EDA Level Test 04 ⭐️⭐️
| Week | Data Analysis | Difficulty | This Notebook |
|---|---|---|---|
| 1 | 서울시 인구 데이터 | ⭐️ | |
| 2 | 화장품 성분 데이터 | ⭐️⭐️⭐️ | |
| 3 | 올림픽 데이터 | ⭐️⭐️ | |
| 4 | 국가별 인터넷 사용률 데이터 | ⭐️⭐️ | 👈 |
| 5 | 전국 박물관/미술관 정보 표준 데이터 | ⭐️⭐️⭐️ | |
| 6 | 서울시 흡연율 통계 데이터 | ⭐️⭐️ | |
| 7 | 웹크롤링 | ⭐️ | |
| 8 | 서울시 지하철 호선별 역별 유/무임 승하차 인원 정보 데이터 | ⭐️⭐️ | |
| 9 | 서울시 교통사고 현황 (사고유형별) 통계 데이터 | ⭐️⭐️ | |
| 10 | 서울시 교통사고 현황 (사고유형별) 통계 + 서울시 차량통행속도 (구별/월별) 통계 + 서울시 인구밀도 (구별) 통계 | ⭐️⭐️⭐️ |
문제 소개 및 데이터 준비 단계
Data 원본 출처
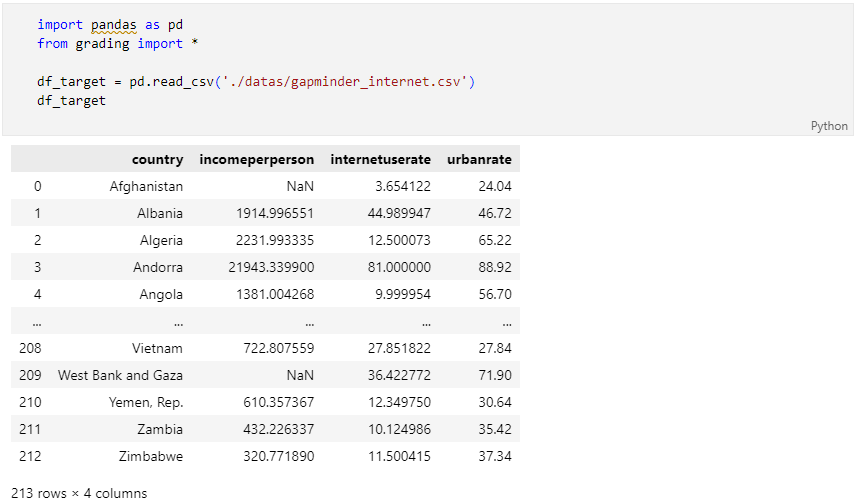
Target Data(CSV): Global Internet Usage(국가별 인터넷 사용률)
- Source: Kaggle
- DownLoad: archive.zip
Reference Data01(HTML Link): 국가별 인구(Population) Data
- Source: Wiki
Reference Data02(CSV): 국가별 ISO코드 / 지역 분류(Region) Data
- Source: Kaggle
- DownLoad: archive.zip
참고사항
- 위 3개의 Data들은 생성 시기가 다르므로 이 Test에서 도출되는 결과는 실제와 일치하지 않습니다.
- 문제에 hint가 있을 경우, 해당 hint를 이용하지 않으셔도 무방합니다.
- 해당 Test는 Wiki의 Online Data를 가져오는 내용을 포함하고 있습니다.
- 해당 내용이 변경될 경우 추후 공유될 정답과 다를 수 있습니다.
- 문제 제작시의 Data는 추후 공유될 정답과 함께 제공합니다. 해당 Data는 아래의 경로에 있습니다.
- 국가별 인구 Data
[DS]EDA Level Test_week 4/solution/datas/wiki_population.csv
- 국가별 인구 Data
- 해당 Test는 pycountry 라는 Library를 사용할 예정입니다.
- https://pypi.org/project/pycountry/#description
- https://github.com/flyingcircusio/pycountry
- 해당 Library가 없는 경우 아래 명령어를 사용하여 설치하시기 바랍니다.
pip install pycountry또는conda install -c conda-forge pycountry
문제 시작! 🏃🏻
1단계: Target Data 불러오기 & 전처리
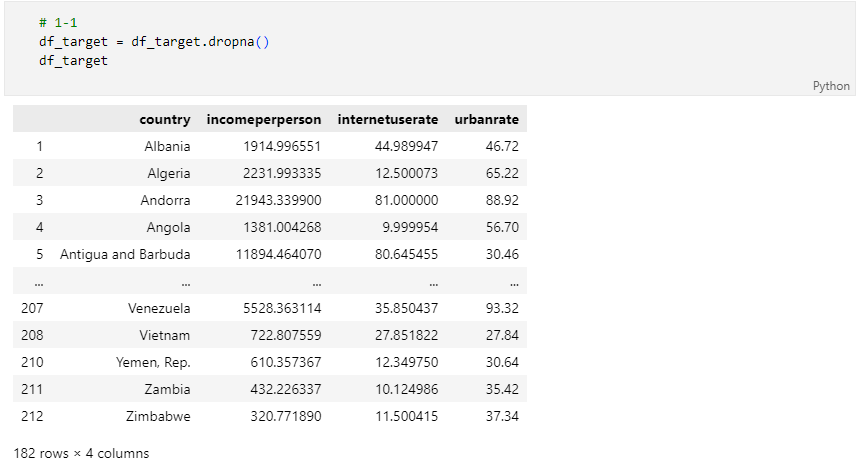
문제 1-1) Target Data 전처리 01 (5점)
- 위에서 읽은 DataFrame에서 Null값을 처리하고자 합니다. 아래 조건에 맞게 Null값을 처리하세요.
- 조건1: 'incomeperperson', 'internetuserate', 'urbanrate' Column(열)에 하나라도 Null값이 있다면 그 row(행)를 삭제(drop)하세요.
- 조건2: Index와 순서(order)는 변경하지 마세요.
