RNN으로 주가 예측
https://www.tensorflow.org/tutorials/structured_data/time_series
📍 실습 순서
1. 데이터 로드
2. x, y 데이터셋 나누기
3. 정규화 (Min-Max Scaling)
4. 윈도우 방식으로 x, y값 만들기
5. 순서 고려하여 데이터셋 나누기
6. 모델 만들고 예측
데이터 로드
!pip install finance-datareader
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import FinanceDataReader as fdr
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout주가 수집
- 삼성전자 ("005930")
df = fdr.DataReader("005930", "2020")
df.shape
>>>>
(734, 6)
df.head(2)
>>>>
Open High Low Close Volume Change
Date
2020-01-02 55500 56000 55000 55200 12993228 -0.010753
2020-01-03 56000 56600 54900 55500 15422255 0.005435
df.tail(2)
>>>>
Open High Low Close Volume Change
Date
2022-12-16 58300 59500 58300 59500 13033596 0.003373
2022-12-19 59500 59500 59100 59500 1342580 0.000000문제, 답안 나누기
df_ohlcv = df.iloc[:, :-1]
dfx = df_ohlcv.drop(columns="Close")
dfy = df_ohlcv["Close"]
dfx.shape, dfy.shape
>>>>
((734, 4), (734,))
# 기술통계값
dfx.describe()
>>>>
Open High Low Volume
count 734.000000 734.000000 734.000000 7.340000e+02
mean 66899.727520 67516.348774 66269.822888 1.853337e+07
std 11169.939924 11202.495204 11133.059435 8.707077e+06
min 42600.000000 43550.000000 42300.000000 1.342580e+06
25% 58000.000000 58700.000000 57500.000000 1.297905e+07
50% 66450.000000 67050.000000 66050.000000 1.639687e+07
75% 77375.000000 77775.000000 76600.000000 2.162467e+07
