EDA (Exploratory Data Analysis, 탐색적 데이터 분석)
- 기존 가설 검정에 치우친 통계학의 단점을 보완
- 주어진 자료만을 이용해 충분한 정보를 찾는 과정
- 데이터를 기술 통계(평균, 분산, 표준편차 등)와 시각화를 통해 다양한 분석 실시
Data preprocessing
- 모델 학습을 위해 raw data를 유용한 format으로 만드는 과정
Data 종류
범주형 데이터 (Categorical data)
순서형 데이터 (Ordinal data)
- 성적, 키
명목형 데이터 (Nominal data)
- 과일 (사과, 바나나)
- 순서에 의미가 없음
- linear regression 등 선형적 모델 사용 시 one hot encoding 필요
수치형 데이터 (Numerical data, Quantitative data)
연속형 데이터 (Continuous data)
- 강수량
이산형 데이터 (Discrete data)
- 나이
Data 준비
Data 불러오기
from google.colab import drive
drive.mount('/content/drive')
basicPath = '[Google drive]'
path = basicPath + '[데이터 위치]'
file = 'train.csv'
data = pd.read_csv(os.path.join(path, file),index_col=None)
# 데이터 확인용
data.head() # DataFrame의 상위 항목들 출력
data.info() # DataFrame의 column, Not-Null수, Dtype 등 정보 출력
display(data.describe(), data.isna().sum()) # DataFrame의 통계 정보, NaN 수 출력
# pandas 옵션 변경
pd.options.display.max_rows = 100
pd.options.display.max_columns =100
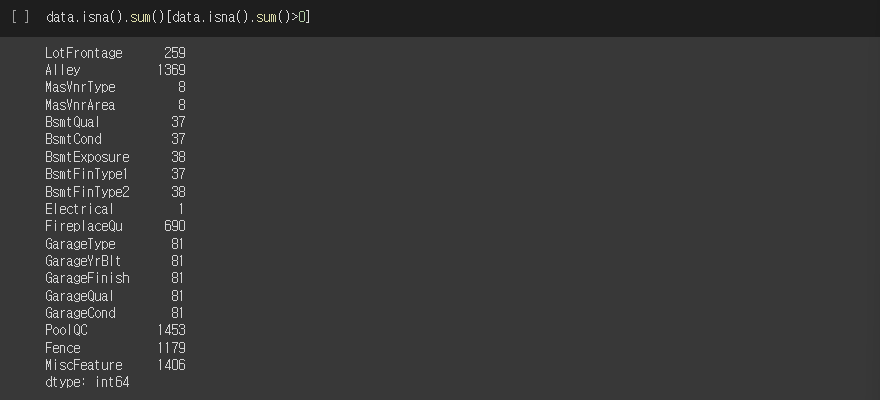
# NaN인 애들만 모아보기
data.isna().sum()[data.isna().sum()>0]실행결과