- 완료 후 결과 dataframe 변수를 check_01_01 함수에 입력하여 채점하세요.
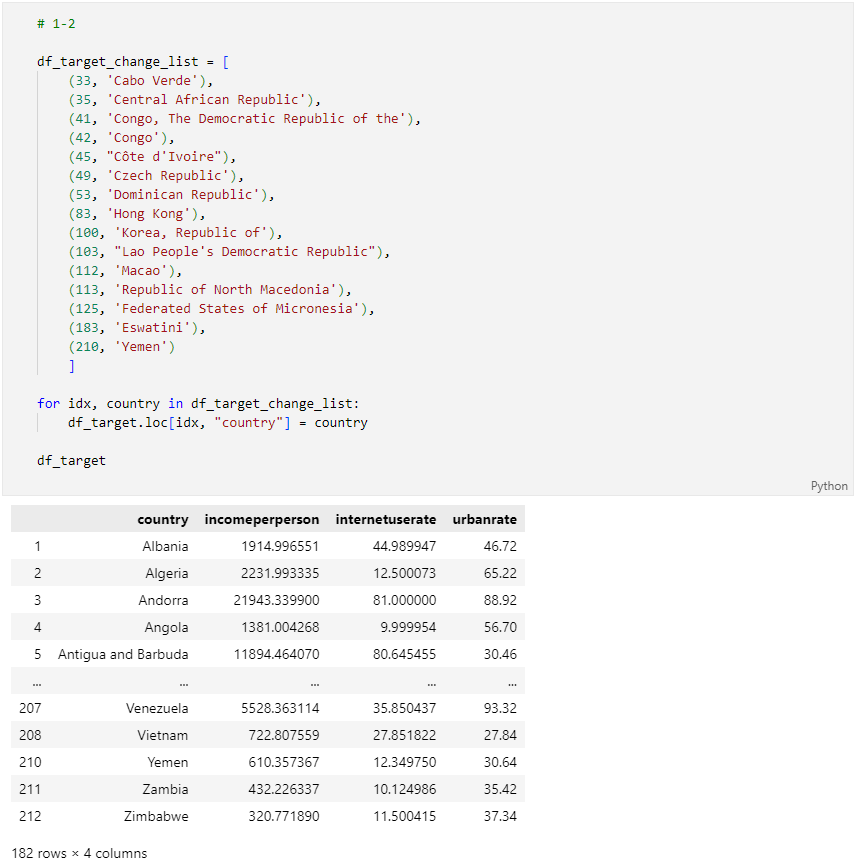
문제 1-2) Target Data 전처리 02 (5점)
- 1-1의 DataFrame(df_target)과 아래의 df_target_change_list를 이용하여 아래 조건에 맞게 국가명(컬럼명: 'country')을 변경하세요.
- 참고: 국가명을 변경하는 이유는 추후(문제 2-4) pycountry Library를 사용하여 국가코드(ex: 대한민국-KR)를 얻기 위함입니다.
- 아래 df_target_change_list는 변경 대상인 df_target의 index와 그에 맞는 국가명이 쌍(tuple)들을 값으로 가지고 있습니다.
- 조건1: df_target_change_list를 이용하여 df_target의 국가명을 변경하세요.
- 조건2: Index 또는 순서(order)는 변경하지 마세요.
- 완료 후 결과 dataframe 변수를 check_01_02 함수에 입력하여 채점하세요.
문제 1-3) Target Data 전처리 03 (10점)
- 1-2의 DataFrame(df_target)과 pycountry Library를 이용하여 아래 조건에 맞게 국가코드를 구하세요.
- 참고: pycountry.countries
- ISO 3166-2(전 세계 나라 및 부속 영토의 주요 구성 단위의 명칭에 고유 부호(코드)를 부여하는 국제 표준) 기준 국가별 코드를 얻을 수 있는 Python Library
- 국가명 표기 방식에 따라 잘못된 값 또는 값 검색이 안되는 경우가 많아 주의가 필요함
- 예시: 대한민국의 경우 'south korea', 'republic of korea', 'korea', 'korea, republic of' 등으로 표기되는데, 이 중 'korea, republic of' 로만 정확한 국가 코드를 얻을 수 있음
- 혼선을 줄이기 위하여 문제 1-2와 같이 변경할 국가명을 제공함
- 사용법(상세 사용법은 2.Datas의 참고사항 내 링크 참조)
- 국가 검색 방법
- 일반 검색: pycountry.countries.get(name=country_name) -> 하나의 결과값을 return
- fuzzy 검색: pycountry.countries.search_fuzzy(country_name) -> 하나 이상의 결과값을 list형태로 return
- 예시
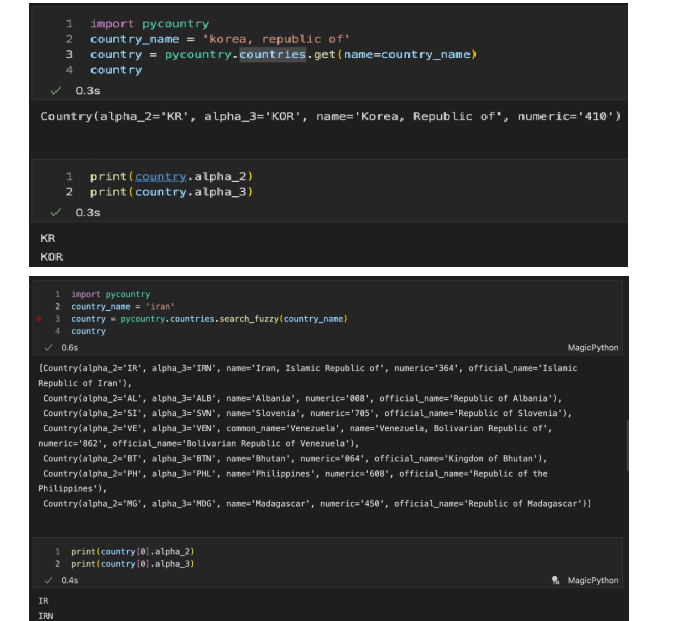
- 국가 검색 방법
- 조건1: df_target에 'code'컬럼을 추가하여 각 row(행)의 국가명에 맞는 2글자 국가코드(alpha_2)를 입력하세요.
