https://www.kaggle.com/competitions/titanic
라이브러리 로드
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt데이터셋 로드
train = pd.read_csv("data/titanic/train.csv", index_col='PassengerId')
print(train.shape)
train.head()
=> (891, 11)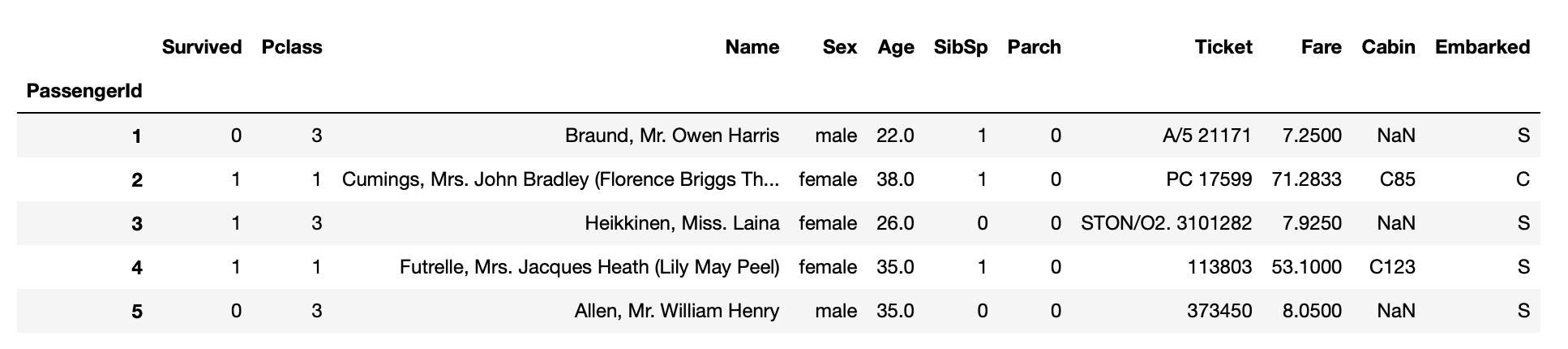
test = pd.read_csv("data/titanic/test.csv", index_col="PassengerId")
print(test.shape)
test.head()
=> (418, 10)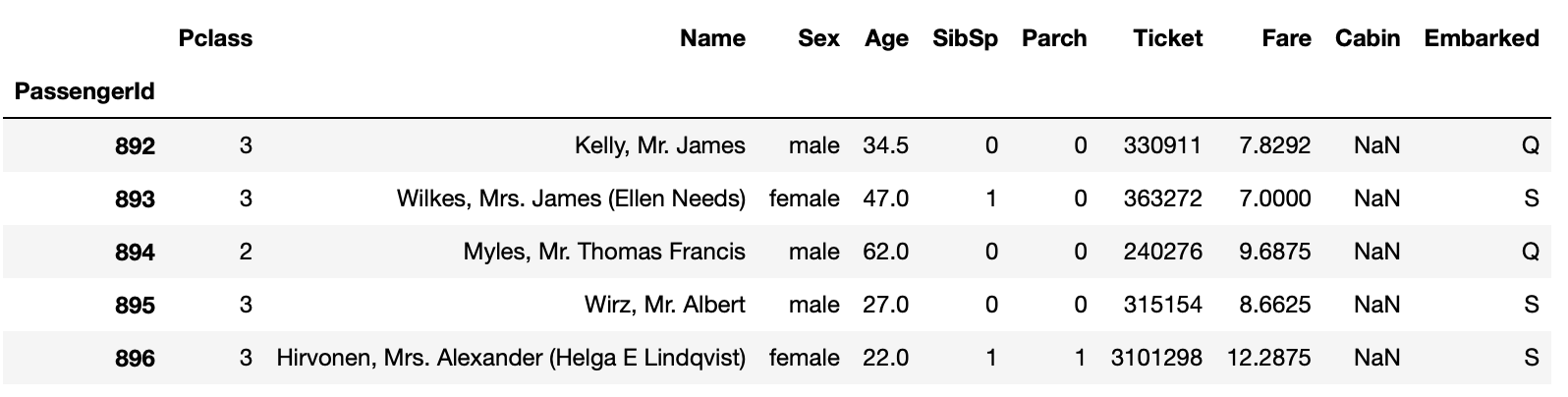
label 값 빈도수
sns.countplot(data=train, x="Survived", hue="Sex")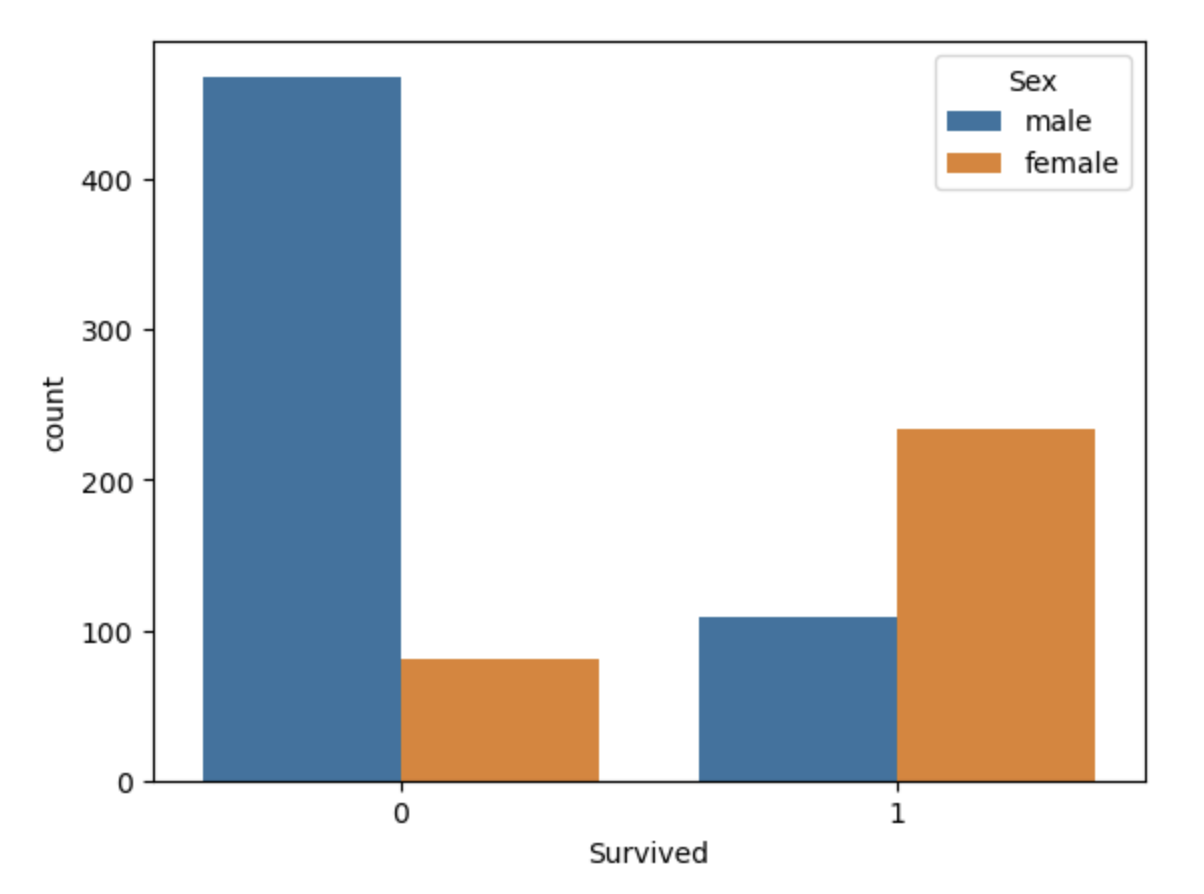
결측치
train.innull().mean() * 100
=>
Survived 0.000000
Pclass 0.000000
Name 0.000000
Sex 0.000000
Age 19.865320
SibSp 0.000000
Parch 0.000000
Ticket 0.000000
Fare 0.000000
Cabin 77.104377
Embarked 0.224467
dtype: float64
test.isnull().mean() * 100
=>
Pclass 0.000000
Name 0.000000
Sex 0.000000
Age 20.574163
SibSp 0.000000
Parch 0.000000
Ticket 0.000000
Fare 0.239234
Cabin 78.229665
Embarked 0.000000
dtype: float64학습과 예측 전체 과정
feature_names : 학습(훈련), 예측에 사용할 컬럼을 리스트 형태로 만들어서 변수에 담아줌.
label_name : 정답값
X_train : feature_names 에 해당되는 컬럼만 train에서 가져온다.
