Basics of Recurrent Neural Networks (RNNs)
Types of RNNs
- 기본적인 구조
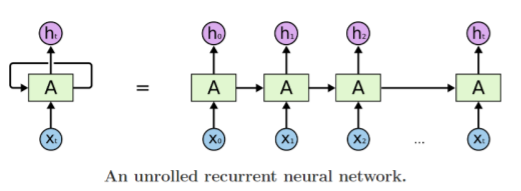
- 전 time step의 RNN module에서 계산한 hidden state vector
- 각 time step에서 들어오는 input vector
- 동일한 parameter를 가진, 반복적으로 등장하는 module인 RNN
Recurrent Neural Network
- 각 time step에서의 vector를 예측하고자 할 때 RNN 사용
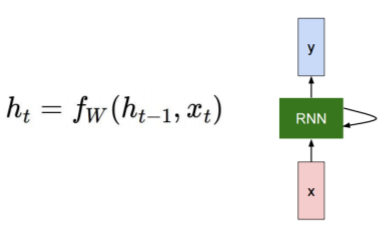
- : 전 time step의 RNN module에서 계산된 hidden state vector
- : time step 에서의 입력 vector
- : 새로운 hidden state vector
- : parameter인 를 가지는 RNN function
- : 매 time step마다 RNN module(linear transformation matrix)을 정의하는 parameter. 모든 time step에서 동일한 값을 공유
- : time step 에서의 output vector
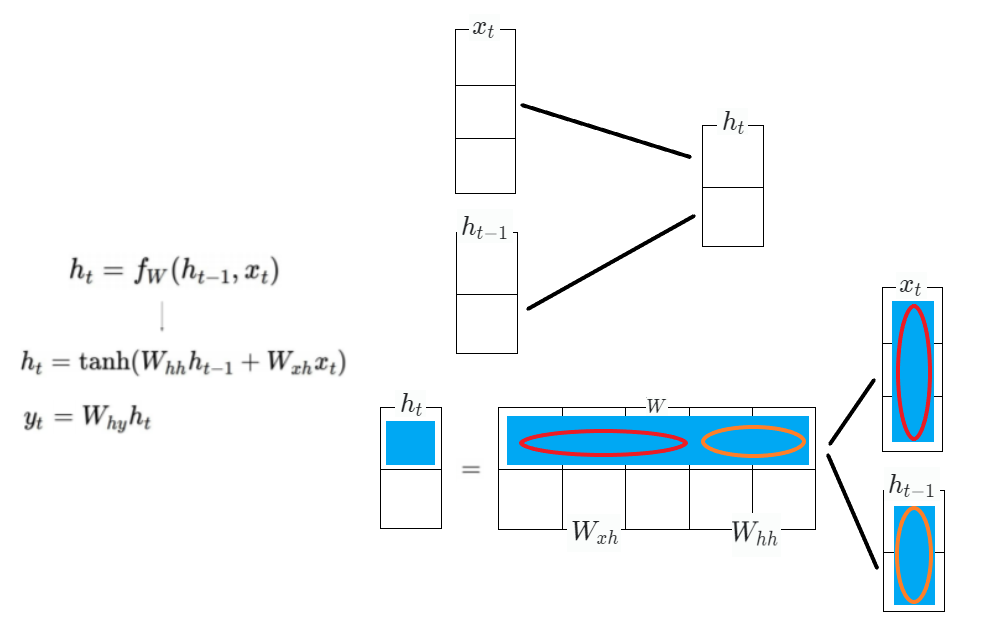
- 는 과 동일한 형태의 dimension 공유해야 함
- 와 는 선형변환을 위한 matrix
- 는 linear transformation matrix로 를 로 바꾸기 위함
- 는 class개수만큼의 dimension을 가지는 vector를 최종 output으로 가지고, 이 값이 softmax layer를 통과함으로써 분류하고자 하는 class와 동일한 개수만큼의 확률분포를 얻게 됨
Types of RNNs
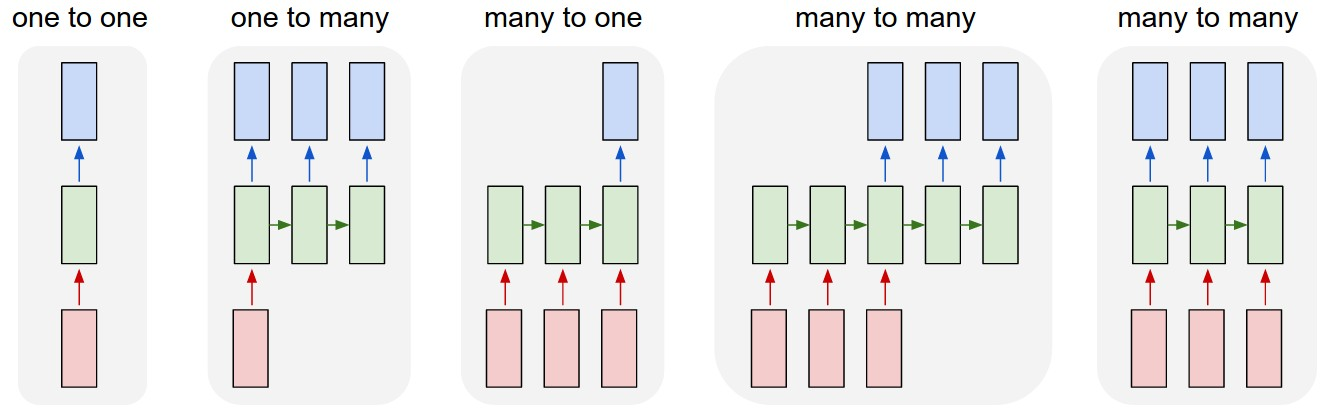
- One-to-One
- 입출력 data의 time step이 단 한 개
- sequence data가 아님 - One-to-Many
- 대표적인 예시로 Image Captioning
- 입력의 time step은 하나이나 출력이 여러 개
- 추가적으로 넣어줄 입력이 따로 없을 경우, 동일한 RNN module의 입력으로는 같은 size의 vector, 행렬, Tensor가 들어가되 값이 모두 0으로 채워진 형태 - Many-to-One
- 대표적인 예시로 Sentiment Classification(감정 분석)
- 길이에 따라 cell 개수 늘려 반복적으로 input 수행
- input으로 들어갈 땐 word embedding vector 형태
- RNN model에서 나온 로 최종적인 output layer 적용함으로써 긍정/부정 값 예측 수행 - Sequence-to-Sequence 1
- 대표적인 예시로 Machine Translation
- 입력으로 들어온 sequence를 모두 읽은 뒤 번역 작업 수행 - Sequence-to-Sequence 2
- 대표적인 예시로 Video classification on frame level
- 입력 진행될 때마다 예측 수행
- delay가 없음

세진니의 눈물 가득 블로그