Beam Search
Greedy Decoding
- 매 time step마다 가장 높은 확률을 가지는 단어 하나만 택해서 decoding 진행

- 이전으로 돌아갈 수 없기 때문에 최적의 예측값이 나오지 못함
Exhaustive Search
- 모든 경우에 대해 일일이 다 계산하고 고려함
- 동시 사건에 대한 확률 분포
- : 출력 문장, : 입력 문장
- : 첫 번째 단어
- 생성 후 생성
- 최대한 높은 확률을 가지는 를 뽑는 것이 최선
- 첫 번째 단어가 틀리면 뒤에 아무리 test해도 높게 나오지 않음
Beam Search
- exhaustive과 greedy의 중간과 같은 방법
- decoder의 매 time step마다 미리 정해둔 k개만큼의 가짓수 고려하고 그 안에서 제일 확률값이 높게 나온 것 사용
- : beam size - Beam Search는 전체에 대한 최적 값을 찾기에는 아직 부족
- Exhaustive Search보다는 효율적
Beam Search : Example
- Beam Size :
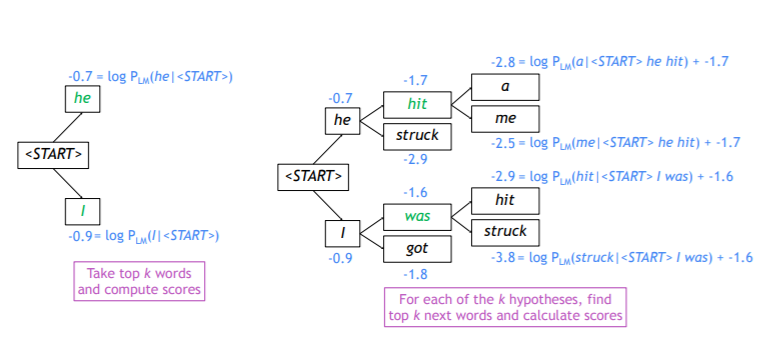
- 2 개를 예측하고, 각각 확률분포값이 높은 2 개를 뽑음
- 확률값은 0에서 1 사이 값이나, 를 씌웠기 때문에 계산값이 음수로 나옴
- 각각의 경우에 대해 다음 단어 예측
- 개에서 개를 고려하기 때문에
- 이번 거 나올 확률 + 이전 거 나올 확률 계산
- 반복적으로 decoding 과정 수행함으로써 나온 결과
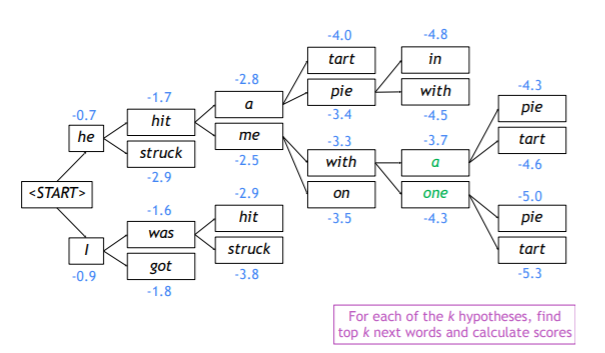
Beam Search : Stopping Criterion
- Greedy Decoding에서는 < End > token나올 때까지 진행
- Beam Search Decoding에서는 < End > token이 각각 다른 time step에서 나옴
- 특정 hypothesis에서 < END > token 생성한 것은 그 경로에 대해서는 더 이상의 생성 과정이 없다는 것을 의미
- 완성된 hypothesis는 임시로 다른 저장공간에 저장 - 보통 Beam Search는
- 시작할 때 지정해둔 time step 값에 도달할 때까지 진행
