Sequence to Sequence Learning with Neural Networks
Sequence to Sequence(Seq2Seq) Learning은 두개의 RNN을 사용하여 하나의 Sequence를 다른 Sequence로 변환하는 모델로 주로 기계 번역 Task에 적용되어 한 언어의 텍스트를 다른 언어로 번역하는데 사용된다.
Abstract
DNN은 레이블이 지정된 대규모 train set이 있을 때 잘 작동하지만 Seq2Seq 매핑이 불가능하다. 이를 해결하기 위해 multilayered LSTM을 사용하여 입력 순서를 고정 차원 벡터로 매핑하고 다른 deep LSTM을 사용하여 target Sequence를 decode 하는 일반적인 end-to-end 접근 방식을 제안한다.
LSTM은 단어 순서에 민감하며 능동태, 수동태에 대해 비교적 불변한 합리적인 구문 및 문장 표현을 배웠다. Source sentences(not target senteces)의 단어 순서를 바꾸면 LSTM의 성능이 현저히 향상되었으며 source와 target senteces사이의 많은 단기 의존성이 도입되어 최적화 문제를 쉽게 해결하였다.
Introduction
Deep Neural Networks (DNNs)는 음성 인식 및시각적 객체 인식과 같이 어려운 문제에서 뛰어난 성능을 보이는 Machine Learning model이다. 또한 bit 숫자를 2개의 input size의 제곱(qudratic size) 크기의 hidden layer로 정렬할 수 있는 병렬 계산을 수행할 수 있다.
하지만 DNN은 유연성과 강력한 성능에도 불구하고 고정된 차원의 벡터로 input과 target을 표현할 수 있는 문제에만 적용이 가능하다. 많은 문제들이 사전에 알 수 없는 길이의 Sequence로 표현되기 때문에 Seq2Seq로 매핑하는 방법을 학습 방법이 DNN보다 해당 문제에서 더 유용하다.
LSTM을 활용한 Seq2Seq 문제 해결
이 연구에서 제시된 아이디어는 하나의 LSTM을 사용하여 한 time-step씩 input Sequence를 읽어내고 그 결과로부터 고정된 크기의 벡터를 얻고 또 다른 LSTM을 사용하여 이 벡터로부터 output Sequence를 추출한다. 이 두 번째 LSTM은 기본적으로 input Sequence에 조건을 걸어놓은 재귀적 신경망 언어 모델이다.
LSTM의 목표는 input Sequence 와 그 길이가 다를 수 있는 output Sequence 의 조건부 확률을 추정하는 것인데 이는 LSTM이 input Sequence의 마지막 hidden state로 부터 제공되는 고정 차원 표현 v를 통해 이루어진다.
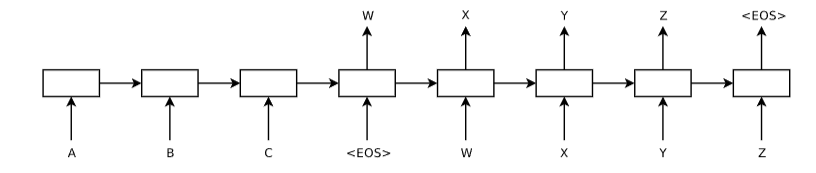
Encoder : 왼쪽의 A, B, C를 처리하고 이를 하나의 context 벡터로 변환한다. 이 과정은 input Sequence를 고정된 길이의 표현으로 encoding한다. 각 상자는 LSTM 셀이며 화살표는 시간에 따른 정보의 흐름을 의미한다.
Decoder : Encoder로부터 얻은 context 벡터를 기반으로 W, X, Y, Z와 같은 새로운 Sequence를 생성한다. 이 과정에서 Decoder는 출력 Sequence의 각 time-step에서 다음 요소를 예측한다.
EOS : End Of Sequence를 나타내며 Sequence의 끝을 표시하는 토큰이다. EOS 토큰은 Encoder의 input Sequence 끝과 Decoder의 출력 Sequence 끝에 나타나며 Decoder에게 생성을 멈추라는 신호로 작용한다.
