
House Price Prediction 경진대회
서울시의 아파트 실거래가를 예측하는 모델을 개발하는 대회로 제공된 아파트 특징 및 거래정보 데이터셋을 기반으로 모델을 학습하고 서울시 각 지역의 아파트 매매 실거래가를 예측한다.
평가 지표
데이터셋
train
- rows = 1,118,822
- columns = 52
국토교통부에서 제공하는 아파트 실거래가 데이터로 아파트의 위치, 크기, 건축 연도, 주변 시설 및 교통 편의성외 다양한 feature를 포함한다.
지하철 정보
서울시에서 제공하는 지하철역의 역사명, 호선, x좌표, y좌표를 포함하고있다.
버스 정류장 정보
서울시에서 제공하는 버스 정류장의 정류장명, x좌표, y좌표를 포함하고있다.
test
- rows = 9,272
- columns = 51
train 데이터와 동일한 feature로 target값 아파트의 실거래가 예측을 위한 데이터이다.
EDA
주어진 데이터의 문제점 파악
결측치
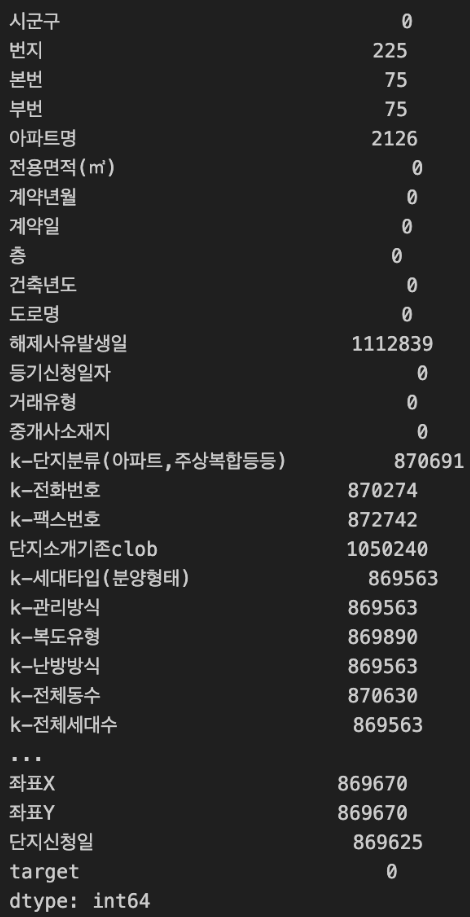
대부분의 feature는 결측치가 80%를 넘겨 각가의 결측치를 모두 크롤링하기에는 2주라는 대회기간이 시간적 한계와 크롤링 정보의 신뢰도 검증에 한계가 있다고 판단하였다.
feature 신뢰도
특정 feature는 동일한 데이터를 다르게 표기하여 데이터 출처에 대한 신뢰도 문제가 있다고 판단했다.
feature 유용성
아파트 가격을 유추하기에 적절한 feature인지에 대한 의문이 드는 feature들이 존재했다. (ex. k-홈페이지, k-팩스번호, k-전화번호 등)
문제점 극복 방안
결측치
모델 예측에 매우 중요한 역할을 할 feature (번지, 본번, 부번, X좌표, Y좌표)와 같이 아파트의 위치 값에도 80% 이상의 결측치가 있었기에 해당 feautre는 크롤링으로 결측치를 처리했다.
크롤링 방법
시군구, 번지를 합쳐 하나의 feature 생성 후 그 중 unique한 값을 추출해 각각의 값에 대해 크롤링을 수행하고 mapping을 수행했다.
feature 신뢰도
실제 값과 비교해보고 크게 오차가 없는 것으로 판단하여 크롤링한 위치 feature를 모델에 사용하기로 결정하였다.
이상치 처리
아파트별 target - 폐기
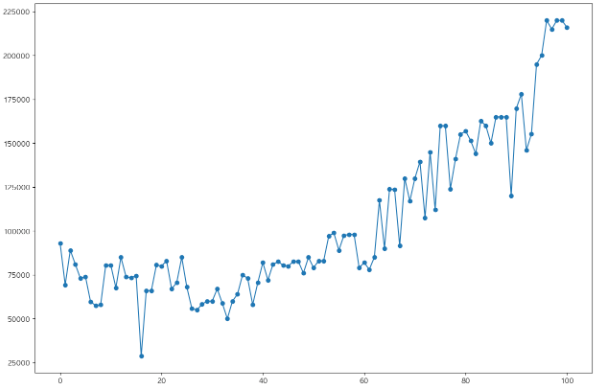
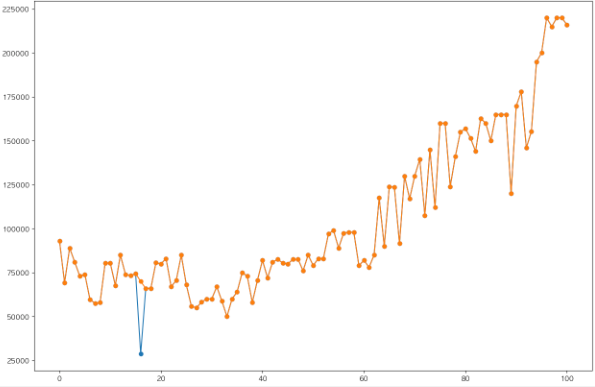
- 아파트별 data 추출
- 계약년월일을 기준으로 정렬
- 좌우 2개씩 4개의 값과 비교하여 튀는 부분 탐지
- 이상치를 4개 값의 평균으로 대체
아파트별 target 값중 각격이 튀는 부분을 탐색 및 조정하였으나 모델 학습에 사용해본 결과 오히려 성능 저하가 발생해 해당 처리는 폐기되었다.
