1. Long Form vs Wide Form
가로로, 세로로 형태를 변환하는 걸 reshaping, pivoting이라고 한다.
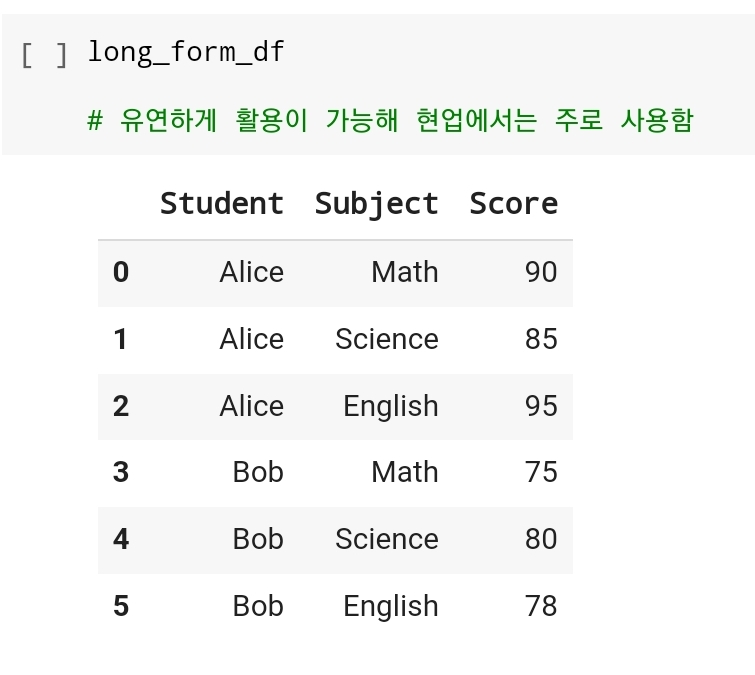
- Long Form :
긴 형식은 데이터를 더 상세하게 나타냄
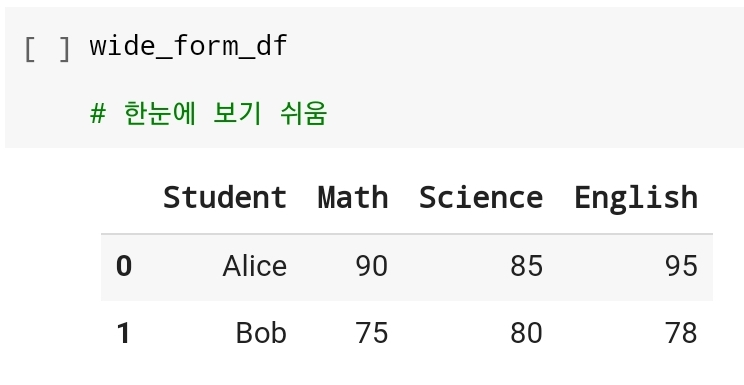
유연하게 데이터를 조작하고, 다양한 형태의 분석에 적합- Wide Form :
데이터의 전반적인 구조를 한 눈에 파악하기 용이
2. df.melt()
- Unpivot (melt) 예시 : 넓은 형식(Wide Form)에서 긴 형식(Long Form)으로 변환
- 주요 파라미터
- id_vars : 데이터의 식별자 역할을 하는 열의 이름을 나타냄. 이 열들은 그대로 유지됨
value_vars : 'long form'으로 변환하고자 하는 열의 이름
var_name : value_vars에 해당하는 열 이름들을 담을 새로운 열의 이름
value_name : value_vars에서의 값을 담을 새로운 열의 이름unpivot_df = wide_form_df.melt( id_vars= 'col_1', value_vars = ['col_2', 'col_3', ...], var_name = 'col_name_1', # variable name value_name = 'col_name_2' )
unpivot_df = wide_form_df.melt(
id_vars = 'Student', # 기준이 되는 파라미터
value_vars = ['Math, 'Science', 'English'],
var_name= 'Subject',
value_name= 'Score'
)
unpivot_df.sort_values('Student')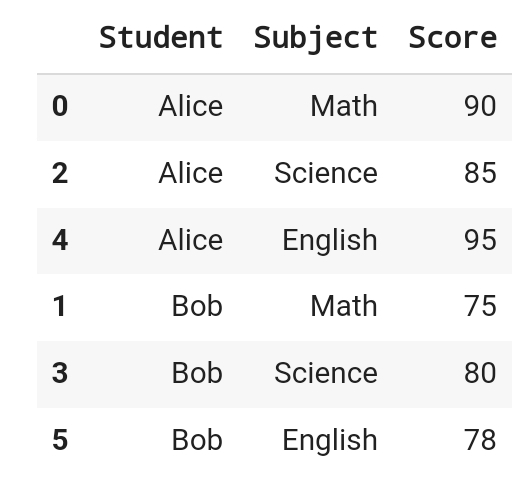
3. df.pivot_table()
- 기본 개념:
데이터 프레임을 재구조화하는 데 사용됨
특정 키 값에 따라 데이터를 요약하고, 그룹화함- 주요 파라미터 :
index : 피벗 테이블의 로우를 그룹화하는 데 사용되는 컬럼
columns : 피벗 테이블의 컬럼을 그룹화하는 데 사용되는 컬럼
values : 분석하려는 데이터 컬럼
