Long Short-Term Memory(LSTM)
Core Idea
- 주요 개념 : cell state 정보를 transformation을 거치지 않고 전달함으로써 long-term dependency 문제 해결
- time step이 먼 경우에도 필요한 정보를 효과적으로 처리하고 학습할 수 있도록 함으로써 gradient vanishing 및 explosion 문제 해결
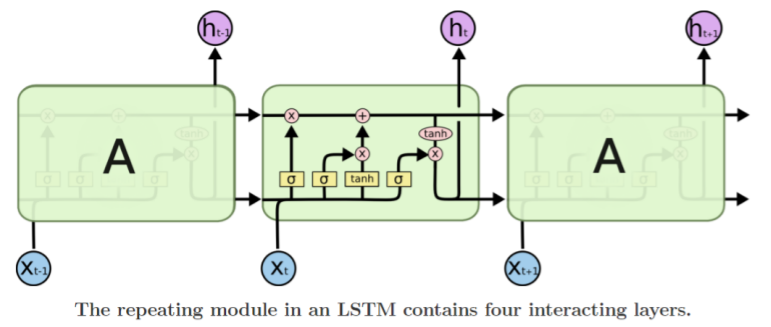
What is LSTM?
- 단기 기억을 담당하는 기억 소자로, 보다 길게 기억할 수 있도록 개선한 model
- : cell state vector의 완전한 정보를 가지고 있음
- : cell state vector를 한 번 더 가공하여 그 time step에서 노출할 필요가 있는 정보만을 남긴 filtering된 정보를 담는 vector
Long short-term memory
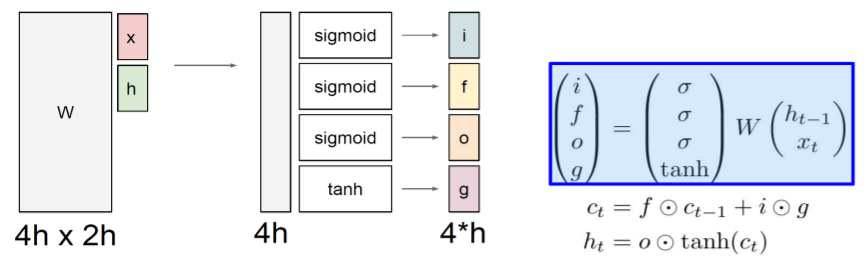
-
cell state, hidden state vector 계산 위한 중간 결과물
- : input gate. cell을 받음
- : forget gate. cell을 지움
- : output gate. 얼마나 cell을 공개시킬지 결정
- : gate gate. 얼마나 cell을 사용할 것인지 결정
-
: 선형 변환 위한 matrix
-
: 와 모두 의 dimension 가질 때.
-
각 gate는 cell state에서 흐를 수 있는 정보의 양 등을 결정
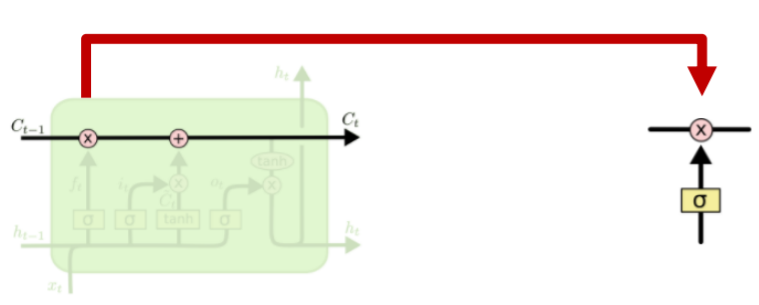
-
vector들은 를 적절하게 변환하는 데에 사용
-
Forget gate
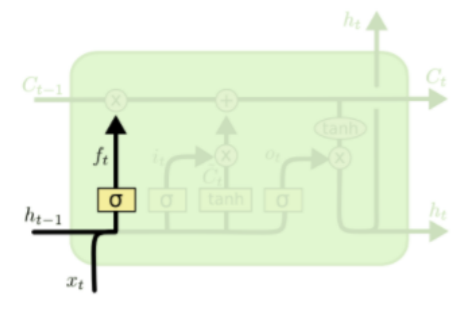
-
- 와 가 만나는 곳에서 선형결합
- 거친 뒤의 에서는 forget하지 않을 정도 기록
- (30%를 forget한다면 0.7로 기록)
- 의 값과 를 내적한 값을 에 기록 -
생성된 정보들은 input gate에 의해 더해지거나 제외될 수 있음
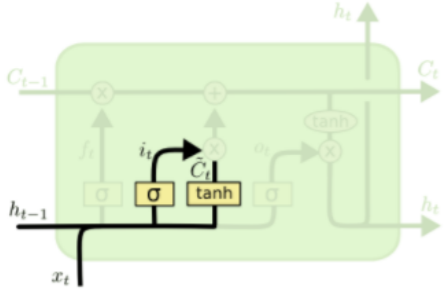
-