전용면적별 target - 폐기
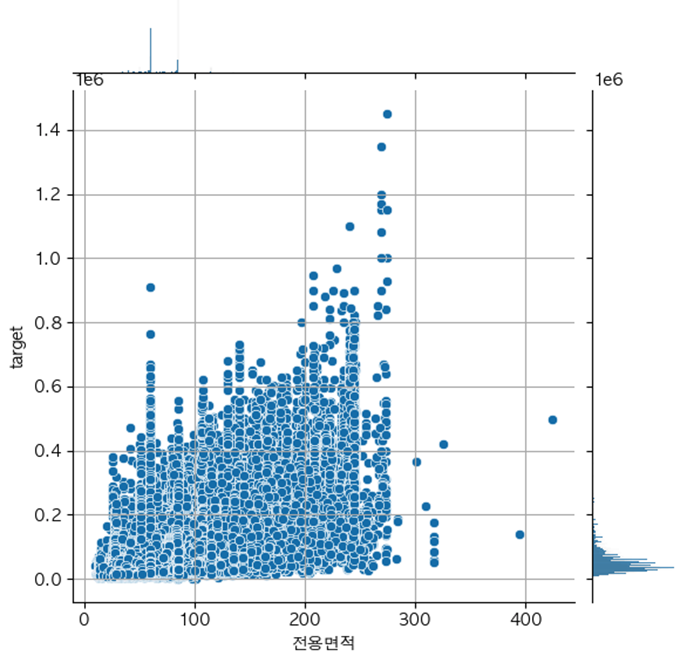
전용면적이 크면 target도 증가할 것이라는 가정으로 전용 면적이 300이 넘는 데이터를 이상치로 판단하여 해당 데이터의 target값을 강제로 2배 상향하였으나 처리되는 값의 개수가 적다보니 모델 학습에 사용해본 결과 성능에 상승효과가 없다고 판단하여 폐기되었다.
층별 target 이상치
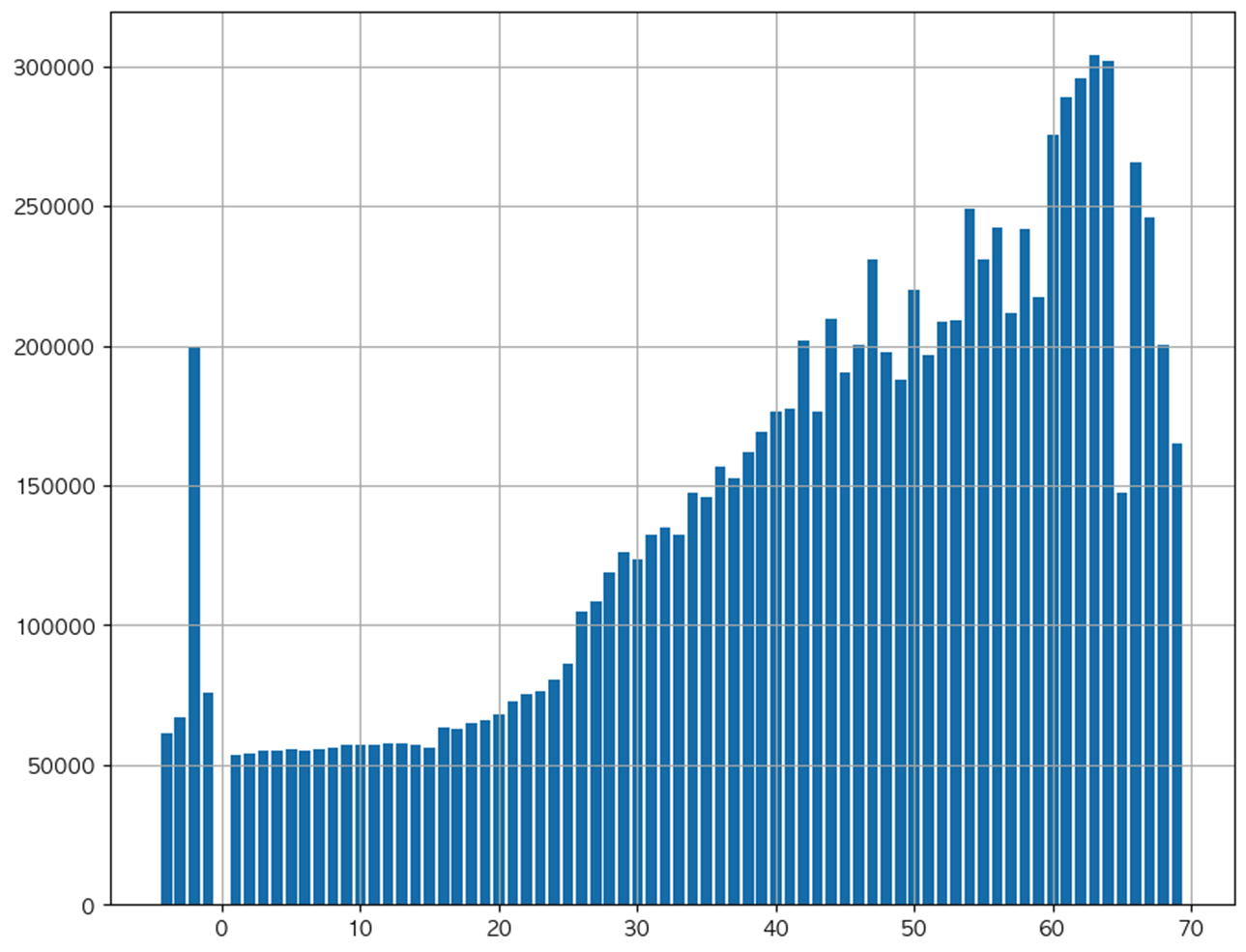
층이 높으면 가격이 상승할 것이라 가정하고 가정과 반대되는 값을 탐색해 해당 데이터를 삭제했으나 성능 향상이 없어 해당 처리를 폐기했다.