- 조건2: 일반검색(pycountry.countries.get(name=country_name))을 우선 이용 해보고, 결과값이 안 나올 경우 fuzzy 검색(pycountry.countries.search_fuzzy(country_name))을 활용하여 검색하세요.
- 조건3: fuzzy 검색을 이용할 경우, 결과값 list의 첫번째 값(index=0)의 국가코드를 입력하세요.
- 조건4: Index 또는 순서(order)는 변경하지 마세요.
- hint: Python 예외처리(try-except)를 활용해 보세요.
- 참고: pycountry.countries
- 완료 후 결과 dataframe 변수를 check_01_03 함수에 입력하여 채점하세요.
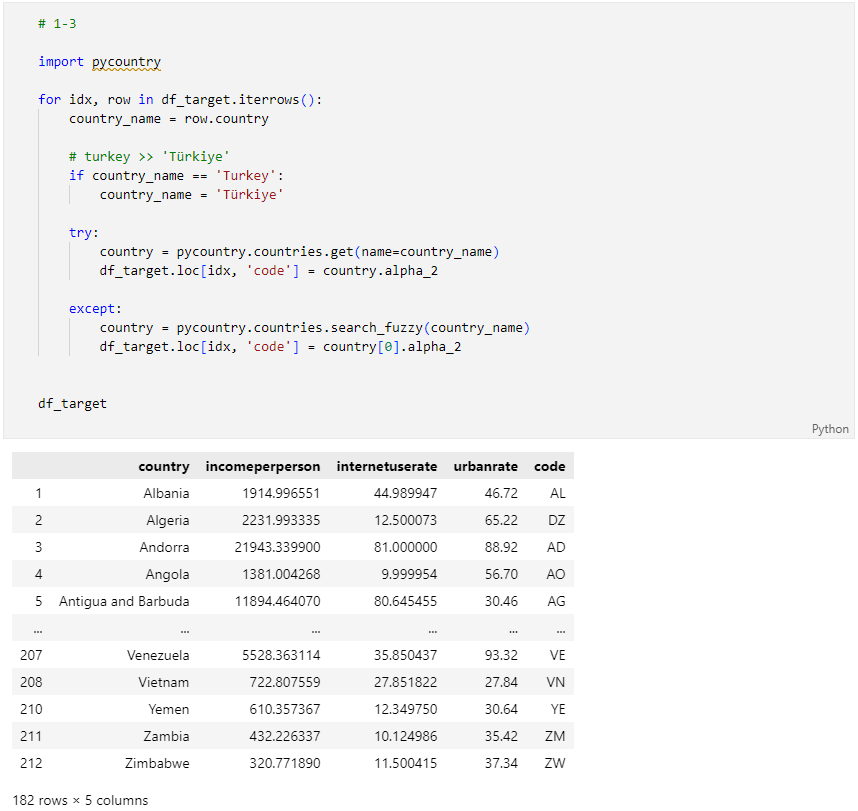
2단계: Reference Data01: 불러오기 & 전처리 & 합치기
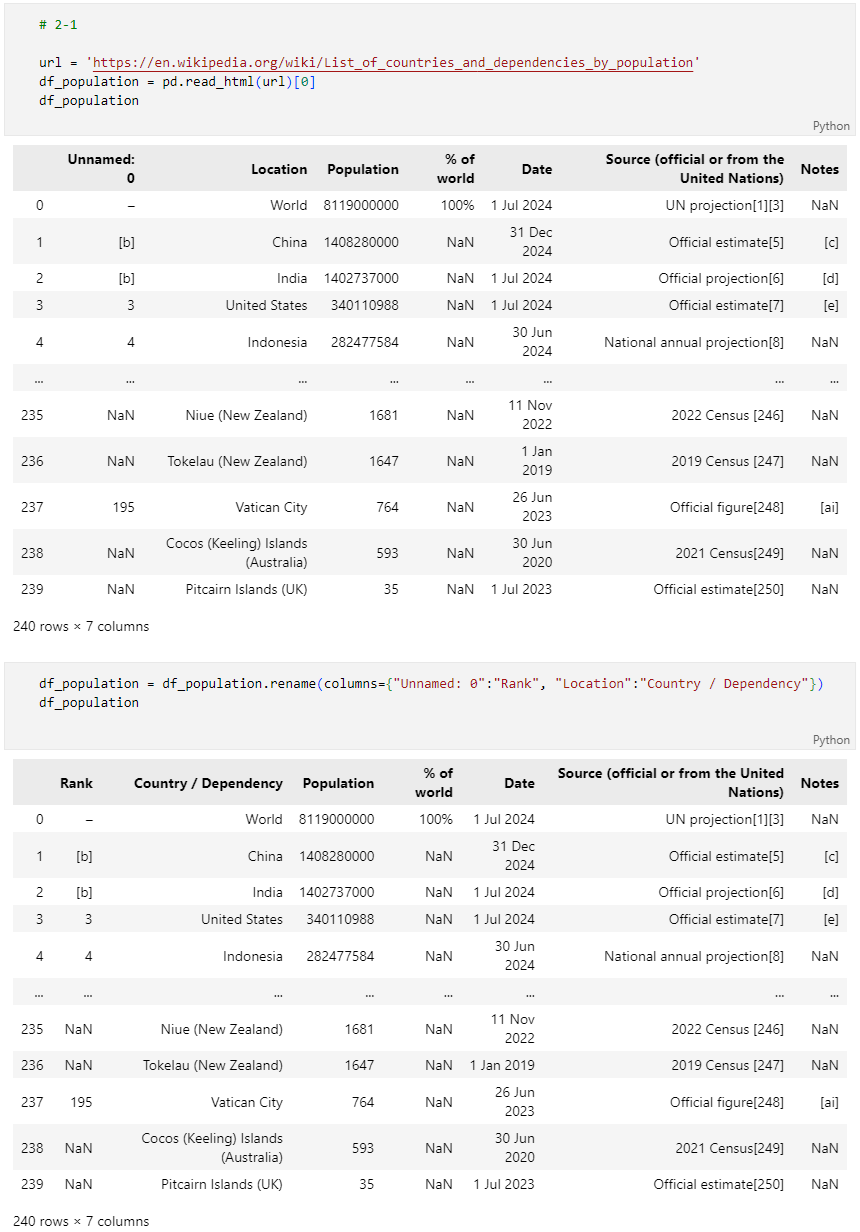
문제 2-1) Web Data 가져오기 (10점)
- 아래 제시된 Link에 있는 국가별 인구에 대한 Table을 아래 조건에 맞게 예시와 같이 Pandas DataFrame으로 불러오세요.
