이전의 문서에서 이어지는 내용으로, 같이 참고하면 좋습니다.
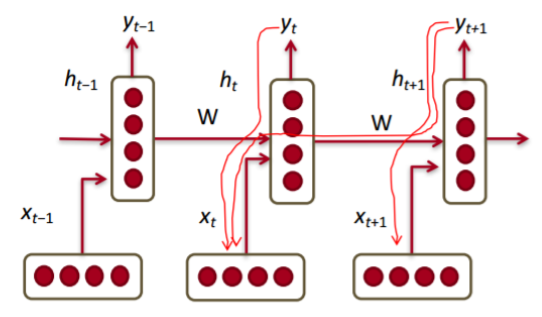
Character-level Language Model
Character-level Language Model

- 예시 training sequence : "hello"
- vocabulary : [h, e, l, o]
- Input Layer
- 각 cell에서 e, l, l, o 를 예측해야 다음 과정으로 넘어갈 수 있음
- Hidden Layer
-
- 는 를, 는 를 선형변환
- 제일 첫 hidden layer인 은 default로 0인 vector로 주어짐
- Output Layer
-
- 각 와 이 마지막 hidden layer 거쳐서 output에서 정의되는 선형변환의 parameter 로 변환됨
- back propagation에 의해 학습 진행
- output layer에서 가장 높은 값의 확률값을 높여서 학습 진행
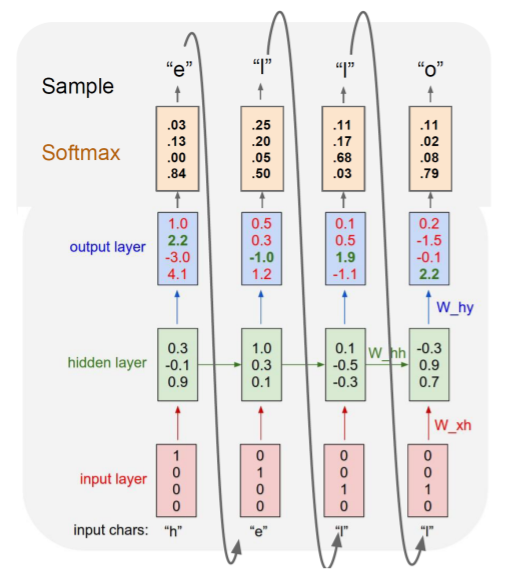
- Softmax
- softmax 거침으로써 확률값의 형태로 결과 출력
- 해당 time step을 거침으로써 나온 예측값을 다음 time step의 input으로
- 다음과 같은 과정을 통해 무한한 길이의 character sequence 생성 가능
Additionals for RNN
- 셰익스피어의 극본에 RNN 적용

