Point Cloud
Lidar 센서, RGB-D센서 등으로 수집되는 데이터를 의미한다.
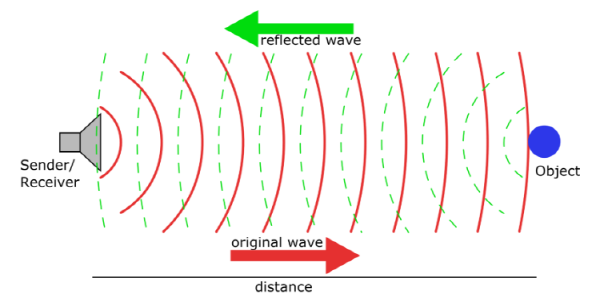
이러한 센서들은 아래 그림처럼 물체에 빛/신호를 보내서 돌아오는 시간을 기록하여 각 빛/신호 당 거리 정보를 계산하고, 하나의 포인트(점)을 생성한다.
포인트 클라우드는 3차원 공간상에 퍼져 있는 여러 포인트(Point)의 집합(set cloud)를 의미한다.
Lidar 센서와 RGB-D 센서로 수집된 데이터는 각각 아래 그림과 같이 나타난다.

Lidar 센서로 수집된 Point Cloud

RGB-D 센서로 수집된 Point Cloud
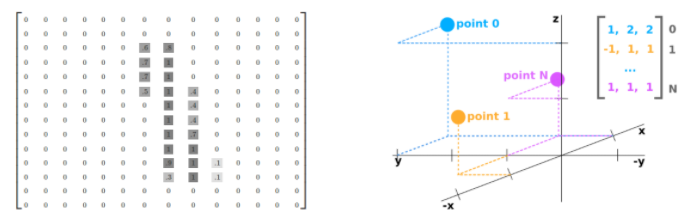
점군(Point Cloud)은 2D 이미지와 다르게 깊이(z축) 정보를 가지고 있기 때문에, 기본적으로 [N X 3] Numpy 배열로 표현된다.
여기서 각 N 줄은 하나의 점과 맵핑이 되며, 3(x, y, z) 정보를 가지고 있다.
이미지 데이터와 Point Cloud
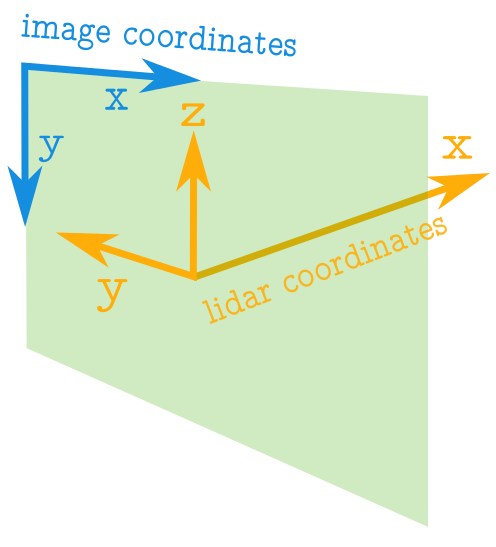
이미지 데이터에서 픽셀의 위치 정보는 항상 양수이다. 기준점은 왼쪽 위 부터이며 좌표값은 정수로 표현한다.
Point Cloud에서 점의 위치는 양수 또는 음수이다. 기준점은 센서의 위치이며, 좌표값은 실수로 표현한다.
기준점의 좌표에서 x, y, z 값은 다음과 같이 나타낸다.
x : 앞, 뒤
y : 왼쪽, 오른쪽
z : 위, 아래
Point Cloud Technology의 이해를 돕는 다섯 가지 리스트
- Points are Easy
- There are many many Point Cloud Formats
- There is a Point Cloud Library
- Point Clouds Takes Time
- Point Clouds are Evolving
1: Points are Easy
유용한 Point Cloud의 핵심은 Individual 하며 Unrelated 한 점을 사용하는 것이다.
Point Cloud는 상대적으로 쉽게 Edit, Display, Filtering 할 수 있는 무료 소프트웨어들이 있다. ( e. g. CloudCompare )
컴퓨터는 Point들의 Scale 혹은 Rotation을 고려하지 않아도 되고, 각 Point의 Position 이나 Color 정보만을 사용한다.
이러한 특징은 Detailed Data의 방대한 용량을 효율적으로 사용할 수 있게 한다.
또한, Point Cloud는 건물 또는 객체의 속성을 측정하는 데 방해를 받지 않는 방법이다.
예를 들면, 병원, 학교 및 스포츠 경기장과 같은 장소들을 측정하기 위해 해당 장소를 폐쇄할 필요가 없다.
대신에, 이러한 방법은 폐쇄 시간 이후에(가동 중지 시간, 혹은 업무 시간이 아닐 때) 수행할 수 있다.
이러한 측정 기술은 다른 방식보다 훨씬 더 정확하고 상세하다.
Point Cloud 이전에는 3D 측량이 거의 없었다.
2: There are many many Point Cloud Formats
3D 모델링을 위한 파일 형식은 수백개가 존재한다. 이것들의 호환성만 생각해도 머리가 지끈하다..
- Point Cloud의 파일 형식의 예
. asc ,. cl3 , . clr , . fls , . fws ,. las , . ptg , . pts , . ptx , . txt ,. pcd , . xyz 등
단순히 x, y, z 정보만을 가진 . xyz 포맷을 이용하여도 되고, 헤더 정보와 x, y, z를 가진 .pcd 포맷을 이용하기도 한다.
