
1. ANOVA road map
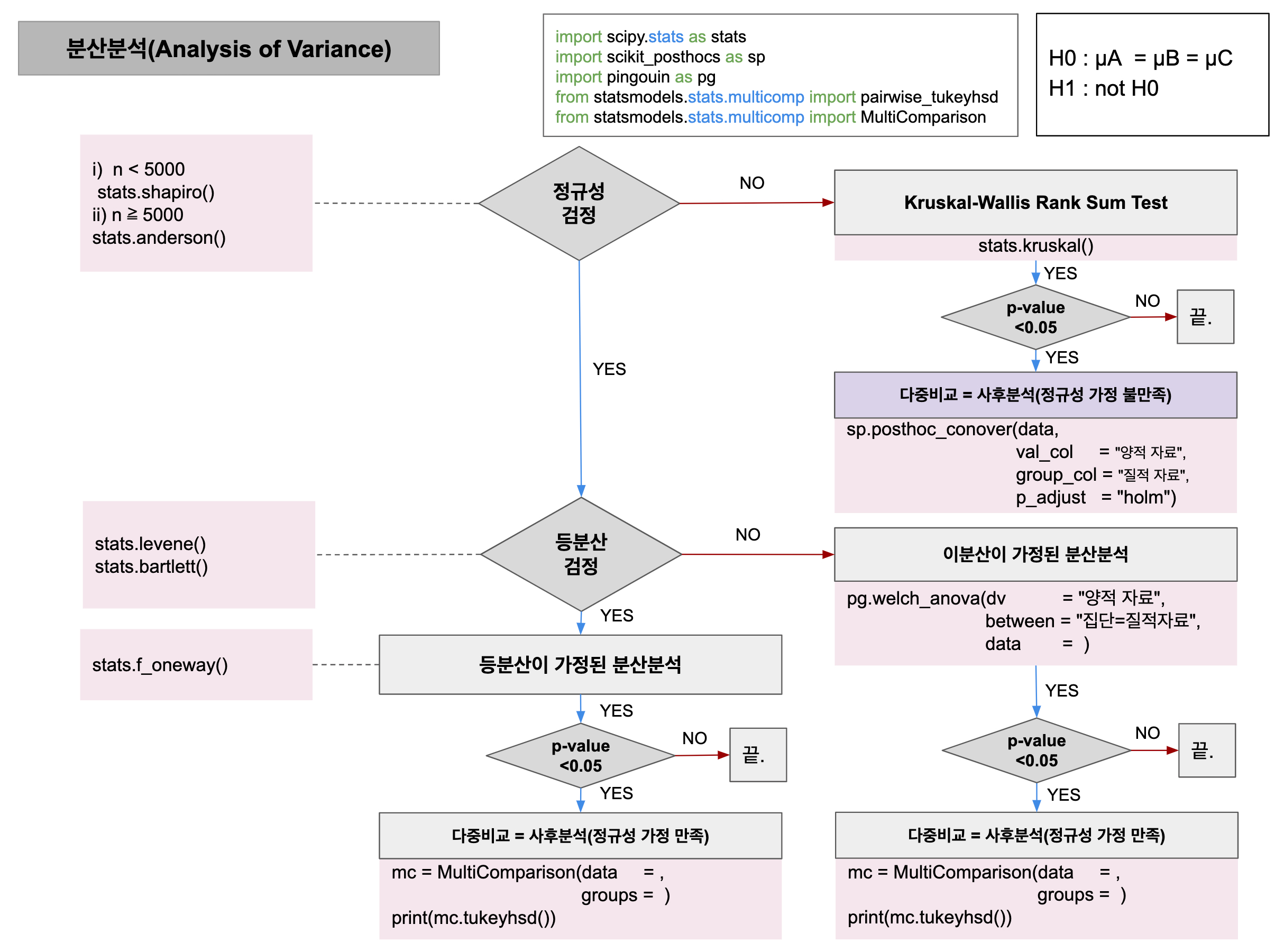
2. 정규성 검정
-
귀무가설 : 정규분포를 따른다.
