Word Embedding
What is Word Embedding?
- vector로써 단어를 표현
- 'cat'과 'kitty'는 비슷한 단어이므로, 비슷한 vector 표현형을 가지고, 서로 가까이에 위치
- 'hamburger'는 'cat'이나 'kitty'와 다른 의미의 단어이므로, 사이 거리가 멂
- Word Embedding은 해당하는 좌표 공간 상에서 학습 data에서 나타난 각각의 단어에 대한 최적의 좌표값, 또는 의미 상의 유사도를 고려한 벡터 표현형을 출력으로 가짐
Word2Vec
Idea of Word2Vec
- 같은 문장에서 나타난 인접한 단어들 간에 의미가 비슷할 것이라는 가정 사용
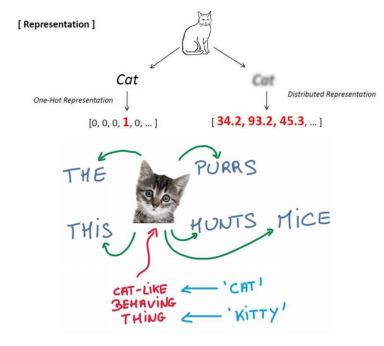
- 예시 문장 : The cat purrs. The cat hunts mice.
- 여기서 purrs와 hunts는 cat이 할만한 행동으로 인식됨
- mice는 hunts의 대상으로 작용 - cat 단어를 입력으로 주고, 주변 단어를 숨긴 채 예측하도록 하는 방식으로 학습 진행
How Word2Vec Algorithm Works
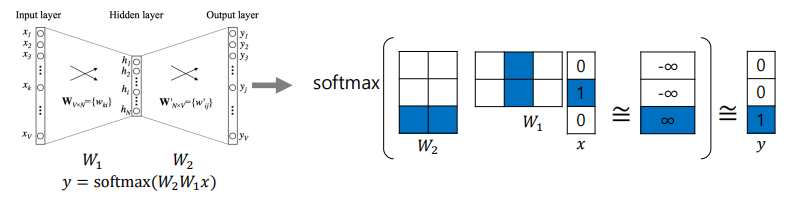
- hidden layer의 차원은 word embedding을 수행하는 좌표공간의 차원 수와 동일한 값을 가짐
- 는 3차원 input을 받고 2차원 output을 내보냄
- 는 해당하는 dimension이 1인 형태인 one-hot vector
- 가장 마지막 y는 softmax를 거친 결과
- tokenize를 진행하고, unique한 단어들만을 모아서 dictionary를 구축
- dictionary의 size를 dimension으로 가지는 one-hot vector로 나타남
- sliding window를 거친 단어를 중심으로 앞 뒤로 나타난 각각의 단어들과 쌍을 이룸.
- sliding window- 오른쪽이 sliding window를 거친 결과쌍
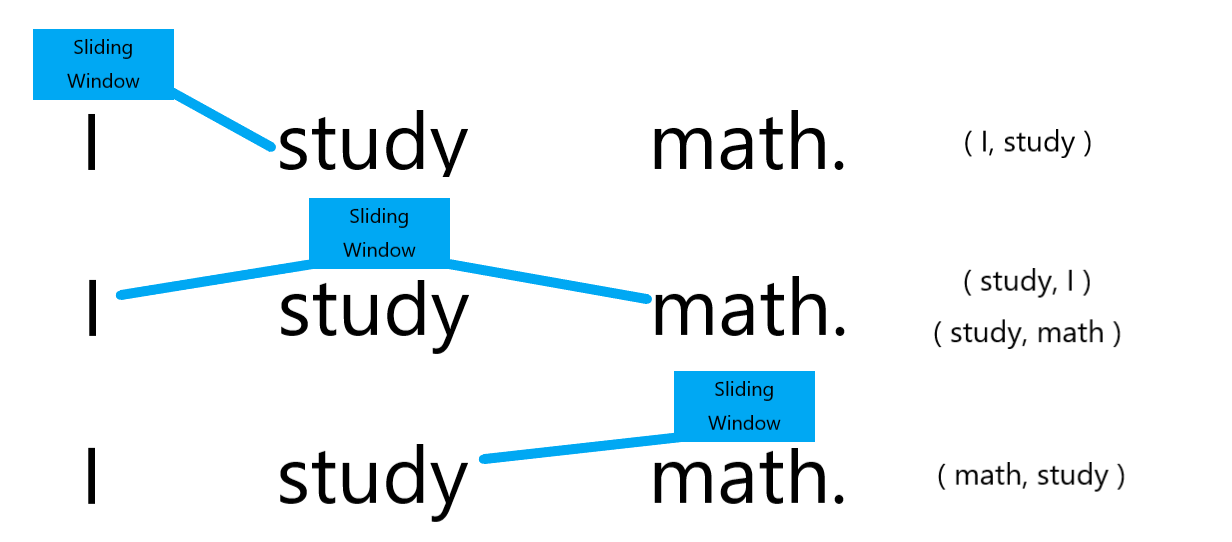
