합성곱 신경망
: Convolutional Neural Network, CNN
- Conv2D
- MaxPooling2D
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))실행 원리
- 합성곱 신경망 (= 피쳐 자동 추출기)
➡️ 어떻게 피쳐를 자동으로 추출할까?
- 필터 (filter)를 랜덤하게 여러 장 만든다. 각 필터의 사이즈는 kernel_size로 칭한다
- 필터를 이미지에 통과시켜서 합성곱 연산을 하여 결과가 나오면 그 결과로 특징을 추출
- 필터를 랜덤하게 만들다보면 1자 모양, '/'모양, 'O'모양, 'ㅁ'모양 이런 패턴들을 랜덤하게 생성한다. 그리고 그 패턴을 통과시켜서 그 패턴이 얼마나 있는지 확인이 가능하다.
- 이러한 패턴들을 여러 장 만든다.
Pooling 풀링
: 합성곱층에서 받은 최종 출력 데이터( Activation Map )의 크기를 줄이거나 특정 데이터를 강조한다.
➡️ 데이터의 사이즈를 줄여주며 노이즈를 상쇄시키고, 미세한 부분에서 일관적인 특징을 제공한다.
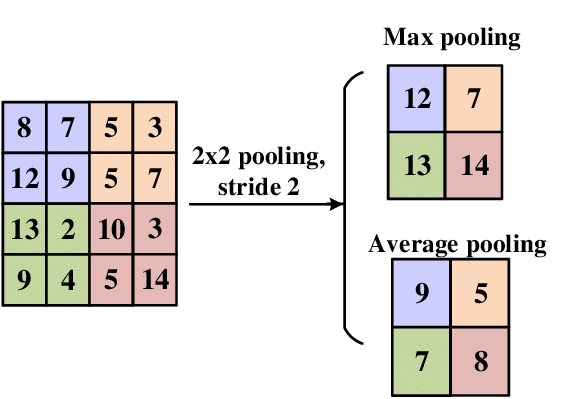
<Pooling Layers 처리하는 방법>
- Max Pooling(최댓값)
- Average Pooling (평균값)
- Min Pooling (최솟값)
➡️ 보통은 합성곱 과정에서 만들어진 특징들의 가장 큰 값들만 가져와서 사이즈 감소 (Max Pooling)
-> 이미지 크기를 줄여 계산을 효율적으로 하고 데이터를 압축하는 효과가 있기 때문에 오버피팅을 방지해주기도 함.
-> 이미지를 추상화 해주기 때문에 너무 자세히 학습하지 않도록 해서 오버피팅을 방지
-> 대체적으로 컬러이미지에는 Max Pooling, 흑백이미지에는 Min Pooling 사용
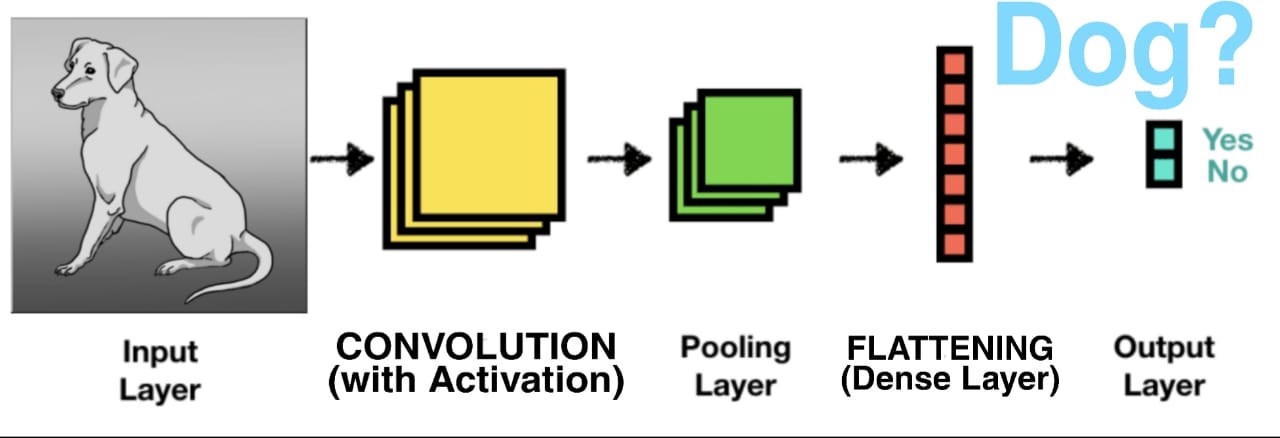
CNN
✅ Convolution 연산을 하면 filter, kernel_size 에 해당하는 filter의 개수만큼 통과시켜서 feature map을 생성한다.
➡️ CNN(= 피처자동추출기) : 비정형 이미지를 입력했을 때 이미지를 전처리하지 않고 그대로 넣어주면 알아서 feature map 생성한다.
➡️ Feature map : feature가 어떤 특징을 갖고 있는지 나타남. 선이 있는지, 0, 1 다양한 모양을 랜덤하게 생성해서 통과시키면 해당 특징이 있는지 학습하게 하는건 convolution 연산
✅ Activation Function(활성화함수)를 통과시킨 output을 activation map을 생성한다
➡️ relu 함수를 사용하게 되면 출력값에 활성화 함수를 적용한 Activation map 반환
✅ TF API
model.add(layers.Conv2D(filters=64, kernel_size=(3, 3),
activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))✅ Padding, Striding 등을 사용해서 입력과 출력사이즈를 조정, Stride는 필터의 이동 보폭을 조정한다.
DNN을 이미지 데이터에 사용했을 때 단점
- Flatten() 으로 1차원 벡터 형태로 주입을 해야하기 때문에 인접 공간에 대한 정보를 잃게 된다.
- 1차원 형태로 주입을 해주게 되면 입력값이 커서 계산이 오래 걸림
➡️ DNN의 단점을 보완한 CNN의 특징
-
Conv, Pooling 연산을 하게 되면 데이터의 공간적인 특징을 학습하여 어떤 패턴이 있는지 알게 됨
-
Pooling을 통해 데이터를 압축하면 데이터의 용량이 줄어들며, 추상화를 하기 때문에 너무 자세히 학습하지 않게 됨. 오버피팅 방지한다.
DNN ↔️ CNN ( 가장 큰 차이 )
: 1차원 flatten 해서 넣어주는 게 아니라 Conv, Pooling 연산을 통해 특징을 학습하고 압축한 결과를 flatten 해서 DNN에 넣어준다.