- Link: https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population
- 예시
- 조건: 해당 DataFrame의 변수명을 'df_population'으로 지정해주세요.
- hint: pandas의 기능 중에 웹페이지의 Table들을 읽어와 DataFrame으로 만들어주는 method가 있습니다.
- 완료 후 결과 dataframe 변수를 check_02_01 함수에 입력하여 채점하세요.
문제 2-2) Population Data 전처리 01 (5점)
- 2-1의 DataFrame(df_population)을 아래의 조건에 맞게 변경하세요.
- 조건1: Column(열) 중 'Country / Dependency', 'Population' 2개만 남기세요.
- 조건2: 컬럼명을 아래와 같이 변경하세요.
- 'Country / Dependency' -> 'country'
- 'Population' -> 'population'
- 조건3: 'country' Column(열)의 값이 'World'인 첫번째 인덱스(index=0)을 삭제하세요.
- 조건4: Index 또는 순서(order)는 변경하지 마세요.
- 완료 후 결과 dataframe 변수를 check_02_02 함수에 입력하여 채점하세요.
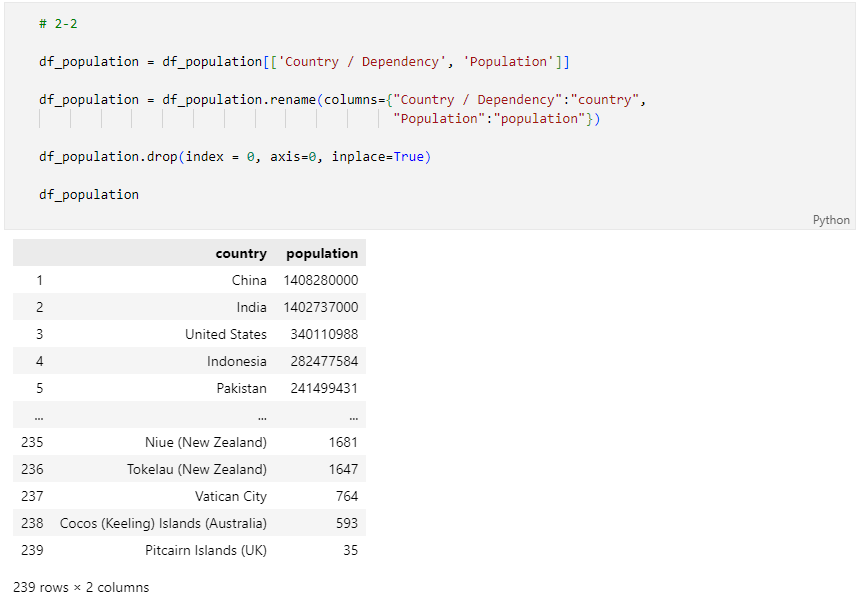
문제 2-3) Population Data 전처리 02 (5점)
- 2-2의 DataFrame(df_population)과 아래의 df_population_change_dict를 이용하여 아래 조건에 맞게 국가명(컬럼명: 'country')을 변경하세요.
- 참고: 국가명을 변경하는 이유는 추후 문제에서 1단계에서 만들었던 df_target과 합치기 위함입니다.
- 변경 국가는 1단계의 df_target에 있는 국가만 해당됩니다.
- 일부 국가명의 표현이 다르기 때문에 df_target을 기준으로 표기를 통일합니다.
- 아래 df_population_change_dict는 변경 대상인 df_population의 기존 국가명과 변경할 국가명이 key-value로 이루어져 있습니다.
- 조건1: df_population_change_dict를 이용하여 df_population의 국가명을 변경하세요.
- 조건2: Index 또는 순서(order)는 변경하지 마세요.
- 참고: 국가명을 변경하는 이유는 추후 문제에서 1단계에서 만들었던 df_target과 합치기 위함입니다.
- 완료 후 결과 dataframe 변수를 check_02_03 함수에 입력하여 채점하세요.
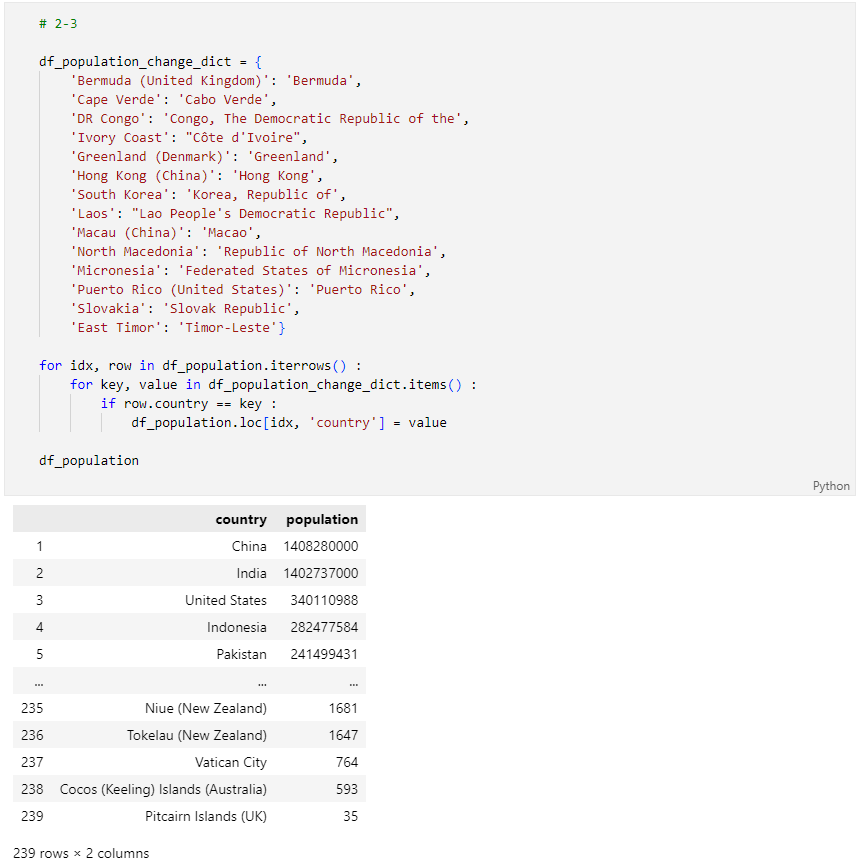
문제 2-4) Data 합치기(10점)
-
1단계의 DataFrame(df_target)과 2-3의 DataFrame(df_population)을 아래의 조건에 맞게 합치세요.
