NNDR(Nearest neighbor distance ratio)
유사점이 가장 높은 매치/두번쨰로 높은 매치
NNDR(Nearest Neighbor Distance Ratio)은 객체 인식이나 매칭 문제에서 사용되는 중요한 지표 중 하나입니다. 이는 주로 특징 기반 매칭에서 사용됩니다.
NNDR은 다음 두 단계로 이루어집니다:
가장 가까운 이웃 찾기 (Nearest Neighbor Search): 각 특징점에 대해, 다른 이미지에서 가장 유사한 특징점을 찾습니다. 이를 통해 두 이미지에서 각 특징점의 대응 관계를 수립합니다.
NNDR 값 계산: 각 특징점마다 가장 가까운 이웃과 두 번째로 가까운 이웃의 거리를 비교합니다. 이 거리 비율을 NNDR로 계산합니다.
NNDR은 다음과 같은 식으로 나타낼 수 있습니다:
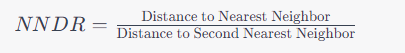
Distance to Nearest Neighbor
Distance to Second Nearest Neighbor
NNDR=
Distance to Second Nearest Neighbor
Distance to Nearest Neighbor
일반적으로 NNDR 값이 낮을수록 더 좋은 대응이라고 볼 수 있습니다. 왜냐하면 가장 가까운 이웃과의 거리가 두 번째로 가까운 이웃과의 거리보다 더 짧아야 더 신뢰할 수 있는 매칭으로 간주할 수 있기 때문입니다.
NNDR은 객체 인식에서 사용될 때, 특히 SIFT, SURF 등의 특징을 사용하여 매칭하는 과정에서 중요한 역할을 합니다. 이를 통해 올바른 대응을 찾아내고, 잘못된 대응을 걸러내는 데 도움이 됩니다.
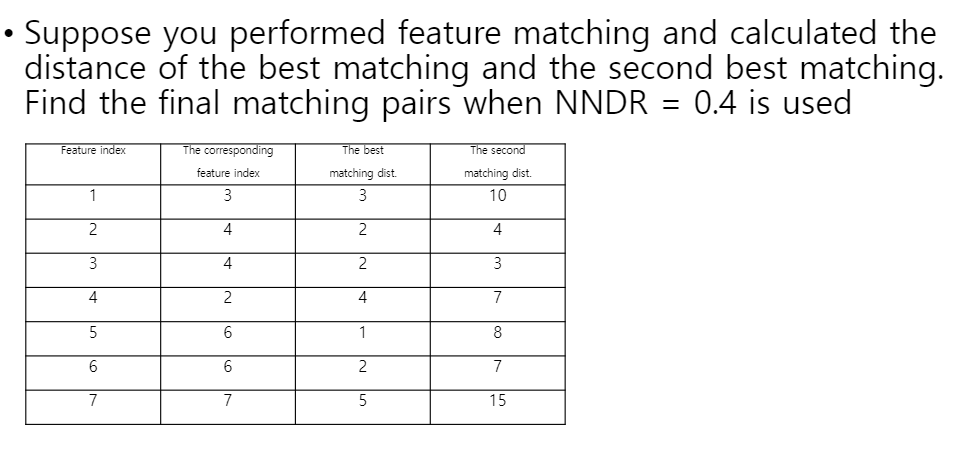
1,5,6,7이 정답.
거리가 2인 index2와 거리가 5인 index7을 보면서 뭔가 합리적이지 않아보이기도 한다. 그러나 보완하는 알고리즘을 발명하면 된다.