딥러닝 너무 어려운데ㅠ
해보고 있습니다.
일단.. MNIST 데이터셋을 가지고 학습을 시켜 보도록 하겠습니다.
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder필요한부분을 임포트 해줍시다!
train_df = pd.read_csv('mnist_train.csv')
test_df = pd.read_csv('mnist_test.csv')kaggle 에서 데이터 2개를 가져왔습니다.
하나는 트레이닝으로 쓰고 하나는 테스트로 사용하도록 하겠습니다!
plt.figure(figsize=(16, 10))
sns.countplot(train_df['label'])
plt.show()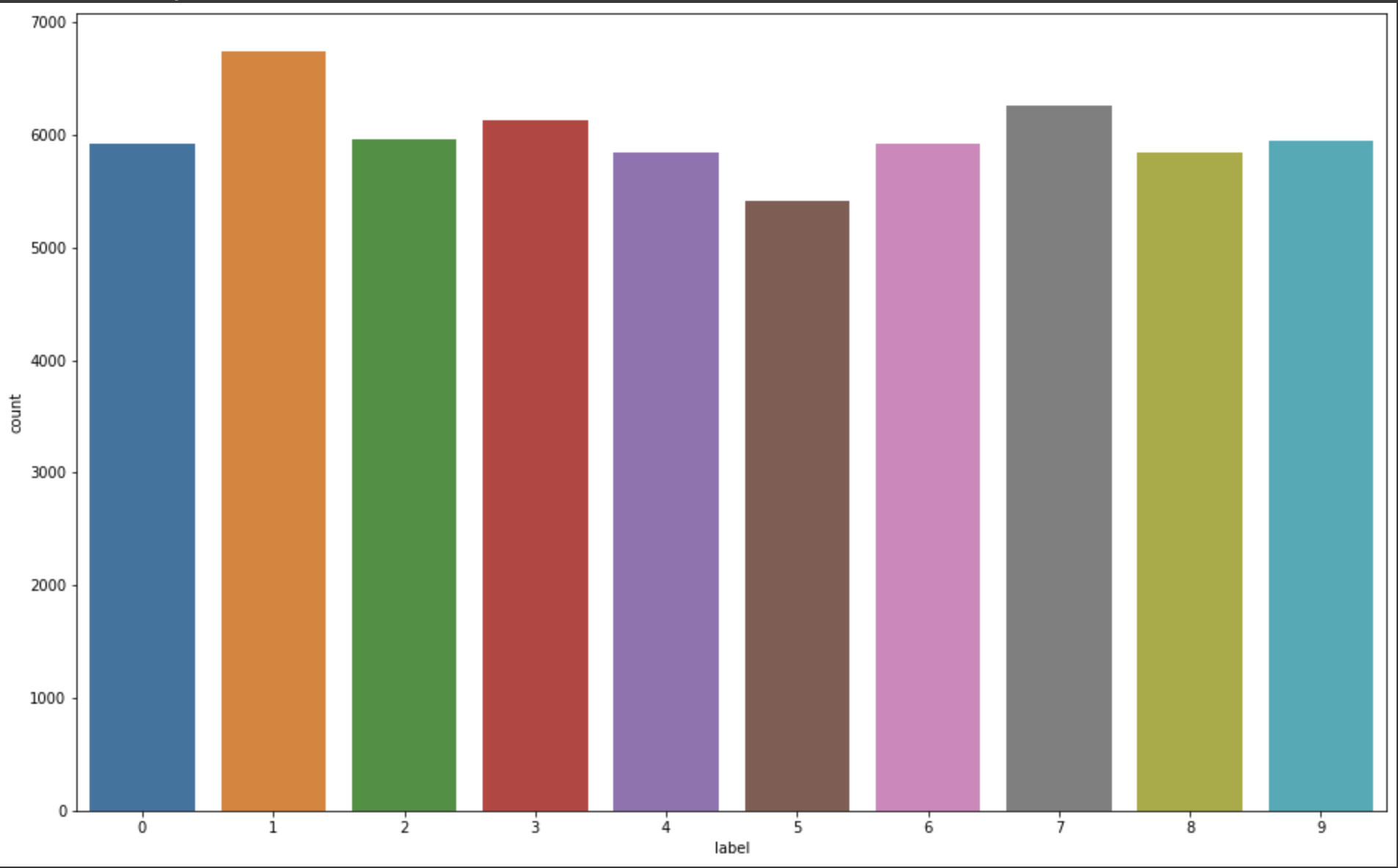
라벨 분포도를 본다면, 숫자가 0개 이니 0부터 9까지 저렇게 되어 있는걸 알수 있습니다.