- 오른쪽이 sliding window를 거친 결과쌍
- Example
- Sentence : "I study math"
- Vocabulary : {"I", "study", "math"}
- Input : "study", [0, 1, 0]
- Output : "math", [0, 0, 1]
- Input과 Output 모두 node의 개수는 len(set(sentence))로 3개
- 의 열과 의 행이 각 단어를 나타냄
- "study" vector는 에서 두번째 열, "math" vector는 에서 세번째 행
- 의 "study" vector와 의 "math" vector는 높은 내적값을 가짐
이때 hidden layer에서 차원이 왜 축소되는가? 왜 굳이 3차원에서 2차원으로 만들었다가 다시 3차원으로 넘어가는가?
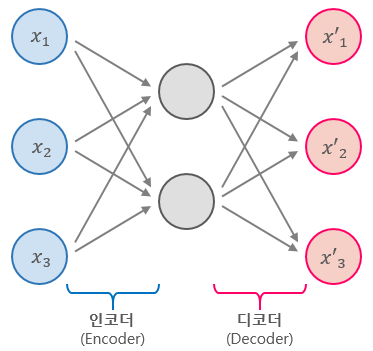
- 이것은 Autoencoder의 차원 축소 특징 때문이라고 할 수 있다.
- Autoencoder는 단순히 입력을 출력으로 복사하는 신경망으로, 네트워크에 여러가지 방법으로 제약을 줌으로써 어려운 신경망으로 만든다.
- 이러한 제약을 통해 Autoencoder가 단순히 입력을 바로 출력으로 복사하지 못하도록 방지하며, 데이터를 효율적으로 표현하는 방법을 학습하도록 제어한다.
참조 : https://excelsior-cjh.tistory.com/187
Another Example

- 주어진 단어들의 관계 등을 확인할 수 있는 Word Embedding Visual Inspector
- 직접 확인해보고 싶다면 이 홈페이지!
Property of Word2Vec
- 단어 vector, 또는 공간에서의 vector 사이 관계는 두 단어 사이의 관계를 표현
- 같은 관계는 같은 벡터로써 나타냄
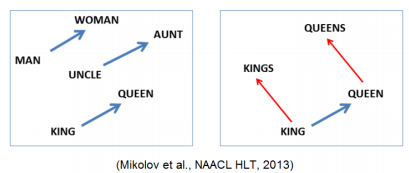
- vec[queen] - vec[king] = vec[woman] - vec[man]