LSTM
LSTM은 RNN(Recurrent Neural Network)의 한 종류로 장기간의 의존성을 기억하는 능력이 탁월해 NLP를 비롯한 Sequence 데이터를 다루는 다양한 분야에서 활용된다.
- 메모리 셀 : LSTM의 기본 구성 요소로서 장기적인 정보를 저장할 수 있는 구조이다.
- 게이트 : 메모리 셀의 정보 흐름을 조절하는 역할을 하며 어떤 정보를 기억하고 삭제하며 출력할지 결정한다. 주로 세 가지 게이트(입력, 삭제, 출력)가 있다.
- 장기적인 의존성 학습 : 일반적은 RNN은 시간이 지날수록 정보가 소실되는 장기 의존성 문제를 가지고 있는 방면 LSTM은 이 문제를 해결하기 위해 장기간에 걸친 데이터의 의존성을 학습할 수 있다.
LSTM 셀 내부의 각 게이트는 가중치와 바이어스를 가진 신경망을 통해 활성화 되며 시그모이드 함수를 사용하여 0과 1사이의 값을 출력한다. 이 값들은 셀 내부의 데이터 흐름을 제어하고 필요한 정보만을 다음 단계로 전달하게 된다.
Experiments
Dataset details
WMT'14 영어-프랑스어 번역 task를 사용하여 실험을 진행했다. 1200만개의 문장을 선택해 train에 사용했으며 16,000개의 의 영어단어와 80,000개의 프랑스어 단어를 단어장으로 설정했다.
Decoding and Rescoring
연구진은 LSTM 모델을 사용하여 직접 번역을 시도했고 기존의 SMT(Statistical Machine Translation) 시스템으로부터 생성된 가장 좋은 1000개의 번역 가설을 Rescoring 하는 방법을 사용했다.
Source Sentence S가 주어졌을 때 올바른 번역 T의 log probability를 최대화하는 것을 목표로 train을 진행했다.
train이 진행 되고 beam search decoder를 사용하여 가장 정확한 번역을 선택한다.
Reversing the Source Sentences
실험 결과 source Sentences의 단어 순서를 반전시키는 것이 test PPL은 5.8에서 4.7로 BLEU는 25.9에서 30.6으로 성능 향상이 발생했다. 이는 source sentence와 target sentence 간의 단기 의존성을 증가시켜 최적화 문제를 간소화 함으로서 성능 향상을 이끌어 냈다.
Training details
총 4 layer의 LSTM을 사용했으며 각 층에 1000개의 셀이 있다. 전체 LSTM 모델은 문장을 표현하기 위해 8000개의 토큰을 사용했으며 384만개의 파라미터를 가진 대규모 모델을 SGD를 활용해 5번의 epoch 이후에 0.7의 고정된 learning rate를 사용하고 momentum을 사용하지 않으며 학습 시켰다.
Prevent grqadient exploding
LSTM과 같은 대규모 모델을 훈련할 때 gradient의 크기가 너무 커지면 Back propagation 연산 시 큰 값의 gradient가 반복적으로 곱해지면서 그 값이 매우 커져 gradient exploding이 발생한다. 이를 해결하기 위해 연구팀은 norm에 제한을 두는 방법을 사용했다.
gradient의 L2 norm, 즉 s를 계산하고 이 값이 특정 threshold 5를 초과하면 gradient를 scaling하여 그 크기를 줄인다. 구체적으로 128로 나누어진 gradient g의 norm s가 5보다 클 경우 로 scaling하여 크기를 조정한다. 이렇게 scaling된 gradient는 이후의 training step에서 사용되며 train과정을 더 안정적으로 만들어준다.
Experimental Results
LSTM 모델은 BLEU 점수를 기준으로 34.8을 기록 했으며 해당 데이터 셋에 대한 기존 SMT 시스템의 33.3의 점수를 초과하였고 Rescoring을 통해 BLEU 점수를 36.5까지 향상 시킬 수 있었다.
