
EDA Level Test 05 ⭐️⭐️
| Week | Data Analysis | Difficulty | This Notebook |
|---|---|---|---|
| 1 | 서울시 인구 데이터 | ⭐️ | |
| 2 | 화장품 성분 데이터 | ⭐️⭐️⭐️ | |
| 3 | 올림픽 데이터 | ⭐️⭐️ | |
| 4 | 국가별 인터넷 사용률 데이터 | ⭐️⭐️ | |
| 5 | 전국 박물관/미술관 정보 표준 데이터 | ⭐️⭐️⭐️ | 👈 |
| 6 | 서울시 흡연율 통계 데이터 | ⭐️⭐️ | |
| 7 | 웹크롤링 | ⭐️ | |
| 8 | 서울시 지하철 호선별 역별 유/무임 승하차 인원 정보 데이터 | ⭐️⭐️ | |
| 9 | 서울시 교통사고 현황 (사고유형별) 통계 데이터 | ⭐️⭐️ | |
| 10 | 서울시 교통사고 현황 (사고유형별) 통계 + 서울시 차량통행속도 (구별/월별) 통계 + 서울시 인구밀도 (구별) 통계 | ⭐️⭐️⭐️ |
문제 소개 및 데이터 준비 단계
Target Data(Json): 전국박물관미술관정보표준데이터
- Source: 공공데이터포털
- DownLoad: 전국박물관미술관정보표준데이터.json
참고사항
- 공공데이터포털에서 해당 데이터는 다양한 Format(xls, xml, json, rdf, csv)으로 제공합니다.
- 다양한 Data Format 사용을 하고자 해당 Test에서는 일부러 json format의 데이터를 사용할 예정입니다.
- json 상세 설명: https://www.json.org/json-ko.html
- 문제에 hint가 있을 경우, 해당 hint를 이용하지 않으셔도 무방합니다.
문제 시작! 🏃🏻
1단계: Json Data로 DataFrame으로 만들기
문제 1-1) Json Data로 Pandas DataFrame 만들기 (10점)
-
위에서 읽은 json_data는 아래와 같이 구성되어있습니다. 이를 참고하여 pandas dataframe으로 불러오세요.
- json_data
- json_data['fields']: List. 각 variable은 하나의 Column(열)을 의미하며, {id: Column(열)명}의 형식으로 구성 되어있습니다.
- json_data['records']: List. 각 variable은 하나의 Row(행)을 의미하며, {Column(열)명: data}의 형식으로 구성 되어있습니다.
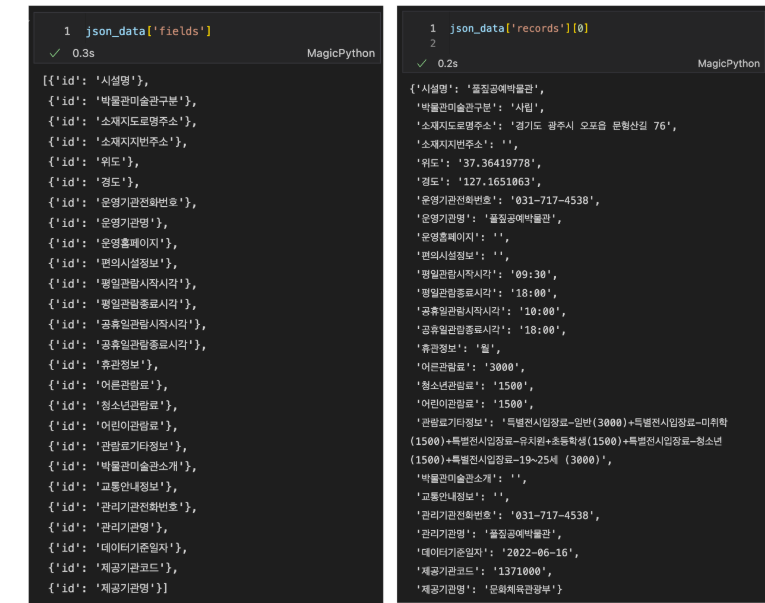
- 조건1: 위의 내용을 참고하여 'json_data'를 이용하여 Pandas DataFrame을 만드세요
- 조건2: json data의 Index와 Column(열)의 순서(order)는 변경하지 마세요.
