
EDA Level Test 08 ⭐️⭐️
| Week | Data Analysis | Difficulty | This Notebook |
|---|---|---|---|
| 1 | 서울시 인구 데이터 | ⭐️ | |
| 2 | 화장품 성분 데이터 | ⭐️⭐️⭐️ | |
| 3 | 올림픽 데이터 | ⭐️⭐️ | |
| 4 | 국가별 인터넷 사용률 데이터 | ⭐️⭐️ | |
| 5 | 전국 박물관/미술관 정보 표준 데이터 | ⭐️⭐️⭐️ | |
| 6 | 서울시 흡연율 통계 데이터 | ⭐️⭐️ | |
| 7 | 웹크롤링 | ⭐️ | |
| 8 | 서울시 지하철 호선별 역별 유/무임 승하차 인원 정보 데이터 | ⭐️⭐️ | 👈 |
| 9 | 서울시 교통사고 현황 (사고유형별) 통계 데이터 | ⭐️⭐️ | |
| 10 | 서울시 교통사고 현황 (사고유형별) 통계 + 서울시 차량통행속도 (구별/월별) 통계 + 서울시 인구밀도 (구별) 통계 | ⭐️⭐️⭐️ |
문제 소개 및 데이터 준비 단계
문제 소개
- 총 3단계 데이터 분석 상황 제시
- 1단계: DataFrame 불러오기 및 전처리
- 2단계: 원하는 정보 얻기 01 - 기초
- 3단계: 원하는 정보 얻기 02 - 심화
- 총점 100점
Data 원본 출처
Target Data(csv): 서울시 지하철 호선별 역별 유/무임 승하차 인원 정보
- Source: 서울 열린데이터 광장
- DownLoad: 상기 Source(서울 열린데이터 광장)에서 csv 파일 Download
- 문제 출제 이후 Data 변경될 가능성이 있으므로 문제 풀이시 하기 File Path의 Data 사용
- File Path:
'./datas/서울시 지하철 호선별 역별 유_무임 승하차 인원 정보.csv'
참고사항
- 문제에 hint가 있을 경우, 해당 hint를 이용하지 않으셔도 무방합니다.
문제 시작! 🏃🏻
1단계: DataFrame 불러오기 및 전처리
문제 1-1) DataFrame 불러오기 (5점)
-
위 2. Datas의 File Path를 참고하여 아래 조건에 맞게 해당 csv 파일을 Pandas DataFrame으로 불러오세요.
-
조건1: Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건2: 'df_target' 변수에 결과 DataFrame을 할당하세요.
-
hint: encoding 확인
-
-
완료 후 결과 DataFrame 변수(df_target)를 check_01_01 함수에 입력하여 채점하세요.
file_path = './datas/서울시 지하철 호선별 역별 유_무임 승하차 인원 정보.csv'
df_target = pd.read_csv(file_path, encoding='cp949')
df_target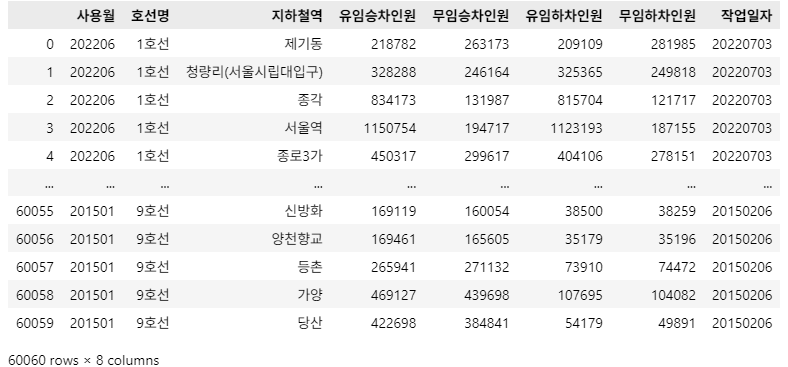
문제 1-2) DataFrame 전처리 01 - 중복제거 01 (5점)
-
중복되는 Data를 삭제하고자 합니다.
-
위 1-1의 DataFrame(df_target)을 아래 조건에 맞게 변경하세요.
