EDA Level Test 10 ⭐️
| Week | Data Analysis | Difficulty | This Notebook |
|---|---|---|---|
| 1 | 서울시 인구 데이터 | ⭐️ | |
| 2 | 화장품 성분 데이터 | ⭐️⭐️⭐️ | |
| 3 | 올림픽 데이터 | ⭐️⭐️ | |
| 4 | 국가별 인터넷 사용률 데이터 | ⭐️⭐️ | |
| 5 | 전국 박물관/미술관 정보 표준 데이터 | ⭐️⭐️⭐️ | |
| 6 | 서울시 흡연율 통계 데이터 | ⭐️⭐️ | |
| 7 | 웹크롤링 | ⭐️ | |
| 8 | 서울시 지하철 호선별 역별 유/무임 승하차 인원 정보 데이터 | ⭐️⭐️ | |
| 9 | 서울시 교통사고 현황 (사고유형별) 통계 데이터 | ⭐️⭐️ | |
| 10 | 서울시 교통사고 현황 (사고유형별) 통계 + 서울시 차량통행속도 (구별/월별) 통계 + 서울시 인구밀도 (구별) 통계 | ⭐️⭐️⭐️ | 👈 |
문제 소개 및 데이터 준비 단계
-
총 3단계 데이터 분석 상황 제시
-
1단계: DataFrame 전처리 & 합치기
-
2단계: Data 가공
-
3단계: 원하는 정보 얻기
-
총점 100점
-
Data 원본 출처
Data01(csv): 서울시 교통사고 현황 (사고유형별) 통계
- Source: 서울 열린데이터 광장
- DownLoad: 상기 Source(서울 열린데이터 광장)에서 csv 파일 Download
- 문제 출제 이후 Data 변경될 가능성이 있으므로 문제 풀이시 하기 File Path의 Data 사용
- File Path
- 원본:
'./datas/교통사고+현황(사고유형별).csv' - 전처리 후:
'./datas/교통사고+현황(사고유형별)_preprocessing.csv'
- 원본:
- 기타
- 해당 Data는 다른 과제에서 전처리 과정을 진행하였으므로 전처리 된 csv 파일을 제공함.
- 이 과제에서는 전처리가 진행 된 csv파일을 이용할 예정.
Data02(csv):서울시 차량통행속도 (구별/월별) 통계
- Source: 서울 열린데이터 광장
- DownLoad: 상기 Source(서울 열린데이터 광장)에서 csv 파일 Download
- 문제 출제 이후 Data 변경될 가능성이 있으므로 문제 풀이시 하기 File Path의 Data 사용
- File Path:
'./datas/차량통행속도(월별_구별).csv'
Data03(csv): 서울시 인구밀도 (구별) 통계
- Source: 서울 열린데이터 광장
- DownLoad: 상기 Source(서울 열린데이터 광장)에서 csv 파일 Download
- 문제 출제 이후 Data 변경될 가능성이 있으므로 문제 풀이시 하기 File Path의 Data 사용
- File Path:
'./datas/인구밀도.csv'
참고사항
- 문제에 hint가 있을 경우, 해당 hint를 이용하지 않으셔도 무방합니다.
문제 시작! 🏃🏻
1단계: DataFrame 전처리 & 합치기
문제 1-1) DataFrame 전처리 01 - 서울시 구별/사고유형별 교통사고 현황 (5점)
-
서울시 구별/사고유형별 교통사고 현황 DataFrame을 수정하고자 합니다.
-
위 2. Datas에서 불러온 DataFrame(df_acc)을 아래 조건에 맞게 변경하세요.
-
결과 DataFrame : df_acc.iloc[:10], 모든 값에 0 입력
-
조건1: ['자치구', '사고유형', '구분']과 '2013'년부터 '2021'년까지(['2013', '2014', ..., '2020, 2021']) Column(열)의 Data만 가져와주세요.
-
조건2: 상기 조건 이외의 Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건3: 'df_acc' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_acc)를 check_01_01 함수에 입력하여 채점하세요.
