
신뢰할 만하고
byte byte를 오류없이 순서에 맞게 전송한다.
message boundaries를 유지하지 않는다. byte를 오류 없이 순서에 맞게 전달하는 게 주 관심이다. 반면 UDP는 boundary를 유지한다. 이 개념을 이해하지 못하면 socket programming에 오류를 발생시킨다.
Flow Control : sender에게 내가 남은 size가 몇인지 알려준다. receiver buffer의 overflow를 막는다.
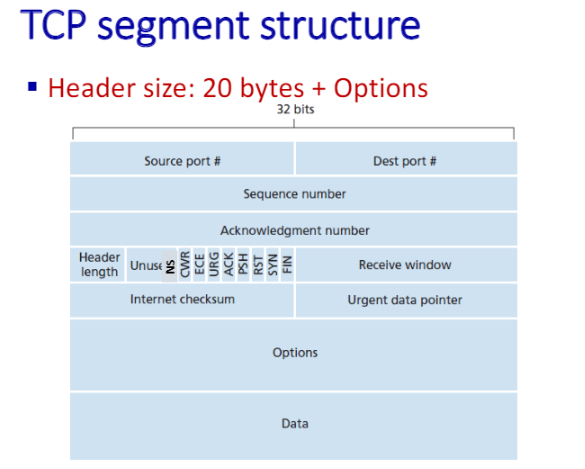
TCP는 옵션 때문에 가변적인 크기이다. Data를 제외하고 전부 header, data가 payload이다. 보통 오버헤드가 40바이트다, 라고 할 때 20 + 20인데, 각각 TCP의 최소값, IP의 최소값이다.
UDP랑 똑같은 부분은 Sour port#, Dest port#이다.
sequence number 와 ack number은 ARQ를 위해 존재한다. sequence number는 32bit크기이다. 왜 이리 큰가? -> 트랜스포트 레이어이기 때문에 round를 한바퀴 돌아서 중복될 가능성을 줄이기 위해.
header length : udp는 8byte로 헤더사이즈가 고정되어 있다. 반면에 TCP는 가변적이기 때문에 알려줘야 한다. 그걸 알려줘야 어디서부터 payload가 시작되는지 알 수 있다. header length는 4bit이다. ECN : explicit congestion notifier. 현재 TCP는 congestion control 할 때 implicit(묵시적, 추정적)으로 예상해서 알고리즘을 돌린다. 이 방법은 오류의 가능성이 있다. 그것을 방지하려고 ECN 메커니즘이 나온 것이다.
URG : urgent한 데이터를 보내야 한다. 기존의 버퍼에 있는 데이터보다 먼저 보내게 된다. urg가 1이 되고 하단에
ack : ack가 1이 되면
syn : handshaking / 처음에 내가 너한테 데이터를 보낼 때 이니셜 sequence number?
fin : connection establishment를 하고 realise할 때, 나 다 보냈어!
receive window : 나에게 남은 receive buffer size가 얼마야. sender는 그것 이상으로 보내지 못 한다.

시퀀스 넘버를 바이트마다 할당시킵니다. 한 바이트에. 바이트마다 넘버링이 있다고 하면 시퀀스 넘버가 여러개 있는데 헤더에 시퀀스넘버를 뭘로 해야 하나..? 그래서 첫번째 바이트에 시퀀스 넘버를 줘서 전송하게 된다. 그리고 SYN bit field가 1인 경우에 그건 이니셜 시퀀스 넘버가 된다.
ack 1000번이다? 나는 999까지는 다 받았다 라는 의미. 999만 받았다는 의미가 아님.
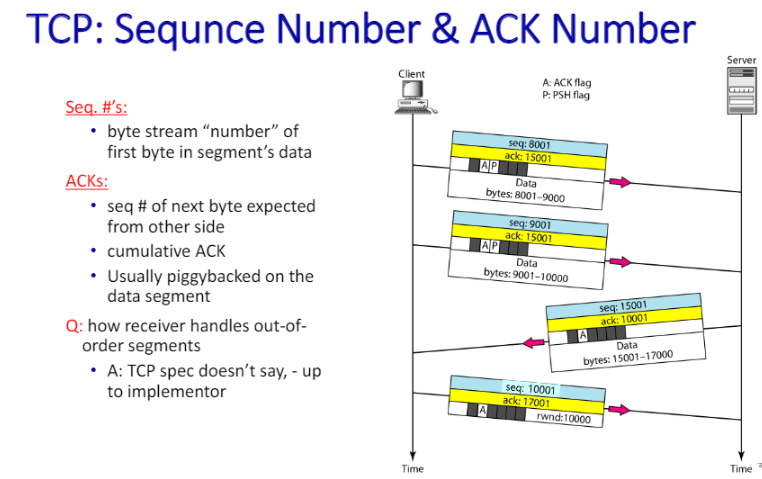
ack

SYN 1 ACK 0 이면 첫 packet이다. 두번쨰 회신은 ack가 있고 나는 squence를 뭘로 할게 이런 거임. 그러니까 각각 1번째 핸드쉐이킹, 2번째 핸드쉐이킹이라는 것.

