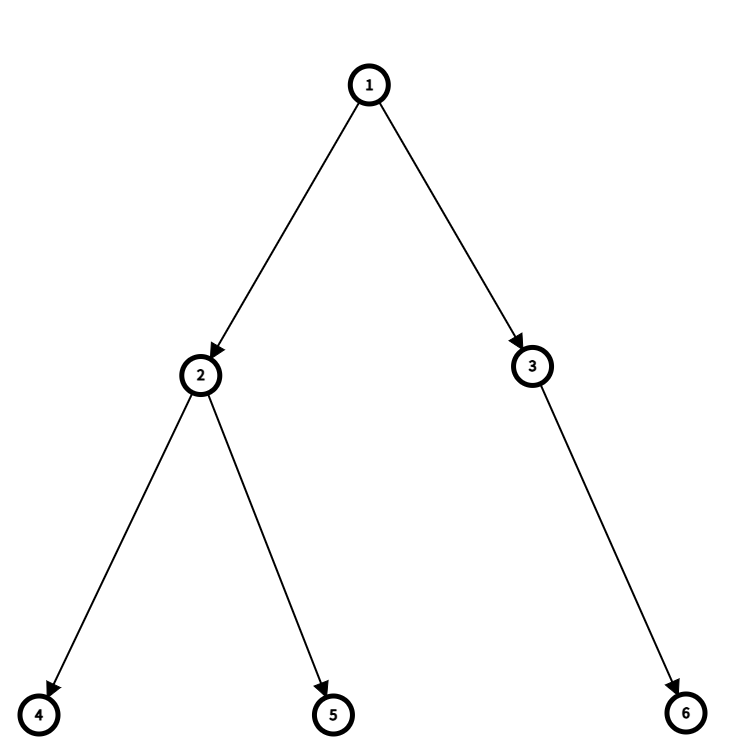
BFS와 DFS를 비교하기 쉽게 동일한 트리 구조를 생성해줍니다.
struct Node {
int data;
Node* left;
Node* right;
Node(int val) : data(val), left(nullptr), right(nullptr) {}
};
// 트리에 속한 노드를 삭제하는 함수
void deleteTree (Node* node) {
if (node == nullptr) return;
deleteTree(node->left);
deleteTree(node->right);
delete node;
}
int main() {
Node* root = new Node(1);
root->left = new Node(2);
root->right = new Node(3);
root->left->left = new Node(4);
root->left->right = new Node(5);
root->right->right = new Node(6);
// 프로그램 종료 전 메모리 누수를 방지하기 위해 node들을 삭제해줍니다.
deleteTree(root);
root = nullptr;
return 0;
}아래의 그림처럼 트리가 생성되었습니다.
너비 우선 탐색 (Breadth First Search, BFS)
그래프나 트리를 탐색하는 알고리즘으로, 시작 노드부터 가까운 노드들을 먼저 탐색하는 방식입니다.
시작 노드의 모든 인접 노드를 먼저 방문한 후, 그 다음 깊이에 있는 노드들을 차례로 방문합니다.
BFS의 핵심 요소
queue
1. 시작 노드를 큐에 넣습니다.
2. 큐에서 노드를 하나 꺼내고, 그 노드의 인접 노드들을 차례로 큐에 넣습니다.
3. 이 과정을 큐가 빌 때까지 반복합니다.
방문 체크(Visited Check)
트리는 사이클이 없는 구조이므로, 동일한 노드를 여러 번 방문할 일이 없어 따로 방문 체크를 하지 않습니다.
다만, 그래프에는 사이클이 존재하거나, 여러 경로를 통해 한 노드에 도달할 수 있습니다. 따라서 방문 체크를 하지 않으면 무한 루프(Infinite Loop)에 빠지거나, 같은 노드를 여러 번 탐색하는 비효율적인 연산이 발생합니다.