Analogy Reasoning
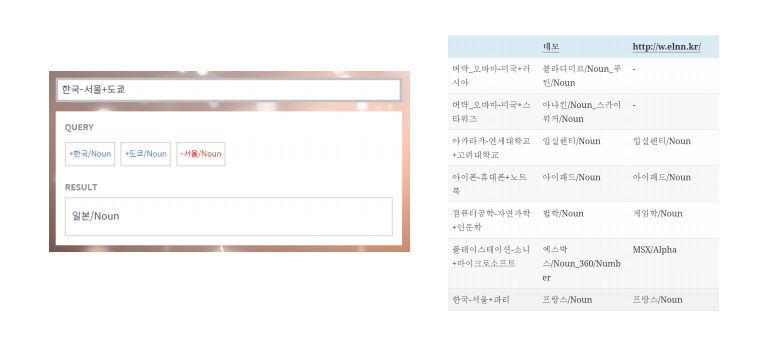
Instruction Detection
- 나머지 단어와 의미가 가장 상이한 하나 찾아냄
- Euclidean distance 구해서 평균 취함으로써 한 단어가 나머지 단어들과 이루는 평균 거리 구할 수 있음
- Examples
- mathshoppingreading science
- eight six seven five threeowenine
- england spain france italy greece germany portugalaustrailia
Application of Word2Vec
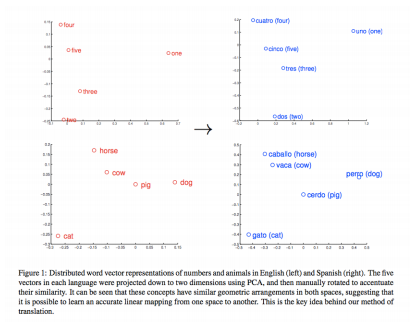
- 서로 다른 언어들에서 같은 의미를 가지는 word들의 embedding vector가 쉽게 align될 수 있도록 하여 번역의 성능 향상하는 Machine Translation
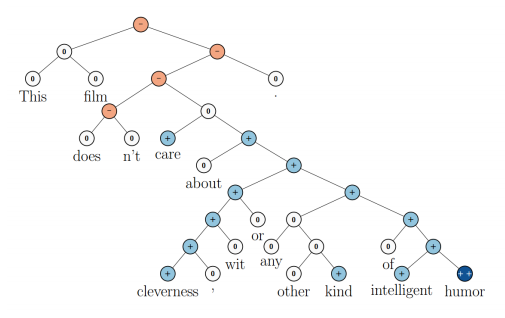
- 감정 분석
- embedding vector로 학습하는 Image Captioning

GloVe
GloVe : Global Vectors for Word Representation
- 입출력 단어 쌍들에 대해 학습 데이터에서 두 단어가 한 window 내에서 동시에 몇 번 등장했는지를 사전에 계산
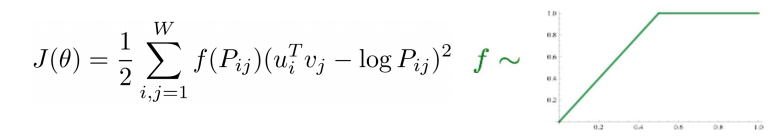
- : window에서 단어 수에 대해 scaling 진행한 결과
- : new Loss Function.
(입력 word의 embedding vector * 출력 word의 embedding vector
두 단어가 한 window 내에서 동시에 몇 번 나타나는가)
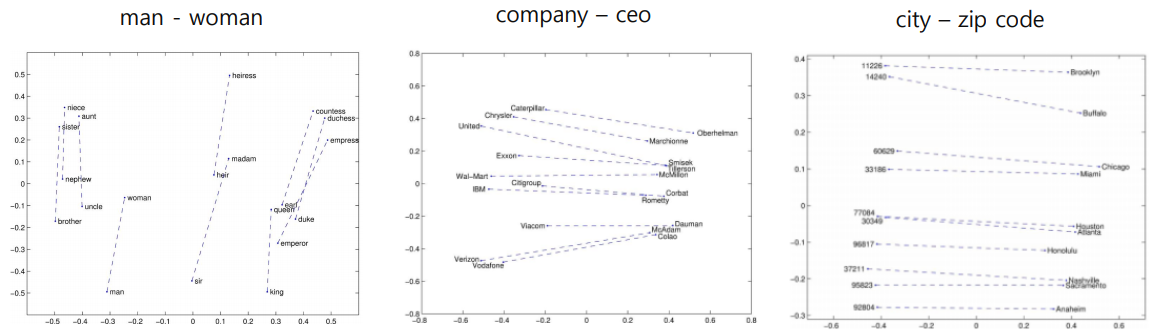
Property of GloVe
- 같은 의미의 단어를 특징만 다르게 2차원 그래프로 표현했을 때 Linear Substructure

세진니의 눈물 가득 블로그