-
조건1: 각 Row(행) 중 ['사용월', '호선명', '지하철역', '유임승차인원', '무임승차인원', '유임하차인원', '무임하차인원'] 의 내용이 모두 똑같은(중복되는) Row(행)이 있다면 가장 앞의 Row(Index가 가장 낮은 Row(행))는 남기고 나머지 중복되는 Row(행)를 삭제하세요.
- 예시1: 각 Row(행) 중 ['사용월', '호선명', '지하철역', '유임승차인원', '무임승차인원', '유임하차인원', '무임하차인원'] 의 내용이 모두 똑같은(중복되는) Row(행)

- 예시2: 가장 앞의 Row(Index가 가장 낮은 Row(행), 621)는 남기고 나머지 중복되는 Row(627)를 삭제

- 예시1: 각 Row(행) 중 ['사용월', '호선명', '지하철역', '유임승차인원', '무임승차인원', '유임하차인원', '무임하차인원'] 의 내용이 모두 똑같은(중복되는) Row(행)
-
조건2: Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건3: 'df_target' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_target)를 check_01_02 함수에 입력하여 채점하세요.
df_target = df_target.drop_duplicates(subset=['사용월', '호선명', '지하철역', '유임승차인원', '무임승차인원',
'유임하차인원', '무임하차인원'], keep='first')
df_target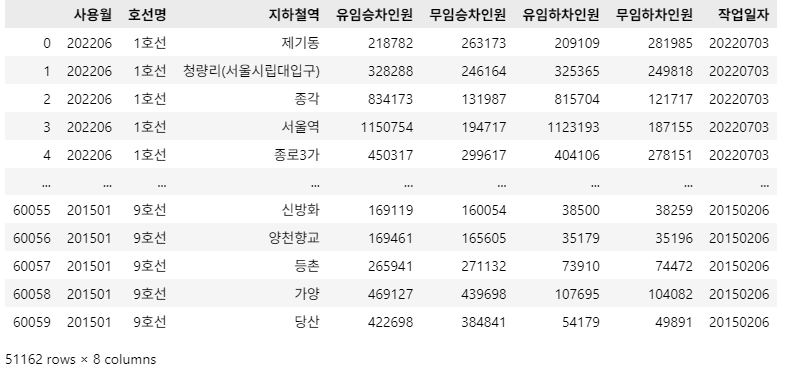
문제 1-3) DataFrame 전처리 02 - 중복제거 02 (10점)
-
위 1-2에서 삭제되지 않은 중복되는 Data를 삭제하고자 합니다.
-
위 1-2의 DataFrame(df_target)을 아래 조건에 맞게 변경하세요.
-
조건1: 각 Row(행) 중 ['사용월', '호선명', '지하철역'] 의 내용이 모두 똑같은(중복되는) Row(행)이 있다면 가장 앞의 Row(Index가 가장 낮은 Row(행))에 ['유임승차인원', '무임승차인원', '유임하차인원', '무임하차인원'] 각각 합한 값을 입력하고, 나머지 ['사용월', '호선명', '지하철역'] 의 내용이 중복되는 Row(행)를 삭제하세요.
- 예시1: ['사용월', '호선명', '지하철역'] 의 내용이 모두 똑같은(중복되는) Row(행)

- 예시2: 가장 앞의 Row(Index가 가장 낮은 Row(행), 15585)에 ['유임승차인원', '무임승차인원', '유임하차인원', '무임하차인원'] 각각 합한 값을 입력

- 예시3: 나머지 ['사용월', '호선명', '지하철역'] 의 내용이 중복되는 Row(행, 15595)를 삭제

- 예시1: ['사용월', '호선명', '지하철역'] 의 내용이 모두 똑같은(중복되는) Row(행)
-
조건2: Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건3: 'df_target' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_target)를 check_01_03 함수에 입력하여 채점하세요.
