서론
연구 배경 및 목적
기계 번역은 컴퓨터를 이용하여 한 언어의 텍스트를 다른 언어로 자동 변환하는 기술로 초기의 기계 번역 시스템은 주로 규칙 기반(Rule-Based) 접근법을 사용하였으며 이후 통계적 기계 번역(Statistical Machine Translation, SMT) 방식으로 발전하였다. SMT는 대규모 parallel corpus를 사용하여 번역 확률 모델을 구축함으로써 보다 자연스러운 번역을 가능하게 했다. 그러나 이러한 전통적인 기법들은 다음과 같은 한계점을 가지고 있다.
- 문맥 이해 부족 : 긴 문장이나 복잡한 문맥을 이해하는 데 한계가 있다.
- 고정된 번역 모델 : 사전 정의된 규칙이나 확률 모델에 의존하여 번역 품질이 제한적이다.
- 데이터 의존성 : 대규모 parallel corpus 품질과 양에 따라 성능이 좌우된다.
딥러닝 기술의 발전으로 신경망 기계 번역(Neural Machine Translation, NMT)이 등자하며 인공 신경망을 사용해 Source Language를 Target Language로 번역하는 방식이다. 이는 문장을 단어 단위로 번역하지 않고 문장 전체를 컨텍스트로 이해하여 번역한다. 그러나 초기의 NMT 모델도 한계점이 존재했다.
- 고정된 컨텍스트 벡터 : Source 문장을 고정된 길이의 벡터로 인코딩하여 번역하므로 문장이 길어질수록 번역 품질이 저하된다.
- 장기 의존성 문제 : 문장 내의 단어 간 장기 의존성을 효과적으로 처리하지 못한다.
Bahdanau, Cho, Bengio의 "Neural Machine Translation by Jointly Learning to Align and Translate" 논문은 위의 한계점을 해결하기 위해 어텐션 메커니즘(Attention Mechanism)을 도입한 새로운 NMT 모델을 제안한다.
-
동적 컨텍스트 벡터 생성 : 고정된 길이의 컨텍스트 벡터를 사용하는 기존 방식의 한계를 극복하고, 문장 내의 각 단어에 대해 동적으로 가중치를 부여하여 번역 성능을 향상시킨다.
-
어텐션 메커니즘 도입 : 디코더가 번역하는 과정에서 인코더의 은닉 상태 중 특정 부분에 집중할 수 있도록 어텐션 메커니즘을 도입하여 장기 의존성 문제를 해결한다.
-
모델의 성능 향상 : 제안된 모델이 기존의 NMT 및 SMT 모델보다 우수한 번역 품질을 제공함을 실험을 통해 검증한다.
-
번역의 직관성 및 해석 가능성 제공 : 어텐션 메커니즘을 통해 어떤 단어가 번역에 중요한 역할을 하는지 시각적으로 해석할 수 있게 하여 번역 과정의 투명성을 높인다.
이 논문은 NMT 분야에서 어텐션 메커니즘의 중요성을 부각시키며 이후 많은 연구에서 이를 기반으로 한 다양한 확장 모델이 제안되도록 하는 중요한 기여를 하였다.
어텐션 메커니즘의 도입
어텐션 메커니즘의 기본 개념
어텐션 메커니즘은 인코더의 hidden states와 디코더의 현재 상태를 이용하여 컨텍스트 벡터(context vector)를 동적으로 생성하며 이 과정은 다음과 같이 이루어진다.
1. 가중치 계산
디코더의 현재 hidden state 와 인코더의 각 hidden state 간의 유사도를 계산한다. 이는 주로 score function 를 사용하여 계산되며 다양한 함수가 사용될 수 있다.
-
가중치 정규화
계산된 점수 를 softmax 함수를 통해 정규화하여 어텐션 가중치 를 얻는다. 이 가중치는 디코더가 인코더의 각 hidden state에 얼마나 집중할지를 나타낸다.
-
컨텍스트 벡터 계산
어텐션 가중치 를 사용하여 인코더의 hidden states의 가중 평균을 구해 컨텍스트 벡터 를 생성한다.
-
디코더 출력 생성
생성된 컨텍스트 벡터 와 디코더의 현재 hidden state 를 결합하여 디코더의 출력 를 생성한다. 이 결합은 보통 연속 벡터(concatenation)를 통해 이루어지며 최종 출력층을 통과하여 예측된 단어 가 생성된다.
왜 어텐션이 필요한가?
기존의 신경망 기계 번역(NMT) 모델은 인코더-디코더 구조를 사용하여 소스 문장을 타겟 문장으로 변환한다. 이때 인코더는 입력 문장을 고정된 길이의 컨텍스트 벡터로 인코딩하고 디코더는 이 벡터를 기반으로 번역을 생성한다. 그러나 이러한 방식은 긴 문장이나 복잡한 문맥을 처리하는 데 한계가 있다. 소스 문장의 모든 정보를 고정된 길이의 벡터에 압축하기 때문에 문장이 길어질수록 중요한 정보가 손실될 수 있다. 어텐션 메커니즘은 이러한 한계를 극복하기 위해 도입된 기법으로 디코더가 번역을 생성하는 과정에서 소스 문장의 특정 부분에 집중할 수 있도록 가중치를 부여하는 방식이다.
어텐션 메커니즘의 장점
-
동적 컨텍스트 벡터
문장의 길이와 상관없이 각 디코딩 스텝마다 다른 컨텍스트 벡터를 생성하며 긴 문장에서도 중요한 정보를 효과적으로 추출할 수 있다. -
장기 의존성 해결
문장 내의 단어 간 장기 의존성을 더 잘 처리할 수 있으며 문맥에 맞는 번역을 생성할 수 있다. -
해석 가능성
어텐션 가중치를 시각화하면 디코더가 번역하는 과정에서 어떤 단어에 집중하는지를 알 수 있어 모델의 동작을 더 잘 이해할 수 있다.
