0. Abstract
MobileNet은 모바일이나 임베디드 비전 앱을 위한 모델.
가벼운 DNN을 만들기 위해 depthwise separabel convolution 사용.
hyper params (latency and accuracy)로 적절한 크기의 사이즈 구현.
1. Introduction
일반적으로 높은 정확도를 위해 네트워크를 깊고 복잡하게 만듦.
크기와 속도 측면에서 효율적인 것만은 아님.
MobileNet에서는 작고 빠른 모델을 위한 네트워크 구조와 hyper params 소개.
2. Prior Work
작고 효율적인 신경망을 위해 사전학습된 네트워크를 압축하거나 작은 네트워크를 직접 학습.
MobileNet은 latency와 size에 맞는 작은 네트워크를 선택.
latency를 최적화하고 작은 네트워크를 만드는 것이 주된 목표.
MobileNet은 depthwise separable convolution 사용.
3. MobileNet Architecture
3.1 Depthwise Separable Convolutoin
depthwise separable convolution은 standard convolution을 depthwise와 pointwise로 나눈 것.
Convolutions
1) Standard : 채널 + 공간 방향의 convolutoin.
2) Depthwise : 공간 방향만의 convolution.
3) Pointwise : 채널 방향만의 convolution (⇔ convoltuion)Reference
[딥러닝] Depth-wise Separable Convolution 원리(Pytorch 구현)
depthwise convolution으로 각각의 input 채널당 하나의 필터를 적용. pointwise convolution으로 이전의 output을 결합.
죽, depthwise separable = filtering + combining
이는 연산과 모델 크기를 급격하게 줄여줌.
※ Standard convolution은 filtering과 combining을 한 번에 수행.
Input : feature map
Output : feature map
Standard Convolution
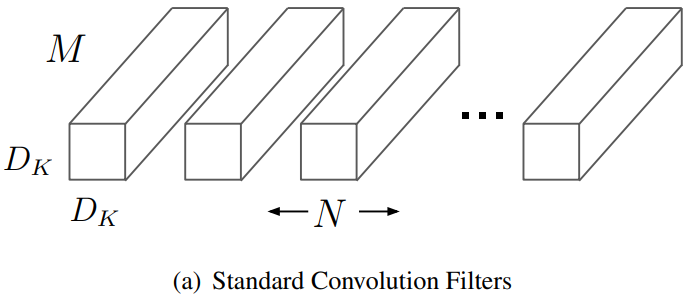
Kernel : 개의
Computational cost :
Depthwise Separable Convolution
Depthwise separable convolution은 depthwise와 pointwise로 구성.
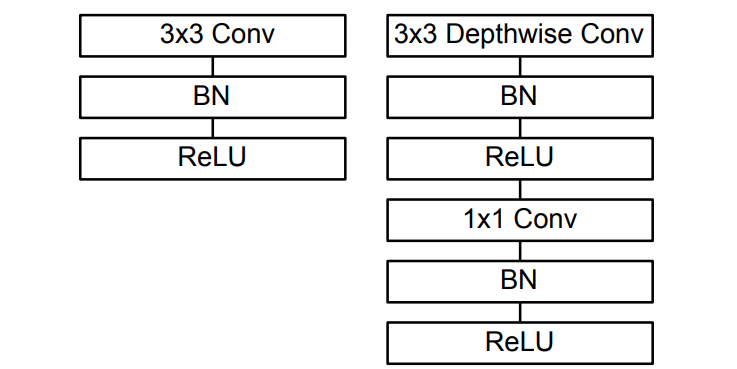
MobileNet은 이에 더해 BN과 ReLU 사용.
Stride 1과 padding 적용.
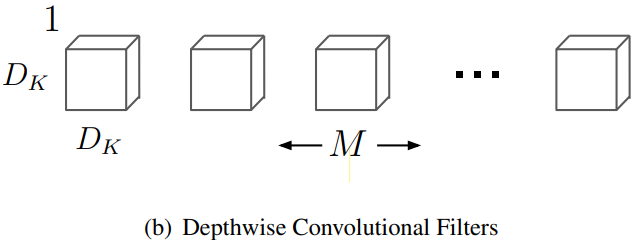
Kernel : 개의
Computational cost :
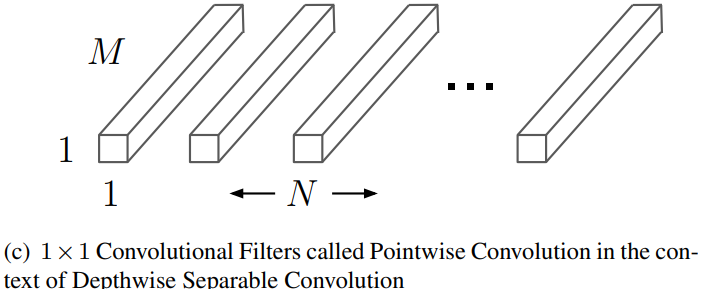
Kernel : 개의
Computational cost :
Total depthwise separable convolutions cost :
연산의 비율은
을 사용하므로 8~9배 연산량 감소 (은 매우 크므로 무시).
