EDA Level Test 09 ⭐️⭐️
| Week | Data Analysis | Difficulty | This Notebook |
|---|---|---|---|
| 1 | 서울시 인구 데이터 | ⭐️ | |
| 2 | 화장품 성분 데이터 | ⭐️⭐️⭐️ | |
| 3 | 올림픽 데이터 | ⭐️⭐️ | |
| 4 | 국가별 인터넷 사용률 데이터 | ⭐️⭐️ | |
| 5 | 전국 박물관/미술관 정보 표준 데이터 | ⭐️⭐️⭐️ | |
| 6 | 서울시 흡연율 통계 데이터 | ⭐️⭐️ | |
| 7 | 웹크롤링 | ⭐️ | |
| 8 | 서울시 지하철 호선별 역별 유/무임 승하차 인원 정보 데이터 | ⭐️⭐️ | |
| 9 | 서울시 교통사고 현황 (사고유형별) 통계 데이터 | ⭐️⭐️ | 👈 |
| 10 | 서울시 교통사고 현황 (사고유형별) 통계 + 서울시 차량통행속도 (구별/월별) 통계 + 서울시 인구밀도 (구별) 통계 | ⭐️⭐️⭐️ |
문제 소개 및 데이터 준비 단계
-
총 3단계 데이터 분석 상황 제시
-
1단계: DataFrame 전처리
-
2단계: Data 가공 및 추출
-
3단계: 원하는 정보 얻기
-
총점 100점
-
Data 원본 출처
Target Data(csv): 서울시 교통사고 현황 (사고유형별) 통계
-
Source: 서울 열린데이터 광장
-
DownLoad: 상기 Source(서울 열린데이터 광장)에서 csv 파일 Download
- 문제 출제 이후 Data 변경될 가능성이 있으므로 문제 풀이시 하기 File Path의 Data 사용
-
File Path:
'./datas/교통사고+현황(사고유형별).csv'
참고사항
- 문제에 hint가 있을 경우, 해당 hint를 이용하지 않으셔도 무방합니다.
문제 시작! 🏃🏻
1단계: DataFrame 전처리
문제 1-1) DataFrame 전처리 01 - Column(열)명 수정 (10점)
-
Column(열)명을 수정하고자 합니다.
-
위 2. Datas에서 불러온 DataFrame(df_target)을 아래 조건에 맞게 변경하세요.
-
조건1: ['자치구별(1)', '사고유형별(2)'] Column(열)을 삭제해주세요.
-
조건2: ['자치구별(2)', '사고유형별(1)'] Column(열)명을 아래와 같이 변경해주세요.
-
'자치구별(2)' -> '자치구'
-
'사고유형별(1)' -> '사고유형'
-
'구분별(1)' -> '구분'
-
-
조건3: Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건4: 'df_target' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_target)를 check_01_01 함수에 입력하여 채점하세요.
import pandas as pd
df_target = pd.read_csv('./datas/교통사고+현황(사고유형별).csv')
df_target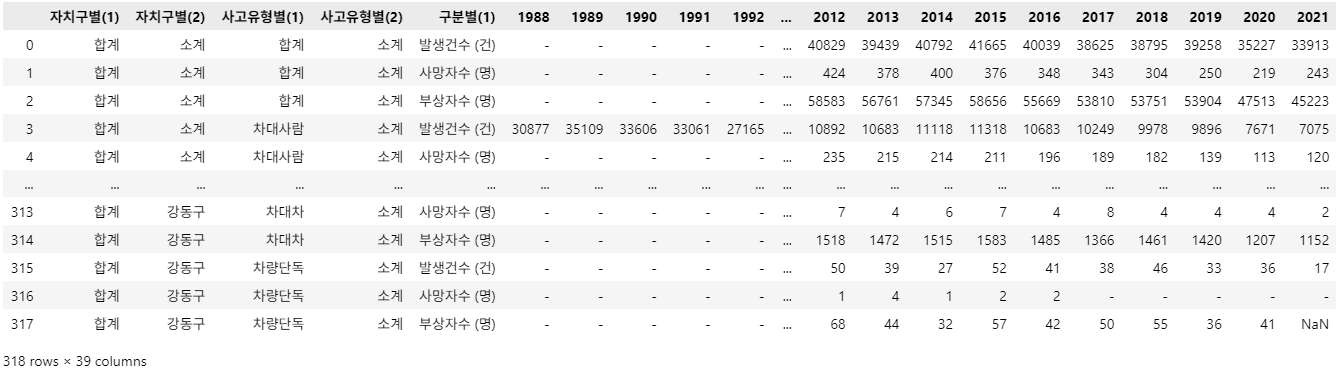
# 1-1
df_target = df_target.drop(columns=['자치구별(1)', '사고유형별(2)'])
df_target = df_target.rename(columns={
'자치구별(2)': '자치구',
'사고유형별(1)': '사고유형',
'구분별(1)': '구분'
})
df_target.head()
문제 1-2) DataFrame 전처리 02 - 특정 Column(열) Data 수정 (10점)
-
Data를 수정하고자 합니다.