- df_target에 df_population의 Data를 추가하려 합니다.
- 조건1: df_target, df_population의 국가명('country' Column(열)의 value)이 같은 Data끼리 합쳐주세요.
- 조건2: 결합 방식은 교집합(겹치는 국가명이 있는 경우만 추출)으로 지정해 주세요.
- 조건3: Column(열)방향으로 DataFrame을 합쳐주세요.
- 조건4: 'code' Column(열)을 기준으로 오름차순으로 정렬해주세요.
- 조건5: index를 reset해주세요.
- 조건6: 결과 DataFrame의 Column은 6개('country', 'incomeperperson', 'internetuserate', 'urbanrate', 'code', 'population')이어야 합니다.
- 조건7: 결과 DataFrame의 변수는 'df' 로 지정해 주세요.
- hint1: 조건1 -> key='country' 또는 on='country'
- hint2: 조건2 -> join='inner' 또는 how='inner'(DataFrame 순서에 따라 'left', 'right'도 가능)
- df_target에 df_population의 Data를 추가하려 합니다.
-
완료 후 결과 dataframe 변수를 check_02_04 함수에 입력하여 채점하세요.
3단계: Reference Data02: 불러오기 & 전처리 & 합치기
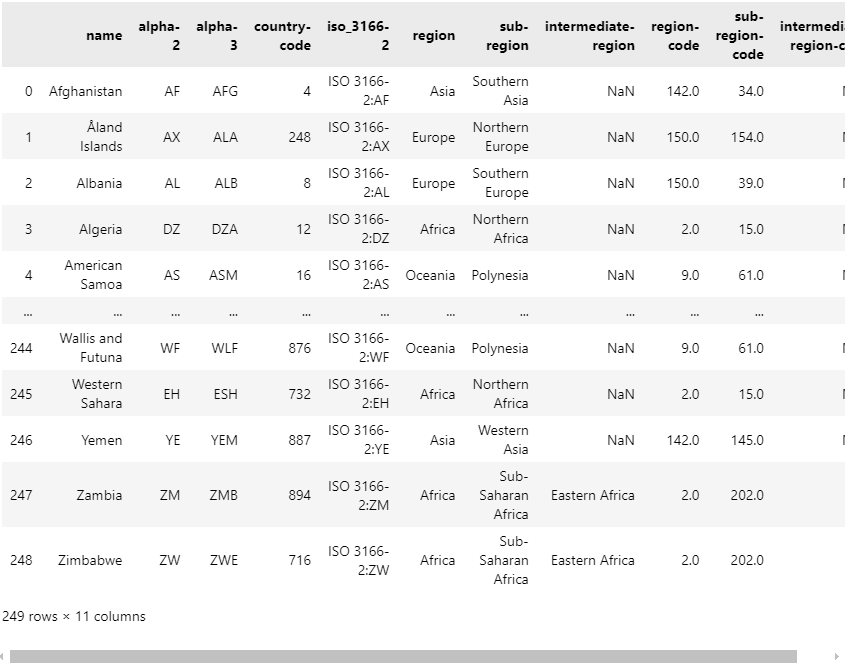
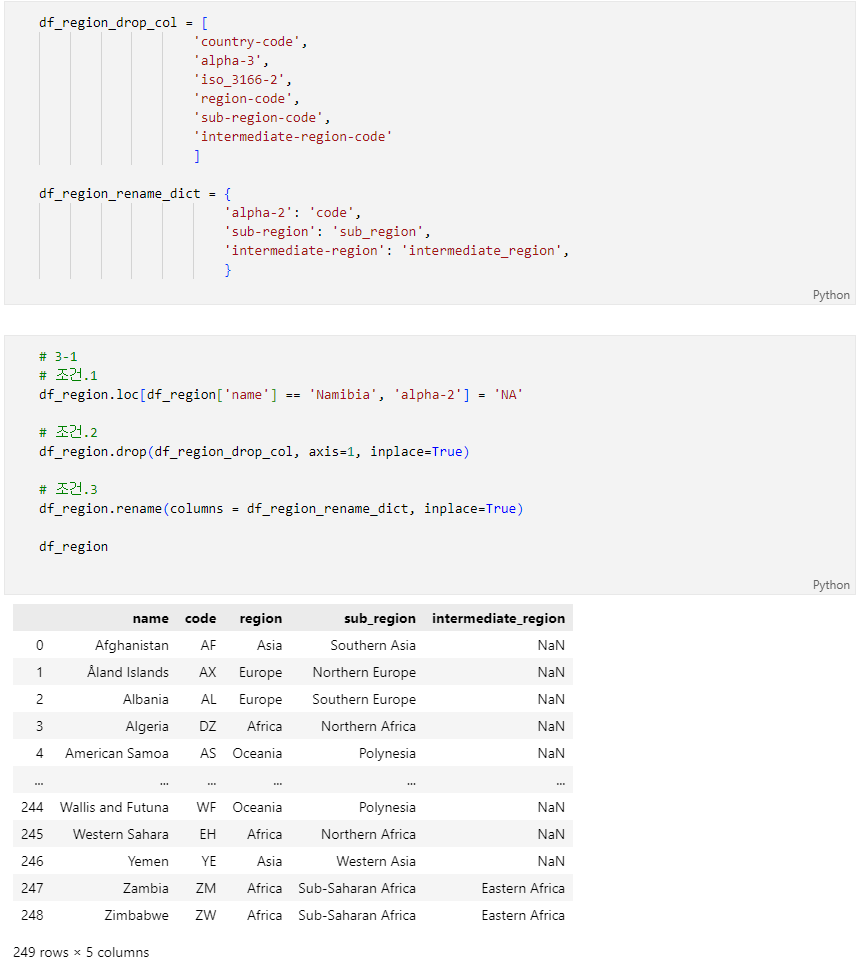
문제 3-1) Region Data 전처리 01 (10점)
- 위의 DataFrame(df_region)을 아래의 조건에 맞게 변경하세요.