모델 구조
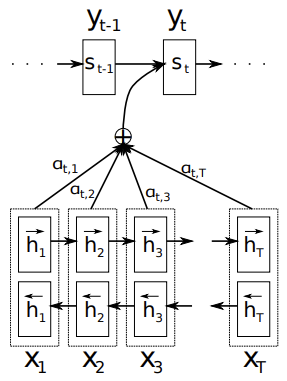
Encoder (BiRNN)
인코더는 소스 문장을 고차원 벡터로 인코딩하는 역할을 하며 한 방향으로 소스 문장을 input으로 받는 RNN과 달리 소스 문장에 대해 이전의 내용과 이후의 내용을 읽는 BiRNN을 사용한다. BiRNN은 forward RNN, backward RNN으로 구성되며 forward RNN은 처음부터 순차적으로 소스 문장을 읽어 hidden state를 생성하고 backward RNN은 역방향으로 소스 문장을 읽어 역방향의 hidden state를 생성한다.
Decoder
디코더는 인코더의 hidden state와 어텐션 메커니즘을 사용하여 타겟 문장을 생성한다.
-
입력 임베딩
타겟 문장의 단어를 입력으로 받고 각 단어는 고차원 임베딩 벡터로 변환된다. 임베딩 벡터는 단어의 의미를 고차원 공간에서 나타내며 학습 과정에서 최적화된다. -
RNN
입력된 단어 임베딩 베겉와 이전 시간 스텝의 hidden state를 기반으로 현재 hidden state를 업데이트 한다. -
어텐션 메커니즘
디코더의 현재 hidden state와 인코더의 모든 hidden state를 사용하여 어텐션 가중치와 컨텍스트 벡터를 계산한다. 이는 디코더가 소스 문장의 특정 부분에 집중할 수 있게 한다. -
output layer
디코더의 은닉 상태와 컨텍스트 벡터를 사용하여 출력 단어의 확률 분포를 계산하여 가장 가능성이 높은 단어를 예측한다.
결론
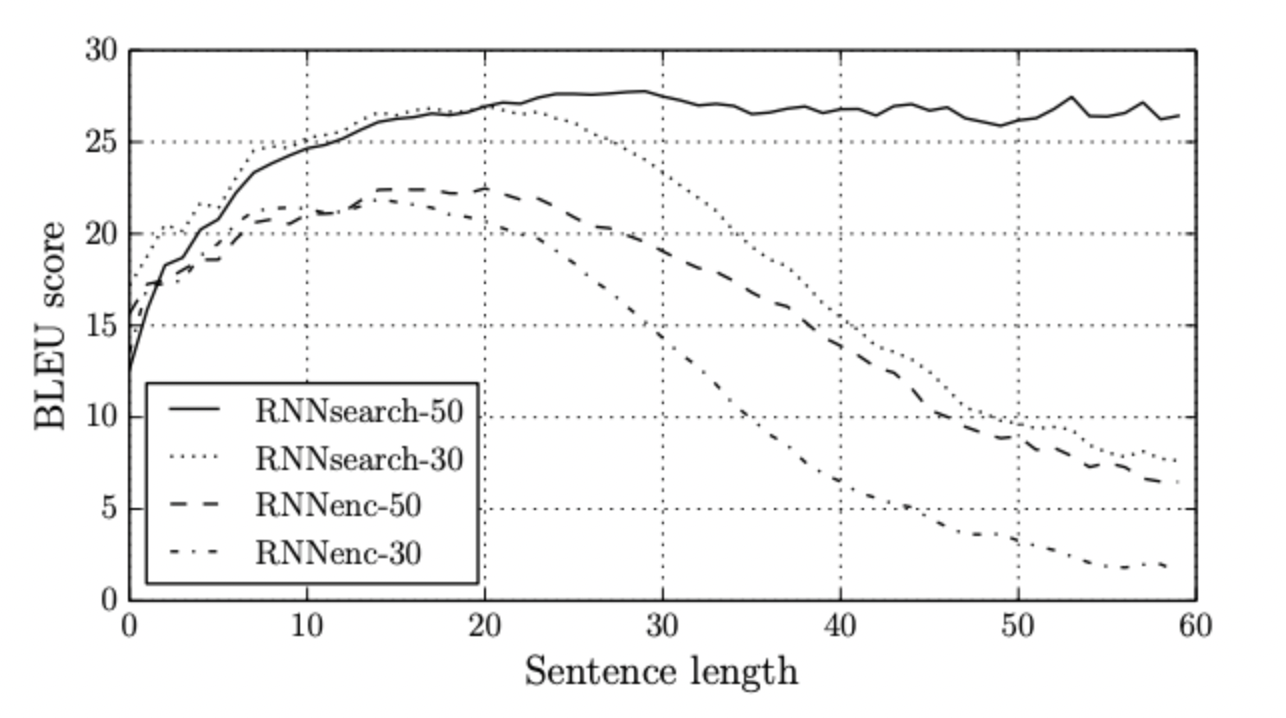
이 논문에서 제안된 모델은 기존의 RNN 기반 번역 모델보다 우수한 성능을 보였다. 특히 BLEU 점수를 통해 평가한 결과 어텐션 메커니즘을 도입한 모델(RNNsearch)가 기존 모델(RNNenc)보다 모든 문장길이에서 더 높은 점수를 얻었으며 문장의 길이가 길어질수록 그 차이가 더 커졌다.