Feature Engineering
지하철, 버스 데이터 활용 feature 생성
지하철 관련 feature 생성
- geopy 라이브러리활용
- 가장 가까운 역과의 거리
- 가장 가까운 역사 ID
- 가장 가까운 역사명
- 가장 가까운 호선
- 인근(1.5km 이내) 지하철 역 개수
버스 관련 feature 생성
- geopy 라이브러리활용
- 가장 가까운 정류장과의 거리
- 가장 가까운 정류장 ID
- 인근(300m 이내) 버스 정류장 개수
GDP
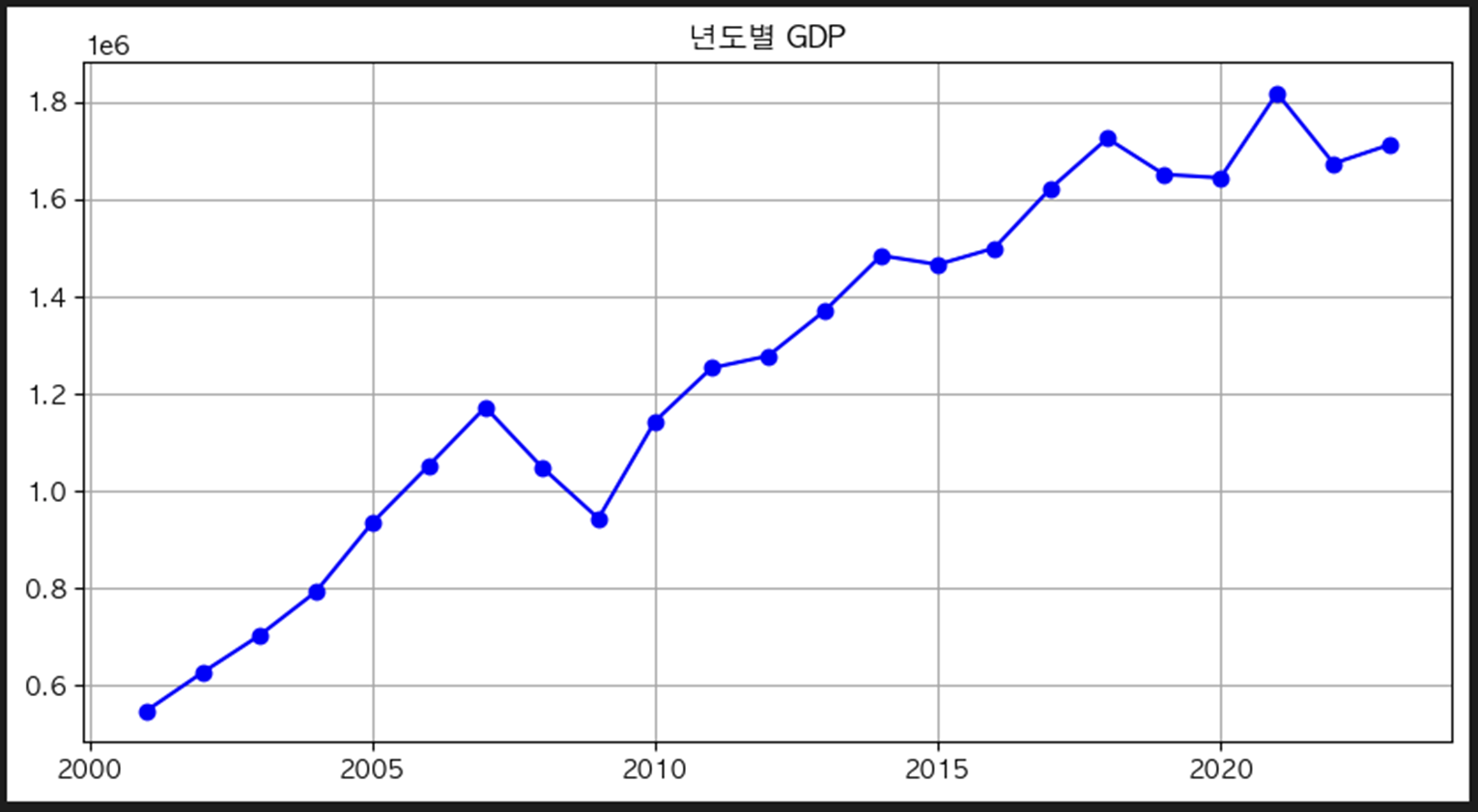
- 국내 년도별 GDP 값 사용
- 각 row당 계약년도에 해당하는 GDP 추가