학습(훈련)에 사용할 데이터셋 예) 시험의 기출문제
X_test : feature_names 에 해당되는 컬럼만 test에서 가져온다
예측에 사용할 데이터셋 예) 실전 시험문제
y_train : label_name 에 해당 되는 컬럼만 train에서 가져온다.
학습(훈련)에 사용할 정답 값 예) 기출문제의 정답
model : 학습, 예측에 사용할 머신러닝 알고리즘
model.fit(X_train, y_train) : 학습(훈련), 기출문제와 정답을 가지고 학습(훈련)하는 과정과 유사.
model.predict(X_test) : 예측, 실제 시험을 보는 과정과 유사. => 문제를 풀어서 정답을 구한다.
score : 시험을 봤다면 몇 문제를 맞고 틀렸는지 채점
metric : 점수를 채점하는 공식. (예를 들어 학교에서 중간고사를 봤다면 전체 평균을 계산.)정답값이자 예측할 값
train.columns
=>
Index(['Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket',
'Fare', 'Cabin', 'Embarked'],
dtype='object')
# 수치 데이터 컬럼만 가져오기 -> 머신러닝 내부에서 연산하기 위해
train.select_dtype(include="number").columns
=> Index(['Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Fare'], dtype='object')
label_name = "Survived"학습, 예측 컬럼
# binary encoding -> 성별은 중요한 역할 (문자 형태면 연산 불가능)
# 수치 데이터로 변환하는 인코딩 작업
train["Gender"] = train["Sex"] == 'female'
test["Gender"] = test["Sex"] == 'female'
feature_names = ['Pclass', 'Age', 'SibSp', 'Parch', 'Fare', 'Gender']
feature_names
=> ['Pclass', 'Age', 'SibSp', 'Parch', 'Fare', 'Gender']학습, 예측 데이터셋 만들기
X_train = train[feature_names].fillna(0)
print(X_train.shape)
print("결측치 합계 : ", X_train.isnull().sum().sum())
X_train.head()
=> (891, 6)
결측치 합계 : 0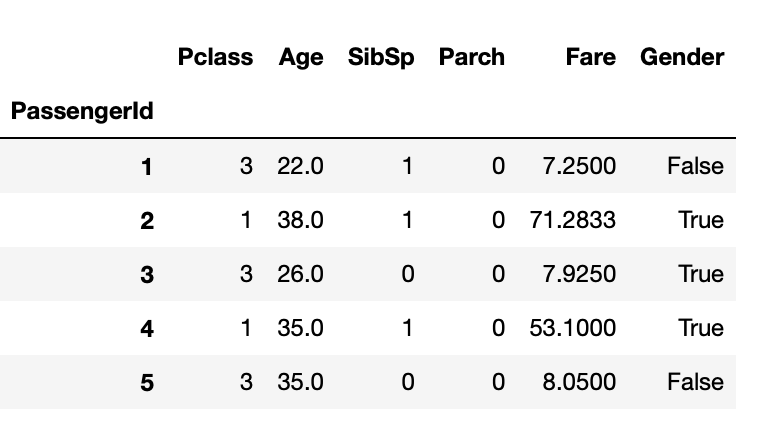
X_test = test[feature_names].fillna(0)
print(X_test.shape)
print("결측치 합계 : ", X_test.isnull().sum().sum())
X_test.head()
=> (418, 6)
결측치 합계 : 0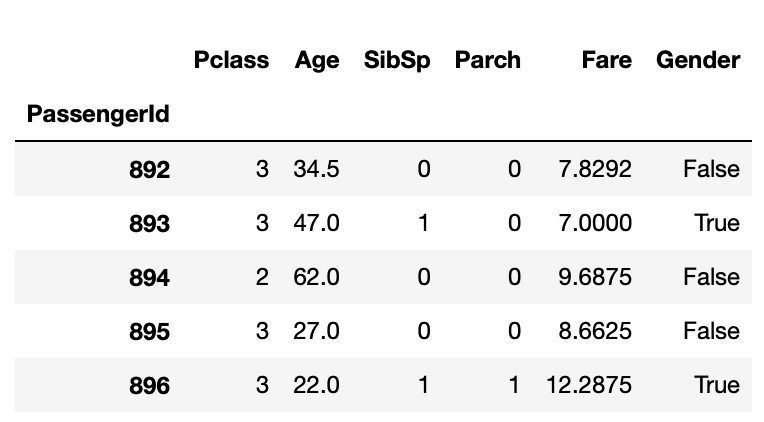
y_train = train[label_name]
print(y_train.shape)
y_train.head()
=>
(891,)
PassengerId
1 0
2 1
3 1
4 1
5 0
Name: Survived, dtype: int64머신러닝 알고리즘
DecisionTreeClassifier(
*,
criterion='gini', # 분할방법 {"gini", "entropy"}, default="gini"
splitter='best',
max_depth=None, # The maximum depth of the tree
min_samples_split=2, # The minimum number of samples required to split an internal node
min_samples_leaf=1, # The minimum number of samples required to be at a leaf node.