- → -1에서 1 사이 값 가짐 -
이전 cell state에 현재의 정보를 추가함으로써 새로운 cell state 생성
-
- 를 통해 필요한 정보만 유지 -
cell state를 tanh 또는 ouput gate로 보냄으로써 hidden state 생성
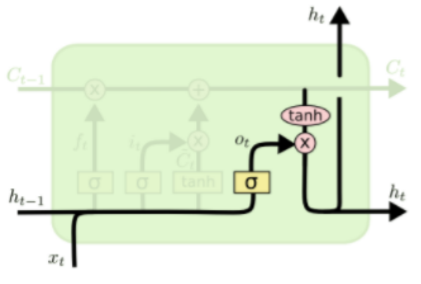
-
hidden state를 다음 time step으로 보내고, 필요하다면 output으로 내보내거나 next layer로 보냄
-
- , output layer의 입력
- 는 기억해야 하는 모든 정보를 담고 있음 -
dimension별로 적절한 비율만큼 값들을 작게 만들어서 최종적인 구성
-
필요한 정보만을 담고 있음
Gated Recurrent Unit(GRU)
What is GRU?
- LSTM의 model 구조 경량화해서 적은 memory 요구량과 빠른 개선이 가능하도록 함
- LSTM의 (Cell state vector)와 (hidden state vector)를 로 일원화
- 2개의 독립된 gate를 통해 하던 연산을 하나의 gate만으로 계산하도록 함
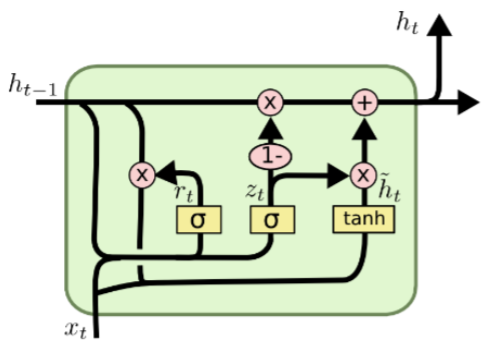
- , input gate
-
-
- (LSTM에서는 )
- LSTM의 가 로 작용하여 가중평균 내는 형태로 계산됨 - input gate가 커지면 커질수록 forget gate에 해당하는 값이 작아짐
- hidden state vector 는 과 로 계산됨
Backpropagation in LSTM/GRU
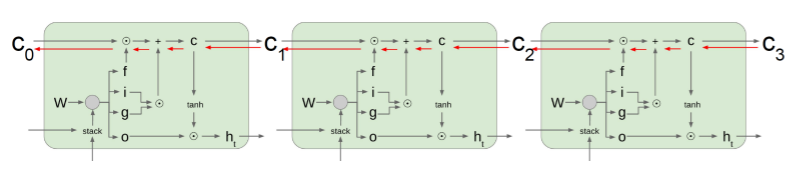
- 덧셈을 통해서 원하는 정보를 만들어줌으로써 gradient vanishing, explosion 문제 해결
Summary on RNN/LSTM/GRU
- RNN은 architecture design에 굉장히 유연함
- vanila RNN은 simple하지만 잘 작동하지 않음
- RNN의 기울기에 대한 backward flow는 explode와 vanish 가능성이 있음
- LSTM과 GRU는 gradient flow를 향상시켜줌

세진니의 눈물 가득 블로그