-
위 1-1 DataFrame(df_target)을 아래 조건에 맞게 변경하세요.
-
조건1: '구분' Column(열) Data를 아래와 같이 변경해주세요.
-
괄호 및 괄호 안의 내용 삭제
-
값 앞뒤에 공백(띄어쓰기 등) 삭제
-
발생건수 (건) → 발생건수
-
사망자수 (명) → 사망자수
-
부상자수 (명) → 부상자수
-
-
-
조건2: Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건3: 'df_target' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_target)를 check_01_02 함수에 입력하여 채점하세요.
# 1-2
df_target['구분'] = df_target['구분'].str.replace(r"\s*\(.*?\)", "", regex=True).str.strip()
df_target.head()
문제 1-3) DataFrame 전처리 03 - Data Type 변경 (10점)
-
Data Type을 수정하고자 합니다.
-
위 1-2 DataFrame(df_target)을 아래 조건에 맞게 변경하세요.
-
조건1: ['1988', '1989', ..., '2020', '2021'] Column(열) Data 중 '-'인 Data를 숫자 0(정수형)으로 변경해주세요.
-
조건2: ['1988', '1989', ..., '2020', '2021'] Column(열) Data 중 nan인 Data를 숫자 0(정수형)으로 변경해주세요.
-
조건3: ['1988', '1989', ..., '2020', '2021'] Column(열) Data 중 전부 숫자로 구성 되어있는 Data의 Type을 정수형으로 변경해주세요.
-
조건4: Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건5: 'df_target' 변수에 결과 DataFrame을 할당하세요.
- hint: ['1988', '1989', ..., '2020', '2021'] Column(열) Data의 Type은 int(int64)가 되어야 합니다.
-
-
완료 후 결과 DataFrame 변수(df_target)를 check_01_03 함수에 입력하여 채점하세요.
# 1-3
year_cols = df_target.columns[3:]
df_target[year_cols] = df_target[year_cols].replace('-', 0)
df_target[year_cols] = df_target[year_cols].fillna(0)
df_target[year_cols] = df_target[year_cols].astype(int)
df_target.head()
문제 1-4) DataFrame 전처리 04 - Index 설정 (10점)
-
Index를 설정하고자 합니다.
-
위 1-3 DataFrame(df_target)을 아래 예시 및 조건에 맞게 변경하세요.
-
예시: df_target.iloc[:26]
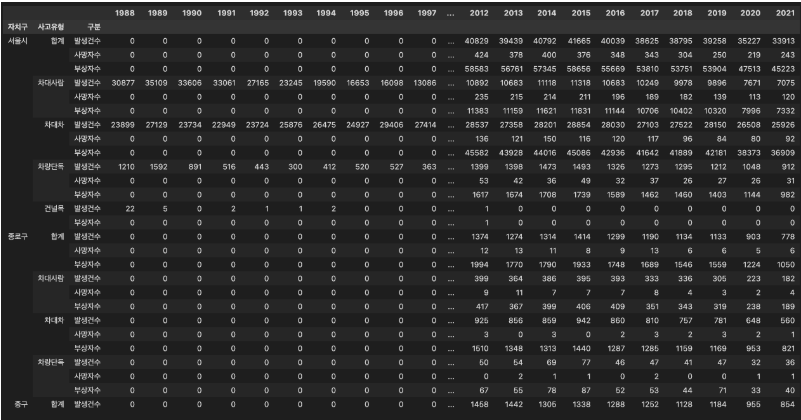
-
조건1: '자치구' Column(열) Data 중 '소계'인 Data를 '서울시'로 변경해주세요.
-
조건2: ['자치구', '사고유형', '구분'] 'Column(열)을 Index로 설정해주세요.
-
조건3: 상기 조건 이외의 Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건4: 'df_target' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_target)를 check_01_04 함수에 입력하여 채점하세요.