- RNN의 학습 과정

- 학습이 진행될수록 처음의 한 character 주어졌을 때 뒤의 내용을 더 잘 예측할 수 있게 됨
- 학습된 RNN에 대한 결과

- 등장인물 : 대사 형식으로 주어짐
- 사람 이름은 대문자
- newline 후 대본 내용
- RNN으로 작성된 논문

- RNN으로 생성된 C code

Backpropagation through time (BPTT)
Backpropagation through time (BPTT)
- 전체 sequence를 통해 loss를 계산한 다음 gradient를 계산하기 위하여 전체 sequence에 대해 backward 수행
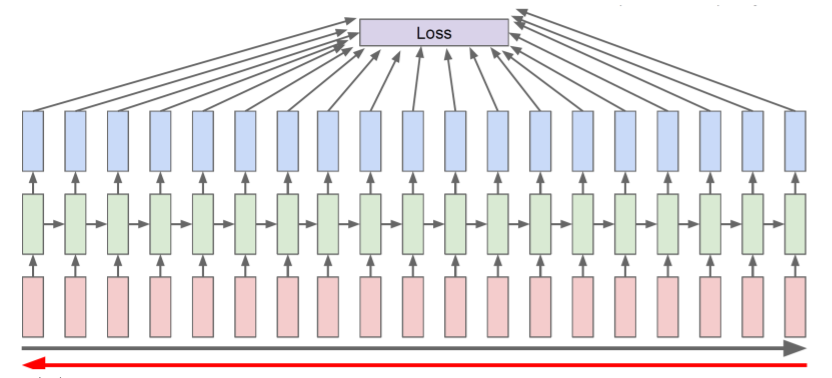
- 전체 sequence 대신 truncation을 수행한 sequence chunk를 이용하여 forward와 backward를 수행
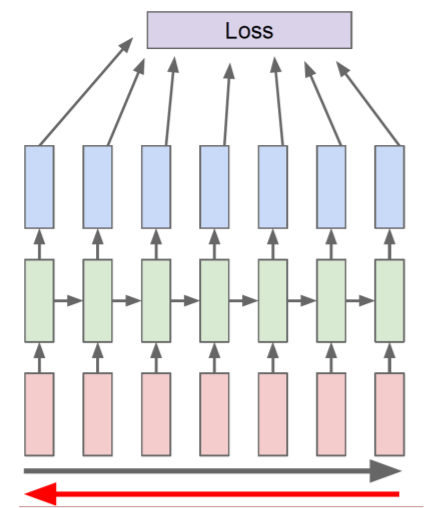
- hidden state들을 계속적으로 forward 연산 시키고, 그 중 몇 개만 backpropagate를 수행
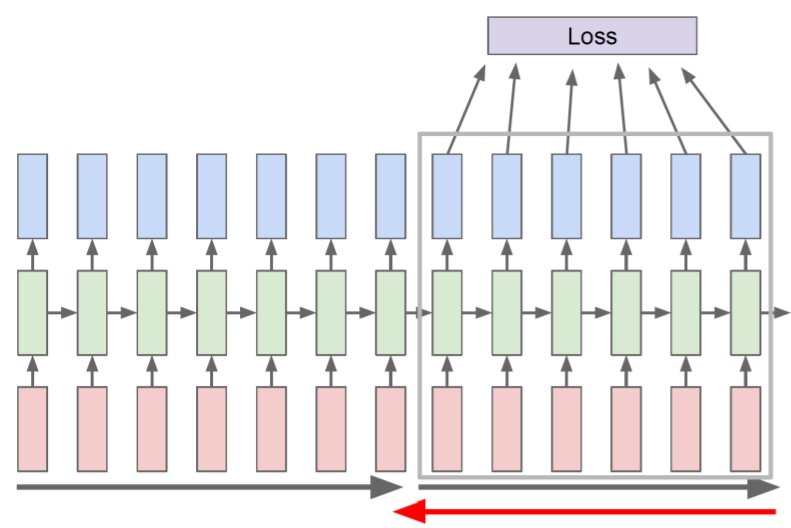
- forward/back propagation으로 RNN의 parameter 학습
Searching for Interpretable Cells
- 필요한 정보가 N개 중 어디에 포함되어 있는가?
- hidden state vector의 각각의 차원을 하나씩 고정하고, time step이 진행됨에 따라 어떻게 변화하는지 분석하여 RNN의 특성 분석
How RNN works
- 특정 hidden state vector의 dimension을 고정해둔 상태에서 해당 dimension의 값이 어떻게 변화하는가를 확인하기 위해 사용한 시각화의 예시
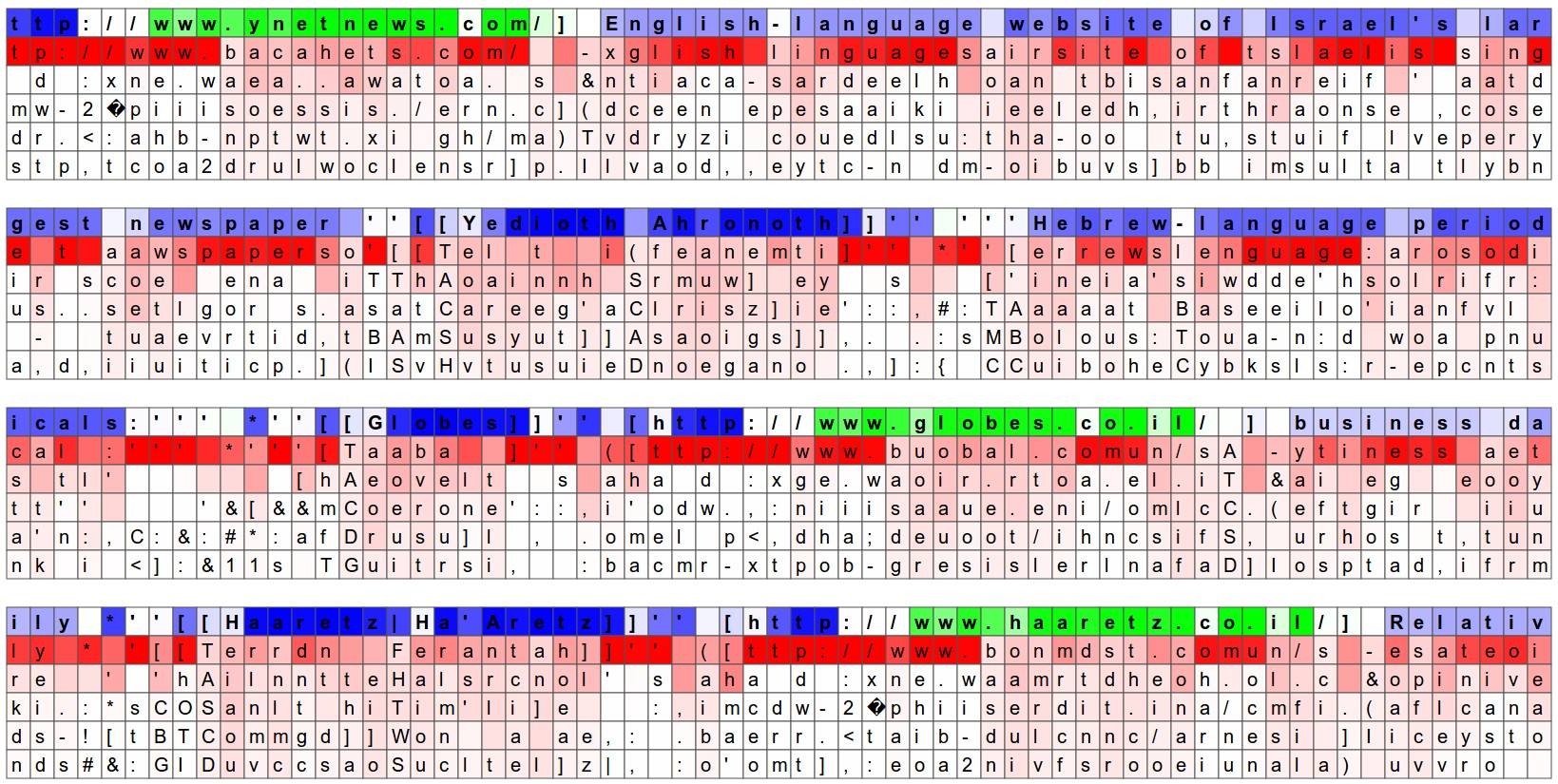
- Quote("") 감지 cell : ""가 열렸는지/닫혔는지 하는 상태를 기억