- 앞에서부터 순차적으로 차례로 읽어 그대로 DataFrame으로 만드세요.
- 조건3: 'df_target' 변수에 결과 DataFrame을 할당하세요.
- hint: pandas의 read_json method로는 읽어지지 않습니다.
- 공공데이터포털에서 json data를 만드는 형식이 read_json과 matching되지 않아 Error가 발생합니다.
- json_data
-
완료 후 결과 DataFrame 변수(df_target)를 check_01_01 함수에 입력하여 채점하세요.

2단계: DataFrame 전처리 01 - 기초
문제 2-1) 기초 전처리 01 (5점)
- 1단계의 DataFrame(df_target)을 아래의 조건에 맞게 변경하세요.
- 해당 json_data의 null값은 ""로 구성되어 df_target.info() 또는 df_target.isna() 등을 이용하여 null값을 확인할 경우 null값이 없다고 나오게 됩니다. 이에 이 Data를 제대로 확인하기 위해서 "" 대신에 Null값을 넣으려 합니다.
- 조건1: ""(또는 '')는 띄어쓰기 없이 쌍따옴표(혹은 따옴표)로만 구성됩니다.
- 조건2: ""(또는 '')를 null값(None)으로 바꾸세요.
- 조건3: Index 또는 순서(order)는 변경하지 마세요.
- 조건4: 'df_target' 변수에 결과 DataFrame을 할당하세요.
- 완료 후 결과 dataframe 변수(df_target)를 check_02_01 함수에 입력하여 채점하세요.

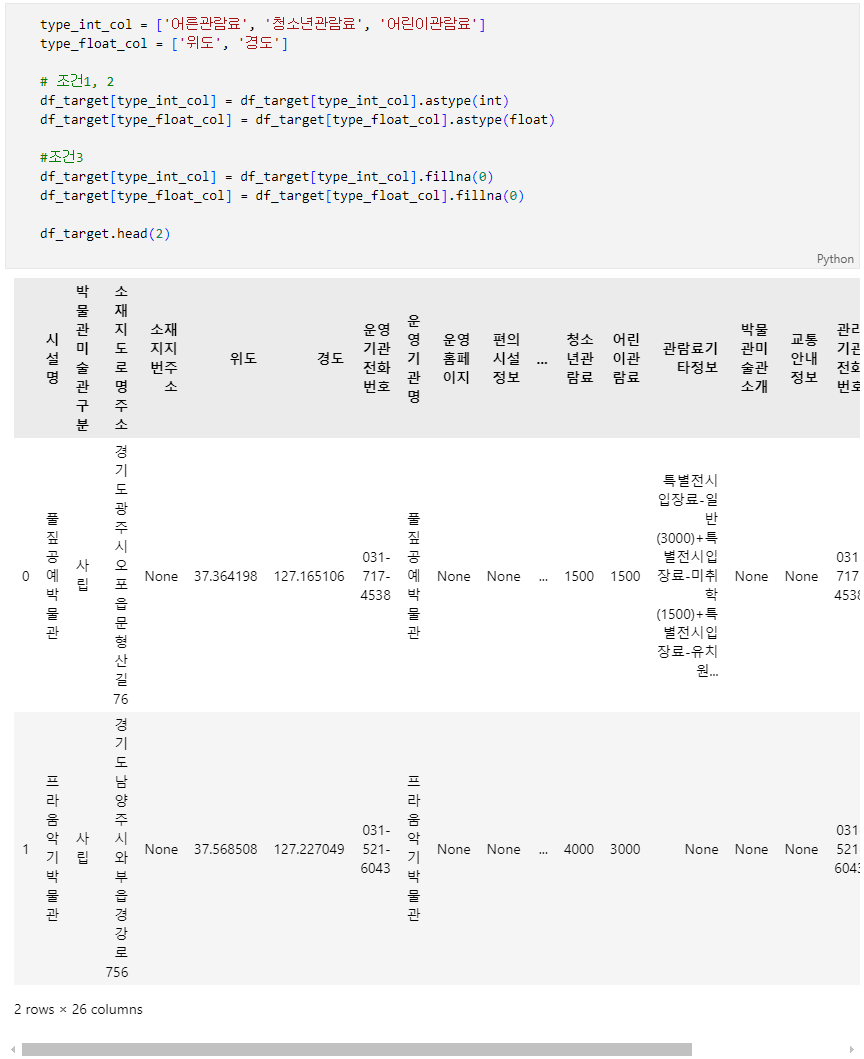
문제 2-2) 기초 전처리 02 (5점)
- 2-1의 DataFrame(df_target)을 아래의 조건에 맞게 변경하세요.