# 채점을 위한 코드입니다. 반드시 실행해주세요.
from grading import *
import pandas as pd# 서울시 구별/사고유형별 교통사고 현황
df_acc = pd.read_csv('./datas/교통사고+현황(사고유형별)_preprocessing.csv')
df_acc.head()
# 1-1
years = [str(year) for year in range(2013, 2022)]
selected_cols = ['자치구', '사고유형', '구분'] + years
df_acc = df_acc[selected_cols]
df_acc
문제 1-2) DataFrame 전처리 02 - 서울시 구별 차량통행속도 (10점)
-
서울시 구별 차량통행속도 DataFrame을 수정하고자 합니다.
-
위 2. Datas에서 불러온 DataFrame(df_speed)을 아래 조건에 맞게 변경하세요.
-
결과 DataFrame 예시: df_speed.iloc[:10], 모든 값에 0 입력
-
조건1: '구분별(2)' Column(열)명을 '자치구'로 변경해 주세요.
-
조건2: '자치구' Column(열) Data 중 '소계'를 '서울시'로 변경해 주세요.
-
조건3: '구분별(1)' Column(열)을 삭제해 주세요.
-
조건4: '자치구' Column(열) Data 중 '강남', '강북'인 Row(행) Data를 삭제해 주세요.
-
조건5: '구분' Column(열)을 생성하고, 해당 Column(열)에 '차량통행속도'를 입력해주세요.
-
조건6: Column 순서는 ['자치구', '구분', '2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020', '2021'] 로 변경해주세요.
-
조건7: Index는 Reset하고, 기존 Index는 삭제(drop)해 주세요.
-
조건8: 상기 조건 이외의 Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건9: 'df_speed' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_speed)를 check_01_02 함수에 입력하여 채점하세요.
# 서울시 구별 차량통행속도
df_speed = pd.read_csv('./datas/차량통행속도(월별_구별).csv')
df_speed.head()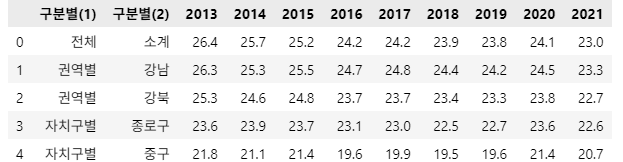
# 1-2
df_speed = df_speed.drop(columns=['구분별(1)'])
df_speed = df_speed.rename(columns={'구분별(2)': '자치구'})
df_speed['자치구'] = df_speed['자치구'].replace('소계', '서울시')
df_speed = df_speed[~df_speed['자치구'].isin(['강남', '강북'])]
df_speed['구분'] = '차량통행속도'
ordered_columns = ['자치구', '구분'] + [str(y) for y in range(2013, 2022)]
df_speed = df_speed[ordered_columns]
df_speed = df_speed.reset_index(drop=True)
df_speed.head()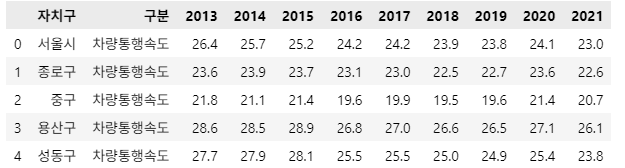
문제 1-3) DataFrame 전처리 03 - 서울시 구별 인구밀도 (10점)
-
서울시 구별 인구밀도 DataFrame을 수정하고자 합니다.
-
위 2. Datas에서 불러온 DataFrame(df_density)을 아래 조건에 맞게 변경하세요.
-
결과 DataFrame 예시: df_density.iloc[:10], 모든 값에 0 입력
-
조건1: '동별(2)' Column(열)명을 '자치구'로 변경해 주세요.
-
조건2: '자치구' Column(열) Data 중 '소계'를 '서울시'로 변경해 주세요.
-
조건3: '동별(1)' Column(열)을 삭제해 주세요.
-
조건4: Column(열)명 중 '.1', '.2'가 있는 Column(명)에서 '.1', '.2'를 삭제해주세요.
- 예시: '2013.1', '2013.2' -> '2013', '2013'
-
조건5: '구분' Column(열)을 생성하고, 해당 Column(열)에 각 Data에 맞추어 '인구', '면적', '인구밀도' 중 하나를 입력해주세요.
