Seq2Seq with attention, Encoder-decoder architecture, Attention mechanism
Seq2Seq Model
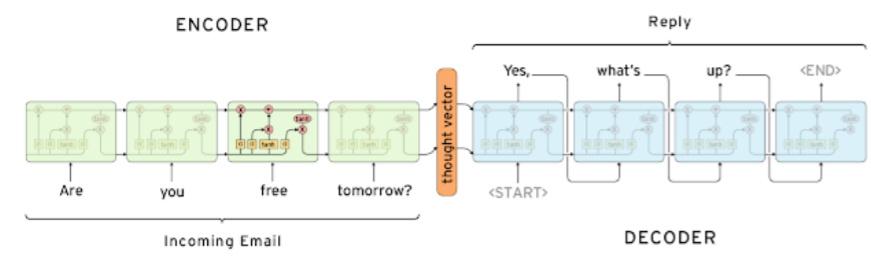
- input으로 연속된 단어를 받고, output으로 연속된 단어를 내보냄
- encoder와 decoder로 구성
-Encoder
- RNN model로써 LSTM을 사용
- 공통된 parameter를 매 time step마다 사용
- input의 마지막 hidden state vector로 decoder와 연결 - Decoder
- < SOS > : Start Of Sentence token
- < EOS > : End Of Sentence token.
- 순차적으로 예측하는 단어 출력
- < SOS >부터 < EOS >가 들어올 때까지 진행
- 별개의 RNN model로 decoder 구성 - 입력을 받은 후 시간이 지나면 유실될 가능성 있음
Seq2Seq Model with Attention
- 기존의 model 사용하면 hidden state vector의 dimension이 RNN의 특성상 항상 고정되어있다는 특성 때문에 훨씬 이전에 나왔던 정보들이 변질되거나 손실될 수 있음
- Attention은 bottleneck problem(수행 과정에서의 병목)을 해결
- 그때 그때 필요한 encoder의 hidden state vector를 이용하는 decoder를 매 time step에서 사용함으로써, 각 state에서 나온 hidden state vector에 집중
- attention 분산을 사용함으로써 encoder의 hidden state에서 가중합 구함
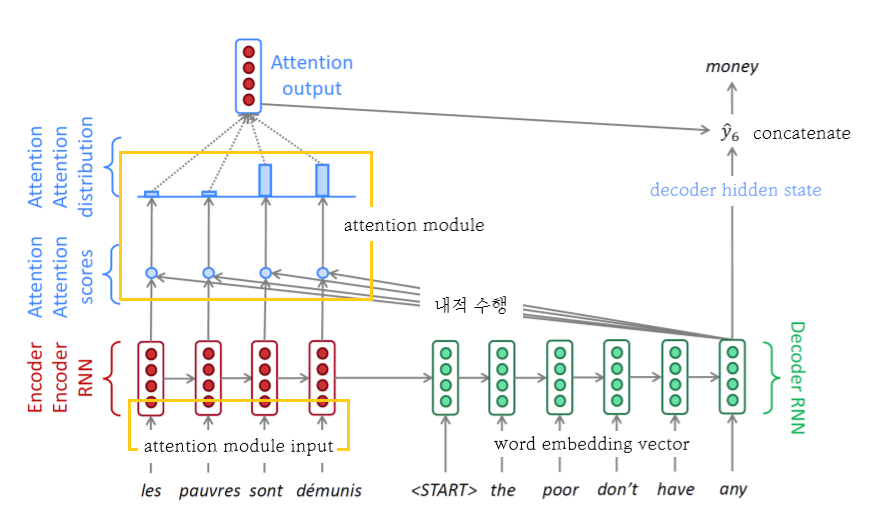
-
attention module의 input은 encoder에서의 각 hidden state vector
-
decoder의 input은 해당 time step에서의 word embedding vector
-
encoder 거친 input은 decoder 거친 hidden state vector와 내적 수행
- decoder의 hidden state vector는 어떤 단어 vector를 중점적으로 가져와야할지에 대한 정보 가지고 있음
-
attention scores는 계산된 내적값에 기반한 유사도 나타냄
-
attention distribution은 softmax 거친 확률값
- 이 값은 encoder에 가중치로 적용됨
-
가중평균 이용하여 하나의 encoding vector, Attention Output 나옴