df_target['original_index'] = df_target.index
columns_to_sum = ['유임승차인원', '무임승차인원', '유임하차인원', '무임하차인원']
df_target_new = []
seen_rows = {}
for idx, row in df_target.iterrows():
group_key = (row['사용월'], row['호선명'], row['지하철역'])
if group_key not in seen_rows:
seen_rows[group_key] = row
df_target_new.append(row)
else:
first_row = seen_rows[group_key]
for col in columns_to_sum:
first_row[col] += row[col]
df_target_new = pd.DataFrame(df_target_new)
df_target_new = df_target_new.sort_values(by='original_index')
df_target_new = df_target_new.drop(columns=['original_index'])
df_target = df_target_new
df_target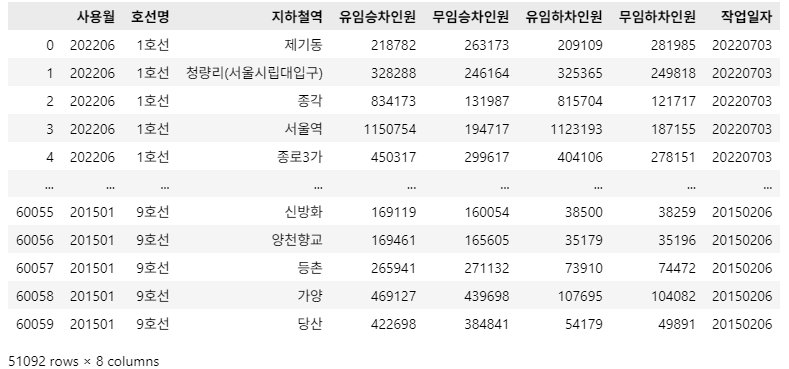
문제 1-4) DataFrame 전처리 03 - Data 수정 01 (5점)
-
위 1-3의 DataFrame(df_target)을 아래 조건에 맞게 변경하세요.
-
조건1: '호선명' Column(열)의 Data가 '9호선2~3단계' 또는 '9호선2단계'라면 이를 '9호선'으로 변경하세요.
-
조건2: '지하철역' Column(열)의 Data에 괄호('(', ')')가 있다면, 괄호 안의 내용과 괄호 자체를 모두 지워주세요.
- 예시: '청량리(서울시립대입구)' -> '청량리'
-
조건3: '지하철역' Column(열)의 Data가 '신천'이라면 '잠실새내'로 변경하세요.
-
조건4: Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건5: 'df_target' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_target)를 check_01_04 함수에 입력하여 채점하세요.
df_target['호선명'] = df_target['호선명'].replace({'9호선2~3단계': '9호선', '9호선2단계': '9호선'})
df_target['지하철역'] = df_target['지하철역'].str.replace(r'\(.*?\)', '', regex=True)
df_target['지하철역'] = df_target['지하철역'].replace({'신천': '잠실새내'})
df_target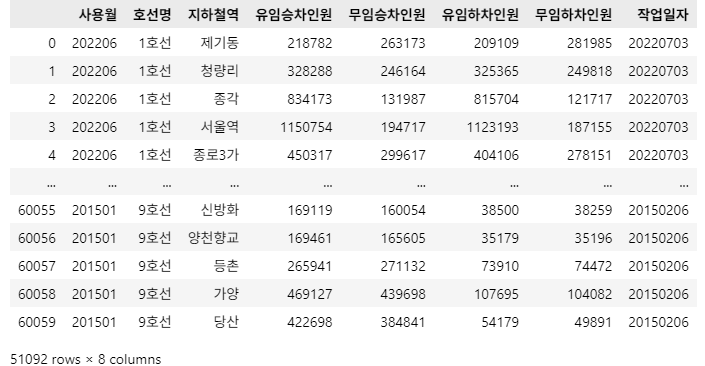
문제 1-5) DataFrame 전처리 03 - Data 수정 02 (10점)
-
아래 Cell의 incheon_station_list에 있는 역은 모두 7호선의 역입니다. 해당 역들은 서울특별시가 아닌 인천광역시(인천교통공사)가 담당하여 Data가 부정확한 것으로 추정됩니다. 이에 기존 7호선과 인천광역시 담당 7호선을 구분하려고 합니다.
-
위 1-4의 DataFrame(df_target)을 아래 조건에 맞게 변경하세요.
-
조건1: incheon_station_list에 있는 역들의 '호선명'을 '7호선'에서 '7호선 인천'으로 변경해주세요.
- 예시1: '7호선' 변경 전

- 예시2: '7호선 인천'으로 변경 후

- 예시1: '7호선' 변경 전
-
조건2: '지하철역' Column(열)의 Data에 괄호('(', ')')가 있다면, 괄호 안의 내용과 괄호 자체를 모두 지워주세요.