# 1-4
df_target['자치구'] = df_target['자치구'].replace('소계', '서울시')
df_target = df_target.set_index(['자치구', '사고유형', '구분'])
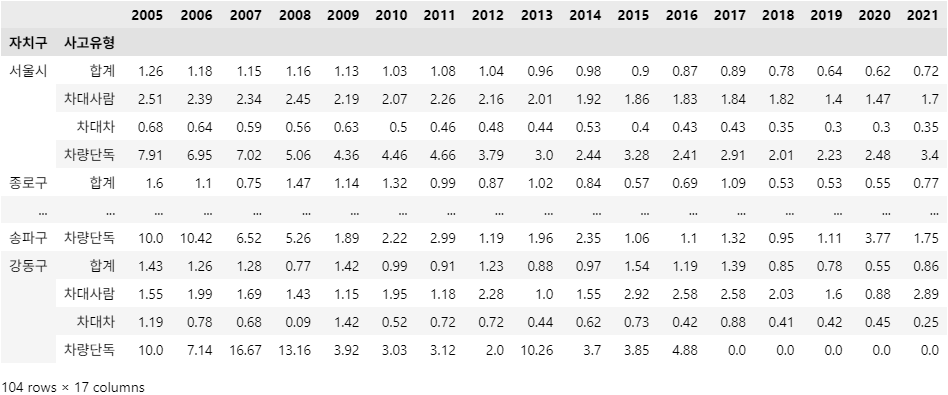
df_target.loc['서울시']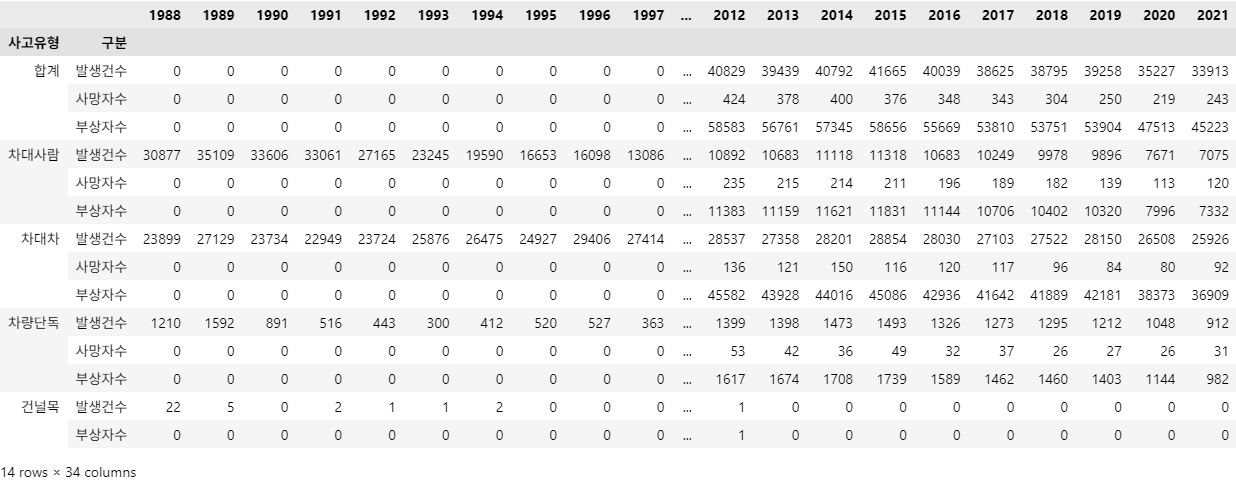
문제 1-5) DataFrame 전처리 05 - 값 채우기 (10점)
-
0인 값 중 일부를 채우고자 합니다.
-
위 1-4 DataFrame(df_target)을 아래 조건에 맞게 변경하세요.
-
조건1: 현재 값이 0인 ['1988', '1989', ..., '2003', '2004'] Column(열)의 '서울시'-'합계'-'발생건수' Row(행) Data를 채워주세요.
-
각 자치구('서울시' 포함) '합계'-'발생건수'는 '차대사람'-'발생건수', '차대차'-'발생건수', '차량단독'-'발생건수', '건널목'-'발생건수'의 합입니다.
-
예시: '용산구'의 2005~2006년 Data
-
2005년 '용산구'-'합계'-'발생건수' 1360 = '차대사람'-'발생건수' 230 + '차대차'-'발생건수' 1082 + '차량단독'-'발생건수' 48 + '건널목'-'발생건수' 0

-
-
-
조건2: 상기 조건 이외의 Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건3: 'df_target' 변수에 결과 DataFrame을 할당하세요.