- 완료된 hypothesis의 개수가 미리 지정해둔 값에 도달할 때까지 진행
Beam Search : Finishing Up
- 위와 같은 식으로 진행했을 경우, 단어가 많이 생성될 수록 확률값이 낮아짐
- 해결 위해
- 사용함으로써 평균 확률값으로 score를 부여
BLEU Score
Precision and Recall
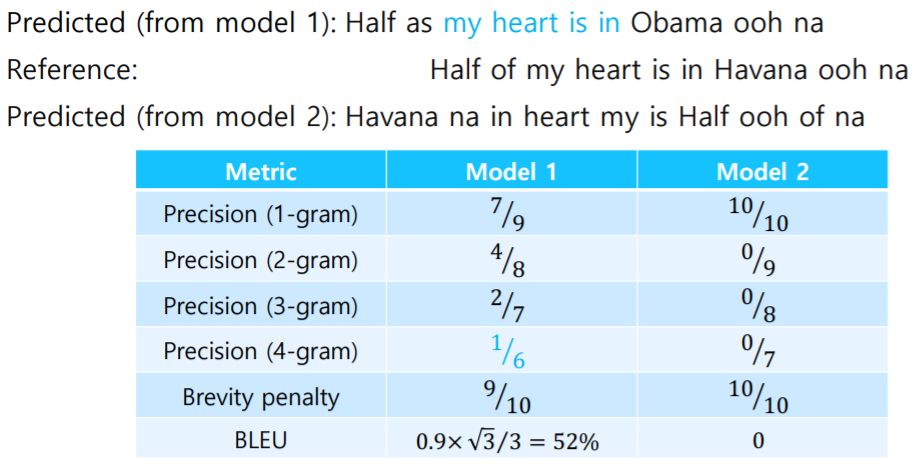
- Reference : Half of my heart is in Havana ooh na na
- Predicted : Half as my heart is in Obama ooh na
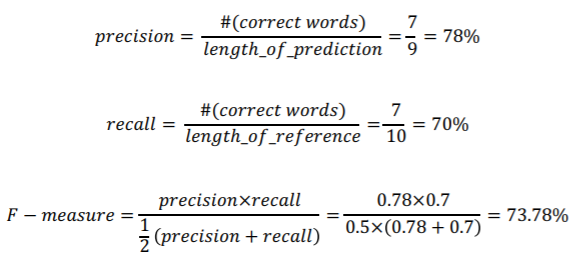
- : 정밀도. 예측된 결과가 노출되었을 때 실질적으로 느끼는 정확도
- keyword로 검색했을 때 나오는 결과의 정확도 - : 재현율. 원래의 의도에 부합하는 정보의 총 개수에서 얼마나 사용자에게 잘 노출시켜주었는가
- : 조화평균. 작은 값에 더 치중됨
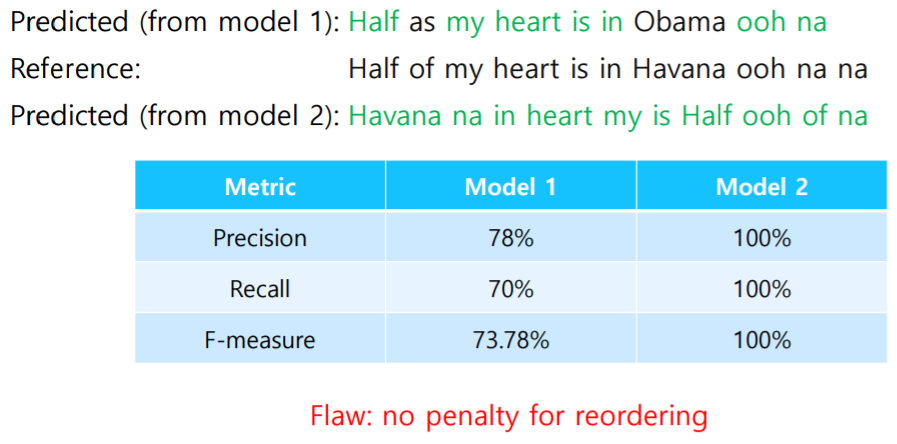
- Model 1 : 순서로 단어 위치와 정확도를 파악
- Model 2 : 각각의 단어가 원래의 문장에 포함되어있는지 파악
BLEU Score
- BiLingual Evaluation Understudy
- 개별 단어 level에서 봤을 때 얼마나 공통적으로 ground truth와 겹치는 단어가 나왔느냐에 대한 계산
- N-gram overlap(N개의 연속된 단어가 ground truth와 얼마나 겹치는가)를 machine translation의 output과 reference sentence 사이에서 계산
- 1-gram : 개별 단어를 단위로
- 2-gram : 2개의 연속된 단어를 단위로 ... - N-gram의 size를 1부터 4까지로 두고 그 때의 precision 계산
- recall의 최댓값으로 작용하는 brevity penalty 적용
- reference 길이보다 더 짧은 문장 생길 경우 대비
- 문장 짧아질수록 기하평균의 값 작아짐

- 보통 corpus의 단위로 계산됨

세진니의 눈물 가득 블로그