- attention의 output은 보통 높은 attention을 받은 hidden state의 정보를 포함하고 있음
-
attention output 값과 decoder hidden state을 concatenate하여 output layer의 input으로 넣음으로써 다음에 나올 단어 예측
-
최종 output : 특정 time step에서의 예측값
-
위의 과정 반복함으로써 계속해서 다음 단어 예측
-
Backpropagation 수행
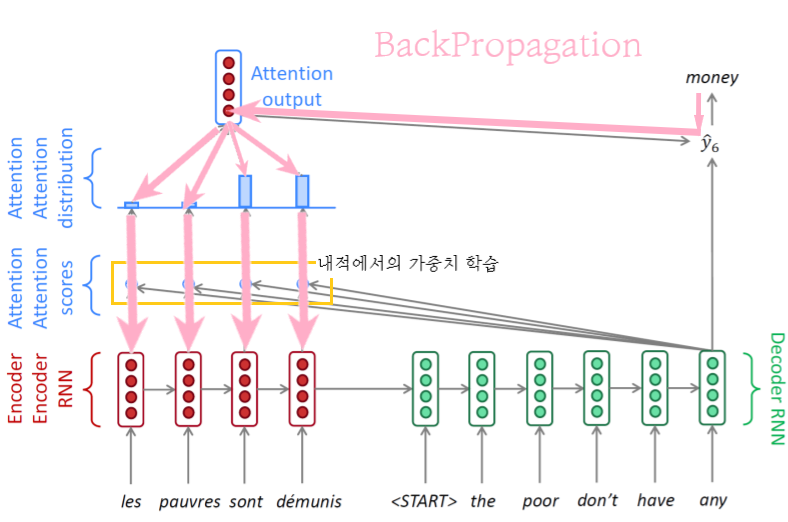
그림이 좀 더럽네 -
teacher forcing을 이용함으로써 매 time step마다 올바른 input만 넣어줌
- 예측이 잘못되더라도 ground truth에서의 단어를 입력으로 주어줌 -
어느정도 시간이 지난 뒤 예측이 충분히 정확해졌을 경우 teacher forcing 거친 값이 아닌, output 값 사용
Different Attention Mechanisms
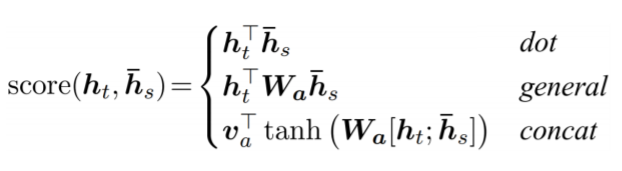
- : 와 사이 유사도 검사 위함
- : decoder에서 주어지는 hidden state vector
- : encoder에서 주어지는 각 word별로의 hidden state vector
- : 일반적인 내적 수행
- : 일반화된 내적 수행함으로써 가중치 이용
- 같은 dimension 가지는 vector들 간에 주어지는 가중치 이용 - : decoder/encoder의 hidden state vector를 input으로 두고 fully connected layer를 거치거나 layer 적층하도록 함
- : 의 결과로 scalar값이 나오기 때문에 vector로 표현하기 위함
- : 첫 번째 layer의 선형 변환 위한 matrix
Attention is Great!
- Attention을 이용함으로써 NMT(기계 번역) 성능 향상
- decoder가 특정 영역에 집중할 수 있음 - 긴 문장에 대해서 번역이 어려운 문제를 해결 (bottleneck problem)
- vanishing gradient problem 해결함으로써 gradient를 빠르게 전달 가능
- 해석 가능성 제공
- attention distribution 통해 어떤 단어에 집중했는지 확인 가능
- 언제 어떤 단어를 사용해야하는지 스스로 학습
Attention Examples in Machine Translation
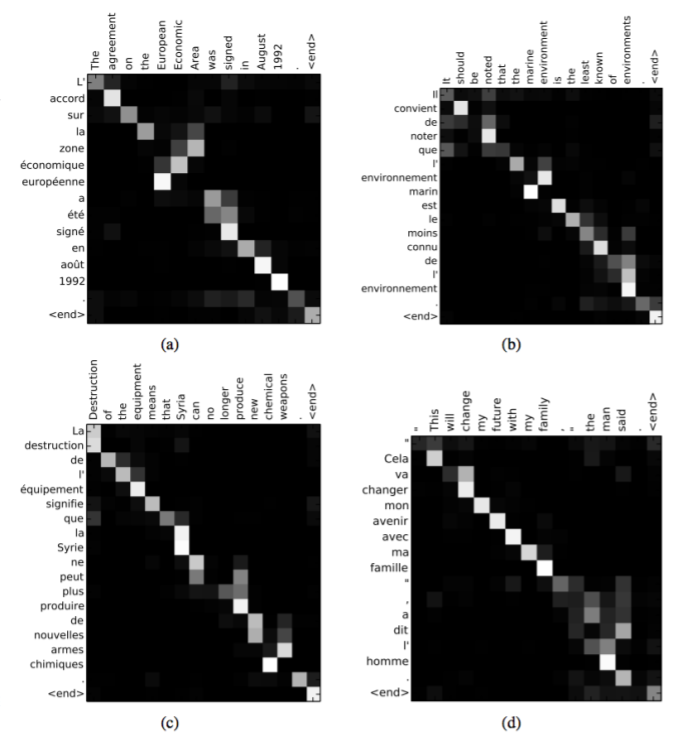
- 단어들의 문법적인 정렬을 학습함
- 불필요한 단어들은 skip할 수 있음

세진니의 눈물 가득 블로그