헤더 사이즈는 0~15 * 4라고 보면 된다. max는 60byte까지 윈도우 사이즈를 통해 플로우 컨트롤을 한다. 센더에게 window size를 저만큼 받으면 ack된다.
체크섬은 header, data, pseudo-header 프로토콜남바 TCP 는 6, UDP는 17

HSN high speed쪽에서 추가된 옵션이 있다.

Timeout은 TCP에서 ARQ에서 loss발생시 필요. 기본적으론 RTT이후에 TImeout이 걸린다. 데이터를 보내고 ack가 올때까지가 RTT. 이것보다 빨리 돌면 쓸데없이 데이터를 재전송한다. TCP는 transport layer이고 중간에 많은 network를 거쳐가기 때문에 그 상황에 따라 변동이 엄청 심하다. worst case보다 더 크게 잡으면 된다. 그러면 쓸데없는 timeout이 안발생한다. 그러나 너무 길게 잡으면 쓸데없이 노는 시간이 많아진다. 그 사이의 적절한 선이 필요하다. 난감하당. 그래서 timeout값을 고정하는 것이 아니라 dynamic, adaptive하게 만들게 된 것. 계속 측정을 해서 현재 RTT가 얼마인지 추정을해서 timeout값을 바꿔가는 알고리즘을 사용했다는 것!

평균 값을 추정해내는데 각 값을 동일한 중요도가 아니라 weighted하게 해서 가까운 시점의 중요도를 높여서 평균을 구하는 방법이 있다.
wating의 합은 1이 돼야.
현재 측정을 1/8로 주고 과거를 7/8로 주는것. 현재 값은 다음으로 가면 estimatedRTT로 간다. 1/8에서 (7/8)^a 만큼 급속히 그 중요도가 낮아진다.
재전송 시에는 sampleRTT는 배제가 된다. 잘못된 추정치가 생길 수 있기 때문(사진찍음)
왜 1/8??? shift right 3번 하면 끝!간단하니까!
실제 타임 아웃은 EstimatedRTT에 2배 정도가 적당
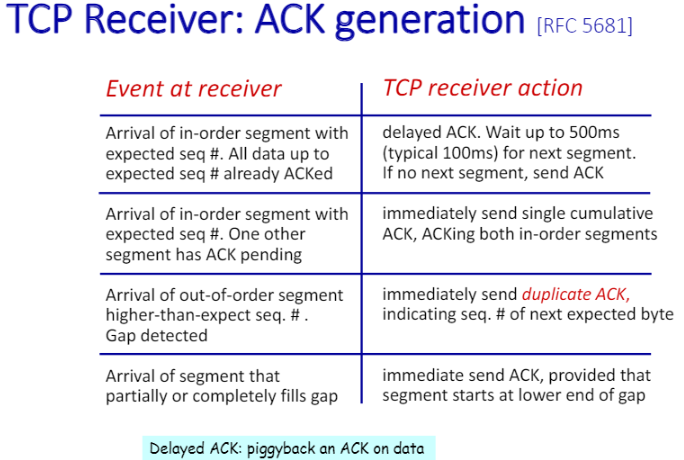
음 평균을 잘 따라가는군
평균의 두배는 좀 많지 않나..?그래서 저기에 루트를 씌우면 어떨까..? 하지만 계산양이 많으니까 전체 절대값의 ... 루트를 씌우면 덧셈만 남으니까..?
세그먼트가 아니라 바이트마다 sequence번호가 할당되서 사용된다. send window size가 가변적이다. ack가 누적적이다. ack를 줄 때 number는 다음 expected value로 준다. 재전송을 할 때는 timeout발생 시. acks가 세개가 발생하면 다시 발생.
ack은 헤더가 없고 데이터만 날라간다. 가능하면 같이 보내면 좋다. 효율적인 측면에서. 그래서 바로 ack을 보내는 게 아니라 들어온 데이터와 함께 보내는 것. 그게 delayed ack의 의미. 그렇다고 한도끝도 없이 기다릴 순 없다.
보낼 데이터가 올 떄까지 기다리는데 다음 데이터가 sender에서 도착하면 이미 있는 ack이랑 이제 출발할 데이터랑 같이 출발시키는 것(가변적이라서 가능한 것)
자신이 기다린 것보다 더 높은 번호일 경우 즉시 보낸다.
갭을 채웠다? 받는 쪽에서 갭이 있었다. 그 갭에 대한 packet이 도착하면 그게 채워지고 거기로 ack을 보낸다. ..?/ 정상적으로 진행될때만 delayed ack이 발생한다고 이해하면 될 듯. 나머지는 상황에 맞게 즉시 보내는 것으로 알면 된다.
