Show and Tell: A Neural Image Caption Generator
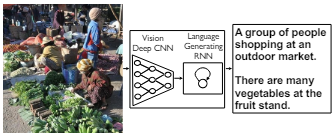
2015년 Google Brain 팀에서 발표한 논문으로 이미지 캡션 생성에 관한 연구이며 이미지에 대한 자연어 설명을 생성하는 모델을 제안한다.
이 논문에서는 이미지의 특징을 추출하는 CNN(Convolutional Neural Eetwork)과 문장을 생성하는 RNN(Recurrent Neural Network)을 결합한 모델을 소개한다. 모델은 이미지 특징을 인코딩 하고 그 인코딩된 정보를 사용하여 자연어 문장을 생성한다. 특히 이 연구는 이미지 캡션 생선 작업에서 LSTM 네트워크를 사용한점이 중요한 특징이다.
서론
연구의 배경 및 중요성
이미지 캡션 생성은 CV(Computer Vision)와 자연어 처리(NLP) 분야의 융합을 요구하는 도전적인 문제로 주어진 이미지에 대해 그 내용을 설명하는 자연어 문장을 생성하는 작업이다. 이 문제는 다양한 응용 분야에서 중요한 의미를 가지며 예를 들어 시각 장애인을 위한 이미지 설명, 이미지 검색 및 분류, 소셜 미디어에서의 자동 태그 생성 등이 있다.
기존의 이미지 캡션 생성 방법은 주로 두 가지로 나뉜다. 첫 번째는 이미지의 시각적 특징을 분석하여 그에 대응하는 텍스트를 생성하는 방법이고 두 번째는 사전 정의된 템플릿에 맞춰 이미지를 설명하는 방법이다. 그러나 이러한 접근 방식들은 제한적이며 특히 다양한 이미지 컨텐츠를 설명하는 데 한계가 있다.
이 논문에서 Google Brain 팀은 이미지 캡션 생성을 위한 혁신적인 신경망 모델을 제안했다. 이 모델은 이미지에서 특징을 추출하는 CNN과 텍스트를 생성하는 RNN의 결합을 통해 보다 유연한고 정확한 이미지 설명을 가능하게 한다. 특히 이 연구는 LSTM 네트워크를 활용하여 문맥을 유지하며 일련의 단어를 생성하는 방법을 사용함으로써 기존의 접근 방식보다 훨씬 더 자연스러운 문장을 생성할 수 있음을 보여주었다.
이미지 캡션 생성의 개요
이미지 캡션 생성 작업은 이미지 분석과 자연어 생성이라는 두 가지 주요 요소를 포함한다. 이 작업의 목표는 이미지의 시각적 정보를 효과적으로 이해하고 이를 기반으로 적절한 자연어 설명을 생성하는 것이다. 이를 위해 필요한 주요 단계는 다음과 같다.
1. 이미지 특징 추출 : 이미지의 시각적 정보를 추출하기 위해 CNN을 사용한다. CNN은 이미지를 여러 계층을 처리하며 최종적으로 고차원 벡터를 생성한다. 이 벡터는 이미지의 중요한 시각 적 요소들을 요약한 것이다.
2. 문장 생성 : 추출된 이미지 feature 벡터를 입력으로 받아 이를 기반으로 자연어 문장을 생성한다. 이 과정에서 RNN, 특히 LSTM네트워크가 사용된다. LSTM은 시퀀스 데이터(단어 시퀀스)를 처리하는 데 적합하며 문맥 정보를 유지하면서 단어를 생성할 수 있다.
3. 통합 모델 : CNN과 LSTM을 결합하여 이미지에서 텍스트로의 매핑을 학습한다. 이미지 feature 벡터를 입력으로 받아 LSTM을 통해 단계적으로 단어를 생성하며 최종적으로 완전한 문장을 출력한다.
이 논문에서 제안된 모델은 End-to-End 학습이 가능하여 별도의 중간 단계 없이 이미지에서 직접 텍스트를 생성할 수 있어 이미지 캡션 생성 작업의 정확도와 효율성을 크게 향상시킨다.
논문의 주요 기여
새로운 모델 제안
이 논무느이 주요 기여는 이미지 캡션 생성을 위한 새로운 신경망 모델을 제안한 것으로 이미지의 시각적 특징을 추출하는 CNN과 자연어 문장을 생성하는 RNN 특히 LSTM 네트워크를 결합한 것이다. 이 모델의 주요구성 요소는 다음과 같다.
1. Convolutional Neural Network
- 이미지의 시각적 feature를 추출하기 위해 사용된다. 일반적으로 Inception 또는 VGG 네트워크와 같은 pretrained된 CNN 모델을 사용하여 이미지의 고차원 벡터를 얻는다.