Meta data
- 데이터의 정보 데이터
- 데이터의 type, NaN, 통계정보, 요소 등의 정보를 포함할 수 있음
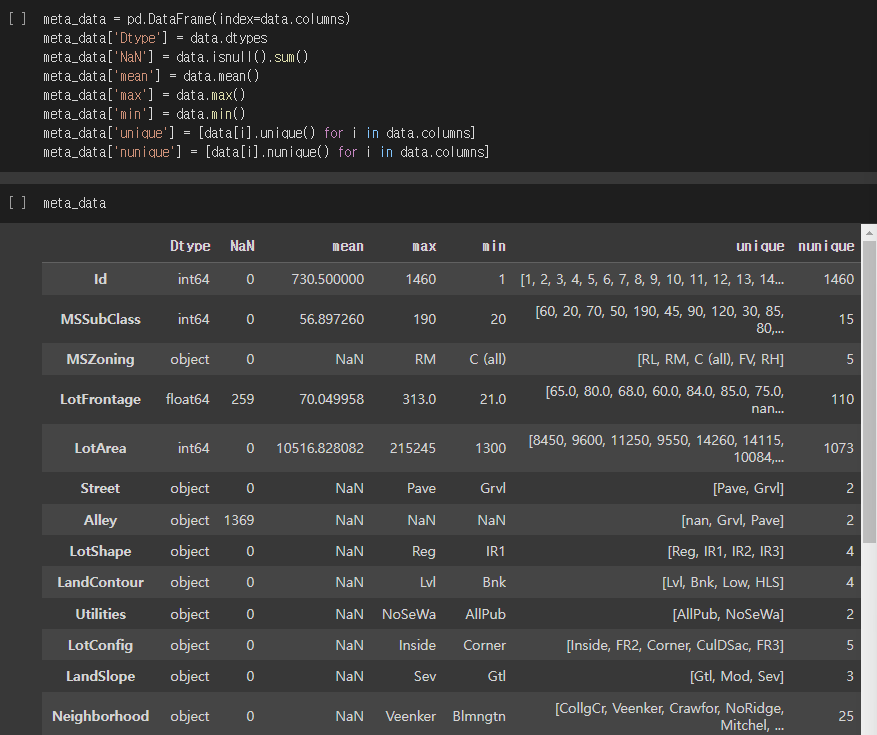
meta_data = pd.DataFrame(index-data.columns) # data의 각 column별 정보로 구성
meta_data['Dtype'] = data.dtypes # 데이터의 자료형
meta_data['NaN'] = data.isnull().sum() # NaN의 수
meta_data['mean'] = data.mean() # 데이터의 평균
meta_data['max'] = data.max() # 데이터의 최대값
meta_data['min'] = data.min() # 데이터의 최소값
meta_data['unique'] = [data[i].unique() for i in data.columns] # 데이터 요소 리스트
meta_data['nunique'] = [data[i].nunique() for i in data.columns] # 데이터 요소 리스트 수
meta_data실행결과
# DataFrame의 column별 정보 확인하기
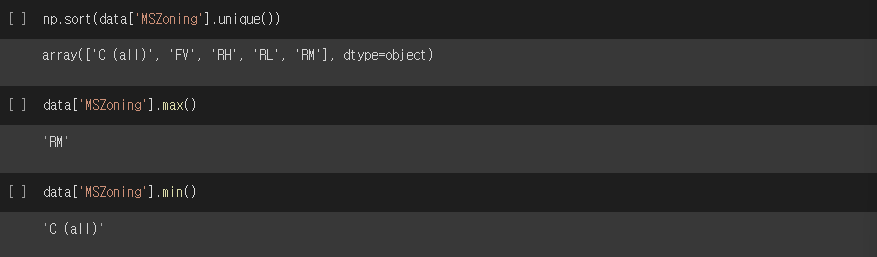
np.sort(data['MSZoning'].unique()) # 'MSZoning' column의 요소를 sort하여 반환
data['MSZoning'].max() # 'MSZoning' column의 요소 중 Max값 반환
data['MSZoning'].min() # 'MSZoning' column의 요소 중 Min값 반환실행결과
중복 데이터 처리
중복 데이터 생성
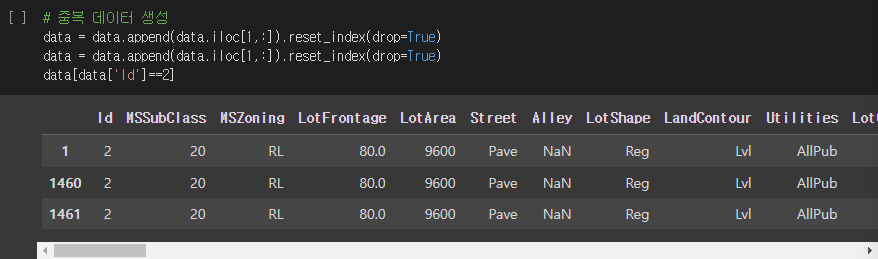
# 중복 데이터 생성
data = data.append(data.iloc[1,:].reset_index(drop=True)
data = data.append(data.iloc[1,:].reset_index(drop=True)
data[data['Id']==2]실행결과