-
대립가설 : 정규분포를 따르지 않는다.
모든 표본 하나씩 다 확인해야 함
만약 하나의 표본이라도 귀무가설을 기각할 경우 분산 분석을 실시하지 못함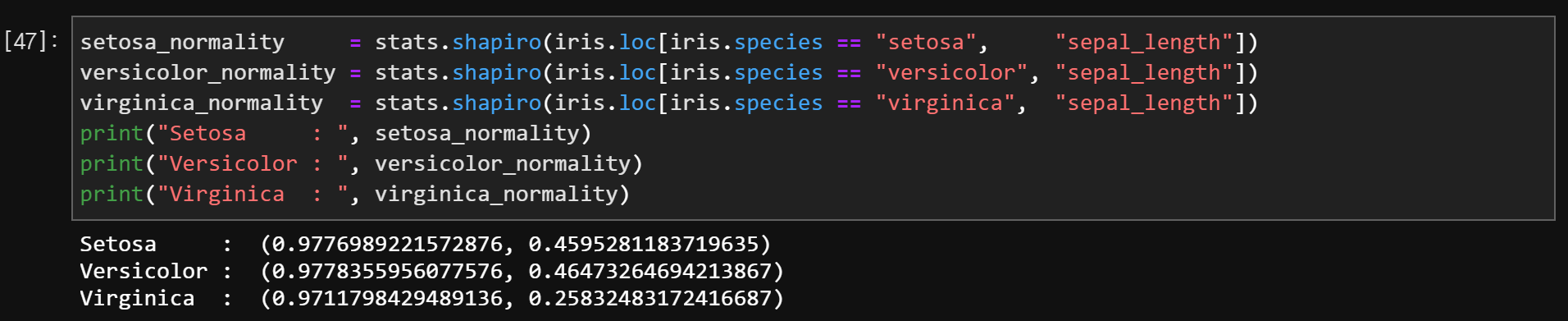
3. Kruskal-Wallis Rank Sum Test
- k 집단 중 하나라도 정규성 가정이 깨질 때 사용함
stats.kruskal(집단 의 양적자료, 집단 2의 양적자료, 집단 3의 양적자료)
4. 등분산 검정
- 귀무가설 : 등분산이다.
- 대립가설 : 이분산이다.

5. 분산분석
- 귀무가설 : k개의 집단 간에 차이가 없다.
- 대립가설 : k개의 집단 간에 차이가 있다.
1) 등분산이 가정된 분산분석
(1) Code
stats.f_oneway(집단 1의 양적자료, 집단 2의 양적자료, 집단3의 양적자료)
# oneway : 일원배치 (일원 = 하나의 질적 자료)
- 결론 : 유의확률이 0.000이므로 유의수준 0.05에서 품종에 따라 꽃잎의 길이에 통계적으로 유의한 차이가 있는 것으로 나타났다.