- 조건1
- 특정 국가('Namibia')의 국가코드가 'NA'이기 때문에 위와 같이 DataFrame을 불러올경우 해당 국가코드가 NaN값으로 처리됩니다.
- 해당 국가의 국가코드를 'NA'로 변경하세요.(해당 값의 type이 string이어야 합니다.)
- 참고
- 아래 조건3에 따른 Column(열)명을 변경하기 전에는 'alpha-2', 변경 후에는 'code' Column(열)에 국가코드가 있습니다.
- 국가명 Column(열)명은 'name'입니다.
- 조건2
- 아래 df_region_drop_col은 Data 분석시 필요 없는 Column(열)입니다.
- df_region_drop_col을 참고하여 df_region의 Column(열)들을 삭제(drop)하세요.
- 조건3
- 아래 df_region_rename_dict는 기존 컬럼명 - 변경할 컬럼명이 key-value로 이루어져 있습니다.
- df_region_rename_dict를 참고하여 df_region의 Column(열)명을 변경하세요.
- 조건4
- Index 또는 순서(order)는 변경하지 마세요.
- 조건1
- 완료 후 결과 dataframe 변수를 check_03_02 함수에 입력하여 채점하세요.
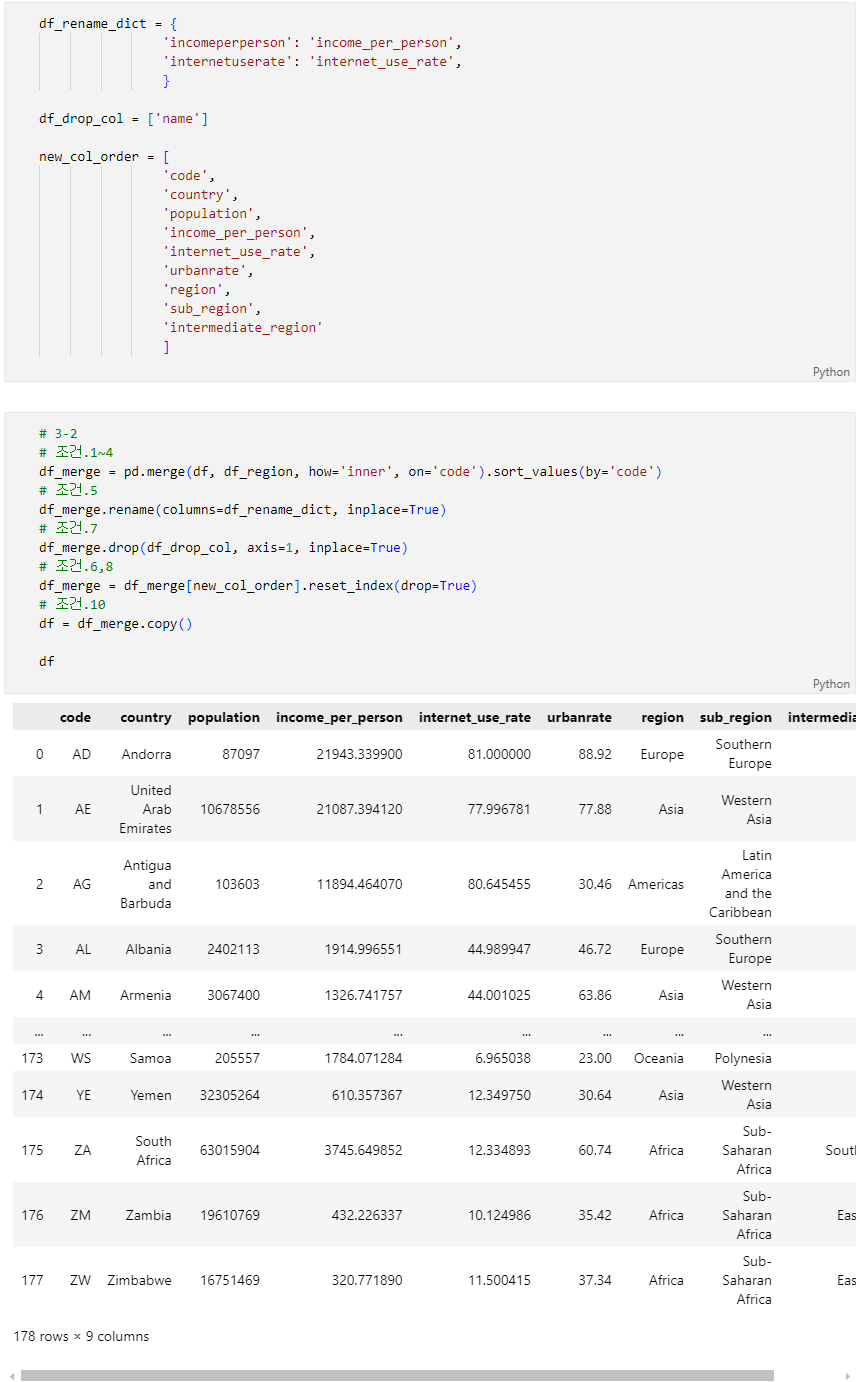
문제 3-2) Data 합치기(10점)
-
2단계의 DataFrame(df)과 3-1의 DataFrame(df_region)을 아래의 조건에 맞게 합치세요.