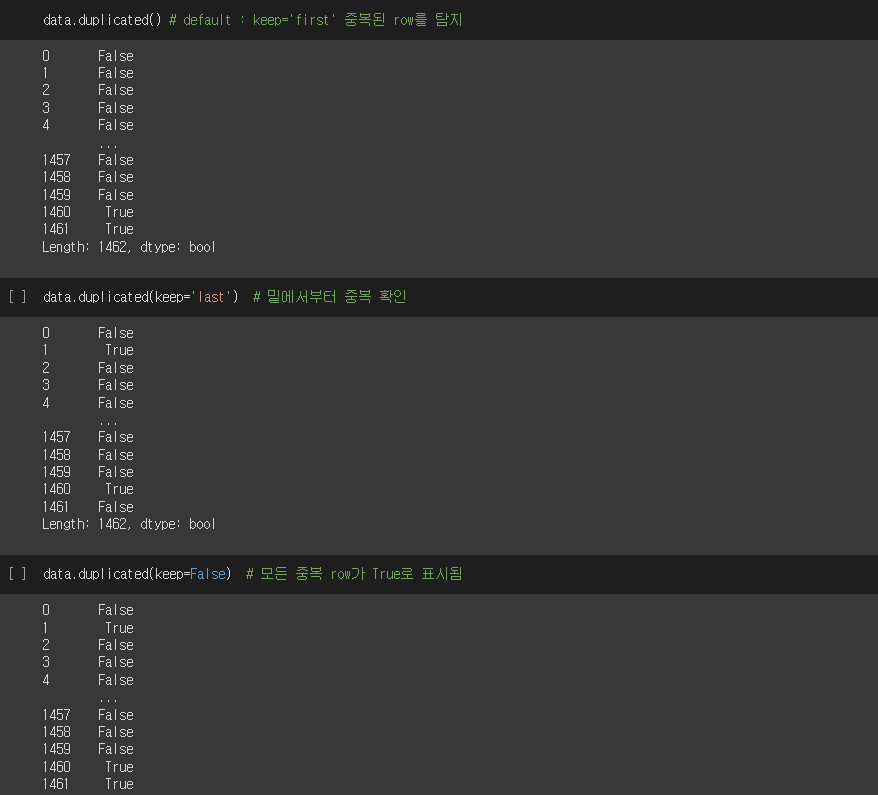
중복 데이터 확인
data.duplicated() # 기본: keep='first' 중복된 row를 탐지
data.duplicated(keep='last') # 옵션: keep='last' 밑네서부터 중복 탐지
data.duplicated(keep=False) # 옵션: 모든 중복 row가 True로 표시실행결과
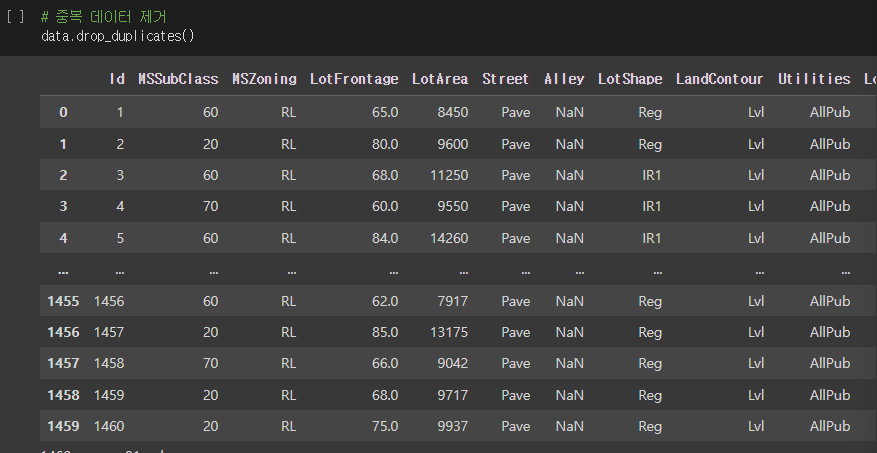
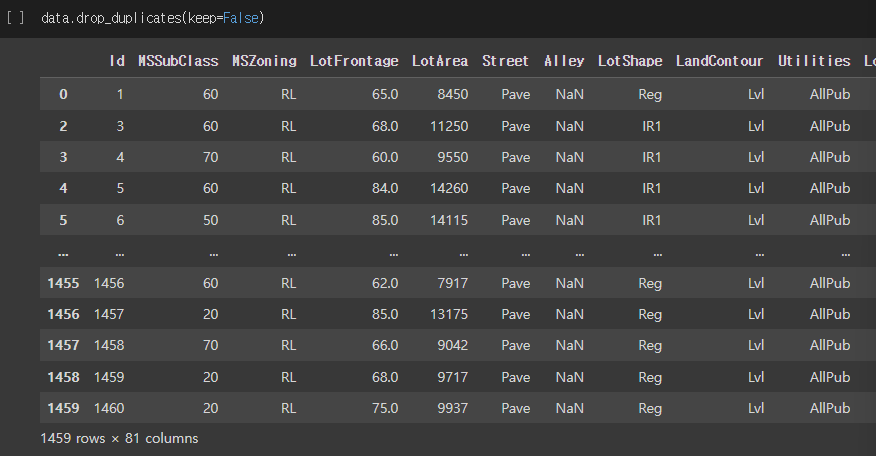
중복 데이터 제거
data.drop_duplicates() # 기본: 중복된 row를 탐지 후 제거
data.drop_duplicates(keep=False) # 옵션: 모든 중복 row를 제거실행결과
이상치 (Outlier)
- 관측된 데이터 범위에서 많이 벗어난 아주 작은 값이나 아주 큰 값
- 패턴에서 벗어난 값
- 이상치가 있다는 것이 특징(정보)가 될 수 있음
이상치 제거
- Z method (Z-score: 표준정규분포의 통계량)
- IQR(Interquartile range) method
Z method
- Numerical data 확인
data.dtypes[data.dtypes!='object'] 실행결과
# Z method 적용 함수
def z_method(data_1dim, thres): # 1차원 array와 threshold값을 받음
mean = np.mean(data_1dim) # 평균
std = np.std(data_1dim) # 표준편차
z_score = [(y-mean)/std for y in data_1dim]
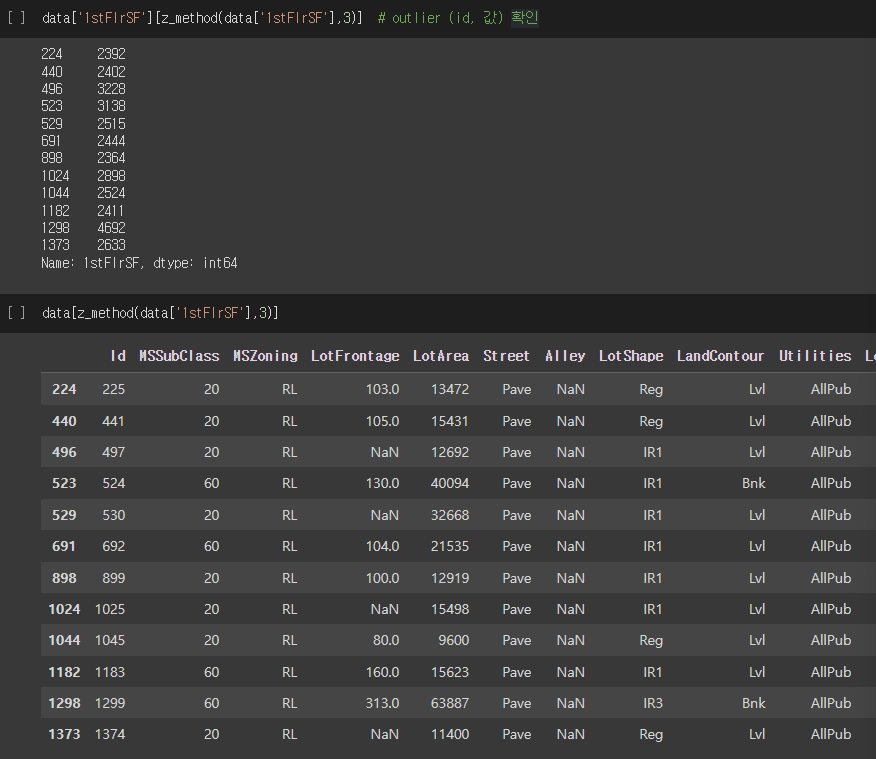
return np.abs(z_score) > thres # outlier detect특정 column의 값에 대해 z-score 구하기
data['1stFlrSF'][z_method(data['1stFlrSF'],3)] # outlier (id, 값) 확인