- 예시: '청량리(서울시립대입구)' -> '청량리'
-
조건3: '지하철역' Column(열)의 Data가 '신천'이라면 '잠실새내'로 변경하세요.
-
조건4: Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건5: 'df_target' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_target)를 check_01_05 함수에 입력하여 채점하세요.
incheon_station_list = ['까치울', '부천종합운동장', '춘의', '신중동', '부천시청', '상동',
'삼산체육관', '굴포천', '부평구청', '산곡', '석남']
df_target.loc[df_target['지하철역'].isin(incheon_station_list), '호선명'] = '7호선 인천'
df_target['지하철역'] = df_target['지하철역'].str.replace(r'\(.*?\)', '', regex=True)
df_target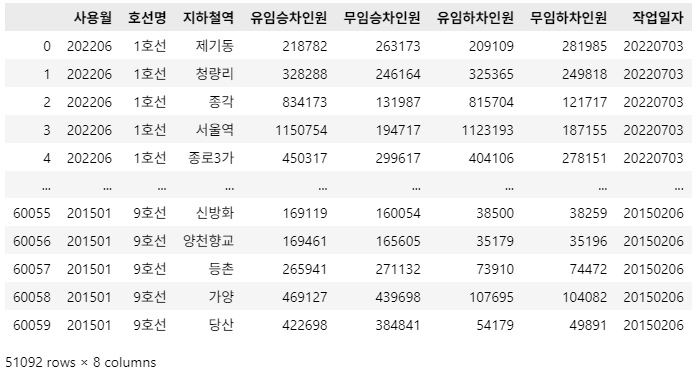
2단계: 원하는 정보 얻기 01 - 기초
문제 2-1) 기초 정보 얻기 01 (5점)
-
위 1단계의 DataFrame(df_target)을 이용하여 아래 예시 및 조건에 맞는 정보를 구하세요.
-
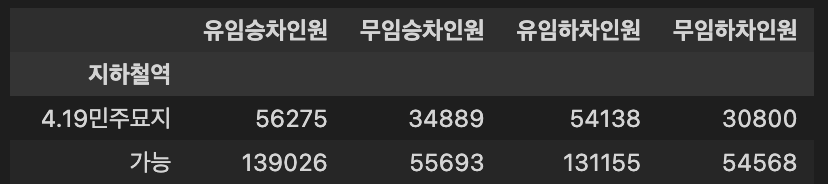
예시: df_result.iloc[:2]
-
조건1: 2022년 6월 기준 각 지하철 역의 [유임승차인원, 무임승차인원, 유임하차인원, 무임하차인원] 을 구하세요.
-
조건2: 환승역(한 지하철역에 여러개의 호선이 있는 역)이 있다면 합산해 주세요.
-
예시: 종합운동장역의 경우 2, 9호선 유/무임 승/하차인원을 합쳐서 보여주세요.


-
-
조건3: Index와 Column은 아래와 같이 지정해 주세요.
- Index: '지하철역'
- Column: ['유임승차인원', '무임승차인원', '유임하차인원', '무임하차인원']
-
조건4: Index 기준 오름차순으로 정렬해주세요.
-
조건5: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_result)를 check_02_01 함수에 입력하여 채점하세요.
df_june_2022 = df_target[df_target['사용월'] == 202206]
df_result = df_june_2022.groupby('지하철역')[['유임승차인원', '무임승차인원', '유임하차인원', '무임하차인원']].sum()
df_result = df_result.sort_index()
df_result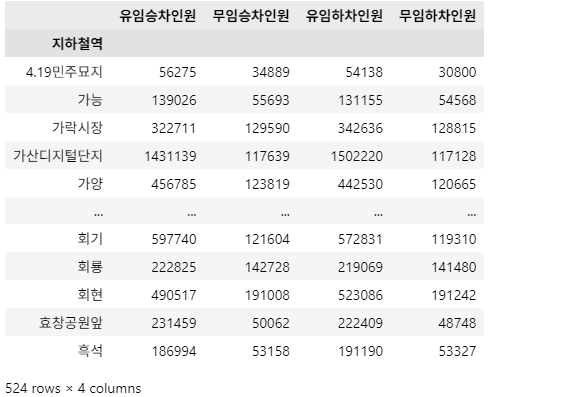
문제 2-2) 기초 정보 얻기 02 (10점)
-
위 1단계의 DataFrame(df_target)을 이용하여 아래 예시 및 조건에 맞는 정보를 구하세요.