- json Data를 Pandas DataFrame으로 만들면서 수치형 데이터들이 string으로 인식되었습니다. 이를 변경하려고 합니다.
- 조건1: 아래 type_int_col의 Column(열) Data를 정수(int)형 Data로 변경하세요.
- 조건2: 아래 type_float_col의 Column(열) Data를 실수(float)형 Data로 변경하세요.
- 조건3: 변경할 Data에 Null값이 있다면, 0으로 채우세요.
- 조건4: Index 또는 순서(order)는 변경하지 마세요.
- 조건5: 'df_target' 변수에 결과 DataFrame을 할당하세요.
- 완료 후 결과 dataframe 변수(df_target)를 check_02_02 함수에 입력하여 채점하세요.
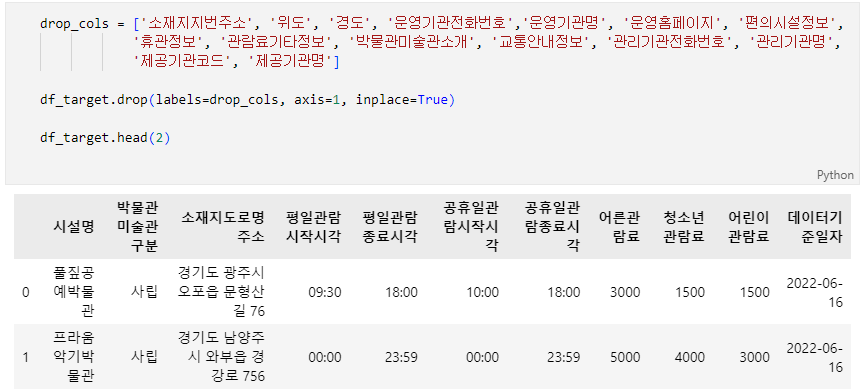
문제 2-3) 기초 전처리 03 (5점)
- 2-2의 DataFrame(df_target)을 아래의 조건에 맞게 변경하세요.
- 분석과 상관 없는 Column(열)의 Data들을 삭제하여 Data의 가독성을 높이고자 합니다.
- 조건1: 아래 drop_col의 Column(열) Data를 삭제하세요.
- 조건2: Index 또는 순서(order)는 변경하지 마세요.
- 조건3: 'df_target' 변수에 결과 DataFrame을 할당하세요.
- 완료 후 결과 dataframe 변수(df_target)를 check_02_03 함수에 입력하여 채점하세요.