- If 조건문 cell : if의 조건문만 따로 처리
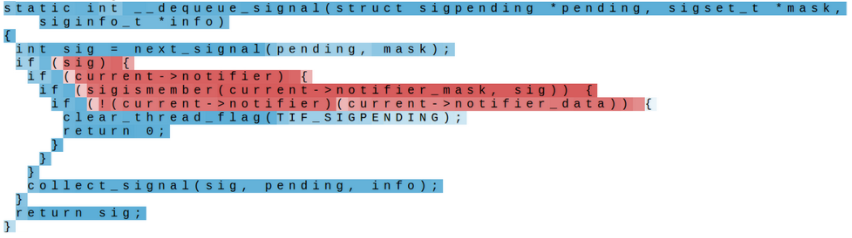
Vanishing/Exploding Gradient Problem in RNN
Vanishing/Exploding Gradient Problem in RNN
- 역전파 중에 각 단계에서 동일한 매트릭스를 곱하면 그라데이션이 사라지거나 폭발할 수 있음
Toy Example
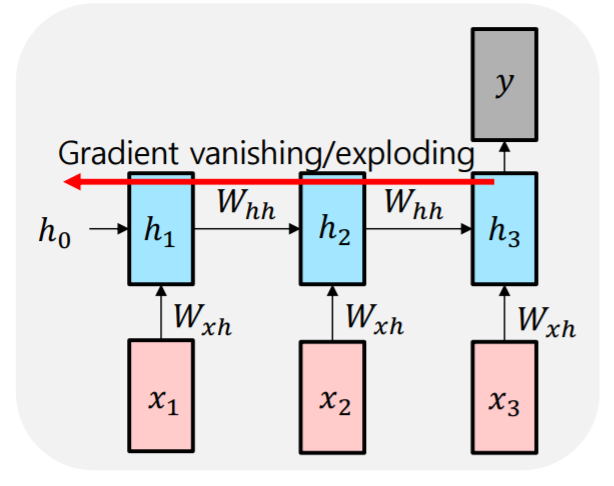
- 일 때
-
-
-
- ...
- - 계속해서 중첩되는 구조가 만들어짐
- time step 거슬러 올라가면서 back propagation 수행했을 때 에 부여되는 gradient 값의 pattern 시각화

- RNN에서의 는 일반적으로 행과 열의 개수가 hidden state vector의 길이와 동일한 정사각행렬
- RNN에서는 절대값이 1보다 작은 값으로 거듭제곱 수행하면서 빠르게 감소됨
- 유의미한 gradient signal이 뒷쪽까지 잘 전달되지 않음
- LSTM은 먼 time step까지도 gradient 값이 남아있으므로 time step간 거리가 멀어도 계산 가능

세진니의 눈물 가득 블로그