-
예시: df_result.iloc[:4]

-
조건1: 2022년 6월 기준 각 지하철 역의 호선의 수를 구하고, 호선의 수가 3개 이상인 역만 보여주세요.
-
조건2: '호선수' Column(열)을 만들어 해당 역의 호선 수를 입력해주세요.
-
조건3: Index와 Column은 아래와 같이 지정해 주세요.
- Index: '지하철역'
- Column: ['호선수']
-
조건4: '호선수' Column(열)을 기준으로 내림차순 정렬하고, '호선수'가 같다면 Index('지하철역')를 기준으로 내림차순 정렬해주세요.
-
조건5: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_result)를 check_02_02 함수에 입력하여 채점하세요.
df_june_2022['호선수'] = df_june_2022.groupby('지하철역')['호선명'].transform('nunique')
df_filtered = df_june_2022[df_june_2022['호선수'] >= 3]
df_result = df_filtered[['지하철역', '호선수']].drop_duplicates()
df_result = df_result.set_index('지하철역').sort_values(by=['호선수', '지하철역'], ascending=[False, False])
df_result
문제 2-3) 기초 정보 얻기 03 (10점)
-
위 1단계의 DataFrame(df_target)을 이용하고, 위 2-2의 DataFrame(df_result)를 응용하여 아래 예시 및 조건에 맞는 정보를 구하세요.
-
예시: df_result.iloc[:4]

-
조건1: 위 2-2를 참고하여 아래와 같이 '호선수'를 구하세요.
- 2022년 6월 기준 각 지하철 역의 호선의 수를 구하고, 호선의 수가 3개 이상인 역만 보여주세요.
- '호선수' Column(열)을 만들어 해당 역의 호선 수를 입력해주세요.
-
조건2: 2022년 6월 기준 '환승호선' Column(열)을 만들어 아래와 같이 해당 역의 환승 가능 호선을 나열해주세요.
- 환승 호선들은 ', '(쉼표+띄어쓰기)로 구분되는 string입니다.
- 환승 호선들은 오름차순으로 정렬 후 나열해주세요.
- 위 예시를 참고해주세요.
-
조건3: Index와 Column은 아래와 같이 지정해 주세요.
- Index: '지하철역'
- Column: ['호선수', '환승호선']
-
조건4: '호선수' Column(열)을 기준으로 내림차순 정렬하고, '호선수'가 같다면 '환승호선' Column(열)을 기준으로 오름차순 정렬해주세요.
-
조건5: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_result)를 check_02_03 함수에 입력하여 채점하세요.
df_filtered = df_june_2022[df_june_2022['호선수'] >= 3]
df_filtered['환승호선'] = df_filtered.groupby('지하철역')['호선명'].transform(lambda x: ', '.join(sorted(x.unique())))
df_result = df_filtered[['지하철역', '호선수', '환승호선']].drop_duplicates()
df_result = df_result.set_index('지하철역').sort_values(by=['호선수', '환승호선'], ascending=[False, True])
df_result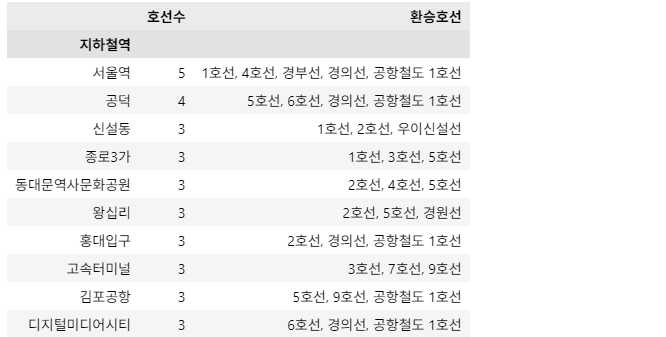
문제 2-4) 기초 정보 얻기 04 (10점)
-
위 1단계의 DataFrame(df_target)을 이용하고, 위 2-2의 DataFrame(df_result)를 응용하여 아래 예시 및 조건에 맞는 정보를 구하세요.