- 다시말해 0번 Index의 Row(행) Data를 일부 변경(괄호 및 괄호내용 제거, 공백(띄어쓰기 등) 제거하고 '구분' Column(열)에 입력하고, 이에 맞추어 같은 연도의 Data를 하나의 Column(행)으로 나타내주세요.
- 아래 예시를 참고해주세요.
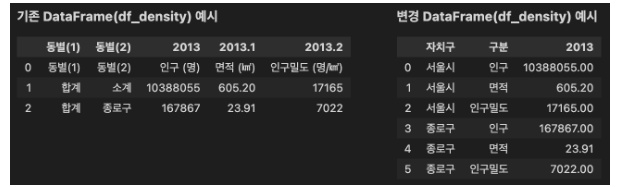
-
조건6: ['자치구', '구분']과 '2013'년부터 '2021'년까지(['2013', '2014', ..., '2020, 2021']) Column(열)의 Data만 가져와주세요.
-
조건7: Column 순서는 ['자치구', '구분', '2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020', '2021'] 로 변경해주세요.
-
조건8: 숫자 Data의 Type은 float으로 변경해주세요.
- 단, Column(열)명의 Data Type은 str입니다.
-
조건9: Index는 Reset하고, 기존 Index는 삭제(drop)해 주세요.
-
조건10: 상기 조건 이외의 Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건11: 'df_density' 변수에 결과 DataFrame을 할당하세요.
-
참고: 해당 DataFrame의 단위는 다음과 같습니다.
- 인구: 명
- 면적: ㎢
- 인구밀도: 명/㎢
-
-
완료 후 결과 DataFrame 변수(df_density)를 check_01_03 함수에 입력하여 채점하세요.
# 서울시 구별 인구밀도(단위: 인구(명) / 면적(㎢) / 인구밀도(명/㎢))
df_density = pd.read_csv('./datas/인구밀도.csv')
df_density.head() 
# 1-3
df_density = df_density.drop(columns=['동별(1)'])
df_density = df_density.rename(columns={'동별(2)': '자치구'})
df_density['자치구'] = df_density['자치구'].replace('소계', '서울시')
df_density.columns = df_density.columns.str.replace(r'\.\d+', '', regex=True)
unit_row = df_density.iloc[0]
unit_row = unit_row.str.replace(r'\s*\(.*?\)', '', regex=True).str.strip()
df_density = df_density[1:].reset_index(drop=True)
new_columns = []
for col, unit in zip(df_density.columns, unit_row):
if col == '자치구':
new_columns.append('자치구')
else:
new_columns.append(f"{col}_{unit}")
df_density.columns = new_columns
df_melted = df_density.melt(id_vars='자치구', var_name='연도_구분', value_name='값')
df_melted[['연도', '구분']] = df_melted['연도_구분'].str.extract(r'(\d{4})_(.*)')
df_melted = df_melted.drop(columns='연도_구분')
gu_order = df_density['자치구'].unique().tolist()
category_order = ['인구', '면적', '인구밀도']
df_density = df_melted.pivot_table(index=['자치구', '구분'], columns='연도', values='값', aggfunc='first').reset_index()
years = [str(y) for y in range(2013, 2022)]
df_density = df_density[['자치구', '구분'] + years]
df_density[years] = df_density[years].apply(pd.to_numeric, errors='coerce')
df_density['구분'] = pd.Categorical(df_density['구분'], categories=category_order, ordered=True)
df_density['자치구'] = pd.Categorical(df_density['자치구'], categories=gu_order, ordered=True)
df_density = df_density.sort_values(by=['자치구', '구분']).reset_index(drop=True)
df_density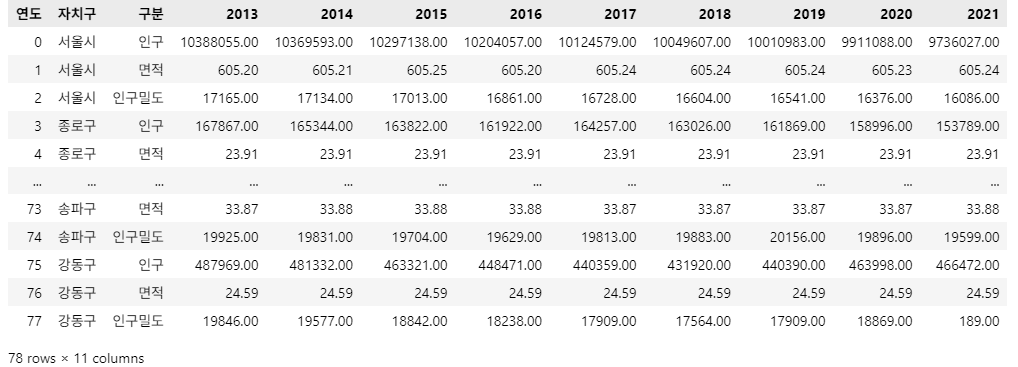
문제 1-4) DataFrame 합치기 - 서울시 구별/사고유형별 교통사고 현황 + 차량통행속도 + 인구밀도 (15점)
-
3개의 DataFrame을 합치고자 합니다.
