
웹 크롤링(Web Crawling)
웹 크롤링(Web Crawling이란 인터넷에 있는 웹페이지를 방문하여 얻고자하는 데이터를 추출하는 자동화 기법으로 웹 크롤러(Web Crawler)라는 소프트웨어를 통해 수행되며 데이터 수집, 웹 콘텐츠의 변화 감지, 사이트의 구조 및 링크를 분석하는 등의 다양한 목적으로 활용된다.
웹사이트 구성 (HTML, CSS, JavaScript)
HTML
HTML은 웹 페이지의 구조를 정의하는 MarkUp 언어로 웹페이지의 내용과 구조적 의미를 나타내는데 사용되며 텍스트 컨텐츠, 이미지, 링크 등의 웹 요소를 정의한다.
HTML 예시
<!DOCTYPE html>
<html>
<head>
<title>웹사이트의 제목</title>
</head>
<body>
<h1>메인 헤더</h1>
<p>이것은 단락입니다.</p>
<img src="image.jpg" alt="설명 이미지">
<a href="http://www.example.com">방문 사이트</a>
</body>
</html>
CSS (Cascading Style Sheets)
CSS는 웹 페이지의 스타일과 레이아웃을 지정하는 Style Sheet 언어로 HTML로 만들어진 웹페이지의 요소들을 꾸미고 디자인을 적용하기 위해 사용된다.
CSS 예시
body {
font-family: 'Arial', sans-serif;
margin: 0;
padding: 0;
}
h1 {
color: navy;
margin-bottom: 15px;
}
p {
color: grey;
line-height: 1.6;
}
img {
max-width: 100%;
height: auto;
}
JavaScript - JS
JavaScript는 웹 페이지에 동적인 기능을 추가하는 Scripting 언어로 사용자의 인터랙션에 반응하거나 데이터를 비동기적으로 로드하고 웹페이지의 요소를 실시간으로 변경할 수 있다.
JavaScript 예시
document.addEventListener('DOMContentLoaded', function() {
var myImage = document.querySelector('img');
myImage.addEventListener('click', function() {
var mySrc = myImage.getAttribute('src');
if (mySrc === 'image.jpg') {
myImage.setAttribute('src', 'other-image.jpg');
} else {
myImage.setAttribute('src', 'image.jpg');
}
});
});크롤링을 위한 Selenium 설치와 이해
Selenium
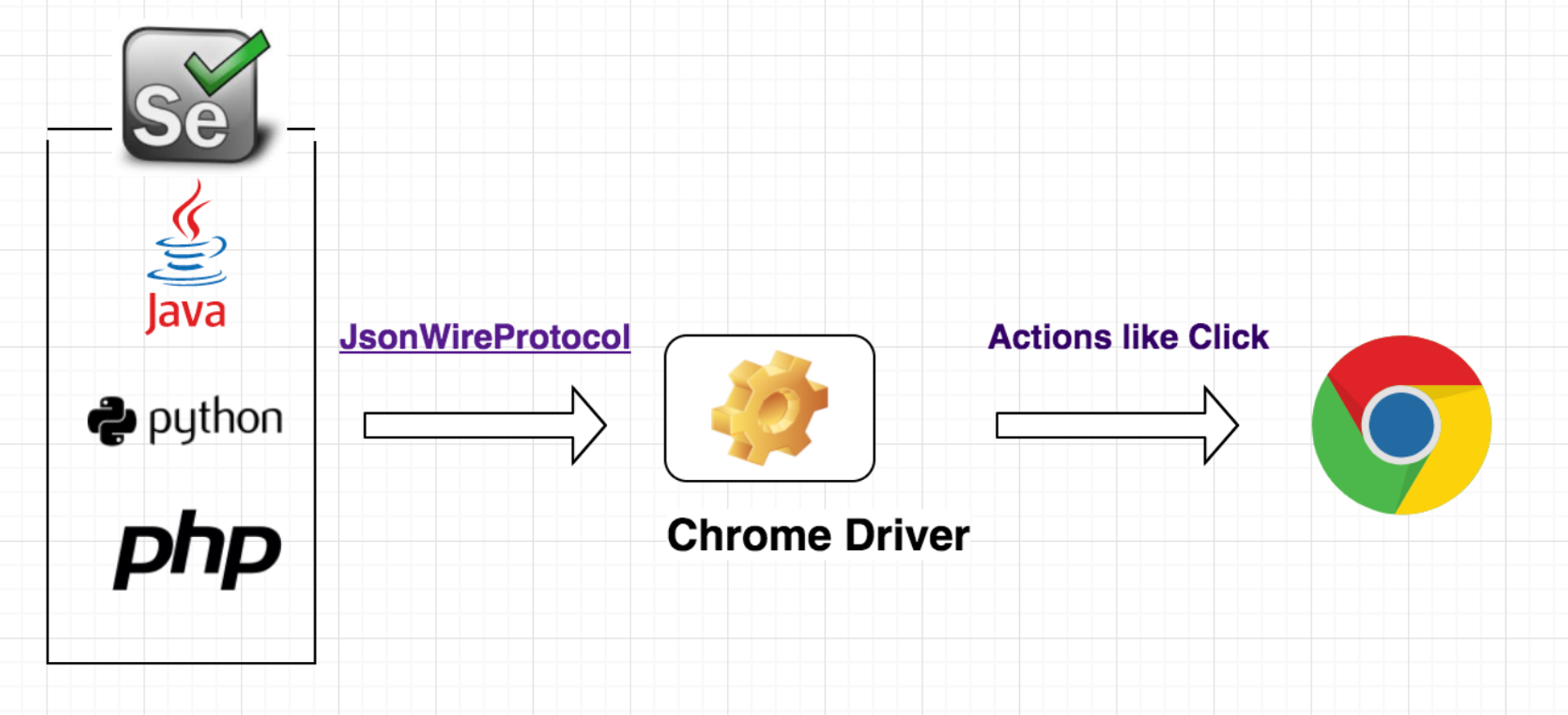
Selenium은 웹 브라우저를 자동화하기 위한 툴과 라이브러리의 모음으로 브라우저 자동화, 동적 컨텐츠 처리, 다양한 브라우저 지원, 다양한 프로그래밍 언어 지원의 기능이 있다.