max 90300.000000 96800.000000 89500.000000 9.030618e+07문제 데이터 시각화
dfx.plot()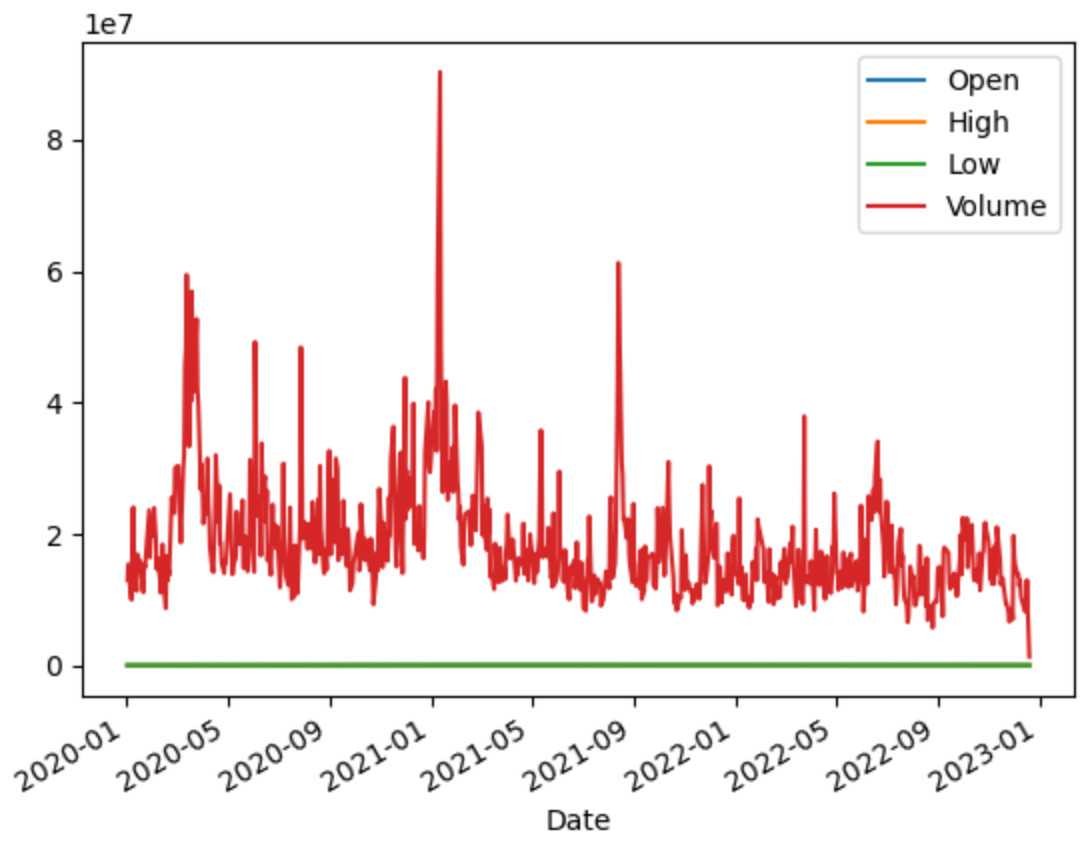
정규화
- MinMaxScaler
- 복원을 위해 x, y 따로 스케일링
- 스케일링 후 list 형태로 변환하기
- fit_transform 할 때는 1차원 데이터는 X -> to_frame()을 통해 2차원 변경
from sklearn.preprocessing import MinMaxScaler
mmsx = MinMaxScaler()
mmsy = MinMaxScaler()
x_mm = mmsx.fit_transform(dfx)
y_mm = mmsy.fit_transform(dfy.to_frame())
x_mm.shape, y_mm.shape
>>>>
((734, 4), (734, 1))- 변수 별로 스케일링 해준 값은 윈도우를 고려하지 않은 값이다.
➡️ 이전 시점의 데이터가 각 행에 들어있지 않고 해당 시점의 스냅샷만 있는 상태 - 윈도우를 고려하여 데이터를 만들 예정
x, y 값 window_size 적용
- 윈도우를 하나씩 이동하면서 데이터를 만들어 줄 예정
- 이전 10일치를 이용하여 그 다음날 종가를 예측
- 한 칸씩 이동하면서 데이터 만들 예정
len(y_mm)
>>>> 734
window_size = 10
len(y_mm) - window_size
>>>>
724
x_mm[0:10], y_mm[10]
>>>>
(array([[0.27044025, 0.23380282, 0.2690678 , 0.13095972],
[0.28092243, 0.24507042, 0.26694915, 0.15826333],
[0.25786164, 0.22629108, 0.26059322, 0.10044975],
[0.27463312, 0.24131455, 0.28177966, 0.0974241 ],
[0.2851153 , 0.2600939 , 0.28813559, 0.24907481],
[0.3312369 , 0.28262911, 0.31991525, 0.25583497],
[0.33962264, 0.30328638, 0.33898305, 0.16475941],
[0.35639413, 0.30892019, 0.3559322 , 0.11259166],
[0.37316562, 0.32769953, 0.37288136, 0.17494476],
[0.35429769, 0.30140845, 0.35169492, 0.14565899]]),
array([0.37525773]))
- window_size 만큼 슬라이싱
- 이전 10일치 데이터로 다음날 주가 예측
- 다음날 종가는 포함하지 않도록 x값을 만들고
- 다음날 종가를 y로 만든다.