-
위 1-1, 1-2, 1-3에서 구한 DataFrame(df_acc, df_speed, df_density)을 아래 조건에 맞게 합쳐주세요.
-
결과 DataFrame 예시: df_target.iloc[:20], 모든 값에 0 입력
-
조건1: df_acc, df_speed, df_density 3개의 DataFrame을 Column(행) 방향으로 합쳐주세요.
- 합친 결과 Column(열)은 위 예시의 Column(열)과 같고, Index(Row(행)의 수)가 증가해야 합니다.
-
조건2: '구분' Column(열) Data가 '차량통행속도', '인구', '면적', '인구밀도'인 경우 Null값인 '사고현황' Colmn(열) 값에 '-'를 입력해 주세요.
-
조건3: DataFrame을 정렬하고자 합니다.
- 아래 셀의 gu_list, cat_list, type_list를 참고해주세요.
- '자치구' Column(열)은 gu_list 순서 그대로 정렬해주세요.
- '구분' Column(열)은 cat_list 순서 그대로 정렬해주세요.
- '사고유형' Column(열)은 type_list 순서 그대로 정렬해주세요.
- 정렬 우선순위는 '자치구' Column(열)이 우선이고, '자치구' Column(열)이 같다면 '사고유형' Column(열), '사고유형' Column(열)이 같다면 '구분' Column(열) 순서로 정렬해주세요.
- 위의 결과 DataFrame 예시를 참고해주세요.
-
조건4: Column 순서는 ['자치구', '사고유형', '구분', '2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020', '2021']로 해주세요.
-
조건5: 숫자 Data의 Type은 float이어야 합니댜.
- 단, Column(열)명의 Data Type은 str입니다.
-
조건6: Index는 Reset하고, 기존 Index는 삭제(drop)해 주세요.
-
조건7: 상기 조건 이외의 Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건8: 'df_target' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_target)를 check_01_04 함수에 입력하여 채점하세요.
# 1-4
gu_list = ['서울시', '종로구', '중구', '용산구', '성동구', '광진구', '동대문구', '중랑구', '성북구',
'강북구', '도봉구', '노원구', '은평구', '서대문구', '마포구', '양천구', '강서구', '구로구',
'금천구', '영등포구', '동작구', '관악구', '서초구', '강남구', '송파구', '강동구']
cat_list = ['발생건수', '사망자수', '부상자수', '차량통행속도', '인구', '면적', '인구밀도']
type_list = ['합계', '차대사람', '차대차', '차량단독', '건널목', '-']
df_speed['사고유형'] = '-'
df_density['사고유형'] = '-'
columns = ['자치구', '사고유형', '구분'] + [str(year) for year in range(2013, 2022)]
df_speed = df_speed[columns]
df_density = df_density[columns]
df_acc = df_acc[columns]
df_combined = pd.concat([df_acc, df_speed, df_density], axis=0, ignore_index=True)