-
예시: df_result.iloc[:4]
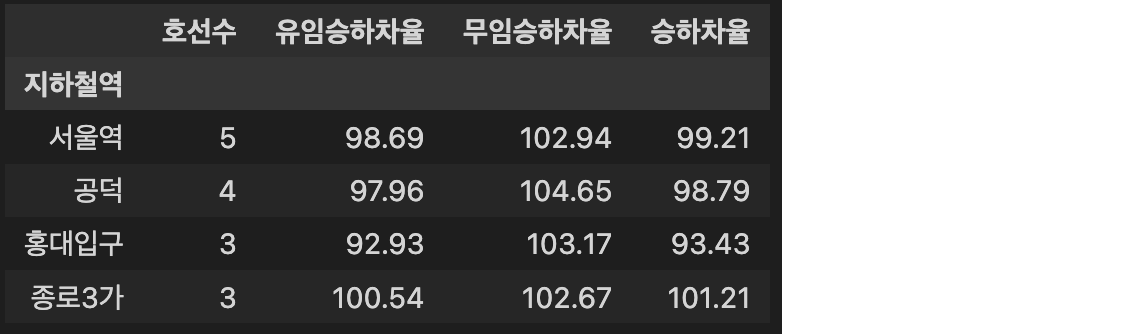
-
조건1: 위 2-2를 참고하여 아래와 같이 '호선수'를 구하세요.
- 2022년 6월 기준 각 지하철 역의 호선의 수를 구하고, 호선의 수가 2개 이상인 역만 보여주세요.
- '호선수' Column(열)을 만들어 해당 역의 호선 수를 입력해주세요.
-
조건2: 2022년 6월 기준 ['유임승하차율', '무임승하차율', '승하차율'] Column(열)을 만들어 아래와 같이 각각의 승하차율을 구하세요.
- 유임승하차율 = 유임승차인원 / 유임하차인원 * 100
- 무임승하차율 = 무임승차인원 / 무임하차인원 * 100
- 승하차율 = (유임승차인원 + 무임승차인원) / (유임하차인원 + 무임하차인원) * 100
- 각각의 승하차율은 소숫점 셋째자리에서 반올림하여 둘째자리까지 표기합니다.
- '무임승하차율'이 '승하차율'보다 크면서, '무임승하차율'이 102 이상인 역만 보여주세요.
- 위 예시를 참고해주세요.
-
조건3: Index와 Column은 아래와 같이 지정해 주세요.
- Index: '지하철역'
- Column: ['호선수', '유임승하차율', '무임승하차율', '승하차율']
-
조건4: '호선수' Column(열)을 기준으로 내림차순 정렬하고, '호선수'가 같다면 '무임승하차율' Column(열)을 기준으로 내림차순 정렬해주세요.
-
조건5: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_result)를 check_02_04 함수에 입력하여 채점하세요.