금리
- 한국은행 기준금리 사용
- 각 row당 계약년월에 해당하는 금리 적용
인플레이션
- 기대 인플레이션율을 계산
- 각 row당 계약년월에 해당하는 계산된 기대 인플레이션율 적용
거래량
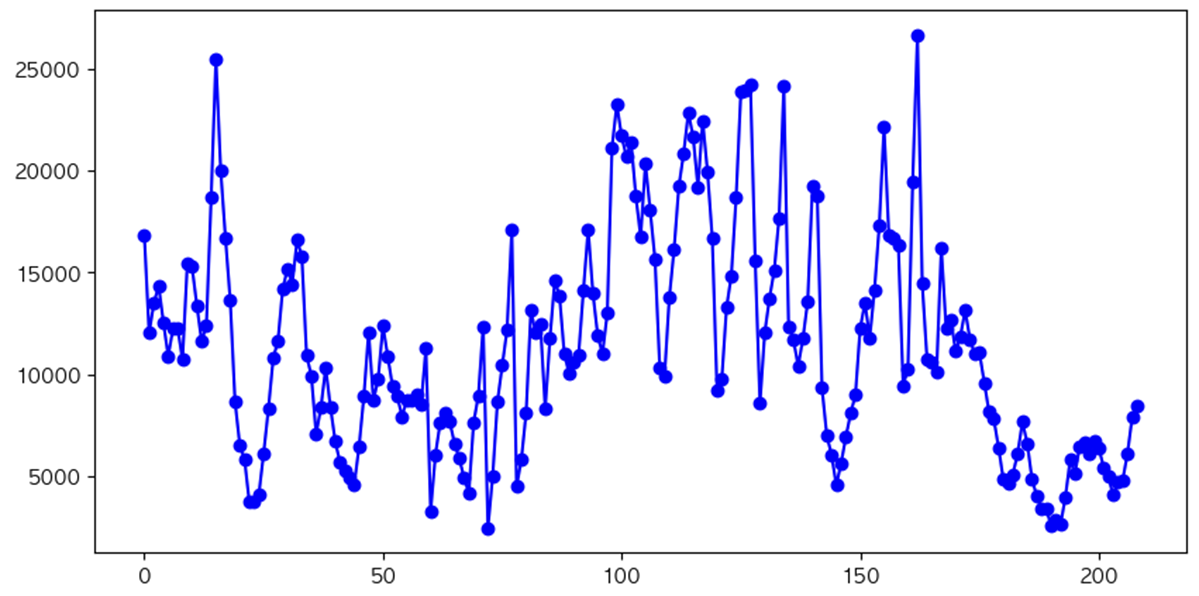
- 주택 거래량 정보
- 각 row당 계약년월에 해당하는 거래량 적용
구별 지가지수
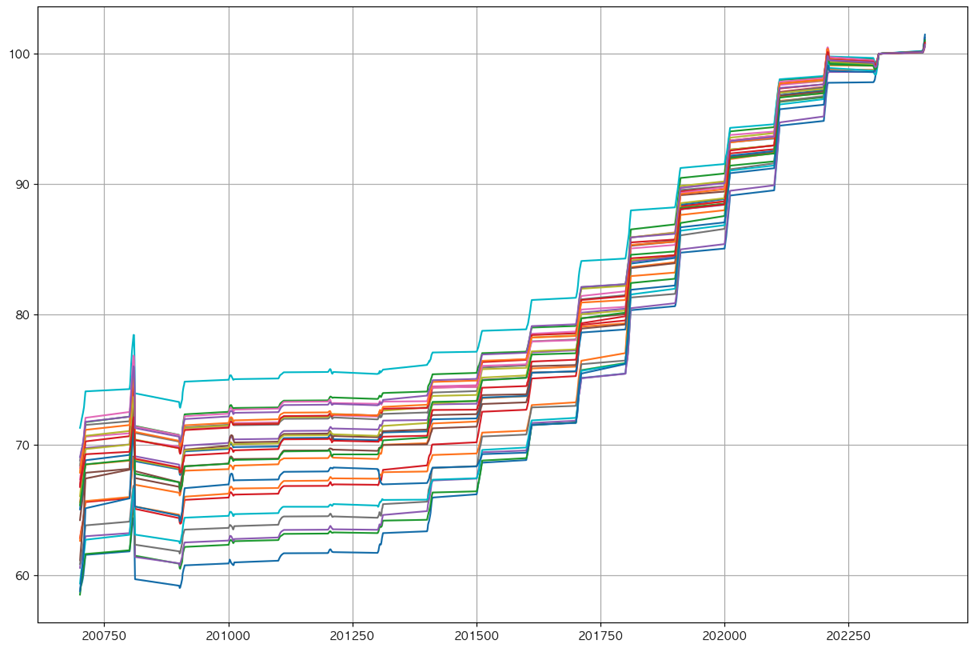
- 각 구별 지가지수
- 구, 계약년월에 해당하는 지가지수 적용
공시지가 평균
- 공시지가 평균 데이터
- 구, 계약년에 맞춰 공시지가 평균 적용