data[z_method(data['1stFlrSF'],3)] # outlier 항목(DataFrame) 확인 실행결과
IQR method
- Numerical data 확인
- 시각화 툴 이용
import matplotlib.pyplot as plt
import seaborn as sns
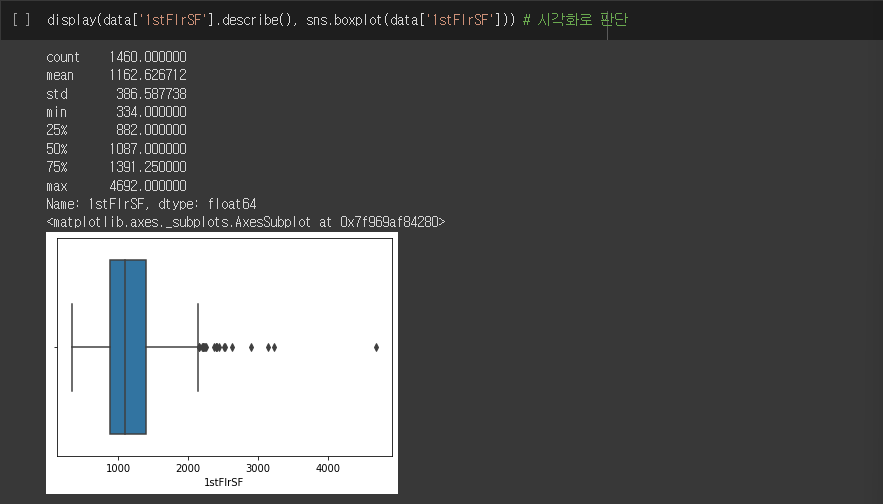
display(data['1stFlrSF'].describe(), sns.boxplot(data['1stFlrSF'])) # 시각화 실행결과
def IQR_method(data_1dim):
Q1, Q3 = np.percentile(data_1dim, [25,75])
IQR = Q3 - Q1
lower_bound = Q1 - (IQR * 1.5)
upper_bound = Q3 + (IQR * 1.5)
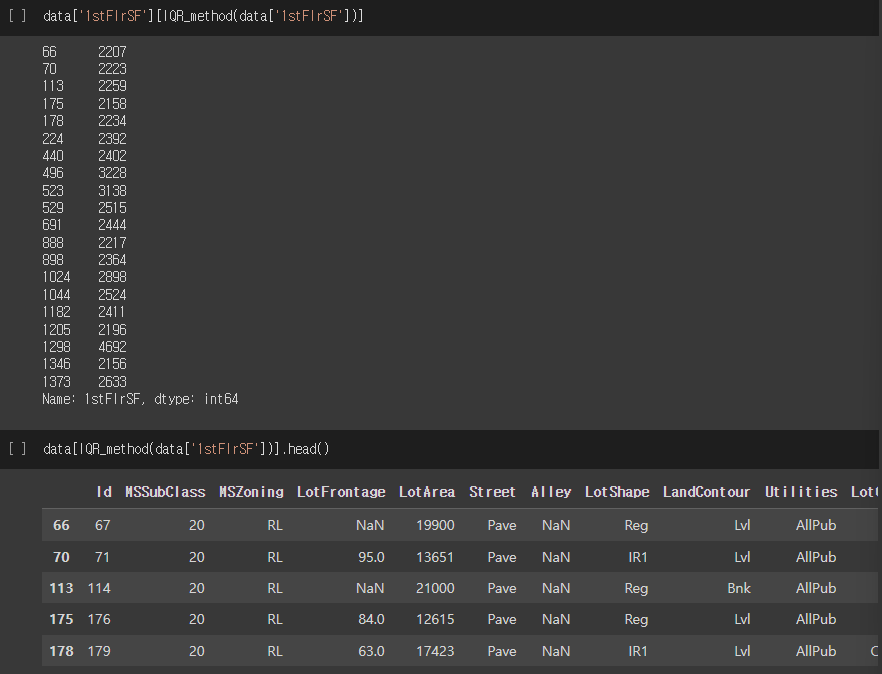
return (data_1dim < lower_bound) | (data_1dim > upper_bound) # outlier detect- 특정 column에 대해 IQR 범위 외 outlier 구하기
data['1stFlrSF'][IQR_method(data['1stFlrSF'])] # outlier (id, 값) 확인
data[IQR_method(data['1stFlrSF'])] # outlier 항목 (DataFrame) 확인실행결과
결측치 처리
- 제거
- 대체 (imputation)
- mean, median, zero-1, most frequent value, interpolation, perdict(KNN)
결측치 확인
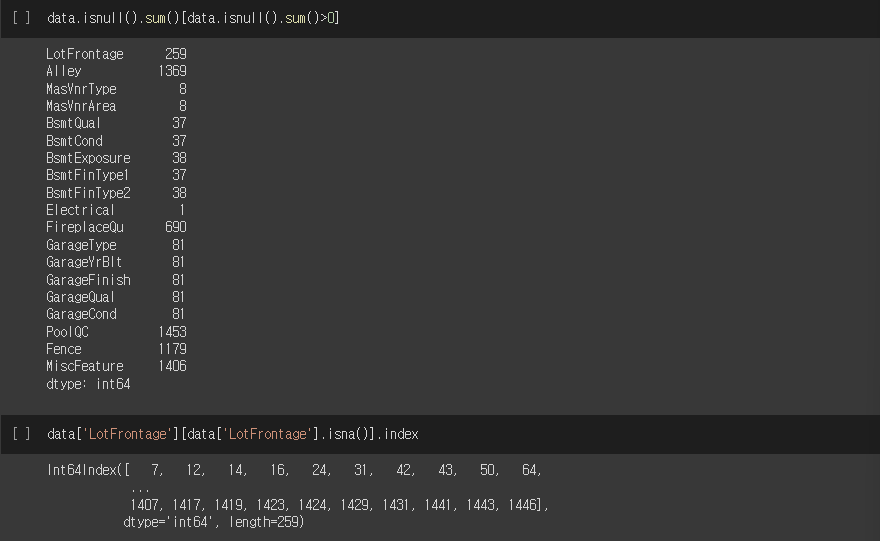
data.isnull().sum()[data.isnull().sum()>0]
data['LotFrontage'][data['LotFrontage'].isna()].index실행결과
결측치 채우기
Numerical Data
temp = data['LotFrontage'][:20]
temp.interpolate() # 기본 옵션: linear -> NaN을 linear값으로 채우기