구현
void bfs(Node* root) {
if (root == nullptr) return;
std::queue<Node*> q;
q.push(root);
while (!q.empty()) {
Node* current = q.front();
q.pop();
std::cout << current->data << std::endl;
if (current->left != nullptr) q.push(current->left);
if (current->right != nullptr) q.push(current->right);
}
}전체 코드
#include <iostream>
#include <vector>
#include <queue>
struct Node {
int data;
Node* left;
Node* right;
Node(int val) : data(val), left(nullptr), right(nullptr) {}
};
void deleteTree(Node* node) {
if (node == nullptr) return;
deleteTree(node->left);
deleteTree(node->right);
delete node;
}
void bfs(Node* root) {
if (root == nullptr) return;
std::queue<Node*> q;
q.push(root);
while (!q.empty()) {
Node* current = q.front();
q.pop();
std::cout << current->data << " ";
if (current->left != nullptr) q.push(current->left);
if (current->right != nullptr) q.push(current->right);
}
}
int main() {
Node* root = new Node(1);
root->left = new Node(2);
root->right = new Node(3);
root->left->left = new Node(4);
root->left->right = new Node(5);
root->right->right = new Node(6);
bfs(root);
deleteTree(root);
root = nullptr;
return 0;
}결과
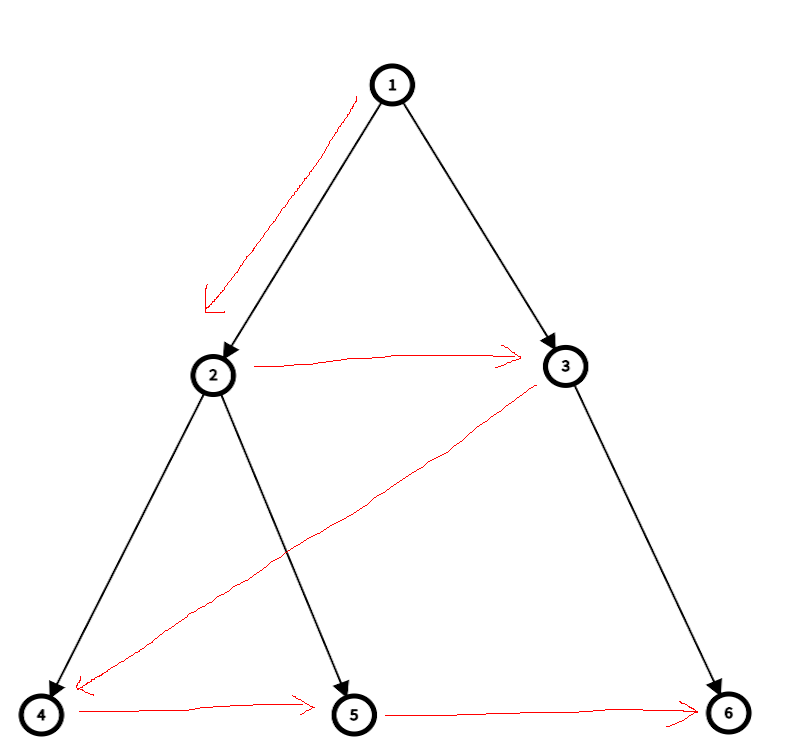

로직으로 보기
1. 시작 노드 삽입:
- 큐에 시작 노드인 1을 넣습니다. (큐: [1])
2. 노드 방문 및 자식 노드 추가:
- 큐의 맨 앞에서 1을 꺼내 방문(출력)합니다.
- 1의 자식 노드인 2와 3을 큐에 순서대로 넣습니다. (큐: [2, 3])
3. 다음 레벨 탐색:
- 큐의 맨 앞에서 2를 꺼내 방문합니다.
- 2의 자식 노드인 4와 5를 큐에 순서대로 넣습니다. (큐: [3, 4, 5])
- 큐의 맨 앞에서 3을 꺼내 방문합니다.
- 3의 자식 노드인 6을 큐에 넣습니다. (큐: [4, 5, 6])
4. 마지막 노드들 탐색:
- 큐의 맨 앞에서 4를 꺼내 방문합니다.
