1. df.astype()
df.astype(int, float, str, ...)데이터 타입을 변경해주는 데 사용
df.info()에서 보여주는 데이터 타입 별로 설명:
- object : 텍스트 또는 혼합된 데이터 타입. 주로 문자열 데이터에 사용됨
- int64 : 정수형 데이터
- float64 : 부동소수점 숫자
- bool : 부울 값(True 또는 False). 참/거짓 값을 나타냄
- datetime64 : 날짜 및 시간 데이터. 날짜와 시간 정보 처리에 사용됨
- category : 범주형 데이터. 제한된 수의 고유값들을 가지며 순서가 없는 그룹 또는 분류를 나타냄
import pandas as pd
data = {'A' : ['1', '2', '3'],
'B' : ['4.5', '5.6', '6.7'],
'C' : ['True', 'False', 'True']}
df = pd.DataFrame(data)
df.info()
# 숫자들이 ' ' 따옴표 사용으로 문자로 인식함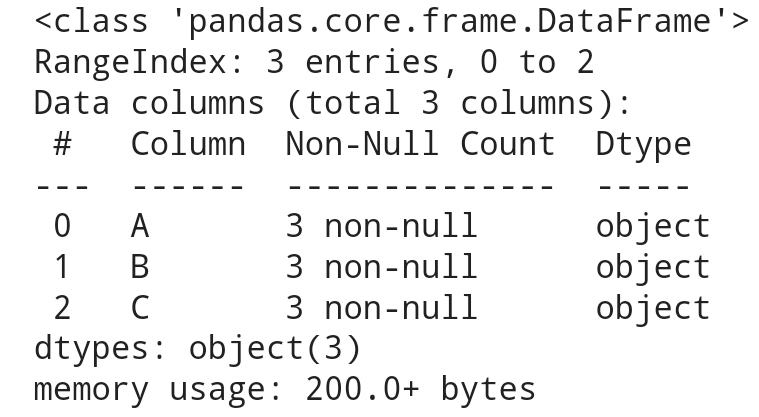
# astype으로 데이터 타입 변경해주기
df['A'] = df['A'].astype(int)
df['B'] = df['B'].astype(float)
df['C'] = dt['C'].astype(bool)
2. NA
- na :누락된 데이터를 나타내는 일반적인 용어
NaN : 부동 소수점 데이터셋에서 누락된 값
None : 객체 타입 (예:문자열) 데이터셋에서 '값이 없음'을 나타내는 값
# 예제 데이터 생성
import pandas as pd
import numpy as np
data = {'숫자열' : [1,2, None, 4, None],
'문자열' : ['사과', None, '바나나', '체리', '']}
df = pd.DataFrame(data)
df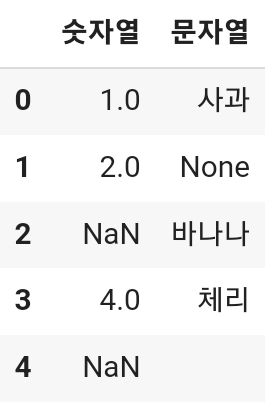
df.isna()
# 문자열 컬럼의 빈 스트링은 값이 있는 것으로 간주함
3. dropna()
dropna(subset=['col_1', 'col_2', ...], how='any/all')
- 누락된 데이터를 포함하는 행이 제거