temp.interpolate(method='nearest') # NaN을 근처 값으로 채우기
temp.fillna(-1) # NaN을 -1로 채우기
temp.fillna(temp.mean()) # NaN을 전체 평균값으로 채우기Categorical Data
temp = data['BsmtQual'][17:40]
temp.value_counts() # 요소 수 카운트
from sklearn.impute import SimpleImputer
impute = SimpleImputer(strategy='most_frequent') # 최빈값으로 채우기
impute.fit_transform(temp.values.reshape(-1,1)) # array 형태 변환Correlation (상관관계) 구하기
PLCC (Pearson Linear Correlation Coefficient)
- |1|에 가까울수록 상관관계가 있고 0에 가까울수록 상관관계가 없음
- 연속형 변수 사용
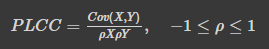
두 column의 상관관계 찾기
temp = data[['GarageArea', 'SalePrice']]
temp.corr()
np.corrcoef(temp['GarageArea'],temp['SalePrice'])실행결과
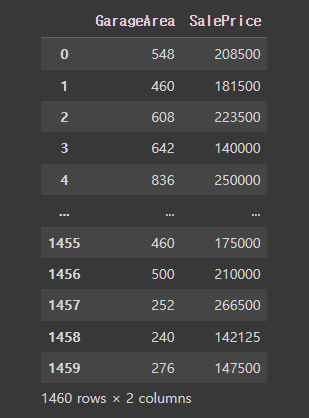


- DataFrame에서 상관관계 찾기
data.iloc[:,:20].corr()
# 상관관계 시각화
plt.filgue(figsize=(10,4))
sns.heatmap(data.iloc[:,:20].corr())
plt.show()실행결과
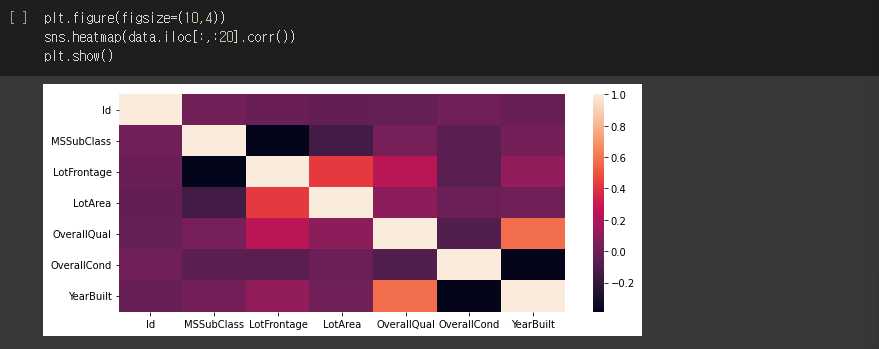
SROCC (Spearman rank-order correlation coefficient)
- 값에 순위를 매겨 순위에 대해 상관계수 계산
- SROCC가 1에 가까울수록 단조 상관성이 크고 0에 가까울수록 단조 상관성이 작음
- 연속형 변수, 순서형 변수 사용