-
참고
-
Coding 방식에 따라 SettingWithCopyWarning 이 발생할 수 있습니다.
-
해당 경고(Warning)가 발생하더라도 정답 인정 여부와는 상관 없습니다.
-
경고(Warning)가 거슬린다면,
pd.set_option('mode.chained_assignment', None)설정을 진행하시면 됩니다. -
다만 경고(Warning)가 안나오게끔 진행하시길 추천드립니다.
-
-
-
완료 후 결과 DataFrame 변수(df_target)를 check_01_05 함수에 입력하여 채점하세요.
# 1-5
year_cols = [str(year) for year in range(1988, 2005)]
target_types = ['차대사람', '차대차', '차량단독', '건널목']
sum_values = df_target.loc[('서울시', target_types, '발생건수'), year_cols].groupby(level=0).sum()
df_target.loc[('서울시', '합계', '발생건수'), year_cols] = sum_values.loc['서울시']
df_target.loc['서울시']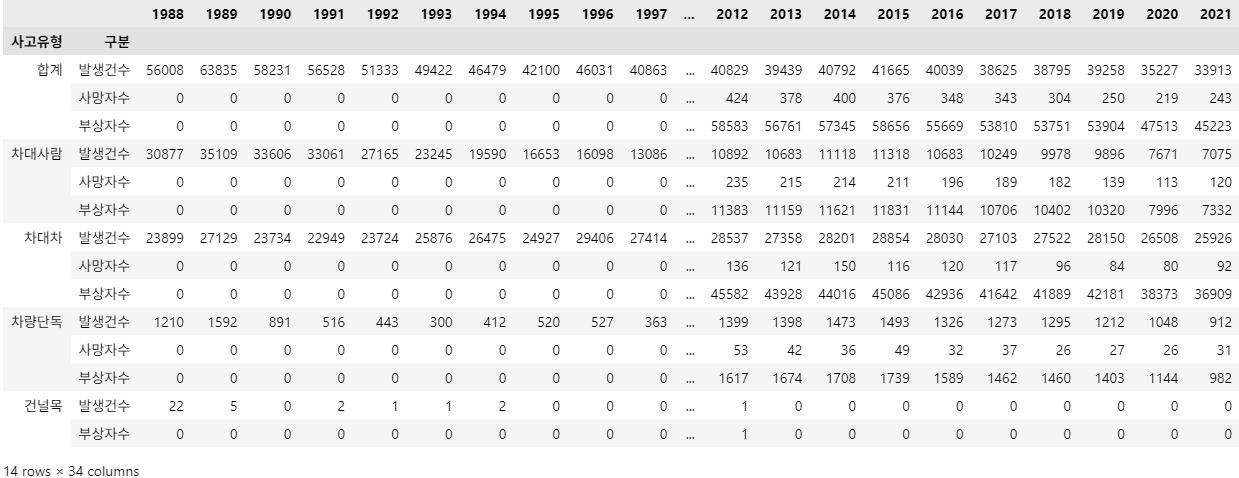
2단계: Data 가공 및 추출
문제 2-1) Data 가공 및 추출 01 - 일부 Data 추출 및 Index 수정 (10점)
-
일부 Data('발생건수')만 추출하고, 불필요한 Index('구분')를 지우려고 합니다.
-
위 1-5 DataFrame(df_target)을 아래 조건에 맞게 변경하세요.
-
조건1: 각 자치구('서울시' 포함) / 사고유형별 '발생건수' Row(행) Data만 추출하세요.
-
조건2: '구분' Index를 제거하세요.
-
조건3: 상기 조건 이외의 Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
기존 DataFrame(df_target)에서 Index/Column 순서 그대로 '발생건수'만 추출해야 합니다.
-
예시: df_result.iloc[:14], 모든 값에 0 입력
-
-
조건4: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_result)를 check_02_01 함수에 입력하여 채점하세요.