df_combined['자치구'] = pd.Categorical(df_combined['자치구'], categories=gu_list, ordered=True)
df_combined['구분'] = pd.Categorical(df_combined['구분'], categories=cat_list, ordered=True)
df_combined['사고유형'] = pd.Categorical(df_combined['사고유형'], categories=type_list, ordered=True)
df_combined = df_combined.sort_values(by=['자치구', '사고유형', '구분']).reset_index(drop=True)
for year in range(2013, 2022):
df_combined[str(year)] = pd.to_numeric(df_combined[str(year)], errors='coerce')
df_target = df_combined.copy()
df_target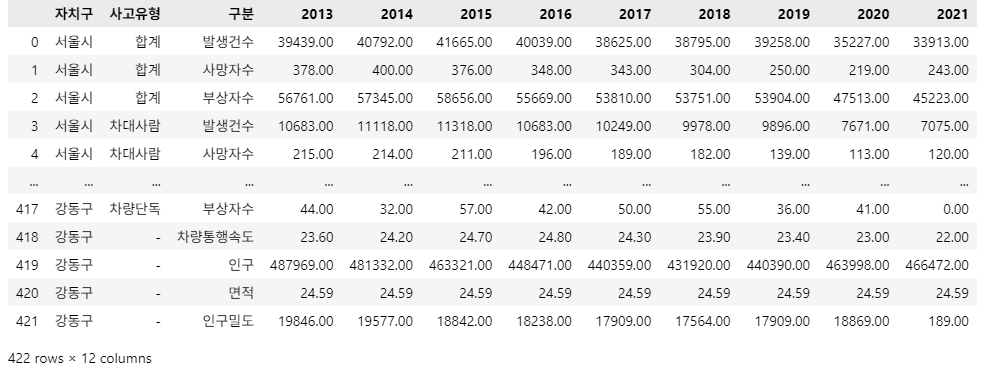
2단계: Data 가공
문제 2-1) DataFrame 가공 01 - 종로구의 교통사고율 구하기 (20점)
-
'종로구'의 인구 10만명당 사고율 / 인구밀도당 사고율 / 차량통행속도당 사고율을 구하고자 합니다.
-
위 1단계에서 구한 DataFrame(df_target)을 이용하여 아래 조건에 맞는 DataFrame을 만들어 주세요.
-
결과 DataFrame 예시: df_result, 모든 값에 0 입력
-
조건1: '자치구' Column(열) Data 중 '종로구'가 대상입니다.
-
조건2: 모든 숫자 Data는 소숫점 세번째자 자리에서 반올림하여 두번째 자리까지 표시하고, Type은 float으로 해주세요.
-
조건3: 각 연도의 '인구 만명당 교통사고율'을 구하세요.
- 인구 만명당 교통사고율: 각 사고유형(합계/차대사람/차대차/차량단독/건널목)별 '인구 만명당 발생건수', '인구 만명당 사망자수', '인구 만명당 부상자수'
- '사고유형' Column(열)에는 각 Row(행)에 맞는 '합계', '차대사람', '차대차', '차량단독', '건널목' 중 하나를 입력하세요.
- '구분' Column(열)에는 각 Row(행)에 맞는 '인구 만명당 발생건수', '인구 만명당 사망자수', '인구 만명당 부상자수' 중 하나를 입력하세요.
- 수식은 아래 예시를 참고하세요.
- 예시: '자치구' Column(열) Data 중 '용산구'의 '인구 만명당 교통사고율'

-
조건4: 각 연도의 '인구밀도당 교통사고율'을 구하세요.
- 인구밀도당 교통사고율: 각 사고유형(합계/차대사람/차대차/차량단독/건널목)별 '인구밀도당 발생건수', '인구밀도당 사망자수', '인구밀도당 부상자수'
- '사고유형' Column(열)에는 각 Row(행)에 맞는 '합계', '차대사람', '차대차', '차량단독', '건널목' 중 하나를 입력하세요.
- '구분' Column(열)에는 각 Row(행)에 맞는 '인구밀도당 발생건수', '인구밀도당 사망자수', '인구밀도당 부상자수' 중 하나를 입력하세요.
- 수식은 아래 예시를 참고하세요.
- 예시: '자치구' Column(열) Data 중 '용산구'의 '인구밀도당 교통사고율'

-
조건5: 각 연도의 '차량통행속도당 교통사고율'을 구하세요.
- 차량통행속도당 교통사고율: 각 사고유형(합계/차대사람/차대차/차량단독/건널목)별 '차량통행속도당 발생건수', '차량통행속도당 사망자수', '차량통행속도당 부상자수'
- '사고유형' Column(열)에는 각 Row(행)에 맞는 '합계', '차대사람', '차대차', '차량단독', '건널목' 중 하나를 입력하세요.