매수우위지수
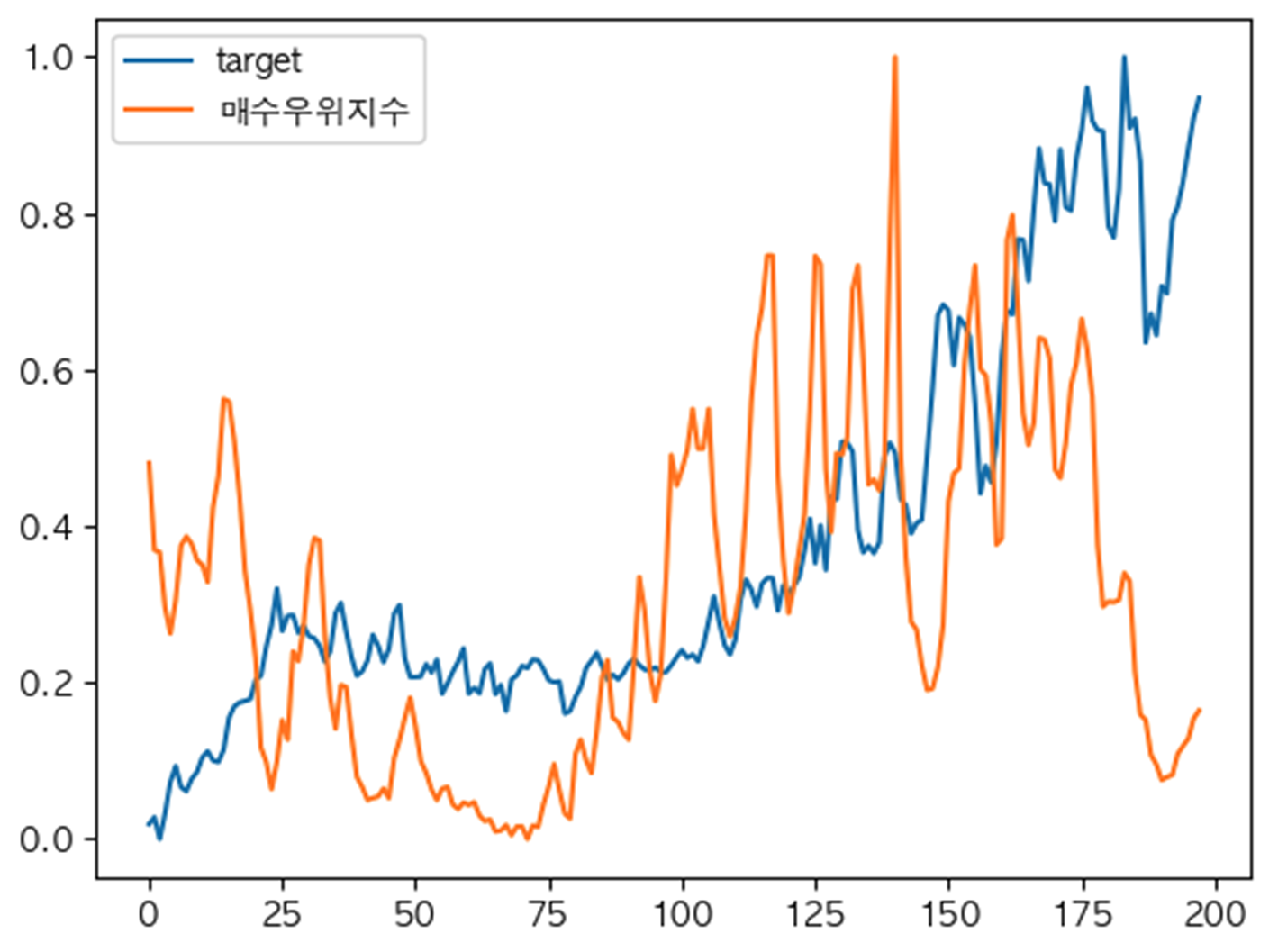
- 매수우위지수 데이터
- 계약년월에 맞춰 매수우위지수 적용
30년 이상 50년 이하
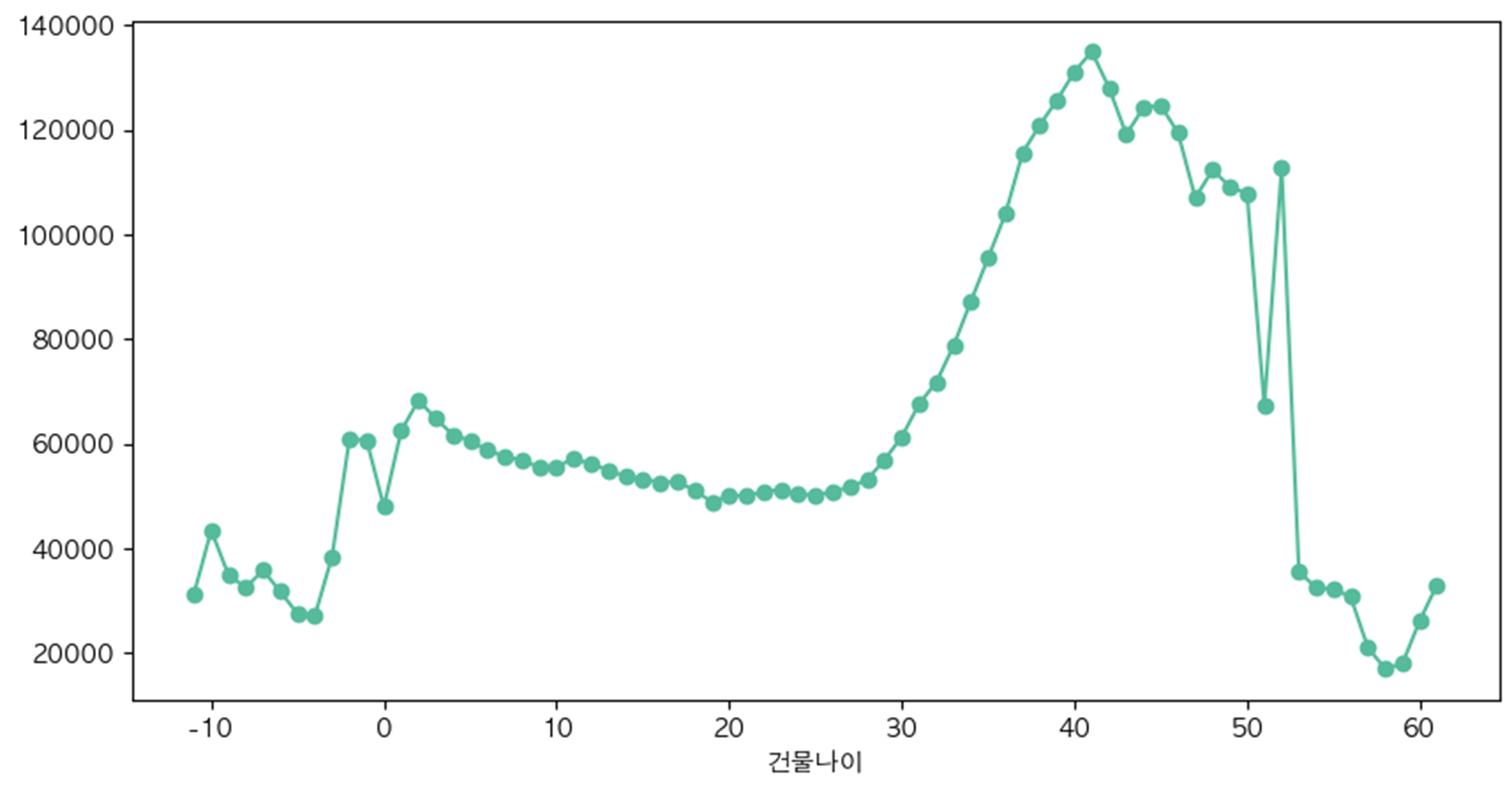
- 건물나이를 계산
- 30년~50년 사이의 경우 거래가가 전체적으로 높음을 확인
- 30년~50년 사이는 1 나머지는 0으로 추가
아파트 카테고리
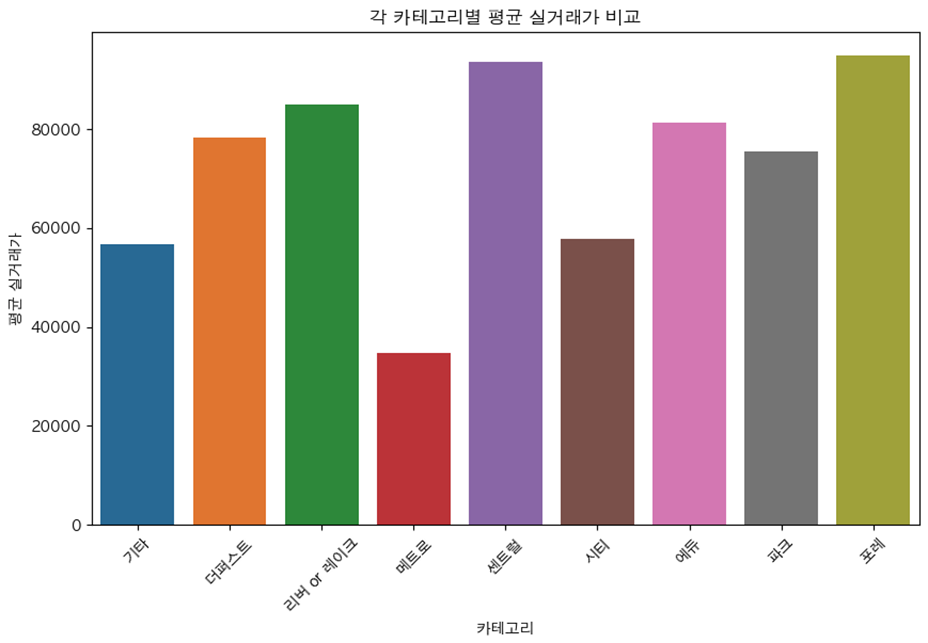
- 아파트 이름에 특정 단어가 들어가는지 확인하여 카테고리 데이터로 추가
지하철 호선 카테고리
