1. column 선택
- 단일 column 선택
df.age df['age'] # 안정적인 방법
- 다중 column 선택
df[['age', 'name']]
# 다양한 column 선택의 방법
import seaborn as sns
df_iris = sns.load_dataset('iris')df_iris['sepal_length']
# df_iris.sepal_legngh 와 같이 . 으로 가지고 오는 경우에는 컬럼 사이 띄어쓰기가 있는 경우 쓸 수가 없다
#그래서 [] 대괄호로 가지고 오는 방법이 안정적
# 변수를 활용한 다중 column 선택
# 컬럼을 2개 이상 가지고 오고싶다? 대괄호 안에 리스트를 넣어 줘야함
df_iris[['sepal_length', 'species']].head()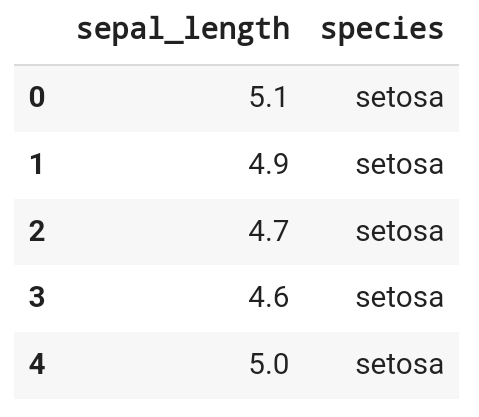
2. column 수정하기
column 삭제 : drop()
df.drop(labels = 'col1', axis=1, inplace=True # axis = 1 : 대상이 column # inplace = True : 원본 df 변경
column명 변경 : rename()
df.rename( columns= {'col1' : 'new_col1', 'col2':'new_col2'}, inplace=True) # 딕셔너리 사용
df_iris.head()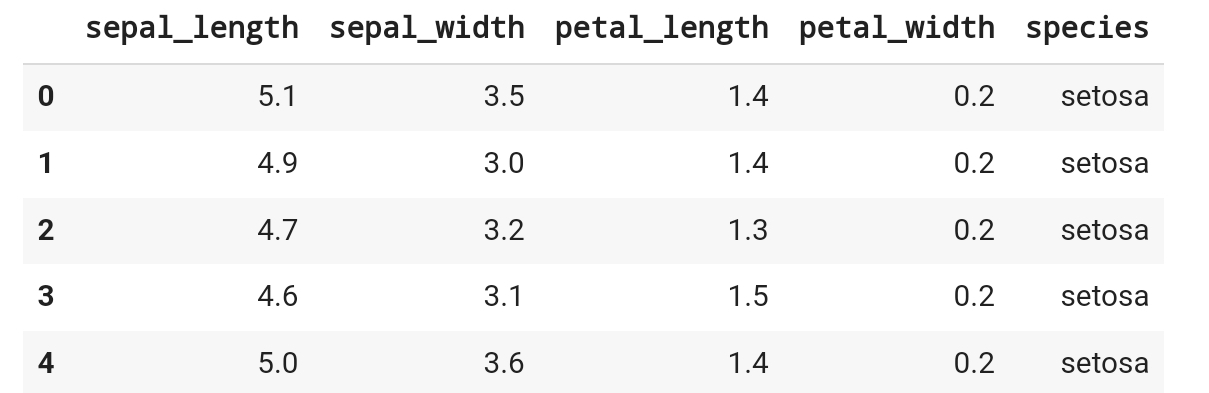
df_iris.rename( columns = {'sepal_length' : 'A', 'sepal_width' : 'B'}, inplace=True )