3.2 Network Structure and Training … help
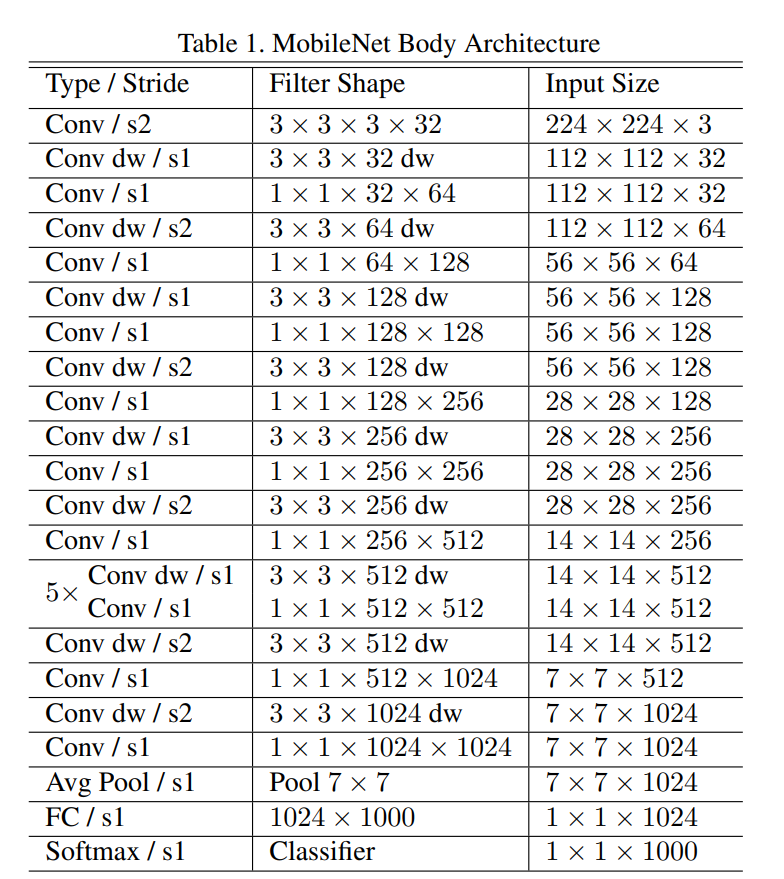
첫 layer를 제외하고는 depthwise separable convolution.
마지막 fc lyaer를 제외한 모든 layer 뒤에 BN과 ReLU 적용.
Down sampling은 strided convolution으로 수행.
# of total layers is 28.
3.3 Width Multiplier: Thinner Models
depthwise separable convolution을 통해 모델이 작고 빨라졌지만, 더 좋은 성능을 요구.
이에 parameter (width multiplier) 도입.
width multiplier 는 네트워크를 얇게함.
Computational cost : where
width multiplier 는 연산량과 # of params를 배 줄임.
3.4 Resolution Multiplier: Reduced Representation
resolution 는 input 이미지에 곱함.
Computational cost : where
resolution multiplier 는 연산량과 # of params를 배 줄임.
4. Experiments
4.1 Model Choices

정확도는 고작 1%.
다만, 연산량과 # of params가 엄청나게 감소.
4.2 Model Shrinking Hyperparameters
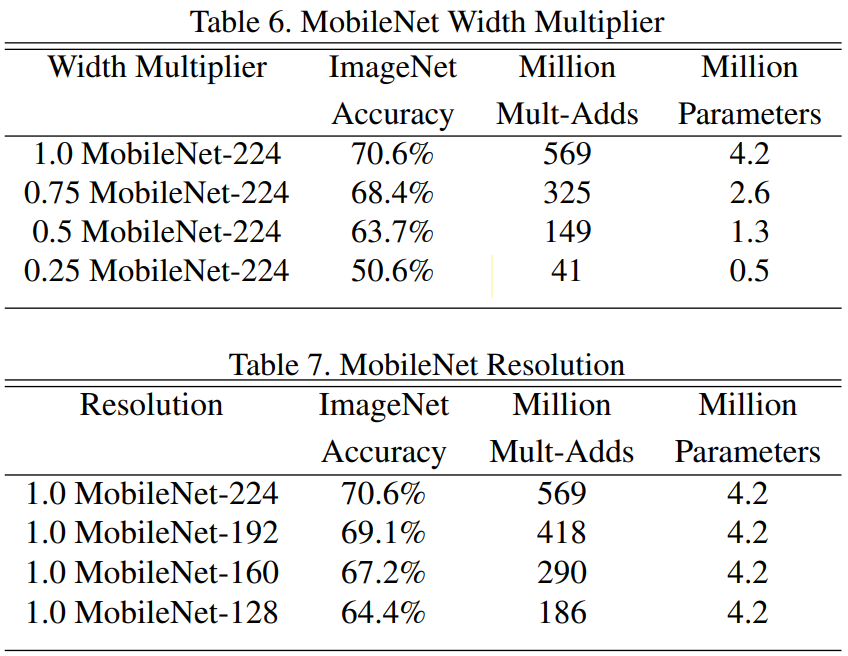
5. Conclusion
We then demonstrated how to build smaller and faster MobileNets using width multiplier and resolutoin multiplier by trading off a reasonable amount of accuracy to reduce size and latency.
Reference
MobileNetV1 논문
MobileNetV1 논문 설명(MobileNets - Efficient Convolutional Neural Networks for Mobile Vision Applications 리뷰)
[CNN Networks] 11. MobileNet (1) - Depthwise Separable Convolution
[CNN Networks] 12. MobileNet (2) - MobileNet의 구조 및 성능