2) 이분산이 가정된 분산분석
(1) Code
import pingouin as pg
pg.welch_anova(dv = '양적자료', between = '집단(질적자료)', data = )
# dv : dependent variable (종속변수 = 반응변수) : 양적자료
# between : independent variable (독립변수 = 설명변수) : 질적자료
- ddof1 = 자유도 : k-1 = 2 -> k = 3
- ddof2 = 자유도 : n-k = 78.073 -> n = 75.073
- F = 검정통계량 : 1828.092
- p-unc = P-value : 0.000
6. 다중비교 & 사후분석
1) 다중비교 (Multiple Comparisons)
(1) Code
from statsmodels.stats.multicomp import pairwise_tukeyhsd
from statsmodels.stats.multicomp import MultiComparison
mc = MultiComparison(data = 양적 자료, groups = 질적 자료)
print(mc.tukeyhsd())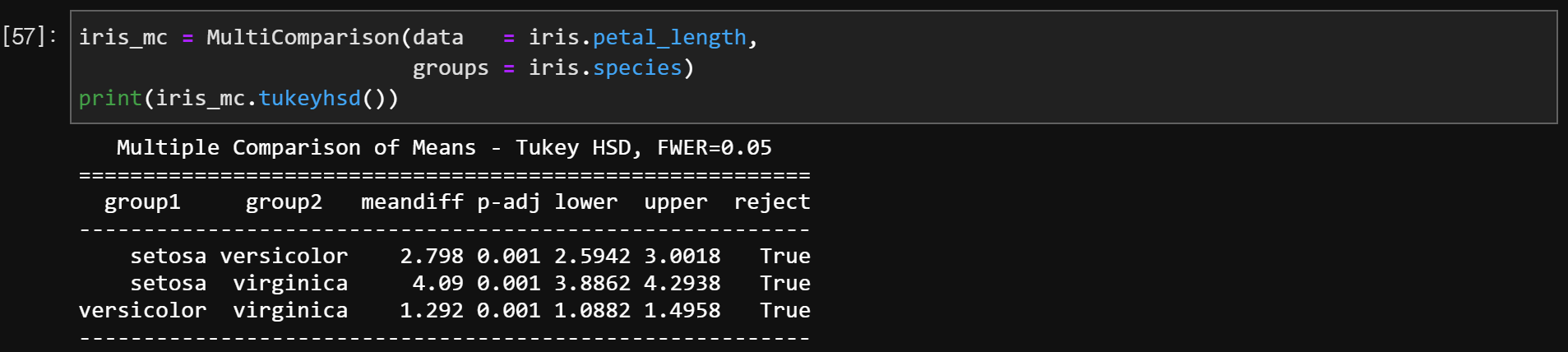
- meandiff = group2 - group1
- p-adj = P-value
- reject = 귀무가설 기각 : True, 채택 : False
2) 사후분석 (Post-Hoc)
(1) Code
import scikit_posthocs as sp
sp.posthoc_conover(data,
val_col = '양적 자료',
group_col = '질적 자료',
p_adjust = 'holm')
# p_adjust : 다중비교(또는 사후분석)의 방법
# 'holm' : Bonferroni 방법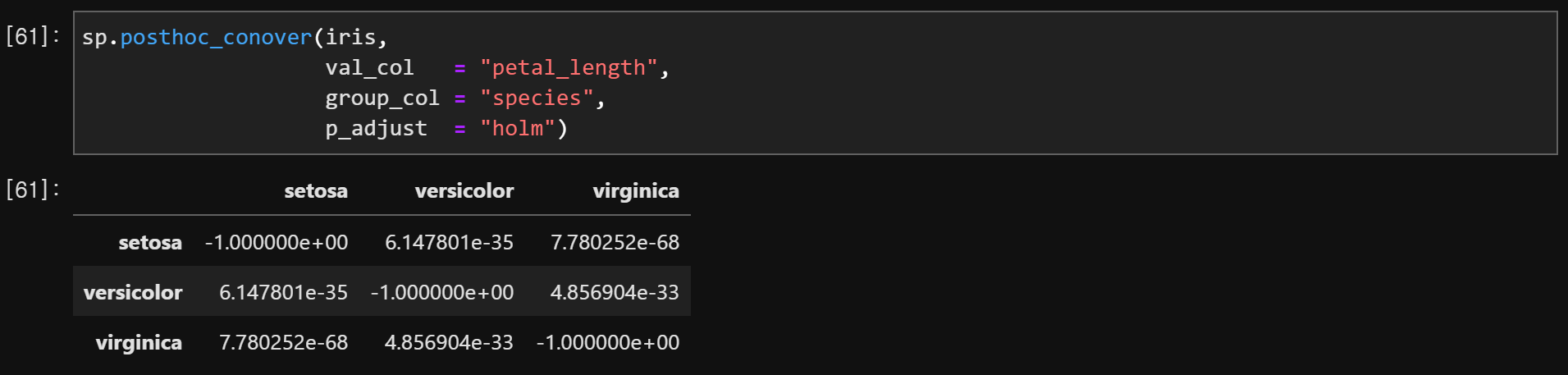
- 행, 열 간의 P-value 값이 나온다.

Back-end, Python, Data