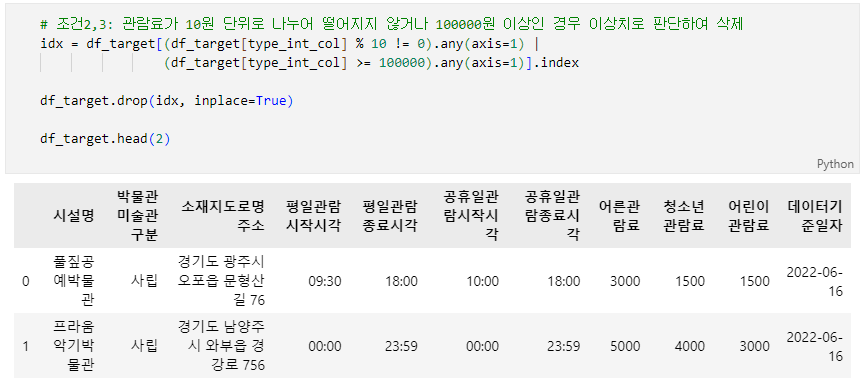
문제 2-4) 기초 전처리 04 (5점)
- 2-3의 DataFrame(df_target)을 아래의 조건에 맞게 변경하세요.
- 어른, 청소년, 어린이 관람료가 이상한 경우, 해당 row(행) data 자체가 이상하다고 판단하여 삭제하고자 합니다.
- 조건1: 관람료와 관련된 Column(열)은 위에서 정의한 type_int_col 입니다.
- 조건2: 관람료가 10원 단위로 나누어 떨어지지 않는 경우 이상치로 판단합니다. 해당 row(행)를 삭제하세요.
- 조건3: 관람료가 100000원(십만원) 이상인 경우 이상치로 판단합니다. 해당 row(행)를 삭제하세요.
- 조건4: Index 또는 순서(order)는 변경하지 마세요.
- 조건5: 'df_target' 변수에 결과 DataFrame을 할당하세요.
- 완료 후 결과 dataframe 변수(df_target)를 check_02_04 함수에 입력하여 채점하세요.
3단계: DataFrame 전처리 02 - 심화
문제 3-1) 심화 전처리 01 (10점)
-
2단계의 DataFrame(df_target)을 아래의 조건에 맞게 변경하세요.
- 휴관중이거나 중복된 박물관/미술관의 data를 삭제하고자 합니다.
- 아래의 조건 이외에도 중복되는 data들이 있으나, 해당 Test에서는 아래 조건에 따른 중복 data만 삭제하여 진행합니다.
- 조건1: 시설명 Column(열) data에 '휴관'이라는 글자가 들어있으면 해당 row(행)은 삭제합니다.
- 조건2: 시설명 Column(열) data가 중복되는 경우 해당 row(행)의 '데이터기준일자'가 최신인 data를 남기고 최신이 아닌 row(행)은 삭제합니다.
- 만약, 시설명 Column(행)의 data가 중복되면서 가장 최신인 data가 두 개 이상인 경우, Index가 가장 낮은(예시: 495, 674 중 495) Index를 남기고, 높은 Index(예시: 495, 674 중 674)의 row(행) data를 삭제하세요.(낮은 인덱스가 더 최근 데이터라고 가정)
- 예시: 아래 예시의 경우 데이터기준일자가 최신인 0번 index의 row(행)은 남기고 1338번 index의 row(행)은 삭제합니다.

- 조건3: 시설명 Column(열) data의 중복 여부는 시설명 Column(열) data의 띄어쓰기를 삭제한 값이 일치할 경우 중복된 박물관/미술관으로 판단합니다.
- 예시: 아래 예시의 경우 시설명 Column(열) data의 띄어쓰기를 삭제할 경우 시설명 Column(열) data가 동일합니다. 이에 데이터기준일자가 최신인 6번 index의 row(행)은 남기고 1909번 index의 row(행)은 삭제합니다.

- 조건4: Index 또는 순서(order)는 변경하지 마세요.
- 문제를 풀기위해 순서를 변경하였다면, 다시 Index 순서로 정렬하세요
- 조건5: 'df_target' 변수에 결과 DataFrame을 할당하세요.
- hint1: '데이터기준일자' Column(열)의 Data는 현재 string입니다. 대소비교가 가능한지 확인해보세요.
- hint2: 조건2 관련하여, '시설명'과 '데이터기준일자'가 같은 data들이 존재합니다. Index를 확인하세요.