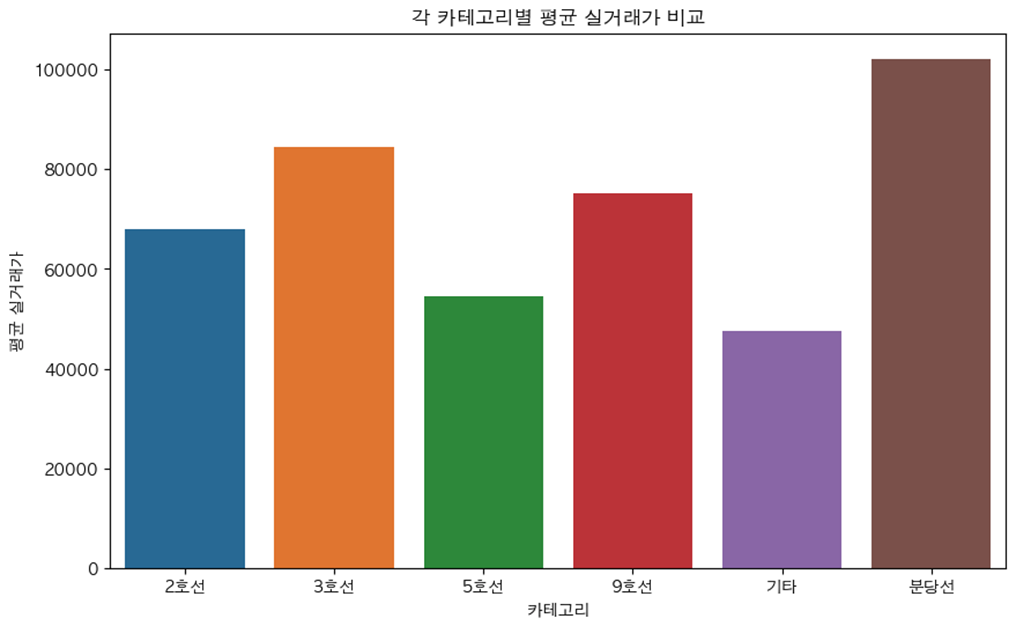
- 특정 지하철 호선을 선택하여 카테고리 생성
아파트 가격 평균
- 특정 아파트의 평균 가격
- 아파트의 가격 특성이 반여오딜 것이라는 가정으로 각각의 아파트에 대해 따로 처리
- test 데이터에만 존재하는 아파트를 발견해 위치, 층, 면적이 비슷한 아파트 값으로 대체
계약월_sin
- np.sin(2 np.pi df['계약월']/12)
- 특정 월에 계약이 많이 일어날 수 있을 것이라는 가정
- 월 사이의 유사도가 반영된다. (12월, 1월이 가까운 위치에 존재한다는 정보 제공)
그 외 생성된 feature
- 구매력지수
- 거래활발지수