min_weight_fraction_leaf=0.0, # The minimum weighted fraction of the sum total of weights
max_features=None, # The number of features to consider when looking for the best split
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
class_weight=None,
ccp_alpha=0.0,
)
- 주요 파라미터
criterion: 가지의 분할의 품질을 측정하는 기능
max_depth: 트리의 최대 깊이
min_samples_split:내부 노드를 분할하는 데 필요한 최소 샘플 수
min_samples_leaf: 리프 노드에 있어야 하는 최소 샘플 수
max_leaf_nodes: 리프 노드 숫자의 제한치
random_state: 추정기의 무작위성을 제어합니다. 실행했을 때 같은 결과가 나오도록 함.from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(criterion="entropy", random_state=42)
model
=> DecisionTreeClassifier(criterion='entropy', random_state=42)학습(훈련)
model.fit(X_train, y_train)
=> DecisionTreeClassifier(criterion='entropy', random_state=42)예측
y_predict = model.predict(X_test)
y_predict[:5]
=> array([0, 0, 1, 1, 0])트리 알고리즘 분석
지니 계수
- class들이 공평하게 섞여 있을수록 지니계수는 상승
- 결정트리는 지니 불순도를 낮추는 방향으로 가지치기를 진행
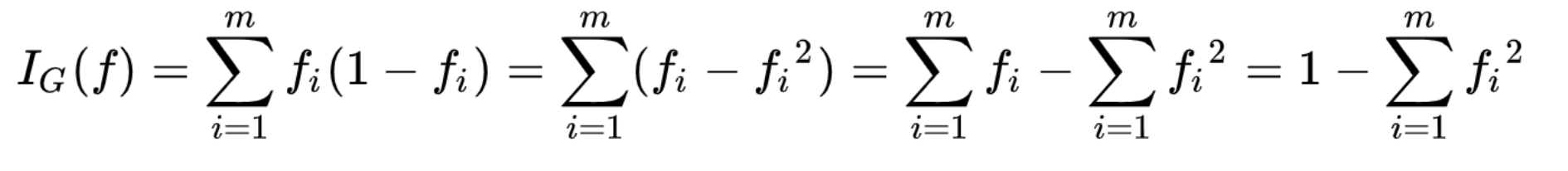
로그
- 지수 함수의 역함수
엔트로피
- 무질서한 정도를 정량화한 값
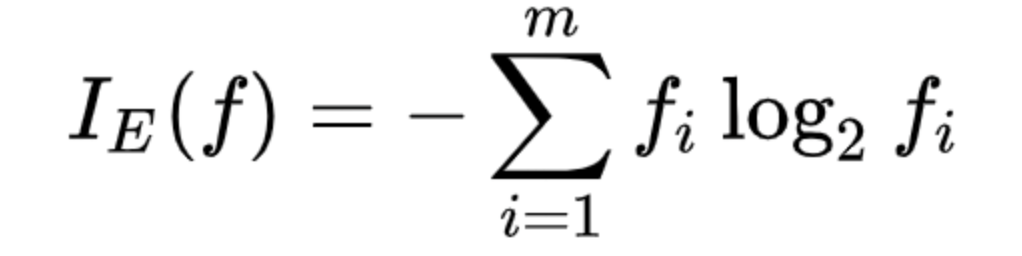
# 엔트로피 공식
-((3/50)*np.log2(3/50) + (47/50)*np.log2(47/50))
# 루트노드의 엔트로피 구하기
- ((549/891) * np.log2(549/891) + (342/891) * np.log2(342/891))