- '데이터기준일자' 기준으로 정렬시 주의하세요.
- 휴관중이거나 중복된 박물관/미술관의 data를 삭제하고자 합니다.
-
완료 후 결과 dataframe 변수(df_target)를 check_03_01 함수에 입력하여 채점하세요.
문제 3-2) 심화 전처리 02 (10점)
-
3-1의 DataFrame(df_target)을 아래의 조건에 맞게 변경하세요.
- 평일과 공휴일에 박물관/미술관이 하루 중 몇시간이나 열려있는지를 알려주는 '관람가능시간'을 구하려고 합니다.
- 조건1: 평일의 관람가능시간은 '평일관람시작시각'부터 '평일관람종료시각'까지 입니다. '평일관람가능시간' Column(열)을 만들어 평일의 관람가능시간을 입력하세요.
- 조건2: 공휴일의 관람가능시간은 '공휴일관람시작시각'부터 '공휴일관람종료시각'까지 입니다. '공휴일관람가능시간' Column(열)을 만들어 공휴일의 관람가능시간을 입력하세요.
- 조건3: '평일관람가능시간'과 '공휴일관람가능시간'은 시간(hour) 단위 실수(float)로 표기합니다.
- 관람가능시간이 8시간 30분인경우 8.5로 표기합니다.
- 관람가능시간이 23시간을 초과하는 경우 24시간으로 표기합니다.
- 평일 또는 공휴일의 관람시작시각과 관람종료시각이 모두 00:00(또는 0:00)인 경우 휴일로 판단하며, 관람가능시간은 0으로 입력합니다.
- 관람가능시간이 6시간 40분과 같이 무환소수(6.6666666666666......6666666667)로 표기될 경우 소숫점 셋째 자리에서 반올림하여 소숫점 둘째 자리까지 표기합니다.

- 조건4: Index 또는 순서(order)는 변경하지 마세요.
- 조건5: 'df_target' 변수에 결과 DataFrame을 할당하세요.
- hint: 각 관람시작시각/관람종료시각의 Data Type은 string 입니다.
-
완료 후 결과 dataframe 변수(df_target)를 check_03_02 함수에 입력하여 채점하세요.

문제 3-3) 심화 전처리 03 (10점)
-
3-2의 DataFrame(df_target)을 아래의 조건에 맞게 변경하세요.
- '소재지도로명주소' Column(열)의 Data를 가공하여 광역자치단체-기초자치단체(행정시)-상세 주소로 구분하려고 합니다.
- 조건1: '소재재도로명주소' Column(열) data의 첫번째 단어는 언제나 광역자치단체명을 의미합니다. '광역' Column(열)을 만들어 해당 row(행) data의 광역자치단체명을 입력하세요.
- '세종특별시'는 현재 '세종특별자차시'로 명칭이 변경되었습니다. 이를 반영해주세요.
- 조건2: '소재재도로명주소' Column(열) data의 두번째 단어는 대부분 기초자치단체명을 의미합니다. '기초' Column(열)을 만들어 해당 row(행) data의 기초자치단체명을 입력하세요.
- '제주특별자치도'의 경우 기초자치단체가 없으나, 행정시('제주시', '서귀포시')가 '소재재도로명주소' Column(열) data의 두번째 단어에 위치합니다. 행정시를 '기초' Column(열)에 입력하세요.
- '세종특별자치시'의 경우 기초자치단체가 없습니다. '세종특별자치시'의 경우 '기초' Column(열)에는 Null값(None)을 입력해주세요.
- 조건3: '소재재도로명주소' Column(열) data에서 광역/기초자치단체(행정시포함)에 포함되지 않은 데이터는 '상세' Column(열)을 만들어 입력하세요.

- 조건4: '소재지도로명주소', '광역', '기초', '상세 Column(행)의 data는 해당 data의 앞-뒤로 띄어쓰기 등 공백이 없어야 합니다.