- 큐의 맨 앞에서 5를 꺼내 방문합니다.
- 큐의 맨 앞에서 6을 꺼내 방문합니다.
5. 종료:
- 큐가 비었으므로, 탐색이 종료됩니다.
깊이 우선 탐색 (Depth-First Search, DFS)
그래프나 트리를 탐색하는 알고리즘으로 , 시작 노드부터 최대한 깊이 내려가며 탐색하는 방식입니다.
한 경로를 따라 더 이상 나아갈 수 없을 때까지 탐색한 후, 가장 최근에 방문한 노드로 되돌아가(백트래킹), 아직 방문하지 않은 다른 경로를 탐색합니다.
DFS의 핵심 요소
stack 또는 재귀(Recursion)
stack
1. 시작 노드를 스택에 넣고 방문 처리합니다.
2. 스택에서 노드를 하나 꺼냅니다.
3. 꺼낸 노드에 인접한 노드 중 아직 방문하지 않은 노드를 모두 스택에 넣습니다.
(보통 깊이를 먼저 탐색하기 위해 자식 노드를 스택에 넣을 때 오른쪽부터 넣습니다. 왼쪽부터 탐색)
4. 스택이 빌 때까지 2~3번 과정을 반복합니다.
재귀(Recursion)
1. 현재 노드를 방문합니다.
2. 현재 노드의 인접 노드들을 차례로 방문합니다.
3. 인접 노드 중 방문하지 않은 노드가 있다면, 그 노드를 기준으로 다시 DFS 함수를 호출합니다.
재귀(Recursion)는 함수 호출 스택(Call Stack)을 사용하기 때문에, 스택 자료구조를 직접 사용하는 것과 내부적으로 동일한 원리로 동작합니다.
방문 체크(Visited Check)
트리는 사이클이 없는 구조이므로, 동일한 노드를 여러 번 방문할 일이 없어 따로 방문 체크를 하지 않습니다.
다만, 그래프에는 사이클이 존재하거나, 여러 경로를 통해 한 노드에 도달할 수 있습니다. 따라서 방문 체크를 하지 않으면 무한 루프(Infinite Loop)에 빠지거나, 같은 노드를 여러 번 탐색하는 비효율적인 연산이 발생합니다.
구현
stack
void dfs(Node* root) {
if (root == nullptr) return;
std::stack<Node*> s;
s.push(root);
while (!s.empty()) {
Node* current = s.top();
s.pop();
std::cout << current->data << " ";
if (current->right != nullptr) s.push(current->right);
if (current->left != nullptr) s.push(current->left);
}
}재귀(Recursion)
void dfs(Node* node) {
if (node == nullptr) return;
std::cout << node->data << " ";
dfs(node->left);
dfs(node->right);
}전체 코드
stack과 재귀(Recursion)의 결과는 동일하기 때문에 재귀 함수의 전체 코드만을 올립니다.