일반적으로 사용되는 *.pcd 포맷은 Header와 Data 세션으로 나누어진다.
- Header : 전체 포인트 수, 데이터 타입, 크기 등의 정보
- Data : x, y, z 또는 x, y, z + 추가정보
데이터를 어디에 어떻게, 누가 사용할지에 따라서 Output Format을 잘 설정하여 저장해야 한다.
3: There is a Point Cloud Library(PCL)
Point Cloud를 다루는 어느 회사나 조직들도 100% 자신들의 기술력으로 Point Cloud를 사용하지 않는다.
Point Cloud를 처리하는 Open Source, 즉 Library를 활용하기 마련이다.
PCL(Point Cloud Library)은 오픈소스 소프트웨어이다.
연구의 목적으로 사용하는 데 있어 무료이며, 다양한 OS에서 컴파일할 수 있다.
- pcl_filters : 3D 점군 데이터에서 이상값과 노이즈 제거 등의 필터링
- pcl_features : 점군 데이터로부터 3D 특징 추정 (feature estimation) 을 위한 수많은 자료 구조와 방법들
- pcl_keypoints : Keypoint (or interest point) 을 검출하는 알고리즘 구현 (BRISK, Harris Corner, NARF, SIFT, SUSAN 등)
- pcl_registration : 여러 데이터셋을 합쳐 큰 모델로 만드는 registration 작업 (ICP 등)
- pcl_kdtree : 빠른 최근거리 이웃을 탐색하는 FLANN 라이브러리를 사용한 kdtree 자료 구조
- pcl_octree : 점군 데이터로부터 계층 트리 구조를 구성하는 방법
- pcl_segmentation : 점군으로부터 클러스터들로 구분하는 알고리즘들
- pcl_sample_consensus : 선, 평면, 실린더 등의 모델 계수 추정을 위한 RANSAC 등의 알고리즘들
- pcl_surface : 3D 표면 복원 기법들 (meshing, convex hulls, Moving Least Squares 등)
- pcl_range_image : range image (or depth map) 을 나타내고 처리하는 방법
- pcl_io : OpenNI 호환 depth camera 로부터 점군 데이터를 읽고 쓰는 방법
- pcl_visualization : 3D 점군 데이터를 처리하는 알고리즘의 결과를 시각화
4: Point Clouds Takes Time
Point Cloud 데이터를 수집하는 핵심은 스캔된 표면에 대한 Access / Visibility 이다.
대부분의 경우, Point Cloud는 실제 객체에 대한 가시적 접근(Visiable access)를 통해 얻는다.
이것은 단순히 모든 스캔 위치를 커버하는 데 시간이 걸린다는 의미이다.
위에서 모든 위치에 대해 스캔하여 가져온 "레이저 스캔"을 정렬하는 것도 문제가 될 수 있다.
Target이 설정되었거나, 움직이는 Target을 정렬하려고 할 수도 있고, 혹은 Target을 정하지 않고 스캔한 뒤 컴퓨터로 교차검증을 하며 수동적으로 오버랩핑하는 스캔방식을 사용할 수도 있다.
전통적으로, Target의 placement를 피함으로써 절약된 시간은 사무실에서 보내는 시간보다 더 시간 소모가 크다.
예를 들어, 중간 규모 건물의 130개의 스캔 포인트 클라우드 데이터 세트를 처리하는 데 거의 25 시간이 걸릴 수 있다.
이러한 스캔을 수집하는 데 하루 밖에 걸리지 않았을 수 있지만, 수동방식으로 하는 처리방법은 해당 포인트 클라우드 데이터 세트의 등록을 수행하는 데 약 3 일이 소요될 수 있다.
그리고, 수동 수정이 필요한 경우 더 오래 걸릴 수 있습니다. 기존 방법을 사용하는 28-scan 데이터 세트는 일반적으로 완료하는 데 4 시간이 걸린다.
Missing link를 위한 Practical Targetless Registraion의 개발은 automated processing software로 한다.
5: Point Clouds are Evolving
포인트 클라우드는 Application 영역에서 점점 더 관련성이 높아지고 있다.
3D Point Cloud의 데이터 가용성, 정확성, 밀도 및 크기는 향후 몇 년 내에 크게 증가할 것으로 예상된다.
(availability, accuracy, density, and size)
기술의 발전으로 스캐너와 포인트 클라우드가 이러한 잠재력을 실현할 것이다.
머신러닝 알고리즘과 vector analysis를 통합한 Point Cloud 처리는 속도를 크게 높이고, 스캔 정렬에 수동으로 개입할 필요성을 줄여준다.기존에 있던 대부분의 Registration Solution각 스캔에서 인공 표적, 평면, 선과 같은 특징을 식별하여 작동한다.이러한 개체는 겹치는 스캔을 정렬하기 위한 참조로 사용한다.그러나, 머신러닝의 존재는 이제 스캔된 환경의 "Natural Features" 들을 "Virtual" 참조로 대신 사용할 수 있다.
일반적인 스캔에서 식별된 이러한 Natural Features가 수백만개에 달하여 정렬 속도를 높이고, 정확도를 높일 수 있다.이러한 기법을 사용하여 포인트 클라우드 처리의 효율성이 이미 40~80% 까지 개선된 경우도 있다.
예를 들어, 이전 Fact 4에서 말했던 "28-scan 데이터 세트"는 이제 완료하는 데 4시간이 아닌 약 1시간이 걸린다.
새로운 기술로 인한 비용 절감은 포인트 클라우드 Application에 대한 기회를 더욱 열어준다.