- '구분' Column(열)에는 각 Row(행)에 맞는 '차량통행속도당 발생건수', '차량통행속도당 사망자수', '차량통행속도당 부상자수' 중 하나를 입력하세요.
- 수식은 아래 예시를 참고하세요.
- 예시: '자치구' Column(열) Data 중 '용산구'의 '차량통행속도당 교통사고율'

-
조건6: 조건3, 조건4, 조건5에서 구한 3개의 DataFrame을 Column(행) 방향으로 합쳐주세요.
- 합친 결과 Column(열)은 위 예시의 Column(열)과 같고, Index(Row(행)의 수)가 증가해야 합니다.
-
조건7: DataFrame을 정렬하고자 합니다.
- 아래 셀의 cat_list, type_list를 참고해주세요.
- '구분' Column(열)은 cat_list 순서 그대로 정렬해주세요.
- '사고유형' Column(열)은 type_list 순서 그대로 정렬해주세요.
- 정렬 우선순위는 '사고유형' Column(열)이 우선이고, '사고유형' Column(열)이 같다면 '구분' Column(열) 순서로 정렬해주세요.
- 위의 결과 DataFrame 예시를 참고해주세요.
-
조건8: Column 순서는 ['자치구', '사고유형', '구분', '2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020', '2021']로 해주세요.
-
조건9: 숫자 Data의 Type은 float이어야 합니댜.
- 단, Column(열)명의 Data Type은 str입니다. -
조건10: Index는 Reset하고, 기존 Index는 삭제(drop)해 주세요.
-
조건11: 상기 조건 이외의 Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건12: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_result)를 check_02_01 함수에 입력하여 채점하세요.
# 2-1
cat_list = ['인구 만명당 발생건수', '인구 만명당 사망자수', '인구 만명당 부상자수', '인구밀도당 부상자수',
'인구밀도당 사망자수', '인구밀도당 발생건수', '차량통행속도당 사망자수', '차량통행속도당 발생건수',
'차량통행속도당 부상자수']
type_list = ['합계', '차대사람', '차대차', '차량단독']
years = [str(y) for y in range(2013, 2022)]
acc_jongro = df_target[(df_target['자치구'] == '종로구') & (df_target['구분'].isin(['발생건수', '사망자수', '부상자수']))].copy()
pop_jongro = df_target[(df_target['자치구'] == '종로구') & (df_target['구분'] == '인구')].iloc[0, 3:]
den_jongro = df_target[(df_target['자치구'] == '종로구') & (df_target['구분'] == '인구밀도')].iloc[0, 3:]
spd_jongro = df_target[(df_target['자치구'] == '종로구') & (df_target['구분'] == '차량통행속도')].iloc[0, 3:]
def compute_rate(df, divisor, prefix):
result = df.copy()
for year in years:
result[year] = df[year].astype(float) / divisor[year].astype(float)
if prefix == '인구 만명당':
result[year] *= 10000
result['구분'] = prefix + ' ' + result['구분'].astype(str)
return result
acc_pop_rate = compute_rate(acc_jongro, pop_jongro, '인구 만명당')
acc_den_rate = compute_rate(acc_jongro, den_jongro, '인구밀도당')
acc_spd_rate = compute_rate(acc_jongro, spd_jongro, '차량통행속도당')
df_result = pd.concat([acc_pop_rate, acc_den_rate, acc_spd_rate], axis=0)
df_result['구분'] = pd.Categorical(df_result['구분'], categories=cat_list, ordered=True)
df_result['사고유형'] = pd.Categorical(df_result['사고유형'], categories=type_list, ordered=True)
df_result = df_result.sort_values(by=['사고유형', '구분']).reset_index(drop=True)
df_result[years] = df_result[years].astype(float).round(2)
df_result = df_result[['자치구', '사고유형', '구분'] + years]
df_result.head(10)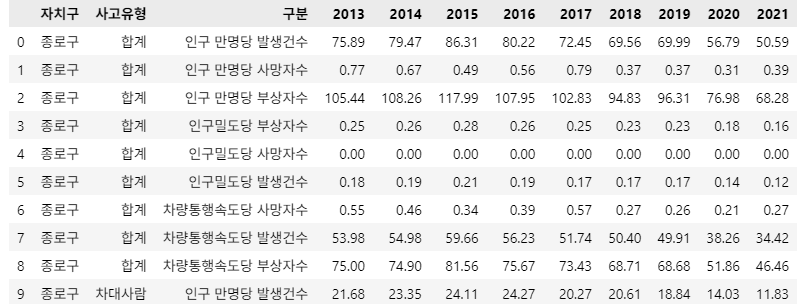
문제 2-2) DataFrame 가공 02 - 각 구의 교통사고율 구하기 (20점)
-
각 자치구의 인구 10만명당 사고율 / 인구밀도당 사고율 / 차량통행속도당 사고율을 구하고자 합니다.