- 조건5: Index 또는 순서(order)는 변경하지 마세요.
- 조건6: 'df_target' 변수에 결과 DataFrame을 할당하세요.
-
완료 후 결과 dataframe 변수(df_target)를 check_03_03 함수에 입력하여 채점하세요.

4단계: 원하는 정보 얻기
문제 4-1) 원하는 정보 얻기 01 (10점)
-
3단계의 DataFrame(df_target)을 이용하여 아래의 조건에 맞는 정보를 구하세요.
- 광역자치단체별 박물관/미술관의 총 수를 확인하고자 합니다.
- 조건1: df_target의 '광역' Column(열)에 있는 광역자치단체 data를 이용하여 광역자치단체별 박물관/미술관의 총 수를 나타내주세요.
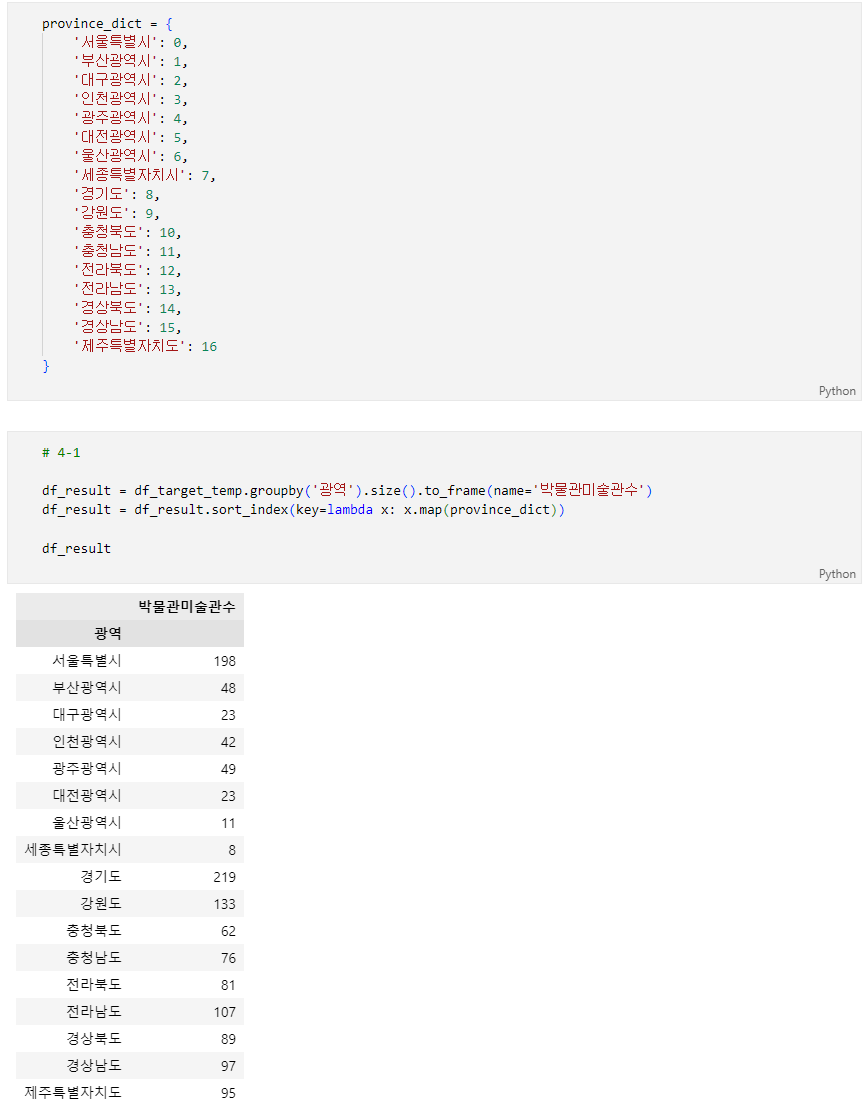
- 조건2: 결과 DataFrame의 Index는 광역자치단체입니다. 광역자치단체의 우선순위는 아래 province_dict의 value(값)으로 제공합니다. Index의 순서를 광역자치단체의 우선순위에 따라 나열해주세요.