#include <iostream>
#include <vector>
struct Node {
int data;
Node* left;
Node* right;
Node(int val) : data(val), left(nullptr), right(nullptr) {}
};
void deleteTree(Node* node) {
if (node == nullptr) return;
deleteTree(node->left);
deleteTree(node->right);
delete node;
}
void dfs(Node* node) {
if (node == nullptr) return;
std::cout << node->data << " ";
dfs(node->left);
dfs(node->right);
}
int main() {
Node* root = new Node(1);
root->left = new Node(2);
root->right = new Node(3);
root->left->left = new Node(4);
root->left->right = new Node(5);
root->right->right = new Node(6);
dfs(root);
deleteTree(root);
root = nullptr;
return 0;
}결과
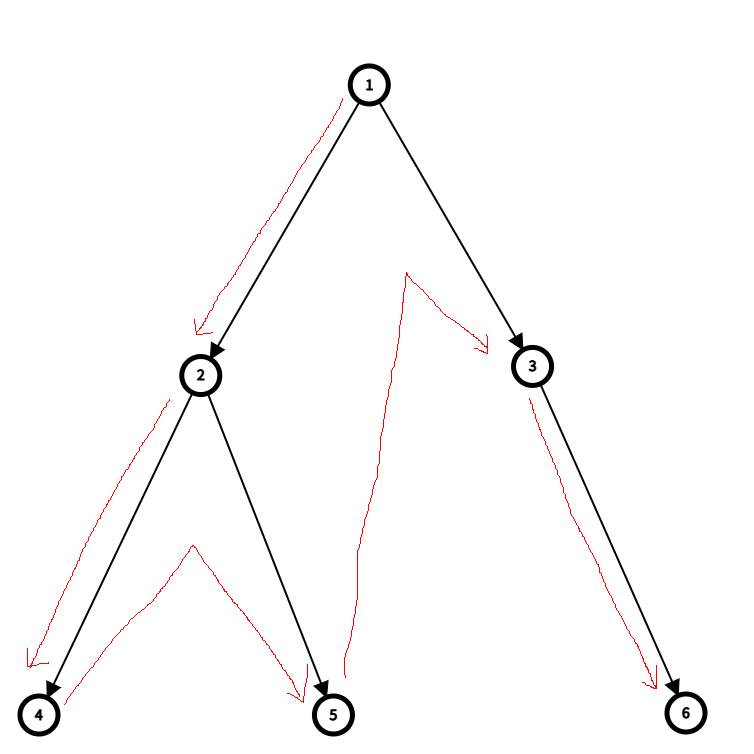

로직으로 보기
1. 시작 노드 방문:
- 시작 노드인 1을 방문(출력)합니다.
2. 왼쪽 서브트리 탐색:
- 1의 왼쪽 자식인 2를 방문합니다.
- 2의 왼쪽 자식인 4를 방문합니다.
- 4는 자식이 없으므로, 더 이상 깊이 들어가지 않고 이전 노드로 돌아옵니다(백트래킹).
3. 다음 경로 탐색:
- 4에서 2로 돌아와서, 2의 오른쪽 자식인 5를 방문합니다.
- 5는 자식이 없으므로, 다시 이전 노드로 돌아옵니다.
4. 다음 큰 가지 탐색:
- 2에서 1로 돌아와서, 1의 오른쪽 자식인 3을 방문합니다.
- 3은 왼쪽 자식이 없으므로, 오른쪽 자식인 6을 방문합니다.
- 6은 자식이 없으므로, 다시 이전 노드로 돌아옵니다.
5. 종료:
- 더 이상 방문할 노드가 없으므로 탐색이 종료됩니다.
끝으로
BFS와 DFS는 모두 그래프와 트리를 탐색하는 강력한 도구이지만, 각자의 특성에 따라 효율적인 활용 분야가 다릅니다.
- BFS는 시작 노드로부터의 최단 경로를 찾을 때 유용합니다.
모든 간선의 길이가 동일한 상황(unweighted graph)에서, BFS는 가장 먼저 목표 노드에 도달하는 경로를 찾기 때문에 최단 경로 탐색에 최적화되어 있습니다. - DFS는 특정 노드에 도달할 수 있는지(reachability)를 확인하거나, 모든 노드를 탐색해야 할 때 효율적입니다. 재귀 방식을 사용하면 코드가 간결해지는 장점도 있습니다.
결론적으로, 두 알고리즘은 탐색 순서라는 명확한 차이점을 가지며, 해결하려는 문제의 성격에 따라 적합한 알고리즘을 선택하는 것이 중요합니다.
알고리즘의 개념 자체를 암기하는 것보다, BFS가 큐를 사용해 '넓게' 탐색하고 DFS가 스택 또는 재귀를 사용해 '깊게' 탐색한다는 핵심 아이디어를 이해하는 것이 더 중요합니다.
이 아이디어를 바탕으로 실제 문제에 적용하고 코드로 구현하는 능력을 기르는 것이 알고리즘 학습의 목표이기 때문입니다.