train_df = train_df.astype(np.float32)
x_train = train_df.drop(columns=['label'], axis=1).values
y_train = train_df[['label']].values
test_df = test_df.astype(np.float32)
x_test = test_df.drop(columns=['label'], axis=1).values
y_test = test_df[['label']].values
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)입력과 출력을 나누어 주어야 하는데요.
트레이닝은 label 빼고 전부 test는 라벨만...
모양을 프린트 해보면
(60000, 784) (60000, 1)
(10000, 784) (10000, 1)
이렇게 나오는걸 알수 있습니다.
index = 1
plt.title(str(y_train[index]))
plt.imshow(x_train[index].reshape((28, 28)), cmap='gray')
plt.show()인덱스 1번을 한번 미리보기로 해보도록 하겠습니다.
28,28 사이즈에 gray 스케일 입니다.
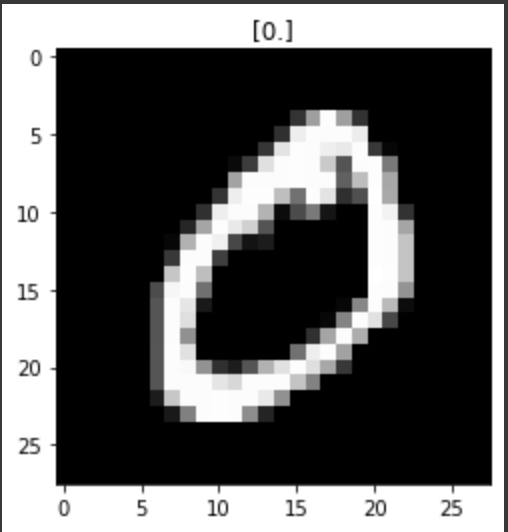
이런 모양으로 되어 있네요~
encoder = OneHotEncoder()
y_train = encoder.fit_transform(y_train).toarray()
y_test = encoder.fit_transform(y_test).toarray()
print(y_train.shape)one hot 인코딩을 해주도록 하겠습니다.
인코딩 된걸 다시 출력해 보면..
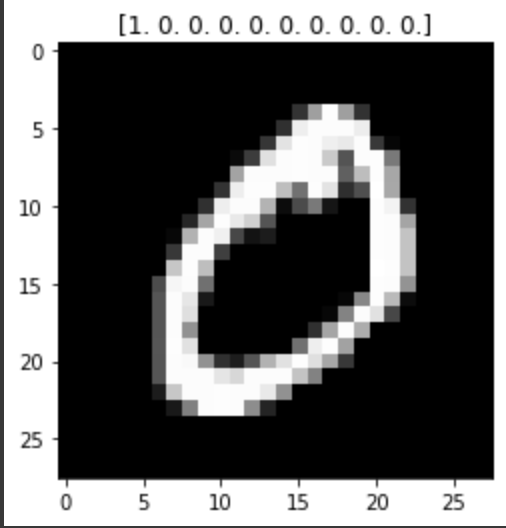
1.0.0.0.0.0 ......
된걸 확인할수 있다. 리스트로 인덱스가 1이기 때문에 0번째 값에 1이 들어간걸 알수 있다.
x_train = x_train / 255.
x_test = x_test / 255.데이터를 일반화 시켜 주자!
이미지 데이터는 픽셀이 0-255 사이에 정수형 데이터로 이루어져 있습니다.