- 출처: 행정안전부
- 조건3: 결과 DataFrame의 박물관/미술관의 총 수를 나타내는 Column(열)의 이름은 '박물관미술관수' 입니다.
- 조건4: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
완료 후 결과 dataframe 변수(df_result)를 check_04_01 함수에 입력하여 채점하세요.
문제 4-2) 원하는 정보 얻기 02 (10점)
-
3단계의 DataFrame(df_target)을 이용하여 아래의 조건에 맞는 정보를 구하세요.
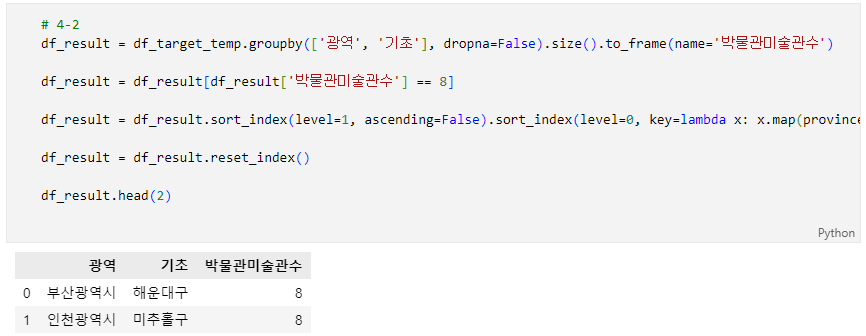
- 광역자치단체-기초자치단체(행정시)의 박물관/미술관의 총 수가 8개인 광역-기초자치단체(행정시)를 확인하고자 합니다.
- 조건1: df_target의 '광역'과 '기초' Column(열)에 있는 광역자치단체/기초자치단체(행정시) data를 이용하여 광역자치단체-기초자치단체(행정시)별 박물관/미술관의 총 수가 8개인 곳을 찾아주세요.
- 조건2: 결과 DataFrame의 '광역' Column(열)에 광역자치단체를, '기초' Column(열)에 기초자치단체(행정시)를 입력해주세요.
- 조건3: '광역' Column(열)은 4-1문제와 같이 광역자치단체의 우선순위에 따라 나열해주세요.
- 4-1의 province_dict 참고
- 조건4: 같은 광역자치단체가 있다면, '기초' Column(열)의 data는 가나다 순의 역순으로 나열해주세요.
- 조건5: 결과 DataFrame의 박물관/미술관의 총 수를 나타내는 Column(열)의 이름은 '박물관미술관수' 입니다.

- 조건6: Index는 숫자(정수) 오름차순으로 설정해주세요.
- 조건7: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
완료 후 결과 dataframe 변수(df_result)를 check_04_02 함수에 입력하여 채점하세요.
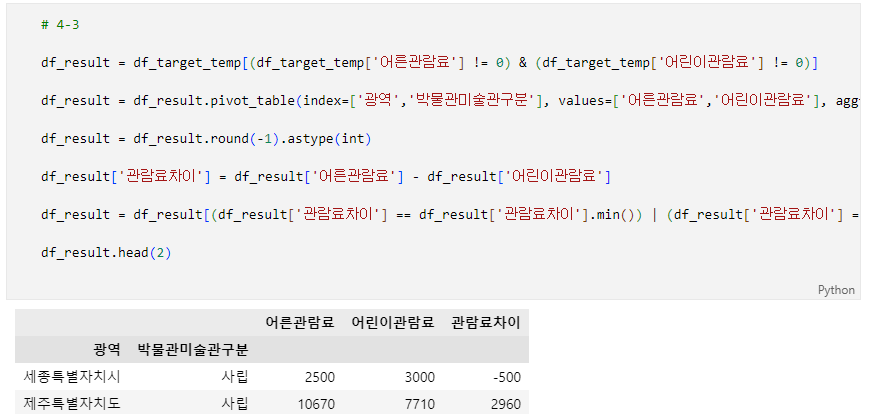
문제 4-3) 원하는 정보 얻기 03 (10점)
-
3단계의 DataFrame(df_target)을 이용하여 아래의 조건에 맞는 정보를 구하세요.