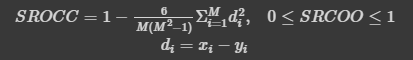
import scipy.stats
scipy.stats.spearmanr(temp['GarageArea'],temp['SalePrice']).correlation
temp.corr(method='spearman')실행결과
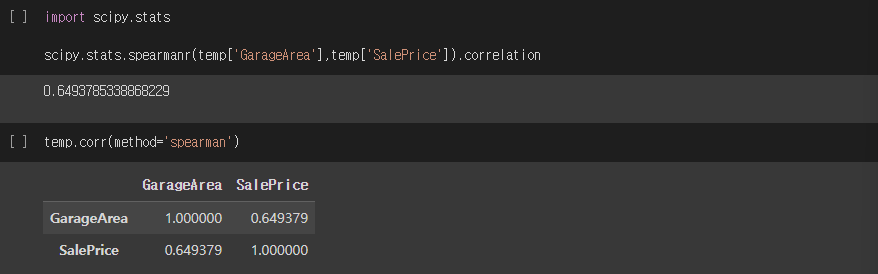
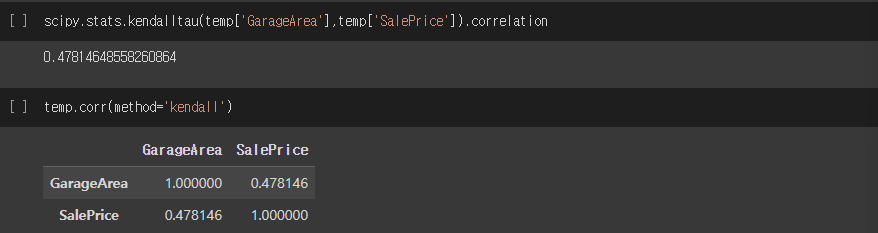
KRCC (Kendall rank correlation coefficient)
- 두 변수들 간의 순위를 비교하여 연관성을 계산
- 순서형 변수 사용
- concordant pair: 각 변수비교 대상의 상하관계가 같은 쌍
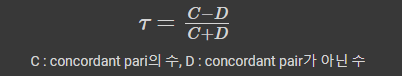
scipy.stats.kendalltau(temp['GarageArea'],temp['SalePrice']).correlation
temp.corr(method='kendall')실행결과
Scaling
- 각 feature의 단위(scale)를 동일하게 맞춰 모델이 특정 feature에 편향되게 학습하는 것을 방지
- MinMaxScaler
- StandardScaler
- RobustScaler
- Log Transform
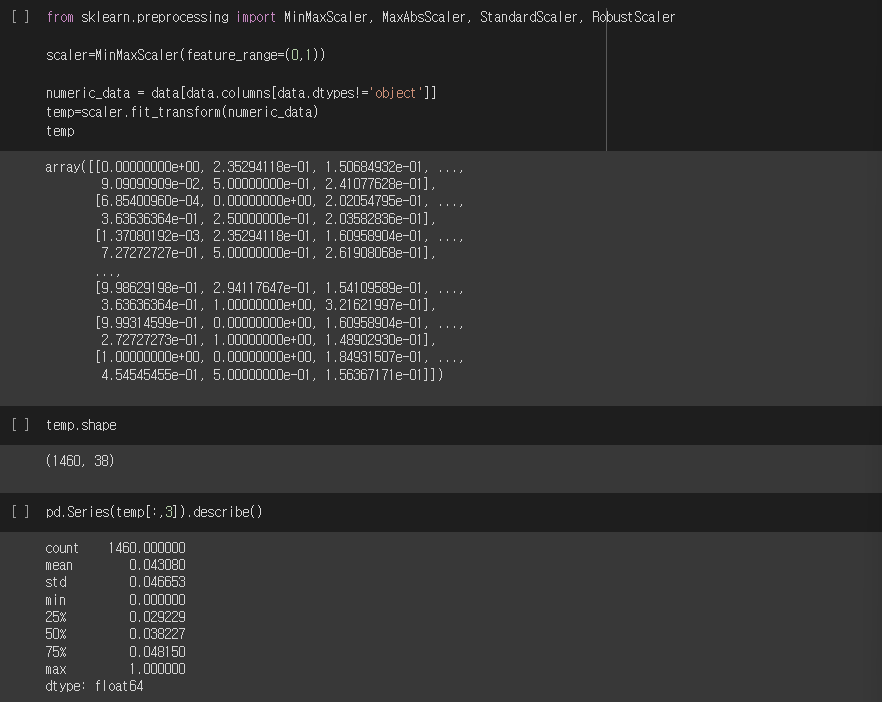
from sklearn.preprocessing import MinMaxScaler, MaxAbsScaler, StandardScaler, RobustScaler
scaler = MinMaxScaler(feature_range=(0,1))
numeric_data = data[data.columns[data.dtypes!='object']]
temp = scaler.fit_transform(numeric_data)
pd.Series(temp[:,3]).describe() # index=3의 통계정보 확인실행결과
Scaler
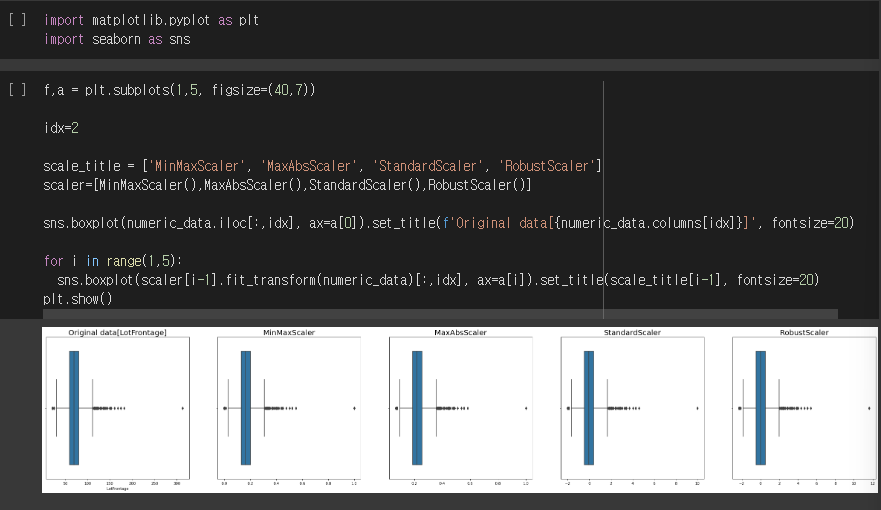