- how 매개변수 :
how='any' 하나라도 None이 있는 행 제거 (기본값)
how='all' 모든 값이 None인 행만 제거
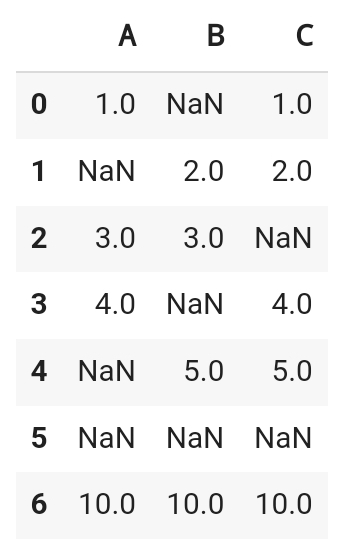
df.dropna() #하나라도 빈값이 있다면 그 행은 drop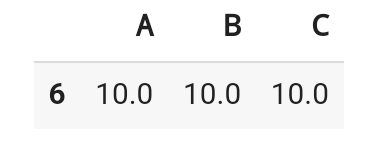
df.dropna(how='all')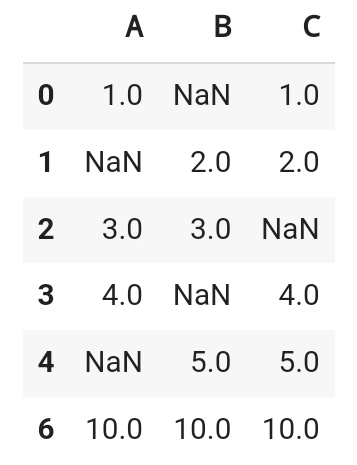
df.dropna(subset = ['A', 'B'], how='any')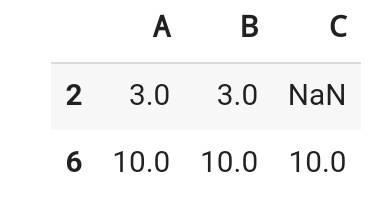
4. fillna()
df.fillna( {'col_1' : value1, 'col_2' : value2} , inplace =True )
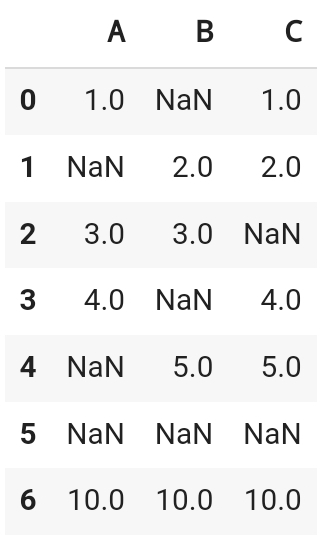
# 값을 채워주기
# 변수를 넣기
df.fillna( {
'A' : df.A.mean(),
'B' : df.B.sum(),
'C' : df.C.max() })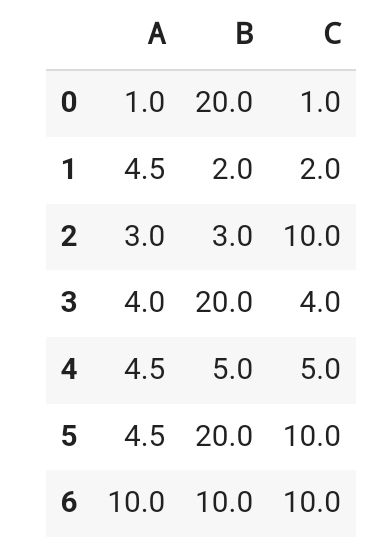
5. Exercise
데이터셋에는 'Name', 'Age', 'Salary'열이 있고, 각각의 열에는 누락된 값이 포함되어 있다.
1. Name열에서 누락된 값을 'Unknown'으로 채워라
2. Age 열에서 누락된 값을 'Age'열의 평균값으로 채워라
3. Salary열의 누락된 값을 포함하는 행 전체를 제거하라
4. 모든 열에서 누락된 값을 포함하는 행을 제거하고, 결과를 새로운 데이터 프레임으로 저장하라.
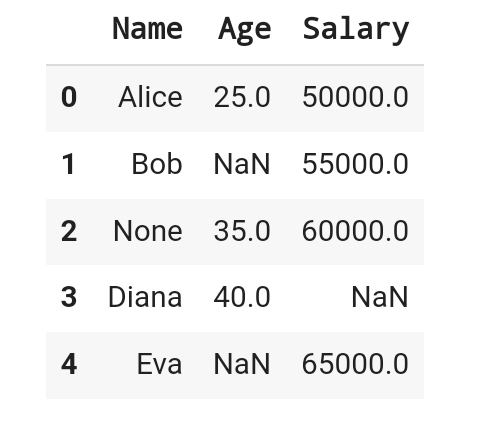
# 1,2,3
df.fillna({
'Name' :'Unknown',
'Age' : 'df.Age.mean()
}, inplace=True
df.dropna(subset= 'Salary', inplace=True)df_drop = df.dropna(how='any')
df_drop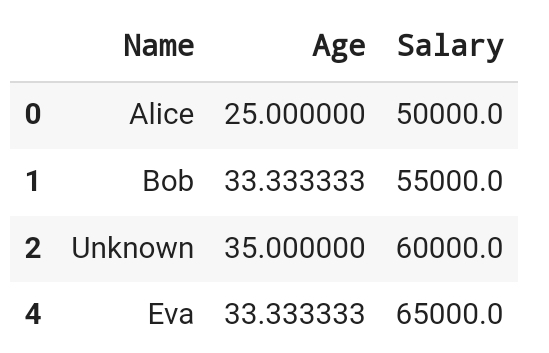

데이터 공부하는 예비 데이터 분석가, 김정민입니다.