Important Concepts in Optimization
Generalization
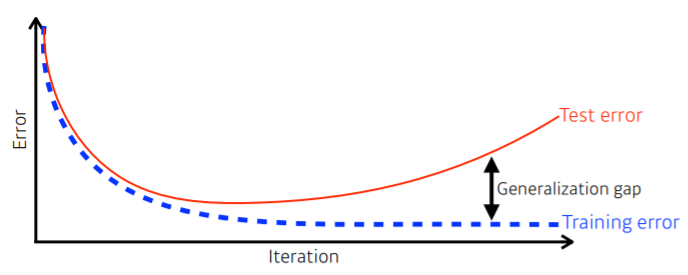
- generalization gap : test error와 training error 사이 간극
- 좋은 generalization 성능 : network 성능이 학습 data와 비슷하게 나올 것이라고 보장
Underfitting vs Overfitting
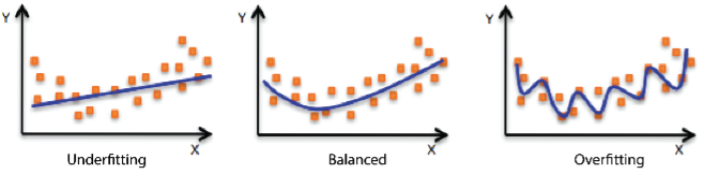
- 모델이 너무 간단해서 학습 오류가 줄어들지 않는 underfitting
- training error가 test dataset에 대한 error보다 작은 경우를 overfitting
Cross-Validation (K-fold Validation)
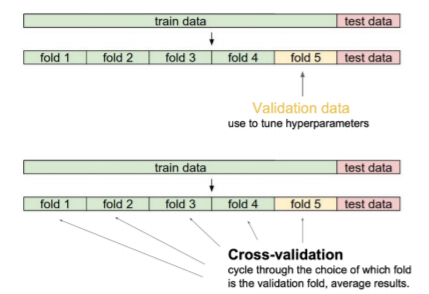
- Cross-Validation은 일반화되는 방법을 평가하기 위한 모형 검증 기법
- 학습 data를 train data와 validation data로 나눔
- validation data : hyperparameter를 조정하기 위함 - K-1개로 학습시키고 나머지 하나로 validation 수행하는 K-fold validation
- i번을 제외한 데이터 전체를 train으로 사용- i번 데이터를 validation 용도로 사용
- 최적의 hyper parameter set 찾기 위해 사용
- test data 활용해서 train 하는 건 절대 금지!!!
Bias and Variance Tradeoff
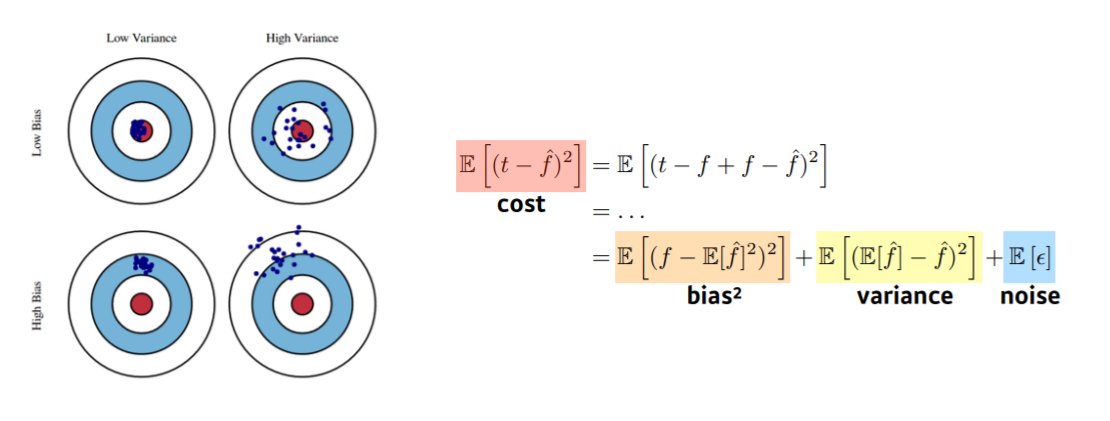
- Bias : 평균적으로 true target에 접근할수록 좋음
- Variance : 입력을 넣었을 때 출력이 얼마나 일관적으로 나오는지
- Tradeoff : 하나가 오르면 하나는 줄어드는 반비례 관계
- Bias ∝ 1/Variance
Bootstrapping