=> 0.9607079018756469시각화
from sklearn.tree import plot_tree
plt.figure(figsize=(12, 6))
plot_tree(model, max_depth=4,
fontsize=10,
filled=True,
feature_names=feature_names)
plt.show()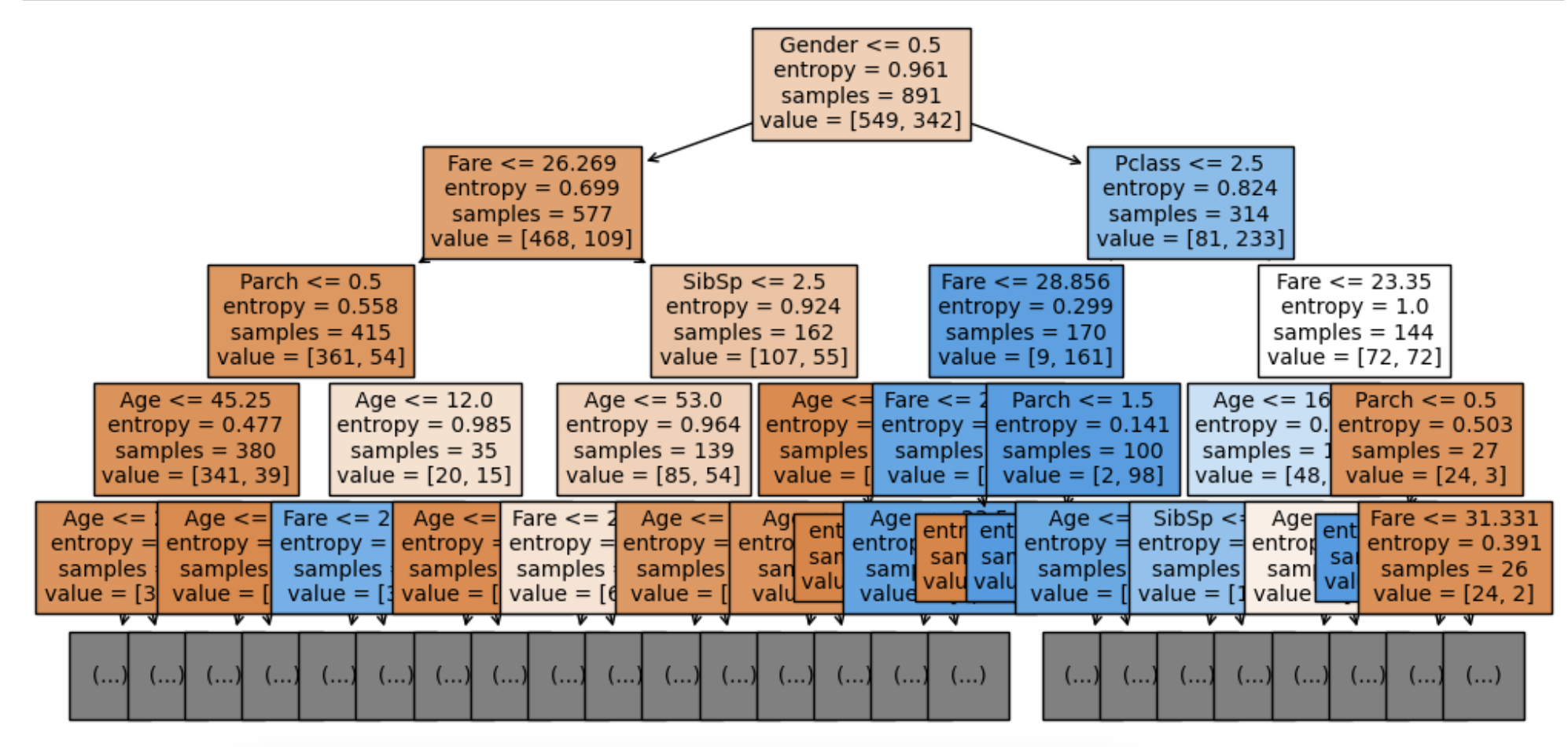
피처 중요도 계산
sns.barplot(x=model.feature_importances_, y=model.feature_names_in_)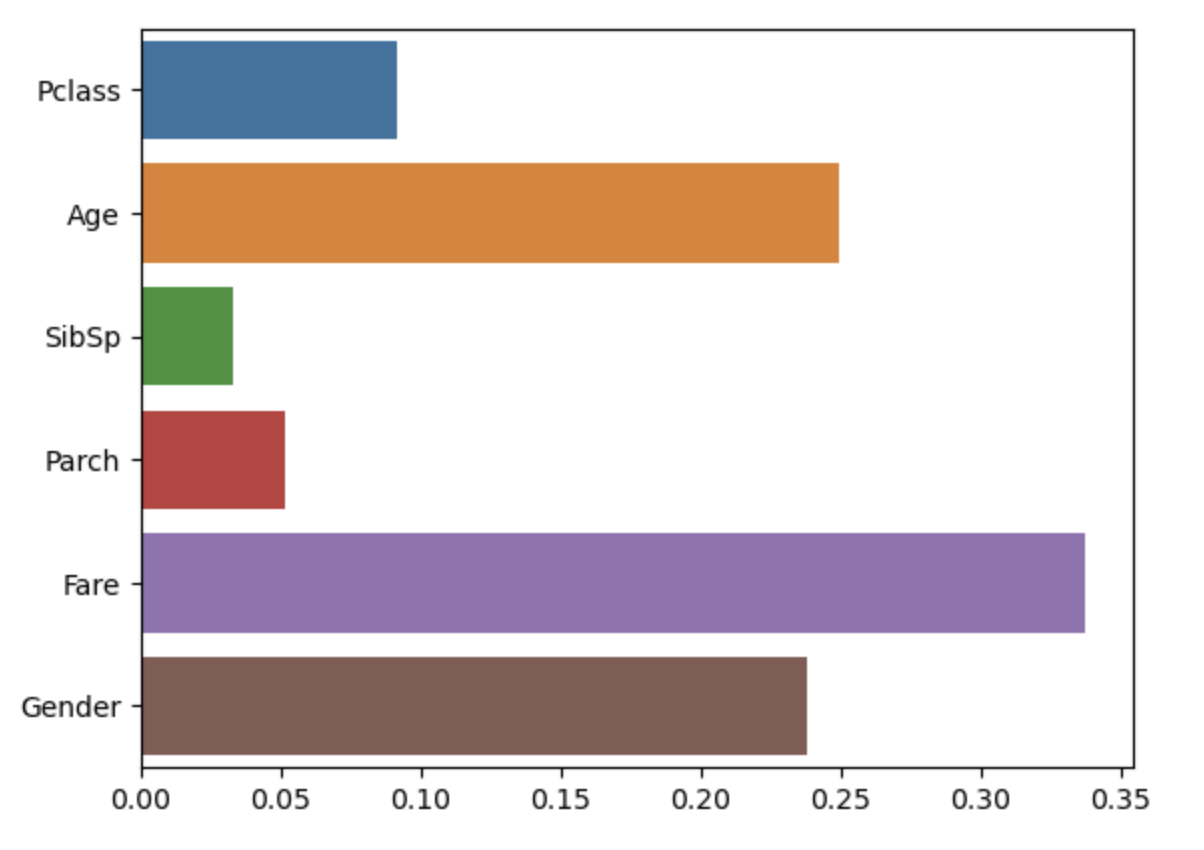
제출하기
submit = pd.read_csv('data/titanic/gender_submission.csv', index_col="PassengerId")
submit.head(2)
=>
Survived
PassengerId
892 0
893 1
submit["Survived"] = y_predict
submit.to_csv('data/titanic/submit2.csv')

Ⓓ🅰️🅣🄰 ♡♥︎