# 2-1
df_result = df_target[df_target.index.get_level_values('구분') == '발생건수']
df_result = df_result.reset_index(level='구분', drop=True)
df_result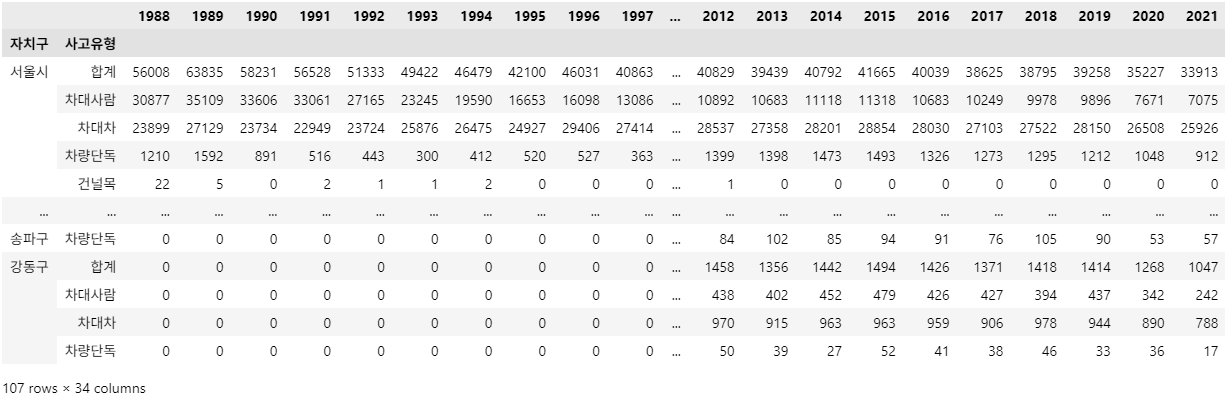
문제 2-2) Data 가공 및 추출 02 - 일부 Data 추출 및 Index 수정 (20점)
-
일부 Data('사망자수')만 추출하고, Index 수정(위치/정렬) 및 삭제('구분')하고자 합니다.
-
위 1-5 DataFrame(df_target)을 아래 조건에 맞게 변경하세요.
-
조건1: 각 자치구('서울시' 포함) / 사고유형별 '사망자수' Row(행) Data만 추출하세요.
-
조건2: '구분' Index를 제거하세요.
-
조건3: Index는 아래와 같이 변경하세요.
-
'자치구'와 '사고유형'의 위치를 바꾸어주세요.
-
'사고유형' Index는 아래 type_list의 순서와 동일하게 정렬해주세요.
-
'자치구' Index는 아래 gu_list의 순서와 동일하게 정렬해주세요.
-
'사고유형' Index를 우선하여 정렬하여 주세요.
- 예시: df_result.iloc[:30], 모든 값에 0 입력
-
-
조건4: 상기 조건 이외의 Column 순서는 변경하지 마세요.
-
조건5: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_result)를 check_02_02 함수에 입력하여 채점하세요.
# 2-2
type_list = df_target.index.get_level_values('사고유형').unique()
gu_list = df_target.index.get_level_values('자치구').unique()
df_result = df_target[df_target.index.get_level_values('구분') == '사망자수']
df_result = df_result.reset_index(level='구분', drop=True)
df_result = df_result.reset_index()
df_result = df_result.set_index(['사고유형', '자치구'])
df_result = df_result.reindex(type_list, level='사고유형')
df_result = df_result.reindex(gu_list, level='자치구')
df_result = df_result.loc[:, ~(df_result == 0).all()]
df_result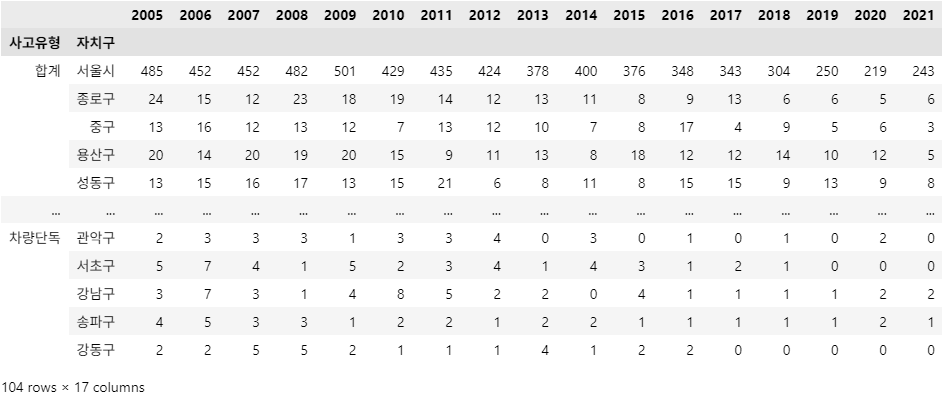
3단계: 원하는 정보 얻기
문제 3) 원하는 정보 얻기 - 사망률 (20점)
-
2005년 이후 교통사고 발생시 '사망률'을 구하고자 합니다.
-
위 1-5 DataFrame(df_target)을 아래 조건에 맞게 변경하세요.