import matplotlib.pyplot as plt
import seaborn as sns
f, a = plt.subplots(1,5,figsize=(40,7) # 1개 5등분 화면크기
idx = 2
scale_title = ['MinMaxScaler', 'MaxAbsScaler', 'StandardScaler', 'RobustScaler']
scaler = [MinMaxScaler(), MaxAbsScaler(), StandardScaler(), RobustScaler()]
# Original data 시각화 출력
sns.boxplot(numeric_data.iloc[:,idx], ax=a[0]).set_title(f'Original data[{numeric_data.columns[idx]}]', fontsize=20)
# Scaled data 시각화 출력
for i in range(1,5):
sns.boxplot(scaler[i-1].fit_transform(numeric_data)[:,idx], ax=a[i]).set_title(scale_title[i-1], fontsize=20)
plt.show() 실행결과
Log Transform
import numpy as np
c1 = 10
c2 = 7777
print(c1/c2)
print(np.log(c1)/np.log(c2))실행결과

Categorical data encoding
- one-hot encoding
- label encoding
- ordinal encoding
One-hot encoding
- text data를 numeric data로 변경
- 우선순위 없음
- 순서가 없는 경우 (이름 등), 고유값의 개수가 적을 때 효율적
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
one_hot = encoder.fit_transform(temp)
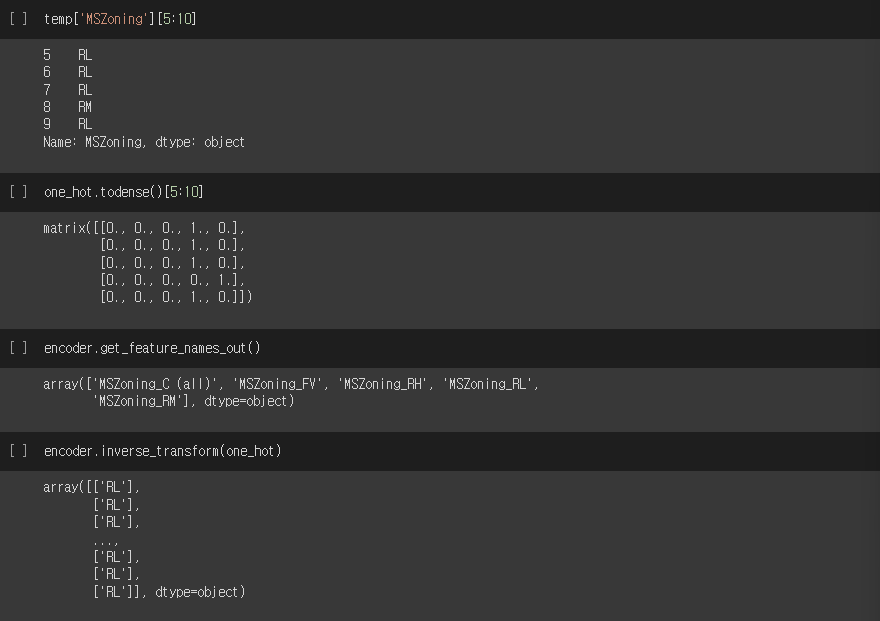
temp['MSZoning'][5:10]
one-hot.todense()[5:10]