- 여러 개의 model 있을 때 하나의 입력에 대해 model들이 예측하는 값의 일치성 보고 uncertainty 예측
Bagging vs Boosting
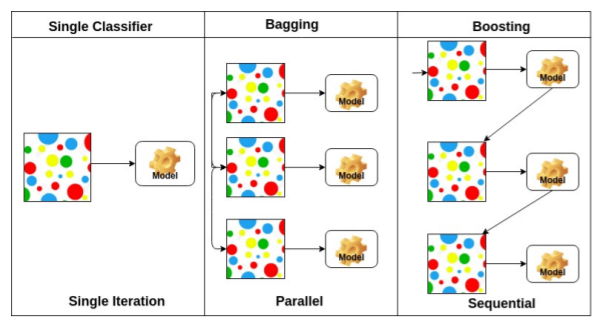
- Bagging (Bootstrapping aggregating)
- multiple model들은 주로 bootstrapping 사용
- 기본 classifier들이 random subset들로 맞춰져있음 - Boosting
- 분류하기 어려운 특정 training sample들에 초점- weak learner들을 합쳐 하나의 strong model을 만듦
Gradient Descent Methods
Batch gradient descent
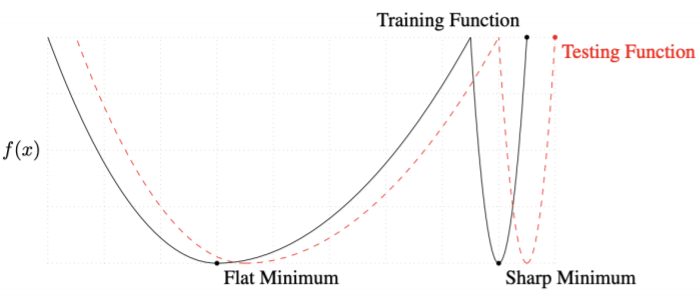
- batch methods가 large할 경우 sharp minimizer에 도달, small할 경우 flat minimizer에 도달하게 됨. sharp보단 flat이 더 좋음.
- flat minimum이 generalization performance가 더 높음
- 따라서, batch size를 줄이면 generalization performance가 더 좋아짐
Momentum (관성)
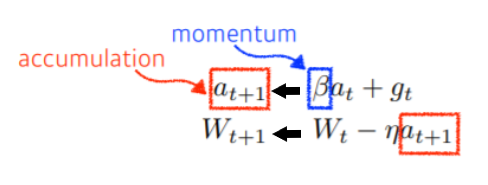
- a라는 momentum을 이루고 있는 term이 계속 그 값을 가지고 있음
- 한 번 흘러간 값을 계속 가지고 있기 때문에, gradient가 크게 변동되어도 최종적으로는 잘 학습됨
Nesterov Accelerated Gradient
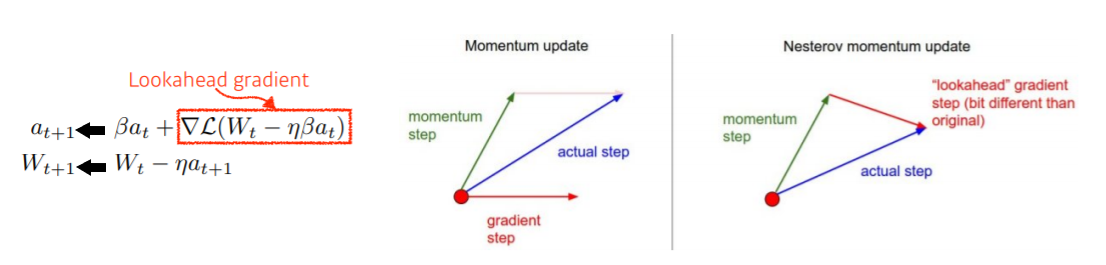
- a의 방향으로 한 번 가보고, 간 곳에서 계산한 gradient 가지고 accumulate 수행
- 제일 오른쪽 그림의 빨간색 화살표는 momentum으로 간다고 쳤을 때의 gradient 방향
- 실제 momentum만을 이용했을 때의 가중치 값을 이용하여 조정된 momentum을 구함
- 새로 구한 momentum에 step 값을 곱해 새로운 가중치를 구함