df_june_2022 = df_target[df_target['사용월'] == 202206].copy()
df_filtered_1 = df_june_2022.groupby(['지하철역']).agg(호선수=('호선명', 'nunique')).reset_index()
df_filtered_2 = df_june_2022.groupby(['지하철역']).sum()
df_filtered_2['유임승하차율'] = round(df_filtered_2['유임승차인원'] / df_filtered_2['유임하차인원'] * 100, 2)
df_filtered_2['무임승하차율'] = round(df_filtered_2['무임승차인원'] / df_filtered_2['무임하차인원'] * 100, 2)
df_filtered_2['승하차율'] = round((df_filtered_2['유임승차인원'] + df_filtered_2['무임승차인원']) / (df_filtered_2['유임하차인원'] + df_filtered_2['무임하차인원']) * 100, 2)
df_filtered_2 = df_filtered_2[['유임승차인원', '유임하차인원', '무임승차인원', '무임하차인원', '유임승하차율', '무임승하차율', '승하차율']]
df_result = pd.merge(df_filtered_1, df_filtered_2, on='지하철역')
df_result = df_result[(df_result['호선수'] >= 2) & (df_result['무임승하차율'] > df_result['승하차율']) & (df_result['무임승하차율'] > 102)]
df_result.sort_values(by=['호선수', '무임승하차율'], ascending=[False, False], inplace=True)
df_result = df_result[['지하철역', '호선수', '유임승하차율', '무임승하차율', '승하차율']]
df_result.set_index('지하철역', inplace=True)
df_result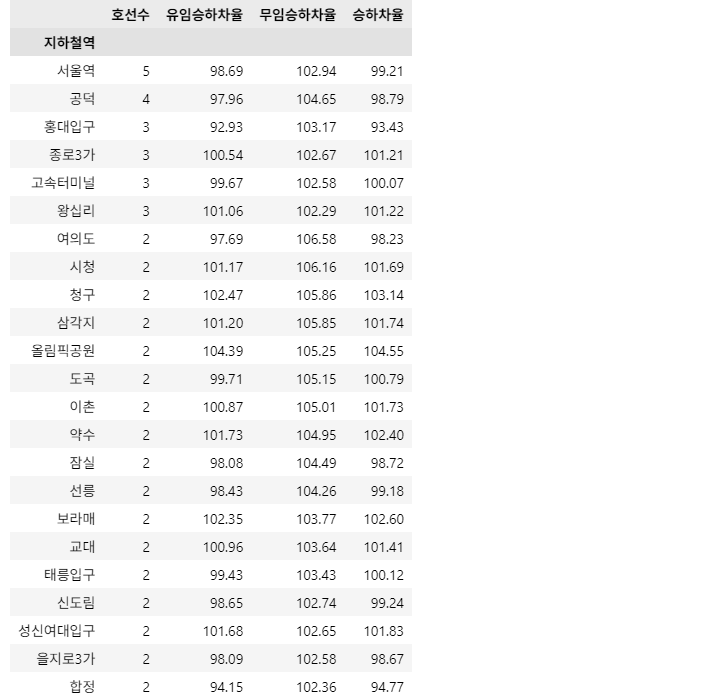
3단계: 원하는 정보 얻기 02 - 심화
문제 3-1) 심화 정보 얻기 01 (15점)
-
2022년 1월 대비 2022년 6월에 유동인구가 얼마나 증가/감소하였는지 확인해보고자 합니다.
-
위 1단계의 DataFrame(df_target)을 이용하여 아래 예시 및 조건에 맞는 정보를 구하세요.
-
예시: df_result.iloc[:2]

-
조건1: '유동인구증감률' Column(열)을 만들어 2022년 1월 대비 2022년 6월의 유동인구 증가율을 입력하세요.
- 유동인구 = '유임승차인원' + '무임승차인원' + '유임하차인원' + '무임하차인원'
- 유동인구 증감률 = (2022년 6월의 유동인구 / 2022년 1월의 유동인구 - 1) * 100
- 유동인구 증감률은 소숫점 셋째자리에서 반올림하여 둘째자리까지 표기합니다.
- 유동인구가 감소한(유동인구 증감률이 0보다 작은) 역만 보여주세요.
-
조건2: 2022년 1월 이후에 역이 신설되어 2022년 1월 유동인구 Data가 없는 경우 제외하고 계산하세요.
- '신림선'의 역들은 2022년 5월에 운영 시작하였습니다.
-
조건3: 위 1-5를 참고하여 '호선명' Column(열) Data가 '7호선 인천'인 경우는 제외하고 구하세요.
- 앞서 언급하였다시피 Data에 오류가 있는 것으로 추정되어 제외합니다.
-
조건4: Index와 Column은 아래와 같이 지정해 주세요.
- Index: '지하철역'
- Column: ['유동인구증감률']
-
조건5: '유동인구증가율' Column(열)을 기준으로 내림차순 정렬하세요.