그렇게 때문에 이걸 255로 나누고 데이터를 0-1 사이에 소수점 으로 만들어 일반화 시켜주도록 합시다.
input = Input(shape=(784,))
hidden = Dense(1024, activation='relu')(input)
hidden = Dense(512, activation='relu')(hidden)
hidden = Dense(256, activation='relu')(hidden)
output = Dense(10, activation='softmax')(hidden)
output = Dropout(rate=0.20)(output)
model = Model(inputs=input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
model.summary()네트워크 구성을 해줍니다. input 데이터 hidden 데이터를 만들고 dropout 도 20% 정도 줍니다.
loss는 카데고리 크로스엔트로픽을 사용하고 adam을 사용하겠습니다. 러닝레이트는 0.001 입니다. 매트릭스를 어큐러시 주어서 정확도를 체크 합니다.
모델 summary를 해보면..
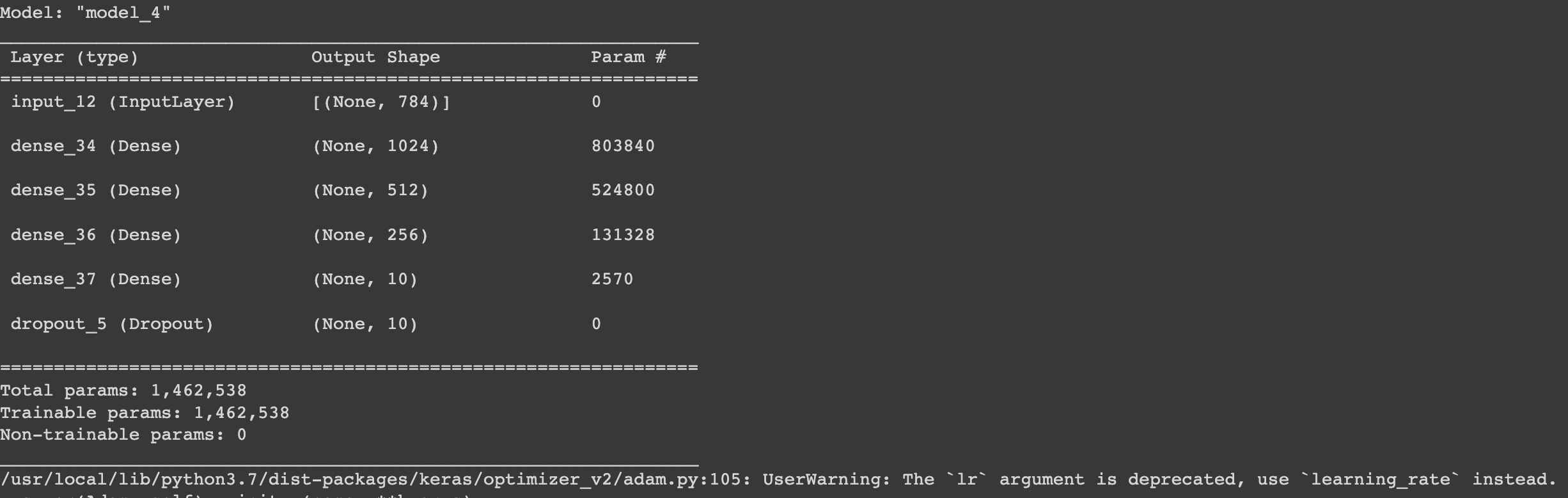
대충 이렇게 레이러를 쌓았네요.
dropout에는 파라미터가 없습니다.
history = model.fit(
x_train,
y_train,
validation_data=(x_test, y_test), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)학습 시켜 보도록 하겠습니다.

마지막 epoch 값이 어큐러시가 거의 100% 가깝네요. loss nan?ㅋ
학습은 잘되었습니다.