- conversion 빠르게 수행 가능
Adagrad
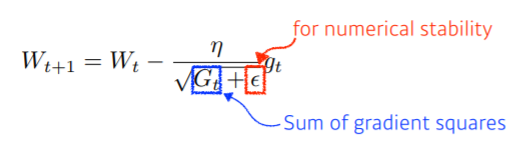
- neural network의 parameter가 지금까지 얼마나 변해왔는지 / 안 변해왔는지 확인
- 많이 변화했을 경우 Gt이 크므로 최종적으로 W(t+1)의 값을 적게 변화시킴
- 뒤로 갈수록 Gt의 값이 커져서 W(t+1)의 값이 0이 될 수 있음
Adadelta
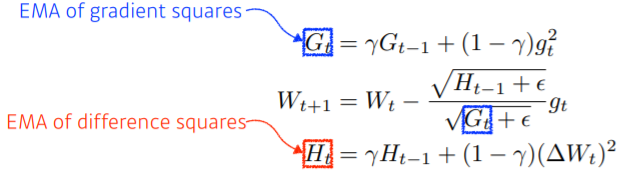
- Adagrad의 G_t가 계속해서 커지는 현상을 막기 위한 방법
- EMA : Exponentail Moving Average
- 정해진 time window만큼의 값 저장하고, 평균값을 가짐
- 이 방법엔 학습률 개념 적용하지 않음
Adam
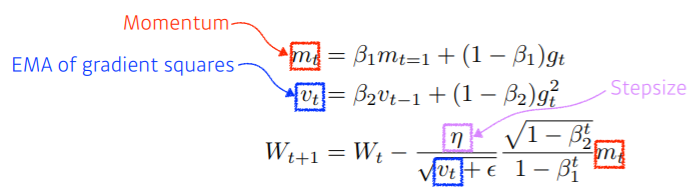
- Adam은 이전의 gradient와 gradient들의 평균에 영향을 받음
- gradient의 크기 변함에 따라서 adaptive하게 learning해서 gradient를 update 시킴
- 이전의 gradient 정보에 해당하는 momentum을 이용
Regularization
- test data에서도 잘 동작할 수 있도록 학습을 방해하는 것이 목적
Early Stopping
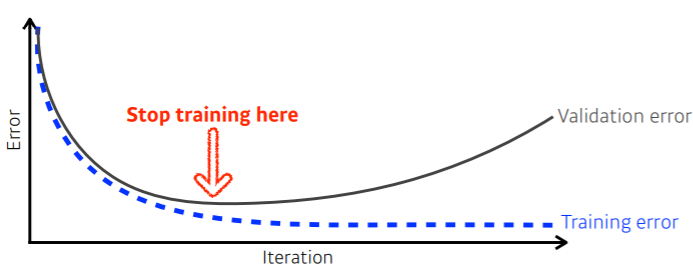
- loss가 어느 정도 커지기 시작할 때 training을 멈춤
Parameter Norm Penalty

- 부드러운 함수일수록 generalization performance가 높음
Data Augmentation
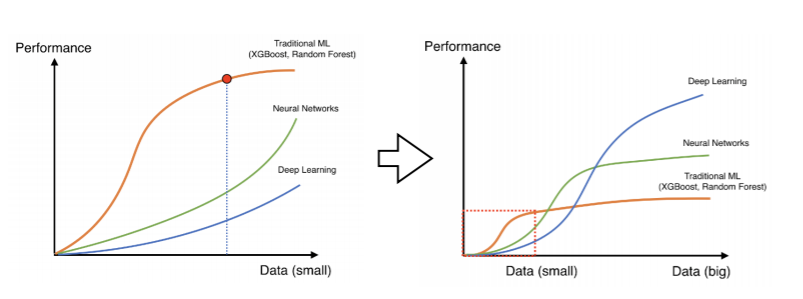
- 데이터가 많은 게 짱이야~
- 데이터가 적을 경우, 이런 식으로 변화를 줘서 데이터에 추가함
Noise Robustness

- 강사님? 마스터님?이 말씀하셨던 건,,, 이렇게 noise를 넣으면 성능이 잘 나온다고 하시더라,,, 증명은 머,, 따로,,,~