- df에 df_region의 Data를 추가하려 합니다.
- 조건1: df, df_region 국가코드('code' Column(열)의 value)가 같은 Data끼리 합쳐주세요.
- 조건2: 결합 방식은 교집합(겹치는 국가코드가 있는 경우만 추출)으로 지정해 주세요.
- 조건3: Column(열)방향으로 DataFrame을 합쳐주세요.
- 조건4: 'code' Column(열)을 기준으로 오름차순으로 정렬해주세요.
- 조건5
- 아래 df_rename_dict는 기존 컬럼명 - 변경할 컬럼명이 key-value로 이루어져 있습니다.
- df_rename_dict를 참고하여 df의 Column(열)명을 변경하세요.
- 조건6
- 아래 new_col_order는 변경하고자하는 Column(열)의 순서대로 Column(열)명을 값으로 가지고 있습니다.
- new_col_order를 참고하여 df의 Column(열)의 순서를 변경하세요.
- 조건7: 'name' Column(열)은 삭제(drop)해 주세요
- 조건8: index를 reset해주세요.
- 조건9: 결과 DataFrame의 Column은 6개('country', 'incomeperperson', 'internetuserate', 'urbanrate', 'code', 'population')이어야 합니다.
- 조건10: 결과 DataFrame의 변수는 'df' 로 지정해 주세요.
- hint1: 조건1 -> key='code' 또는 on='code'
- hint2: 조건2 -> join='inner' 또는 how='inner'(DataFrame 순서에 따라 'left', 'right'도 가능)
- df에 df_region의 Data를 추가하려 합니다.
-
완료 후 결과 dataframe 변수를 check_03_02 함수에 입력하여 채점하세요.
4단계: Data 분석하기(가중 평균 & 분산)
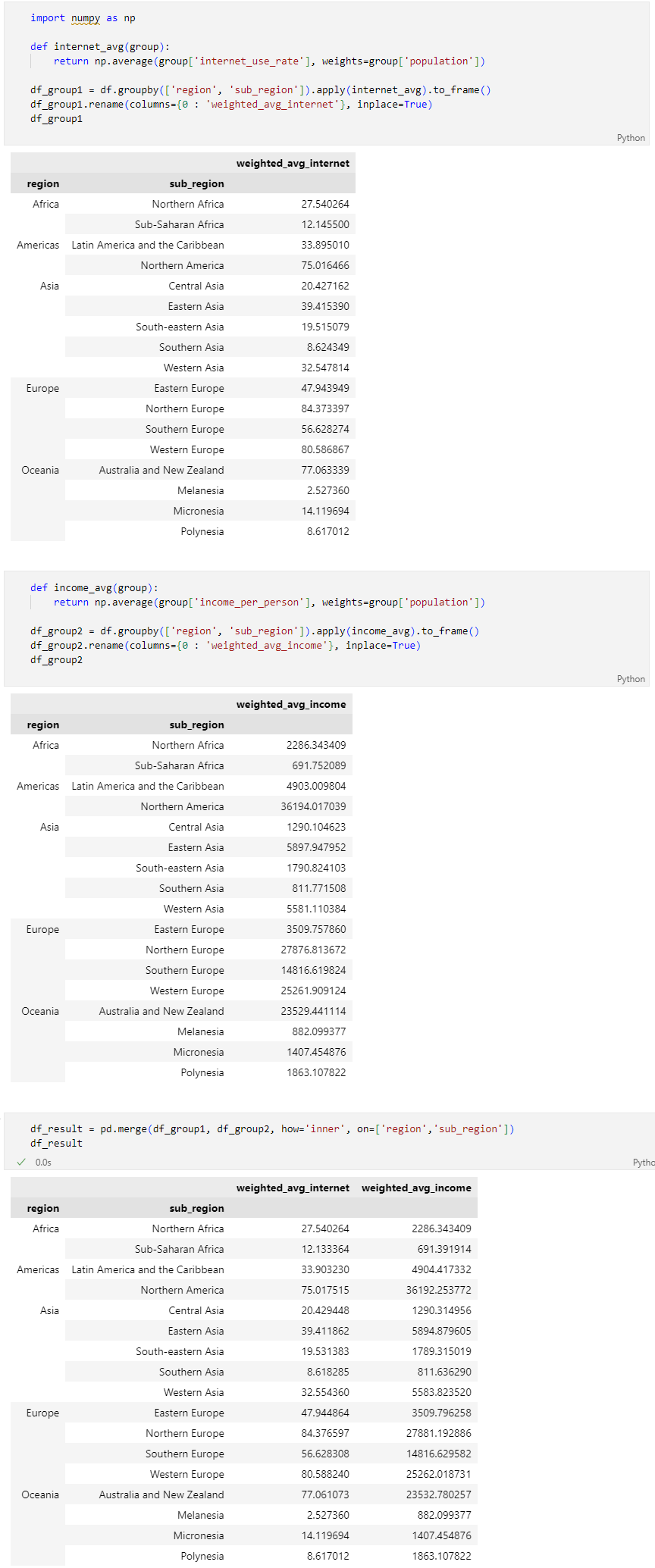
문제 4-1) 지역대륙별 가준 평균 구하기 (15점)
-
3단계 DataFrame(df)의 국가별 인터넷 사용률(internet_use_rate) 및 인당 소득(income_per_person)을 대륙(region) 또는 지역대륙(sub_region)별로 평균을 합산하여 보기 위해서는 단순 평균이 아닌 국가별 인구수(population)을 가중한 평균을 계산하여야 합니다.
-
3단계 DataFrame(df)을 이용하여 지역대륙(sub_region)별 조건에 맞게 가중평균을 구하세요.