- CNN의 마지막 Pooling layer에서 추출된 feature 벡터는 이미지의 고유한 표현을 담고 있으며 이는 이미지의 중요한 시각적인 요소들을 요약한 것이다.
2. Long Short-Term Memory (LSTM)
- 추출된 이미지 feature 벡터를 입력으로 받아 순차적으로 단어를 생성하여 자연어 문장을 생성한다.
- 이미치 feature 베겉는 LSTM의 초기 상태(initial state)롤 사용되거나 첫 번째 입력으로 제공된다. 이후 LSTM은 단어 시퀀스를 단계적으로 생성하며 각 단계에서 다음 단어를 예측한다.
3. End-to-End 학습
- 모델은 이미지에서 텍스트로의 매핑을 End-to-End 방식으로 학습한다. 이는 별도의 중간 단계 없이 직접적으로 임지에서 문장을 생성할 수 있음을 의미한다.
- 학습 과정에서는 이미지와 그에 대응하는 문장 쌍을 사용하여 모델을 학습시킨다. 손실 함수로는 일반적으로 Cross Entropy Loss를 사용하여 모델이 예측한 단어 시퀀스와 실제 단어 시퀀스 간의 차이를 최소화 한다.
기존 연구와 비교
1. 템플릿 기반 접근 방식과의 차이
기존의 템플릿 기반 접근 방식은 사전 정의된 문장 구조에 따라 이미지를 설명한다. 이러한 방법은 정해진 템플릿의 범위를 벗어나는 다양한 이미지 컨텐츠를 설명하는 데 한계가 있다. Show and Tell 모델은 템플릿에 의존하지 않고 학습된 신경망을 통해 유연하게 다양한 문장을 생성할 수 있다.
2. feature 기반 접근 방식과의 차이
feature 기반 접근 방식은 이미지의 시각적 feature를 분석하여 그에 대응하는 텍스트를 생성하여 feature 추출과 문장 생성이 별도의 단계로 이루어져 통합적인 학습이 어렵다. Show and Tell 모델은 CNN과 LSTM을 결합하여 이미지에서 텍스트로의 매핑을 통합적으로 학습하여 End-to-End 학습을 통해 더 높은 정확도와 유연성을 제공합니다.
모델 아키텍처
Convolutional Neural Network (CNN) 개요
Convolutional Neural Network (CNN)은 이미지 처리 및 인식 작업에서 널리 사용되는 신경망 구조로 이미지의 공간적 계층 구조를 활용하여 이미지의 시각적 feature를 효과적으로 추출한다.
1. Convolutional Layers
는 필터 는 입력 이미지, 는 편향, 는 컨볼루션 연산이다.
- 입력 이미지에 다양한 필터를 적용하여 feature map을 생성한다.
- 각 커널은 이미지의 특정 패턴이나 특징을 감지한다.
2. Pooling Layers
Feature Map의 공간 차원을 줄이고 계산량을 감소시키며 중요한 feature를 추출한다.
3. Fully Connected Layers
최종 Feature Map을 벡터로 변환하여 분류 또는 회귀 작업을 수행한다.
논문에서는 사전 학습된 CNN을 사용하여 이미지의 고차원 feature 벡터 를 추출하고 LSTM 네트워크의 입력으로 사용된다.
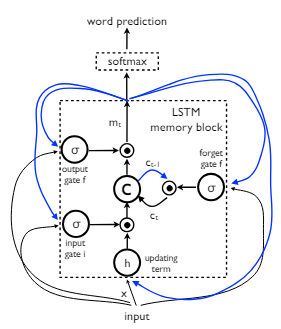
Long Short-Term Memory (LSTM) 개요
Long Short-Term Memory (LSTM)은 RNN의 한 종류로 긴 시퀀스 데이터의 장기 의존성 문제를 해결하기 위해 설계되었다.
1. Input Gate
현재 입력 와 이전 hidden state 을 통해 새로운 정보 를 생성하고 이를 cell state에 얼마나 반영할지를 결정한다.
2. Forget Gate
이전 셀 상태 에서 얼마나 많은 정보를 잊을지를 결정한다.
3. Output Gate
cell state 를 기반으로 현재 시간 단계의 hidden state 를 업데이트한다.
4. Cell State
새로운 Cell state는 이전 셀 상태 에 Forget gate 를 적용하고 새로운 정보 에 input gate 를 적용하여 계산된다.
5. Hidden State
Hidden state는 이전 Cell state 에 output gate 를 적용하여 계산된다.
6. Output
다음 time step의 출력은 hidden state 에 Softmax를 적용하여 계산된다.