df_iris.head()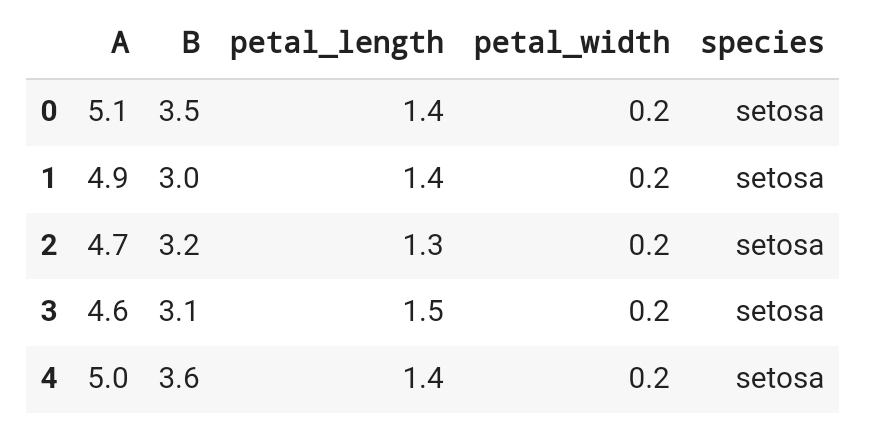
column 추가
df['new_col'] = existing_series
df_iris['A_plus_B'] = df_iris['A'] + df_iris['B']
df_iris.head()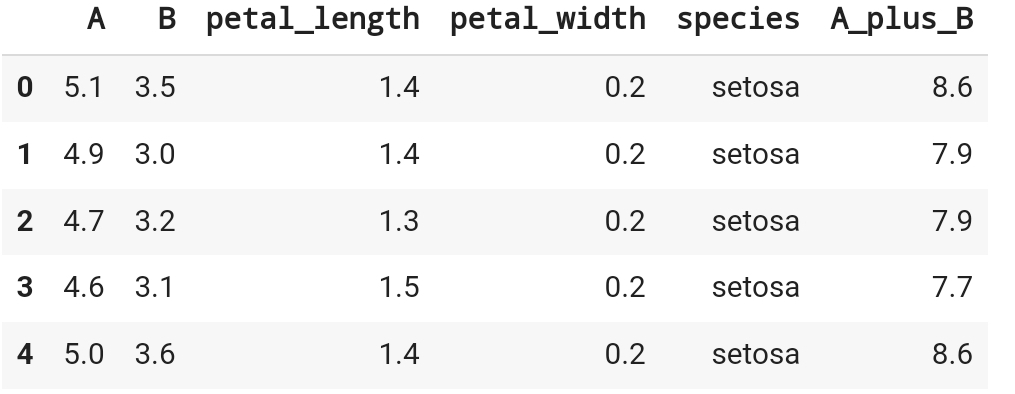
3. Series
DataFrame에서 하나의 column 만 선택하면 Series이다



- 사진 중략
4. nlargest(), nsmallest()
df.nlargest(number, ['col1', 'col2', ...])
# nlargest 다중 나열
df_iris.A.nlargest(10)
# 시리즈의 큰 값 기준으로 nlargest
df_iris.nlargest(10, ['A', 'B'])
# 두 개의 컬럼 기준으로
# A를 먼저 나열하고, A가 같은 값이면 B 기준으로 나열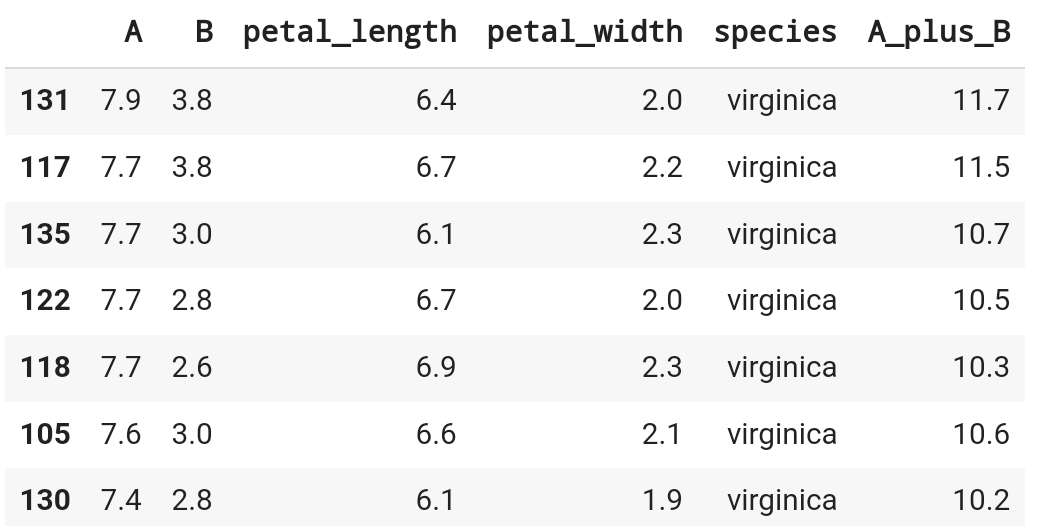
5. value_counts()
value_counts() : 각 값 별로 개수 세기
# column 하나
df_iris['A'].value_counts().head()
# column 두개
df_iris[['A', 'B']].value_counts().head()
# plot() bar 차트
df_iris['A'].value_counts().head().plot(kind='bar')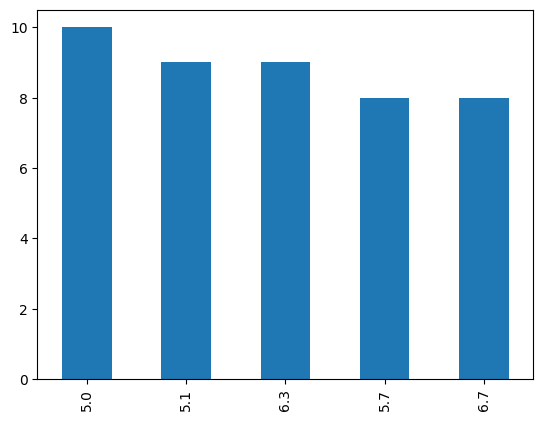

데이터 공부하는 예비 데이터 분석가, 김정민입니다.