from tqdm import trange
x_data = []
y_data = []
for start in trange(len(y_mm) - window_size):
stop = start+window_size
print("start:", start, "stop:", stop)
x_data.append(x_mm[start:stop])
y_data.append(y_mm[stop])train, test 나누기
- 8:2로 나누기
split_size = int(len(x_data)*0.8)
split_size
>>>>
579
X_train = np.array(x_data[:split_size])
y_train = np.array(y_data[:split_size])
X_test = np.array(x_data[split_size:])
y_test = np.array(y_data[split_size:])
X_train.shape, y_train.shape, X_test.shape, y_test.shape
>>>>
((579, 10, 4), (579, 1), (145, 10, 4), (145, 1))모델 생성
- LSTM
from tensorflow.keras.layers import Dense, Bidirectional
data_size = dfx.shape[1]
model = Sequential()
model.add(LSTM(units=64, activation='relu', return_sequences=True,
input_shape=X_train[0].shape))
model.add(Bidirectional(LSTM(units=64, return_sequences=True)))
model.add(Bidirectional(LSTM(units=64, return_sequences=True)))
model.add(Bidirectional(LSTM(units=64)))
model.add(Dropout(0.05))
model.add(Dense(units=1))
model.summary()
>>>>
Model: "sequential_11"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_24 (LSTM) (None, 10, 64) 17664
bidirectional_4 (Bidirectio (None, 10, 128) 66048
nal)
bidirectional_5 (Bidirectio (None, 10, 128) 98816
nal)
bidirectional_6 (Bidirectio (None, 128) 98816
nal)
dropout_8 (Dropout) (None, 128) 0
dense_8 (Dense) (None, 1) 129
=================================================================
Total params: 281,473
Trainable params: 281,473
Non-trainable params: 0
_________________________________________________________________complie
model.compile(optimizer='adam',
loss='mse',
metrics=['mse', 'mae'])학습과 예측
history = model.fit(X_train, y_train, epochs=100, batch_size=30)
history
df_hist = pd.DataFrame(history.history)
df_hist.tail()
>>>>
loss mse mae
95 0.001018 0.001018 0.024697
96 0.001052 0.001052 0.025547
97 0.001030 0.001030 0.024488
98 0.000957 0.000957 0.024064
99 0.000958 0.000958 0.023762- 시각화
pd.DataFrame(history.history).plot()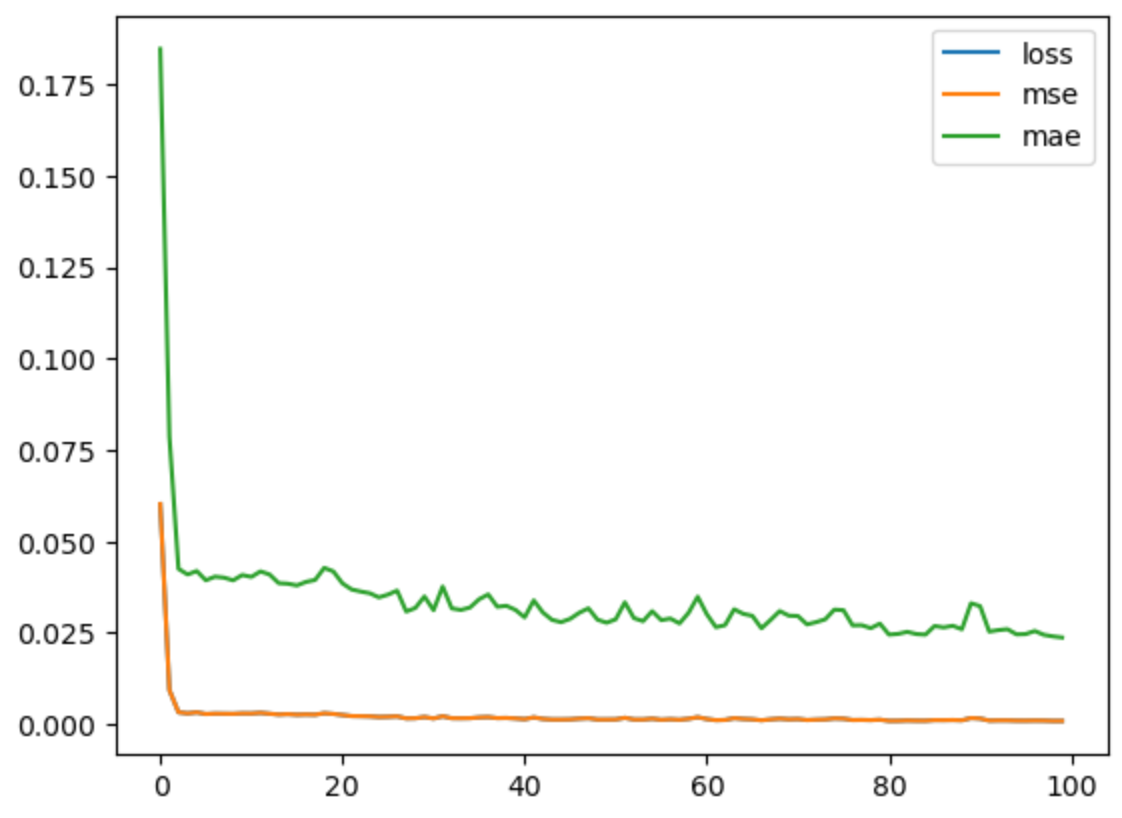
- 예측