그래프로 그려 보도록 하겠습니다.
plt.figure(figsize=(16, 10))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.figure(figsize=(16, 10))
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])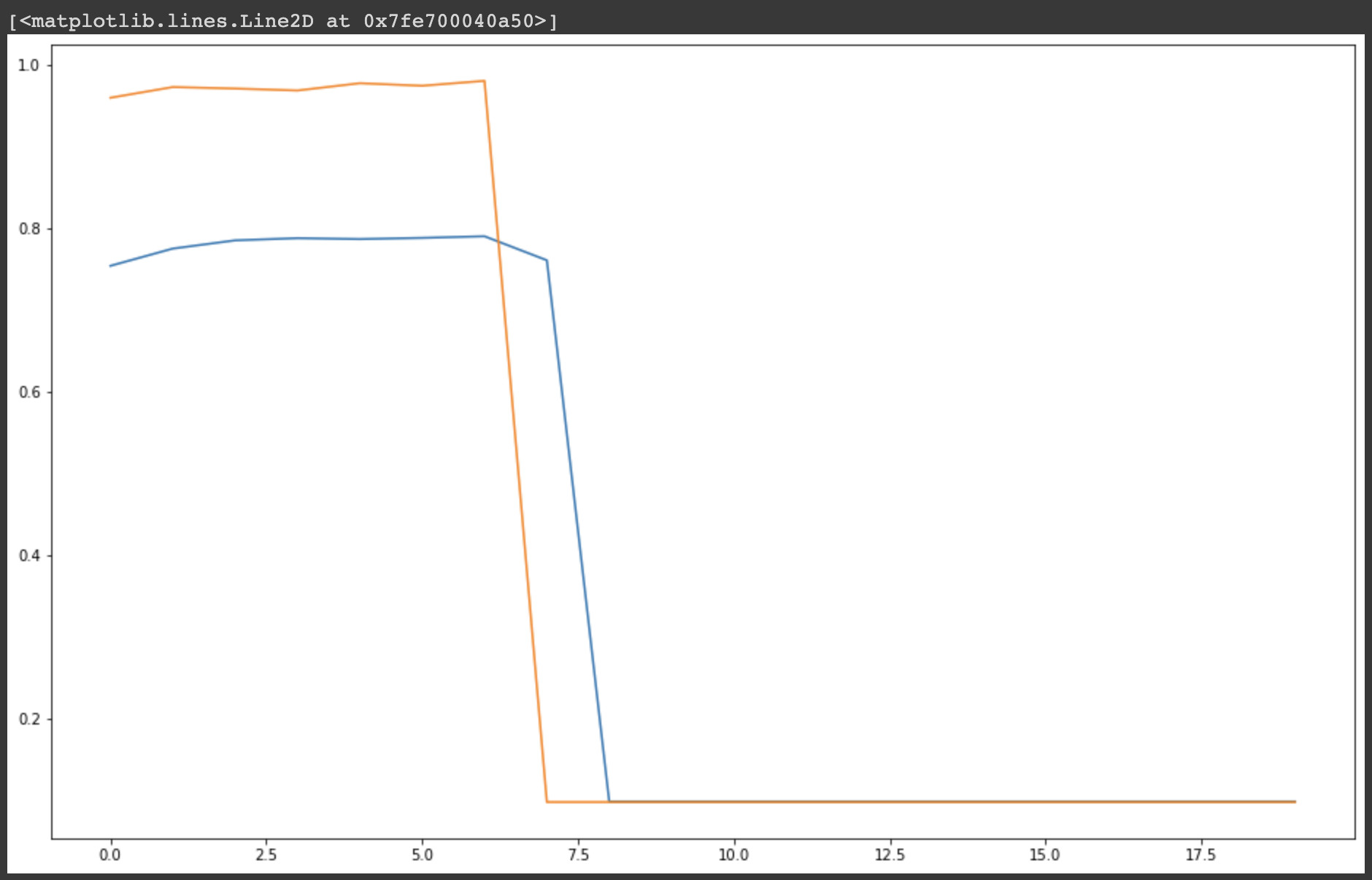
진짜 코랩 gpu 무료로 잘 쓰게 해주었으면 합니다.
딥러닝 할때마다 학습 기다림에 지칩니다..ㅠㅠ