Selenium 설치 및 실행
# selenium 설치
!pip install seleniumpython Selenium을 통해 크롬드라이버로 크롬브라우저를 컨트롤 할 수 있다.
# webdriver_manager 설치
!pip install webdriver_manager라이브러리 import
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManagerChromeDriverManager 설치
ChromeDriverManager().install()Selenium 실행
browser = webdriver.Chrome()
url = "https://www.naver.com"
# browser에서 url 열기
browser.get(url)
# 기본 함수
browser.back() # 뒤로가기
browser.forward() # 앞으로가기
browser.refresh() # 새로고침
browser.title'NAVER'
By
By.CLASS_NAME # 태그의 클래스명으로 추출
By.TAG_NAME # 태그 이름으로 추출
By.ID # 태그의 id 값으로 추출
By.XPATH # 태그의 경로로 추출Keys
(1) 요소를 하나씩 클릭하는 방법

from selenium.webdriver.common.by import By
browser.find_element(By.ID, 'query').click()
browser.find_element(By.ID, 'query').send_keys("날씨") # 검색어 입력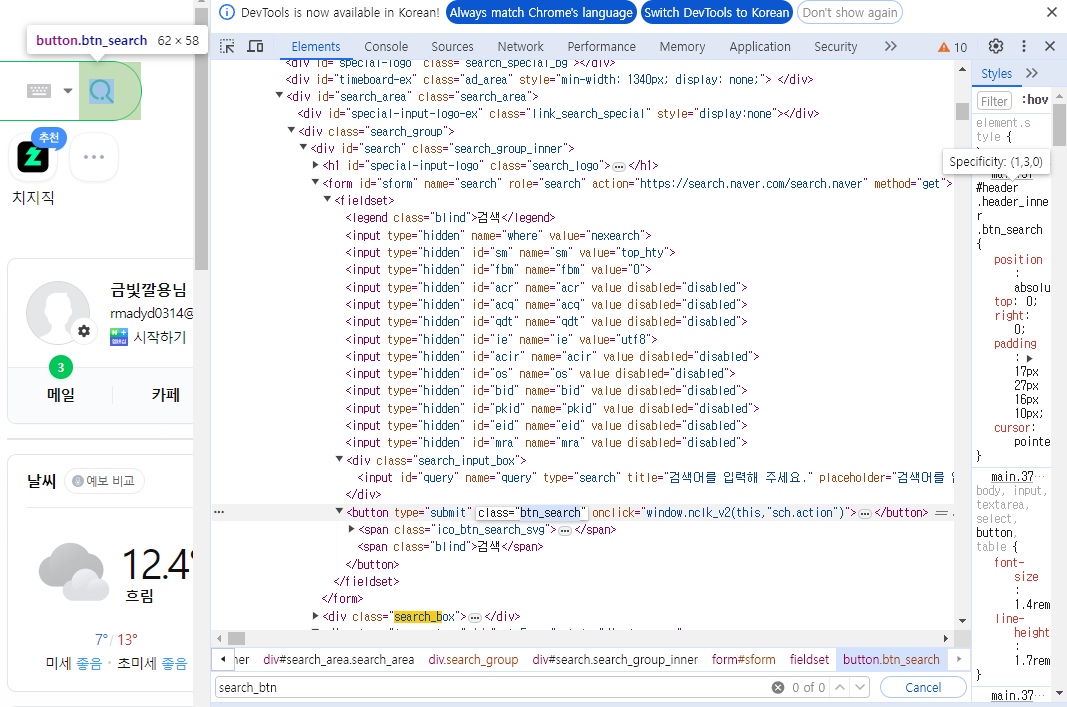
browser.find_element(By.ID, 'search_btn').click() # 검색 버튼 클릭(2) Keys 라이브러리 사용
from selenium.webdriver.common.keys import Keys
elem = browser.find_element(By.ID, 'query') # 요소 지정
elem.send_keys("검색원하는 단어")
elem.send_keys(Keys.ENTER)하나의 데이터 가져오기
temp = browser.find_element(By.CLASS_NAME, 'temperature_text').text
temp.split('\n')[1]'9.1°'
# 체감, 습도, 풍향
data = browser.find_element(By.CLASS_NAME, 'summary_list').text'체감 8.7° 습도 76% 북서풍 1.4m/s'