- 매매가격 지수 증감률
- 매매가격대비 전세가격 비율
- 가장 가까운 한강 다리와의 거리
- etc..
Feature select
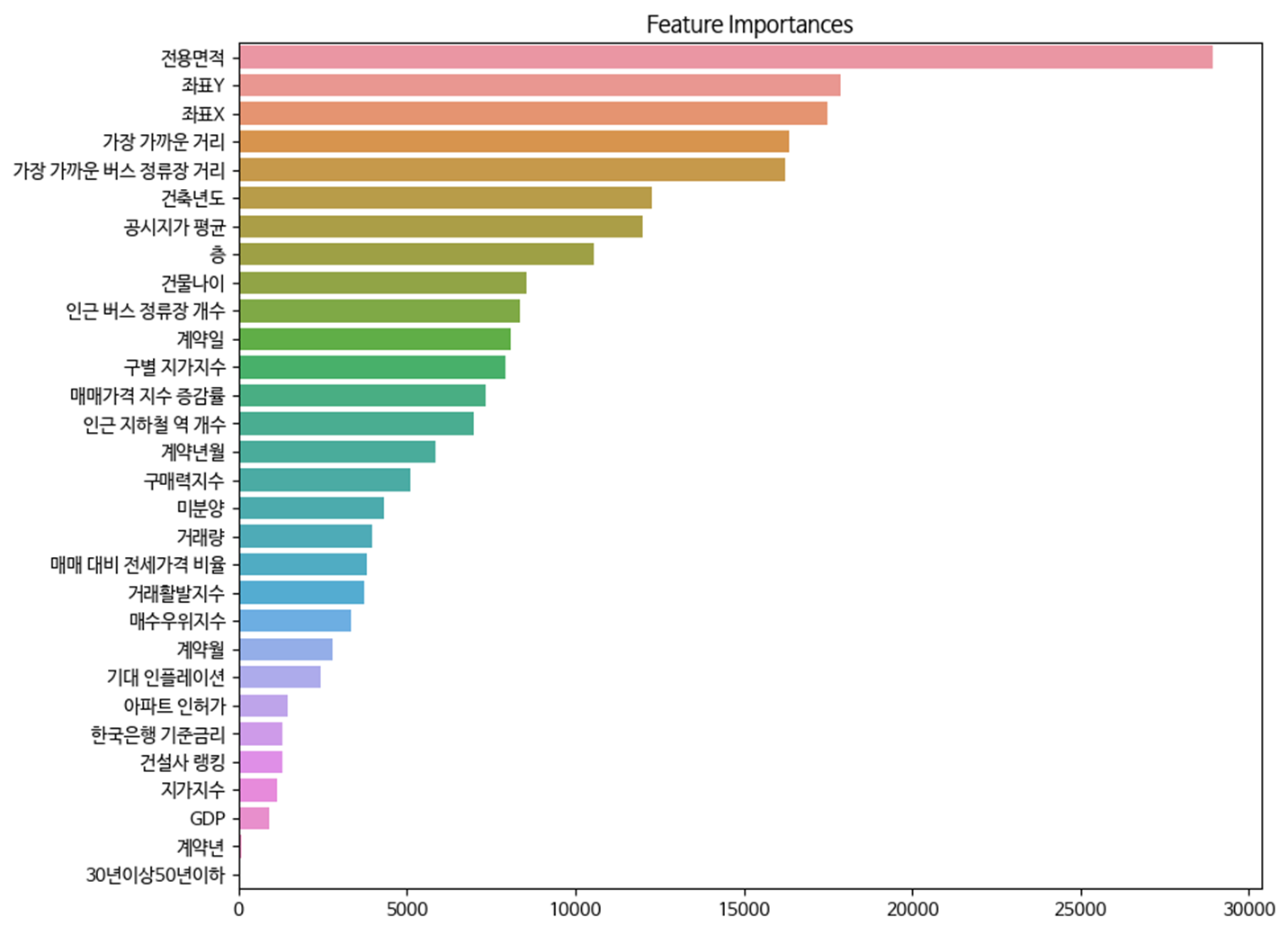
Feature Importance
- 생성된 feature를 전부 활용하여 모델을 학습한 뒤 Feature Importance를 출력해 불필요한 feature 제거
Feed Forward Selection
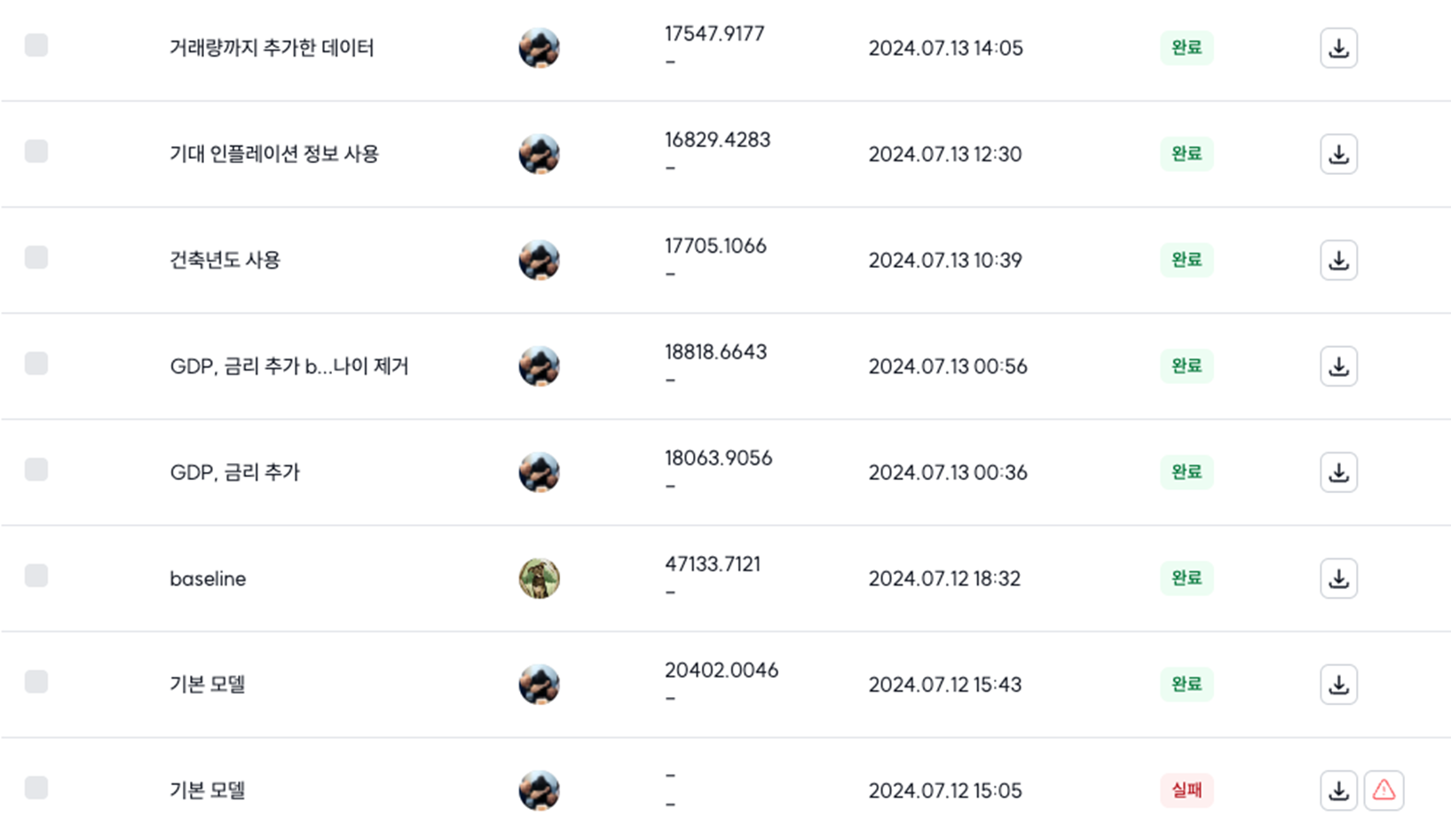
- 새로운 feature 추가시 baseline으로정한 모델로 학습
- RMSE 값의 개선되면 해당 feature 추가
- 해당 과정 중 최고점 달성 및 보완
결과
Feature Importance

Feed Forward Selection

Best Model Features
- 전용면적
- 층
- 건축년도
- 좌표X
- 좌표Y
- 가장 가까운 지하철역과의 거리
- 인근 지하철 역 개수
- 가장 가까운 버스 정류장 거리
- 인근 버스 정류장 개수
- 계약년
- GDP
- 한국은행 기준금리
- 기대 인플레이션
- 거래량
- 구별 지가지수
- 공시지가 평균
- 매수 우위 지수
- 30년 이상 50년 이하
- 아파트 카테고리
- 지하철 카테고리
- 아파트 평균가격
- 계약월_sin