Label Smoothing
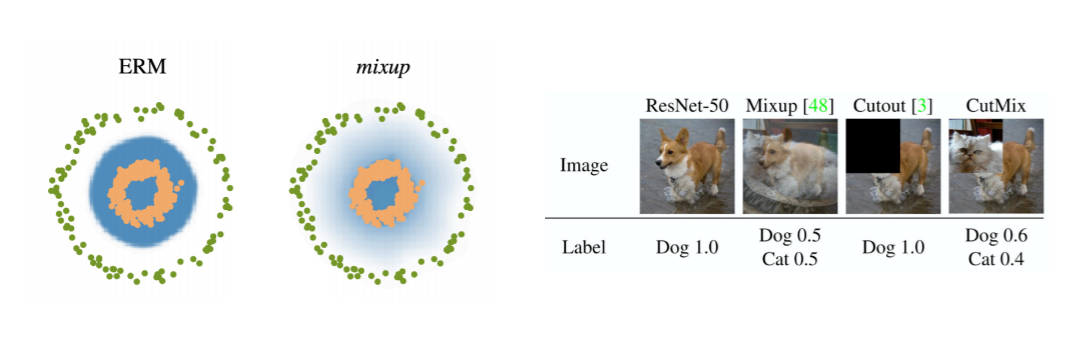
- Mix-up은 random하게 선택된 2개의 training data의 input과 output을 모두 섞어줌
- CutMix는 입력을 cut and paste로 mix하고, random하게 선택한 두 개의 training data의 soft label로 만듦
Dropout
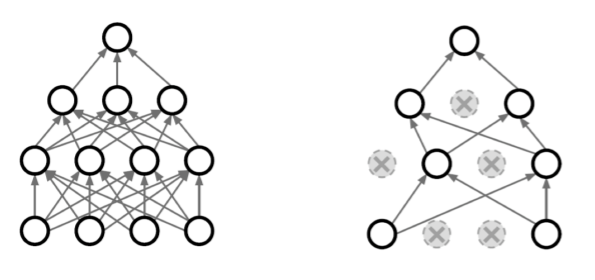
- 특정 몇 개의 neuron들을 0으로 만듦
Batch Normalization
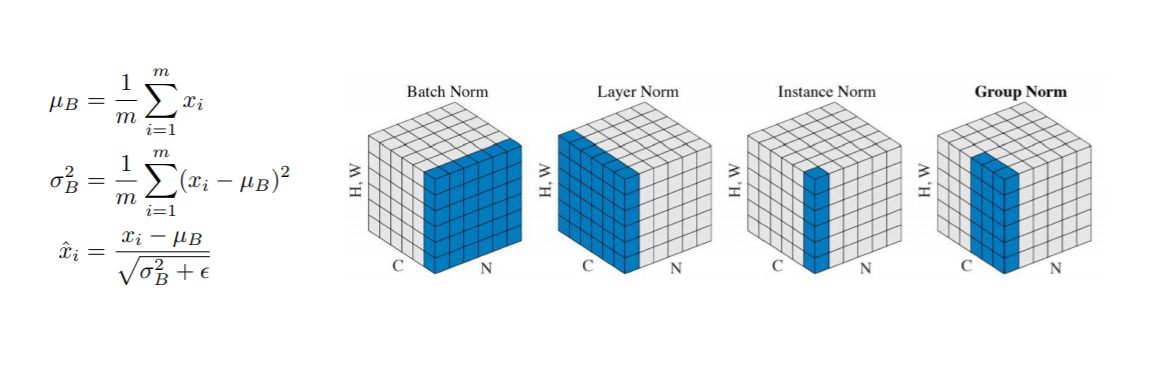
- 이거,,, 강의할 땐 스르륵 지나가서 그냥 나도 같이 스르륵 넘어갔는데 피어세션 때 다른 캠퍼분이 질문하셔서 다시 한 번 볼 수 있는 기회가 됐다,,, 그리고 이 페이지를 추천해주셨당.
내 걸 보는 것보다,,, 이걸 보는 것도 나쁘지 않을 것 같은,,,^^ - 우선 오른쪽의 그림은,,, 원래 4차원 형탠데 3차원으로 표현하려고 한 것 같다
- 그리고 하나의 box?는 각각 convolution 과정 중에 channel이 여러 개 뽑힌 상황을 표현하고 있는 것 같았다
- N은 batch의 개수, C는 channel의 개수, H와 W는 각각 높이와 너비
- Batch Normalization
- N, H, W에 대해서만 연산을 수행- 같은 feature의 애들끼리 연산 진행하고, layer 전체를 줄임
- Layer Normalization
- 특정 pixel에서 channel끼리 연산을 진행- 각각의 layer 정보를 줄임
- Instance Normalization
- 각 데이터에 대해서 연산 수행- img 한 장 별로 layer를 줄임
- Group Normaliztaion
- channel을 그룹으로 묶어 normalization을 진행- group 수 G에 대해 G==1일 때 layer normalization과 동일
- G == C이면 instance normalization과 동일

세진니의 눈물 가득 블로그