-
참고
- 가중 평균: 자료의 평균을 구할 때 자료 값의 중요도나 영향 정도에 해당하는 가중치를 반영하여 구한 평균값

- 조건1: 가중치(weights)는 population Column(열)을 이용하세요.
- 조건2: 지역대륙(sub_region)의 인터넷 사용률(internet_use_rate) 및 인당 소득(income_per_person)을 아래 표와 같은 index, column 형태로 나타내주세요.
- index = ['region', 'sub_region']
- column = ['weighted_ave_internet', 'weighted_ave_income']
- 조건3: 결과 DataFrame의 변수는 'df_result' 로 지정해 주세요.
- hint1: pandas.DataFrame.groupby
- hint2: numpy.average
- 가중 평균: 자료의 평균을 구할 때 자료 값의 중요도나 영향 정도에 해당하는 가중치를 반영하여 구한 평균값
-
완료 후 결과 dataframe 변수를 check_04_01 함수에 입력하여 채점하세요.
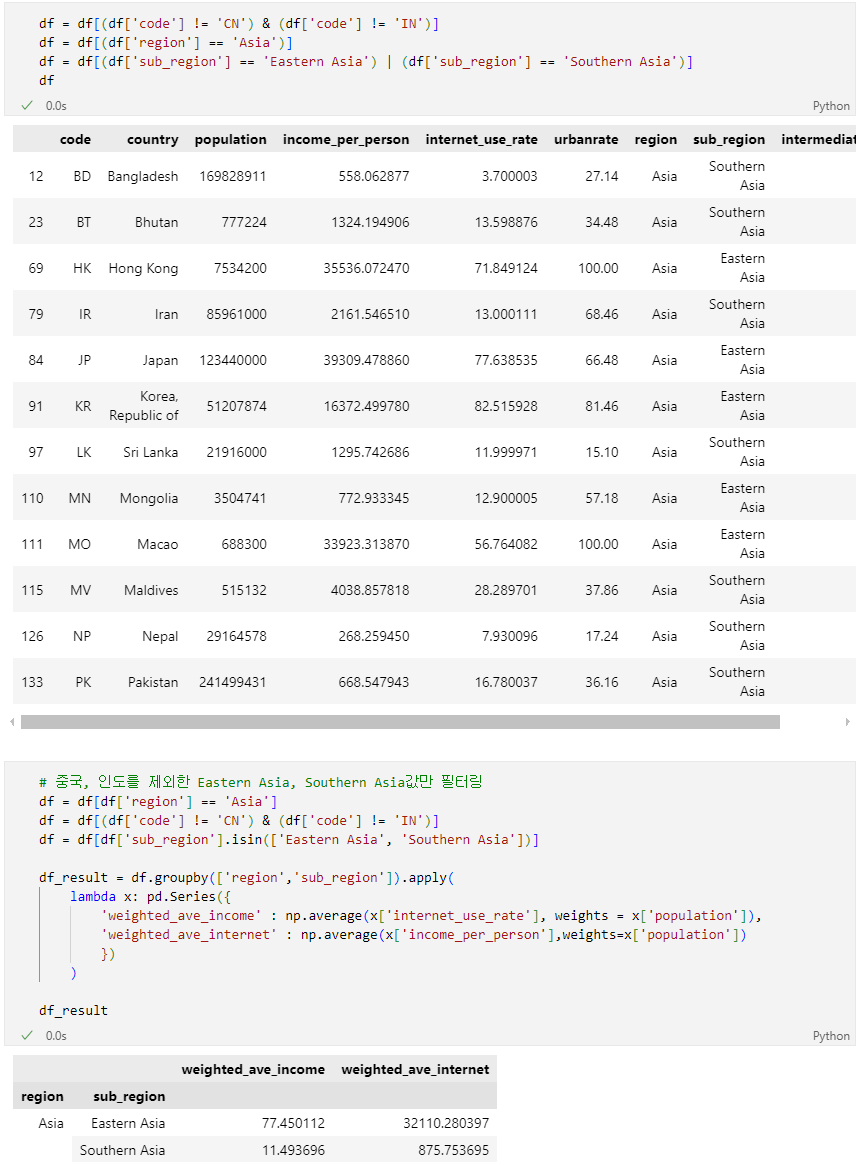
문제 4-2) 특정 조건의 가준 평균 구하기 (15점)
-
중국과 인도를 제외한 Eastern Asia, Southern Asia의 인터넷 사용률(internet_use_rate) 및 인당 소득(income_per_person)을 아래 조건에 맞게 구하세요.
-
참고: 4-1의 참고사항 참조
- 조건1: 가중치(weights)는 population Column(열)을 이용하세요.
- 조건2: 중국(국가코드(code): 'CN)과 인도(국가코드: 'IN')를 제외한 Asia(region) - Eastern Asia, Southern Asia (sub_region)의 인터넷 사용률(internet_use_rate) 및 인당 소득(income_per_person)을 아래 표와 같은 index, column 형태로 나타내주세요.
- index = ['region', 'sub_region']
- column = ['weighted_ave_internet', 'weighted_ave_income']
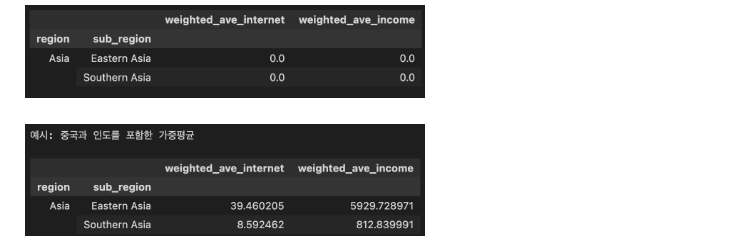
- 조건3: 결과 DataFrame의 변수는 'df_result' 로 지정해 주세요.
- hint1: pandas.DataFrame.groupby
- hint2: numpy.average
-
완료 후 결과 dataframe 변수를 check_04_02 함수에 입력하여 채점하세요.