CNN과 LSTM의 결합 방법
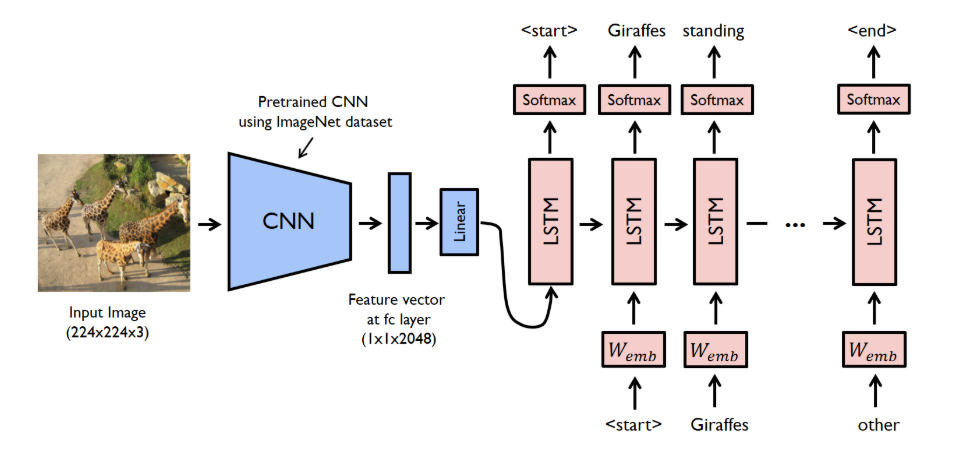
1. 이미지 feature 추출
CNN을 사용하여 입력이미지 에서 고차원 feature 벡터 를 추출한다.
2. 이미지 feature 벡터를 LSTM 입력으로 사용
추출된 feature 벡터 는 LSTM의 초기 상태 또는 첫 번째 입력으로 사용된다.
3. 문장 생성
LSTM은 이미지 feature 벡터 를 기반으로 시퀀스 단어 을 생성 하고 각 시간 단계 에서 LSTM은 현재 단어 와 이전 hidden state 를 입력으로 받아 다음 단어 를 예측한다.
모델의 학습 과정
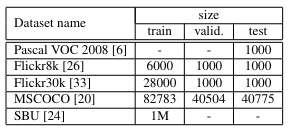
데이터셋
이 논문의 실험에 사용된 데이터셋은 다음과 같다.
학습 방법 및 절차
seq2seq 모델에서 Encoder를 CNN으로 사용하고 Decoder로 LSTM 사용하여 input Image가 주어졌을 때 output Sequence의 확률을 최대화 하는 방향으로 학습을 진행하였다.
Over fitting을 예방하기 위한 기술
1. Pre Trained CNN 사용
2. Pre Trained Word embedding vector 사용
3. Dropout & Ensemble
Inference
- Sampling
LSTM 모델이 생성한 다음 단어의 확률 분포로부터 단어를 샘플링하여 캡션을 생성하는 방법으로 확률 분포를 직접 사용하여 예측하는 단어를 선택하므로 생성된 문장에 더 많은 다양성을 제공할 수 있다.
-
초기 상태 설정
CNN을 사용하여 입력 이미지에서 feature 벡터 를 추출하고 이를 LSTM의 초기 상태로 설정한다. -
단어 샘플링
LSTM의 초기입력으로 시작 토큰 를 사용하여 첫 번재 단어를 생성한다. 각 시간 단계 에서 이전에 생성된 단어 을 입력으로 받아 다음 단어의 확률 분포 을 예측한다. 이 확률 분포로부터 샘플링 하여 다음 단어 를 선택하고 이를 반복하여 토큰이 생성 되거나 최대 길이에 도달할 때까지 단어를 생성한다.
- Beam Search
Beam Searchs는 샘플링보다 더 정교한 방법으로 다양한 경로를 탐색하여 가장 가능성이 높은 캡션을 생성하는 방법이다.
-
초기 설정
CNN을 사용하여 입력 이미지에서 feature 벡터 를 추출하고 이를 LSTM의 초기 상태로 설정한다.
-
Beam Search
각 시간 단계 에서 현재 Beam 내의 각 경로에 대해 다음 단어의 확률 분포를 예측한다. 각 경로에서 가장 높은 확률을 가진 상위 개의 단어를 선택하여 새로운 경로를 생성한다. 이때 는 beam width이다.
선택된 단어와 경로 확률을 조합하여 새로운 Beam을 형성하며 이 과정을 반복하여 토큰이 생성되거나 최대 길이에 도달할 때까지 Beam을 확장한다. -
최종 선택
모든 경로가 확장된 후 가장 높은 누적 확률을 가진 경로를 선택하여 최종 캡션으로 사용한다.