- 광역자치단체-박물관미술관구분(사립, 국립, 공립, 대학)의 평균 관람료 차이를 알아보고자 합니다.
- 조건1: df_target의 '광역'과 '박물관미술관구분' Column(열)에 있는 광역자치단체/박물관미술관구분 data를 이용하여 광역자치단체-박물관미술관구분별 평균 어른관람료-평균 어린이관람료 간 차이가 가장 크고 작은 곳을 찾아주세요.
- 단, 어른관람료 또는 어린이관람료가 둘 중 하나라도 0원(무료)인 박물관/미술관의 경우 평균 계산에서 제외해주세요.
- 조건3: 결과 DataFrame의 '광역' Index에 광역자치단체를, '박물관미술관구분' Index에 박물관미술관구분를 입력해주세요.
- 조건4: '광역' Index은 4-1문제와 같이 광역자치단체의 우선순위에 따라 나열해주세요.
- 4-1의 province_dict 참고
- 조건5: 결과 DataFrame의 '어른관람료' Column(열)은 광역자치단체-박물관미술관구분별 평균 어른 관람료를, '어린이관람료' Column(열)은 광역자치단체-박물관미술관구분별 평균 어린이 관람료를, '관람료차이' Column(열)은 광역자치단체-박물관미술관구분별 평균 어른 관람료 - 평균 어린이 관람료(차액)을 입력해주세요.
- 어른/어린이 관람료 및 관람료차이는 평균값에서 소숫점 첫째 자리에서 반올림한 정수 값을 입력해주세요.
- 예시: 2978.5원 -> 2980.0원(소숫점 첫째 자리에서 반올림) -> 2980원(정수 값)
- 예시: 청소년관람료-어린이관람료 차이가 가장 크고 작은 광역자치단체-박물관미술관구분
- 어른/어린이 관람료 및 관람료차이는 평균값에서 소숫점 첫째 자리에서 반올림한 정수 값을 입력해주세요.

- 조건6: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
완료 후 결과 dataframe 변수(df_result)를 check_04_03 함수에 입력하여 채점하세요.
문제 4-4) 원하는 정보 얻기 04 (10점)
-
3단계의 DataFrame(df_target)을 이용하여 아래의 조건에 맞는 정보를 구하세요.
- 가족(어른2, 청소년1, 어린이1)이 공휴일에 제주특별자치도 제주시에 있는 미술관을 관람하려 합니다. 총 관람료가 2만원 이하, 공휴일 4시간 이상 관람 가능한 미술관 list를 보여주세요.
- 조건1: 가족(어른 2명, 청소년 1명, 어린이 1명)의 총 관람료가 2만원 이하여야 합니다.
- 조건2: 제주특별자치도의 제주시에 있는 미술관을 가려고 합니다.
- 미술관: 이 Test에서는 df_target의 시설명 Column(열)에 있는 data 중 <'미술관' 또는 '갤러리' 또는 '아트'> 라는 글자들이 포함되어 있는 곳을 '미술관'이라고 정의합니다.
- 조건3: 공휴일에 가고자 합니다. 공휴일에 4시간 이상 관람 가능한 미술관이어야 합니다.
- 조건4: 미술관 List의 Frame은 df_target과 동일합니다.
- 예시: 서울특별시 송파구에서 가족(어른2, 청소년1, 어린이1)이 총 관람료 2만원 이내로 공휴일에 4시간 이상 관람할 수 있는 박물관 List

- 조건5: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
완료 후 결과 dataframe 변수(df_result)를 check_04_04 함수에 입력하여 채점하세요.