aggfunc : 집계 함수, 예를 들어 np.sum, np.mean (기본값은 np.mean)df.pivot_table( index = 'col_1', columns = 'col_2', values= 'col_3', aggfunc = 'min/max/...' )
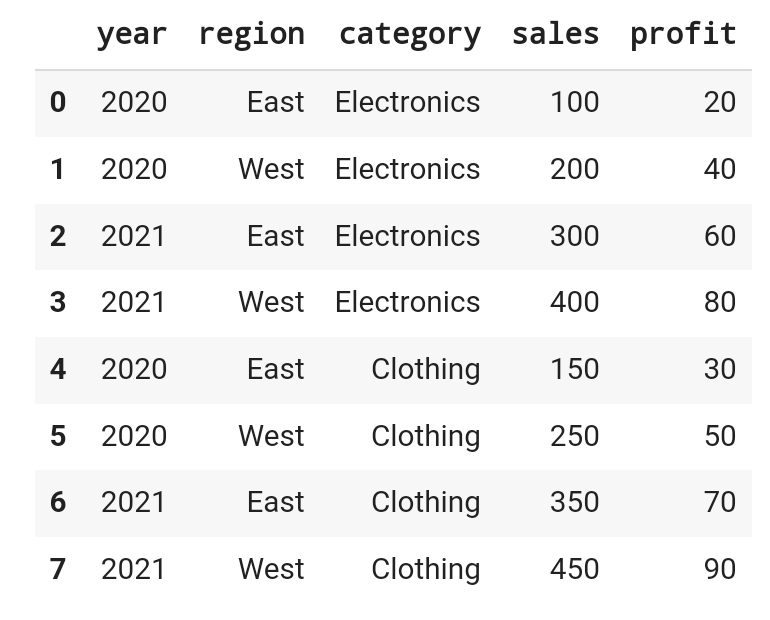
data.pivot_table(
index = 'region',
columns = 'year', # 시간이 지남에 따라 지역별로
values = 'sales',
aggfunc = 'sum' ) 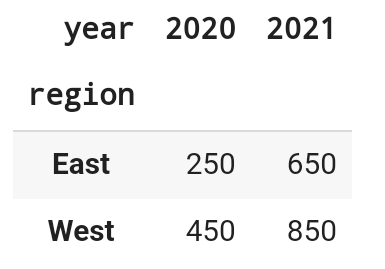
data.pivot_table(
index = 'region',
columns= 'category',
values = 'sales',
aggfunc = 'sum' )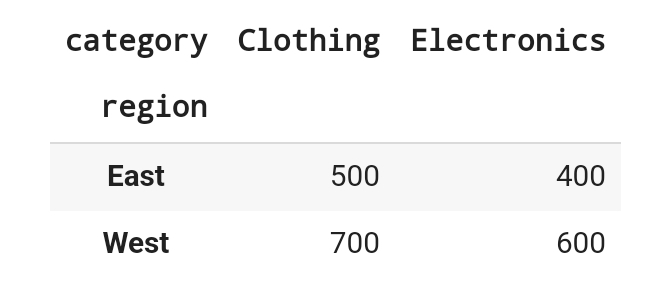
4. Exercise
- 판다스의 melt 함수를 사용해 'iris' 데이터셋을 long form으로 변환하라
- variable 열의 이름을 measure_type으로, value열의 이름을 measure_value로 변경
- iris_long으로 변경
- iris_long을 활용하여 species와 measure_type별 평균을 구하라
import pandas as pd
import seaborn as sns
# iris 데이터셋 로드
iris = sns.load_dataset('iris', cache=False)
# long form으로 변경
iris_long = iris.melt(
id_vars = 'species',
value_vars = ['sepal_length', 'sepal_width','petal_length', 'petal_width'],
var_name= 'measure_type',
value_name= 'measure_value' )
# iris_long을 활용하여 species와 measure_type별 평균
iris_long.pivot_table(
index = 'species',
columns = 'measure_type',
values= 'measure_value',
aggfunc = 'mean' )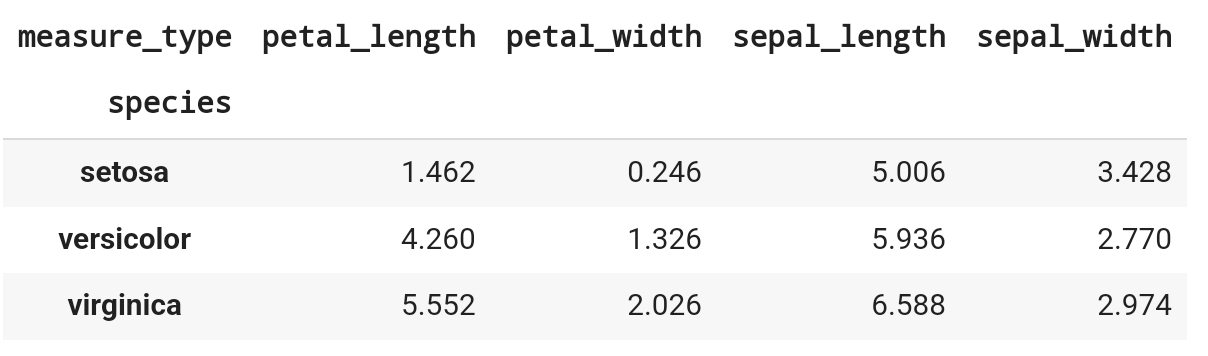

데이터 공부하는 예비 데이터 분석가, 김정민입니다.