진행하고 있는지에 관한 아티클
1주 1개 실험하는 프로덕트 팀이 되는 여정
https://medium.com/daangn/1%EC%A3%BC-1%EA%B0%9C-%EC%8B%A4%ED%97%98%ED%95%98%EB%8A%94-%ED%94%84%EB%A1%9C%EB%8D%95%ED%8A%B8-%ED%8C%80%EC%9D%B4-%EB%90%98%EB%8A%94-%EC%97%AC%EC%A0%95-b8a4c337a8e1
6. WHERE절
SQL에서 WHERE절은 조건을 설정하는 절로, 조건 설정을 통해 원하는 데이터를 추출할 수 있다.
WHERE절에 대해 잘 정리된 아티클SQL - WHERE절 (조건 설정)
https://woochan-autobiography.tistory.com/577
7. EDA
데이터 분석의 기본은 EDA(Exploratory Data Analysis, 탐색적 데이터 분석)라고 할 수 있다.
EDA를 통해 처음 보는 데이터 안에서 숨어있는 인사이트를 찾아낼 수 있는데, EDA가 무엇인지, 어떻게 하는지에 대한 아티클데이터분석 기초 - EDA의 개념과 데이터분석 잘하는 법
https://jalynne-kim.medium.com/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%84%9D-%EA%B8%B0%EC%B4%88-eda%EC%9D%98-%EA%B0%9C%EB%85%90%EA%B3%BC-%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%84%9D-%EC%9E%98-%ED%95%98%EB%8A%94-%EB%B2%95-a3cac2cc5ebc
8. 데이터 전처리
정확한 데이터 분석을 위한 과정
탐색적 데이터 분석(EDA)라고 불리우는 단계에서 수행해야 할 Task에 대해 순서대로 정리
9. SQL 집합 연산자
- 합집합 연산자 (UNION, UNION ALL)
- 교집합 연산자 (INTERSECT)
- 차집합 연산자 (EXCEPT)
10. SQL 윈도우 함수
행과 행 간의 관계를 쉽게 정의하기 위해 만든 함수가 윈도우 함수다.
윈도우 함수는 분석 함수나 순위 함수로도 알려져 있다.
윈도우 함수는 기존에 사용하던 집계 함수도 있고, 새로이 윈도우 함수 전용으로 만들어진 기능도 있다.
윈도우 함수는 다른 함수와 달리 중첩해서 사용은 못하지만, 서브쿼리에는 사용할 수 있다.
11. SQL 그룹 함수와 GROUP BY
각종 집계함수, 그룹함수와 함께 쓰이며 그룹화된 정보 제공
https://velog.io/@mindddi/SQL%EA%B7%B8%EB%A3%B9%ED%95%A8%EC%88%98-%EA%B7%B8%EB%A3%B9%ED%95%A8%EC%88%98%EC%99%80-GROUP-BY
https://blog.naver.com/regenesis90/222179953582
12. 서브쿼리(SubQuery) 종류 및 사용법
오라클에서 쿼리문을 작성하다보면 서브 쿼리를 자주 접하게 된다. 서브 쿼리는 메인 쿼리 내부에 작성하는 쿼리를 뜻하며, 주로 아래의 3가지 서브 쿼리로 분류한다.

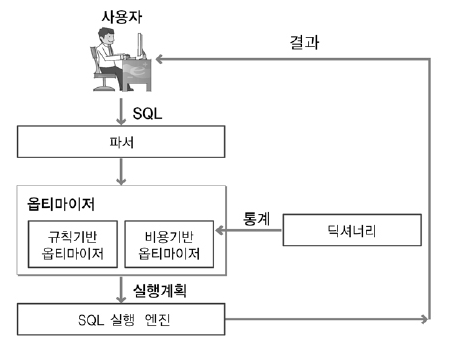
13. 데이터베이스 옵티마이저에 대하여
옵티마이저는 가장 효율적인 방법으로 SQL을 수행할 최적의 처리 경로를 생성해주는 DBMS의 핵심엔진이다. 컴퓨터의 두뇌가 CPU인 것처럼 DBMS의 두뇌는 옵티마이저라고 할 수 있다. 개발자가 SQL을 작성하고 실행하면 SW 실행 파일처럼 즉시 실행되는 것이 아니라 옵티마이저라느 곳에서 "이 쿼리문을 어떻게 실행시키겠다!"라는 여러가지 실행계획을 세우게 된다. 이렇게 실행계획을 세운 뒤 시스템 통계정보를 활용해 각 실행계획의 예상비용을 산정 후 각 실행계획을 비교해서 최고의 효율을 가지고 있는 실행계획을 판별한 후 그 실행계획에 따라 쿼리를 수행하게 된다.
14. SQL INDEX 뜻과 원리 (Oracle, MS-SQL)
인덱스란 검색 속도를 높이기 위해 사용하는 하나의 기술로, 해당 테이블의 컬럼을 색인화하여 검색 시 해당 테이블의 레코드를 FULL SCAN하는 것이 아니라 색인화되 있는 인덱스 파일을 검색하여 빠르게 검색한다.
15. JOIN 수행 원리
조인이란 두 개 이상의 테이블을 하나의 집합으로 만드는 연산이다. SQL문에서 FROM 절에 두 개 이상의 테이블이 나열될 경우 조인이 수행된다. 조인 연산은 두 테이블 사이에서 수행된다. FROM 절에 A, B, C라는 세 개의 테이블이 존재하더라도 세 개의 테이블이 동시에 조인이 수행되는 것은 아니다. 세 개의 테이블 중에서 먼저 두 개의 테이블에 대해 조인이 수행된다. 그리고 먼저 수행된 조인 결과와 나머지 테이블 사이에서 조인이 수행된다. 이러한 작업은 FROM 절에 나열된 모든 테이블을 조인할 때까지 반복 수행한다. 예를 들어, A, B, C 세 개의 테이블을 조인할 때를 가정으로 설명하면 다음과 같다. 먼저 A와 B 두 테이블을 먼저 조인하면 해당 조인 결과와 나머지 C 테이블을 조인한다(A → B → C). 만약, A와 C 테이블을 먼저 조인한다면 해당 조인 결과와 나머지 B 테이블을 조인한다(A → C → B). 테이블 또는 조인 결과를 이용하여 조인을 수행할 때 조인 단계별로 다른 조인 기법을 사용할 수 있다. 예를 들어, A와 B 테이블을 조인할 때는 NL Join 기법을 사용하고 해당 조인 결과와 C 테이블을 조인할 때는 Hash Join 기법을 사용할 수 있다. 조인 기법은 두 개의 테이블을 조인할 때 사용할 수 있는 방법이다. 여기서는 조인 기법 중에서 자주 사용되는 NL Join, Hash Join, Sort Merge Join에 대해서 조인 원리를 간단하게 설명한다.
16. SQL 최적화 및 성능 튜닝
https://qwefgh90.github.io/sphinx/database/sql_optimize.html
SQLD 종료 후 복습기간중...