-
조건6: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_result)를 check_03_01 함수에 입력하여 채점하세요.
df_january_2022 = df_target[df_target['사용월'] == 202201]
df_january_2022 = df_january_2022[df_january_2022['호선명'] != '7호선 인천']
df_january_2022['유동인구'] = df_january_2022['유임승차인원'] + df_january_2022['무임승차인원'] + df_january_2022['유임하차인원'] + df_january_2022['무임하차인원']
df_january_2022 = df_january_2022.groupby(['지하철역'])['유동인구'].sum()
df_june_2022 = df_target[df_target['사용월'] == 202206]
df_june_2022 = df_june_2022[df_june_2022['호선명'] != '7호선 인천']
df_june_2022['유동인구'] = df_june_2022['유임승차인원'] + df_june_2022['무임승차인원'] + df_june_2022['유임하차인원'] + df_june_2022['무임하차인원']
df_june_2022 = df_june_2022.groupby(['지하철역'])['유동인구'].sum()
merged_df = pd.merge(df_january_2022, df_june_2022, on='지하철역', suffixes=('_1월', '_6월'))
merged_df['유동인구증감률'] = round(((merged_df['유동인구_6월'] / merged_df['유동인구_1월']) - 1) * 100, 2)
merged_df = merged_df[merged_df['유동인구증감률'] < 0]
df_result = merged_df[['유동인구증감률']].sort_values(by='유동인구증감률', ascending=False)
df_result
문제 3-2) 심화 정보 얻기 02 (15점)
-
2015년부터 2022년까지 지하철 1~9호선에서 신설된 역을 확인하고자 합니다.
-
위 1단계의 DataFrame(df_target)을 이용하여 아래 예시 및 조건에 맞는 정보를 구하세요.
- 예시: df_result.iloc[:2]

- 예시: df_result.iloc[:2]
-
조건1: 2015년부터 2022년까지 지하철 1~9호선에서 신설된 역을 확인하고자 합니다.
-
위 1-5를 참고하여 '호선명' Column(열) Data가 '7호선 인천'인 경우는 제외하고 구하세요.
-
신설 역: 2015년 1월부터 2022년 6월까지의 기간 중 유동인구('유임승차인원' + '무임승차인원' + '유임하차인원' + '무임하차인원') Data가 존재하지 않는 경우 해당 월에 해당 역은 존재하지 않는다고 판단합니다. 예를들어 2018년 3월부터 유동인구 Data가 있다면 해당 역은 2018년 3월에 신설되었다고 판단합니다.
-
예시: 9호선 '둔촌오륜'역의 경우 Data가 2018년 12월 부터 2022년 6월까지 존재합니다. 따라서 9호선 '둔촌오륜'역은 2018년 12월에 신설된 역으로 판단합니다.
-
-
조건2: Index와 Column은 아래와 같이 지정해 주세요.
-
Index: 0부터 시작하는 연속의 숫자
-
Column: ['호선명', '지하철역', '신설월']
-
-
조건3: 아래와 같이 DataFrame을 정렬하고 Index를 초기화 하세요..
-
'호선명' Column(열)을 기준으로 오름차순 정렬하세요.
-
'호선명'이 같다면, '신설월' Column(열)을 기준으로 내림차순 정렬하세요.
-
'호선명'과 '신설월'이 같다면, '지하철역' Column(열)을 기준으로 오름차순 정렬하세요.
-
위와 같이 정렬 후 Index를 Reset하고, 기존 Index는 삭제(drop)하세요.
-
-
조건4: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
완료 후 결과 DataFrame 변수(df_result)를 check_03_02 함수에 입력하여 채점하세요.
df_target['사용월'] = df_target['사용월'].astype(str)
df_target['연도'] = df_target['사용월'].str[:4].astype(int)
df_target_filtered = df_target[(df_target['연도'] >= 2015) & (df_target['연도'] <= 2022)]
df_target_filtered = df_target_filtered[df_target_filtered['호선명'] != '7호선 인천']
df_target_filtered = df_target_filtered[df_target_filtered['호선명'].isin([f'{i}호선' for i in range(1, 10)])]
all_months = sorted(df_target_filtered['사용월'].unique())
data_list = []
for line, station_name in df_target_filtered[['호선명', '지하철역']].drop_duplicates().values:
target_months = sorted(df_target_filtered[df_target_filtered['지하철역'] == station_name]['사용월'].to_list())
no_exist = [month for month in all_months if month not in target_months]
if no_exist:
data_list.append([line, station_name, target_months[0]])
df_result = pd.DataFrame(data_list, columns=['호선명', '지하철역', '신설월'])
df_result.sort_values(by=['호선명', '신설월', '지하철역'], ascending=[True, False, True], inplace=True)
df_result.reset_index(drop=True, inplace=True)
df_result