y_pred = model.predict(X_test)
y_pred[:5]
>>>>
array([[0.5018468 ],
[0.5099241 ],
[0.51882905],
[0.5098167 ],
[0.49872634]], dtype=float32)rmse
rmse = ((y_test - y_pred) ** 2).mean() ** 0.5
>>>>
0.02397817505628904예측결과 시각화
pd.DataFrame({'test': y_test.flatten(),
"predict:" y_pred.flatten()}).plot(figsize=(12, 5))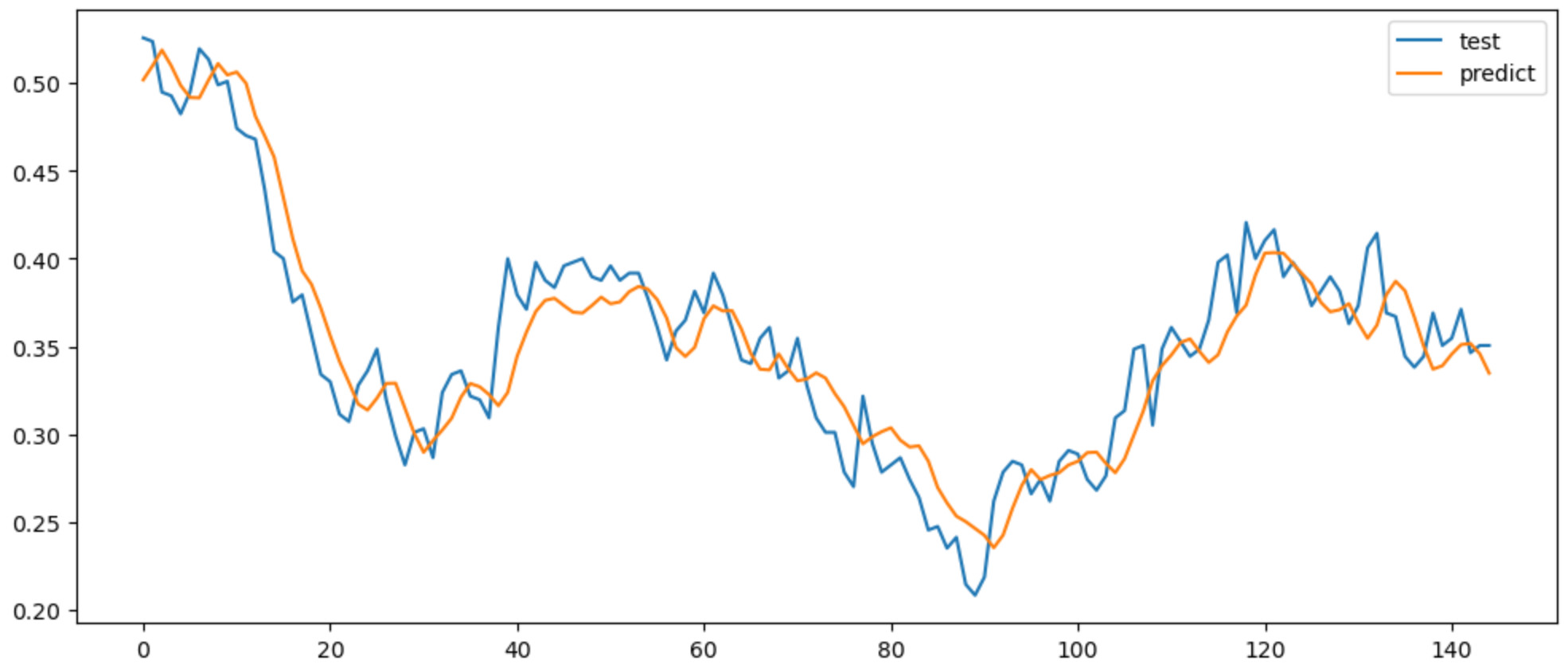
원래 값으로 복원하여 비교
- 스케일링으로 처리했던 값 복원
y_predict_inverse = mmsy.inverse_transform(y_pred)
y_predict = y_predict_inverse.flatten()
y_predict[:5]
>>>>
array([66839.57, 67231.32, 67663.21, 67226.11, 66688.23], dtype=float32)# 방법 1
y_test_inverse = mmsy.inverse_transform(y_test)
y_test_inverse = y_test_inverse.flatten()
rmse = ((y_test_inverse - y_predict) ** 2).mean() ** 0.5
rmse
>>>>
1162.9414395035483
# 방법 2
y_test_origin = dfy[:10][split_size:]
rmse = ((y_test_origin - y_predict) **2).mean() ** 0.5
rmse
>>>>
1162.9414395035474시각화
pd.DataFrame({'test' : y_test_origin,
'predict': y_predict}).plot(figsize=(12, 5))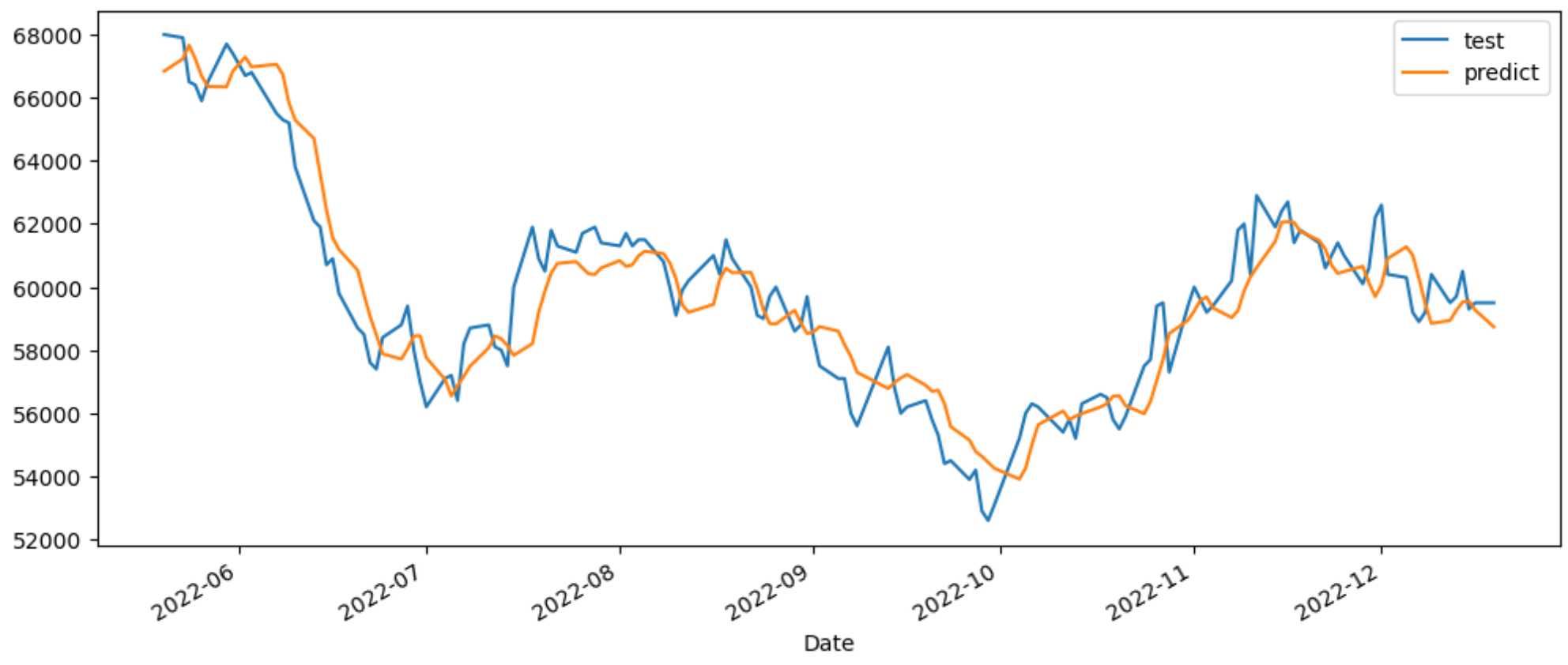

Ⓓ🅰️🅣🄰 ♡♥︎