encoder.get_feature_names_out()
encoder.inverse_transform(one_hot)실행결과
Label encoding
- text data를 numeric data로 변경
- 우선순위 있음
- 순서가 있는 경우 사용
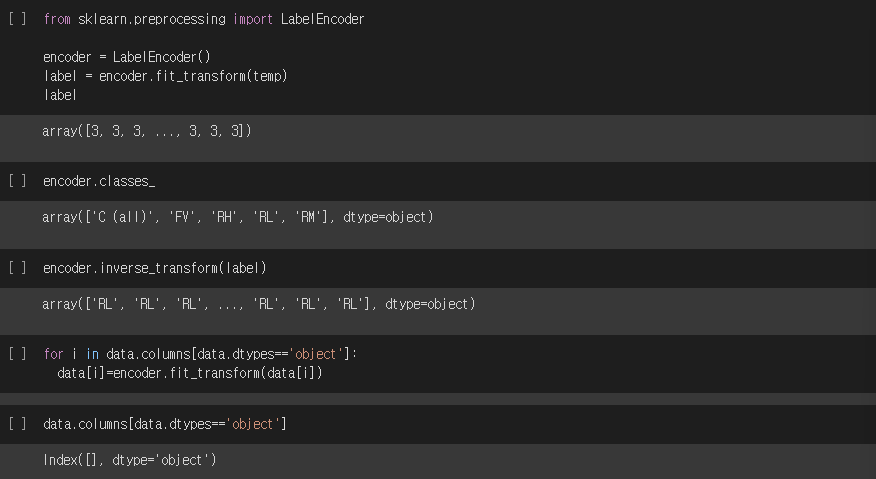
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
label = encoder.fit_transform(temp)
encoder.classes_
encoder.inverse_transform(label)
for i in data.columns[data.dtypes=='object']:
data[i] = encoder.fit_transform(data[i])
data.columns[data.dtypes=='object']실행결과
Data binning
- 연속형 변수를 특정 구간으로 나누어 범주형/순위형 변수로 변환하는 방법
- continuous value -> discrete value
- 이상치 완화, 과적합 완화
Data binning 예시
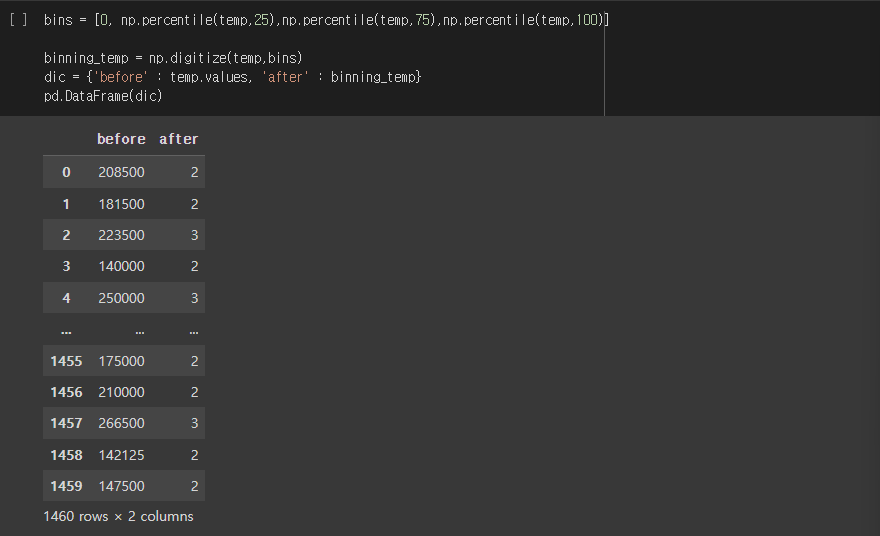
bins = [0, np.percentile(temp, 25), np.percentile(temp,75), np.percentile(temp,100)]
binning_temp = np.digitize(temp, bins)
dic = {'before' : temp.values, 'after' : binning_temp}
pd.DataFrame(dic)실행결과
Data binning 후 label 붙이기
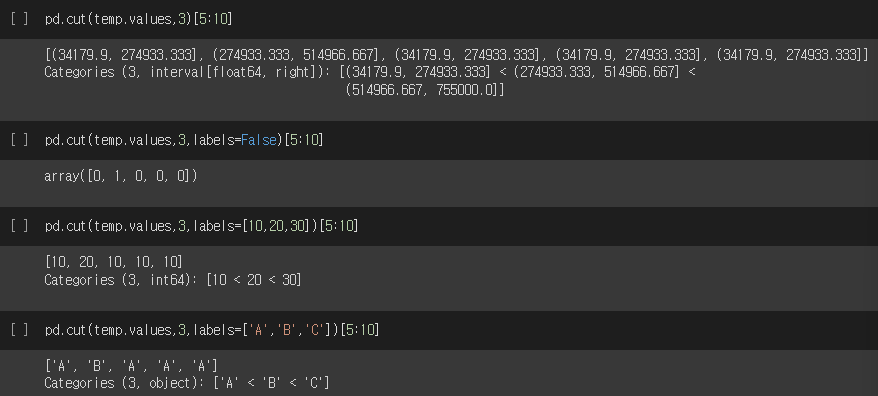
pd.cut(temp.values, 3)[5:10]
pd.cut(temp.values, 3, labels=False)[5:10]
pd.cut(temp.values, 3, labels=[10,20,30])[5:10]
pd.cut(temp.values, 3, lables=['A','B','C'])[5:10]**실행결과