-
조건1: 2005년부터 2021년까지 각 자치구('서울시' 포함) / 사고유형별 '사망률'을 구하고자 합니다.
-
'사망률' = '사망자수' / '발생건수' * 100
-
소숫점 셋째자리에서 반올림하여 두번째자리까지 표기해주세요.
-
특정 자치구의 사고유형 중 '사망자수' 또는 '발생건수'가 없다면 계산하지 말고 넘어가세요.
-
예시1
- 2005년 '서울시'-'차대사람'의 '사망률' 2.51 = 2005년 '서울시'-'차대사람'-'사망자수' 229 / 2005년 '서울시'-'차대사람'-'발생건수' 9111 * 100
-
예시2
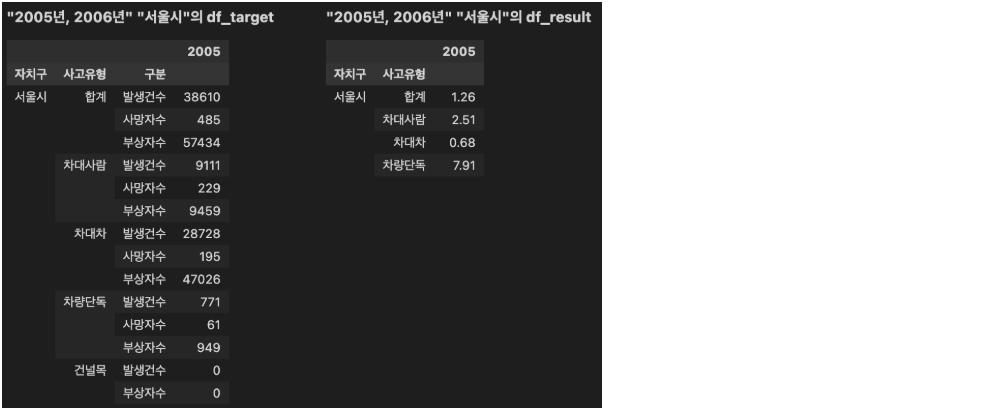
-
-
조건2: '구분' Index를 제거하세요.
-
조건3: 상기 조건 이외의 Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
기존 DataFrame(df_target)에서 Index/Column 순서에 맞추어 '사망률'만 나타내야 합니다.
- '사고유형' Index는 아래 type_list의 순서와 동일하게 정렬되어야 합니다.
- '자치구' Index는 아래 gu_list의 순서와 동일하게 정렬되어야 합니다.
-
예시: df_result, 모든 값에 0 입력
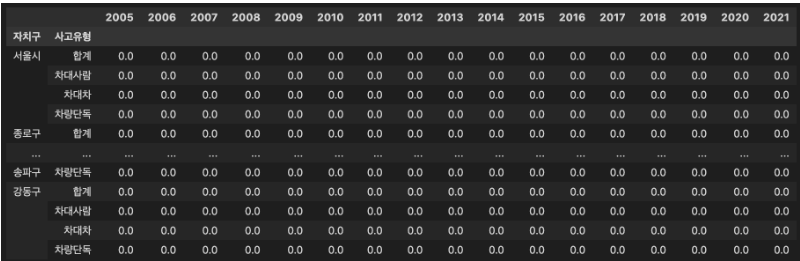
-
-
조건4: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_result)를 check_03 함수에 입력하여 채점하세요.
# 3
def calculate_death_rate(df_target, start_year=2005, end_year=2021):
years = [str(year) for year in range(start_year, end_year + 1)]
gu_list = df_target.index.get_level_values('자치구').unique()
type_list = df_target.index.get_level_values('사고유형').unique()
df_result = pd.DataFrame(index=pd.MultiIndex.from_product([gu_list, type_list],
names=['자치구', '사고유형']),
columns=years)
for year in years:
for gu in gu_list:
for type in type_list:
try:
death_count = df_target.loc[(gu, type, '사망자수'), year]
accident_count = df_target.loc[(gu, type, '발생건수'), year]
if pd.notnull(death_count) and pd.notnull(accident_count):
death_rate = (death_count / accident_count) * 100
df_result.at[(gu, type), year] = round(death_rate, 2)
else:
df_result.at[(gu, type), year] = None
except KeyError:
df_result.at[(gu, type), year] = None
for gu in gu_list:
for type in type_list:
if df_result.loc[(gu, type)].isnull().all():
df_result = df_result.drop((gu, type))
return df_result
df_result = calculate_death_rate(df_target)
df_result