-
위 2-1에서 만든 DataFrame을 참고하고, 위 1단계에서 구한 DataFrame(df_target)을 이용하여 아래 조건에 맞는 DataFrame을 만들어 주세요.
-
결과 DataFrame 예시: df_result.iloc[:50], 모든 값에 0 입력
-
조건1: '자치구' Column(열) Data 전체가 대상입니다.
-
조건2: 모든 숫자 Data는 소숫점 세번째자 자리에서 반올림하여 두번째 자리까지 표시하고, Type은 float으로 해주세요.
-
조건3: 각 연도의 '인구 만명당 교통사고율'을 구하세요.
- 인구 만명당 교통사고율: 각 사고유형(합계/차대사람/차대차/차량단독/건널목)별 '인구 만명당 발생건수', '인구 만명당 사망자수', '인구 만명당 부상자수'
- '사고유형' Column(열)에는 각 Row(행)에 맞는 '합계', '차대사람', '차대차', '차량단독', '건널목' 중 하나를 입력하세요.
- '구분' Column(열)에는 각 Row(행)에 맞는 '인구 만명당 발생건수', '인구 만명당 사망자수', '인구 만명당 부상자수' 중 하나를 입력하세요.
- 수식은 아래 예시를 참고하세요.
- 예시: '자치구' Column(열) Data 중 '서울시'의 '인구 만명당 교통사고율'

-
조건4: 각 연도의 '인구밀도당 교통사고율'을 구하세요.
- 인구밀도당 교통사고율: 각 사고유형(합계/차대사람/차대차/차량단독/건널목)별 '인구밀도당 발생건수', '인구밀도당 사망자수', '인구밀도당 부상자수'
- '사고유형' Column(열)에는 각 Row(행)에 맞는 '합계', '차대사람', '차대차', '차량단독', '건널목' 중 하나를 입력하세요.
- '구분' Column(열)에는 각 Row(행)에 맞는 '인구밀도당 발생건수', '인구밀도당 사망자수', '인구밀도당 부상자수' 중 하나를 입력하세요.
- 수식은 아래 예시를 참고하세요.
- 예시: '자치구' Column(열) Data 중 '서울시'의 '인구밀도당 교통사고율'

-
조건5: 각 연도의 '차량통행속도당 교통사고율'을 구하세요.
- 차량통행속도당 교통사고율: 각 사고유형(합계/차대사람/차대차/차량단독/건널목)별 '차량통행속도당 발생건수', '차량통행속도당 사망자수', '차량통행속도당 부상자수'
- '사고유형' Column(열)에는 각 Row(행)에 맞는 '합계', '차대사람', '차대차', '차량단독', '건널목' 중 하나를 입력하세요.
- '구분' Column(열)에는 각 Row(행)에 맞는 '차량통행속도당 발생건수', '차량통행속도당 사망자수', '차량통행속도당 부상자수' 중 하나를 입력하세요.
- 수식은 아래 예시를 참고하세요.
- 예시: '자치구' Column(열) Data 중 '서울시'의 '차량통행속도당 교통사고율'

-
조건6: 조건3, 조건4, 조건5에서 구한 3개의 DataFrame을 Column(행) 방향으로 합쳐주세요.
- 합친 결과 Column(열)은 위 예시의 Column(열)과 같고, Index(Row(행)의 수)가 증가해야 합니다.
-
조건7: DataFrame을 정렬하고자 합니다.
- 아래 셀의 gu_list, cat_list, type_list를 참고해주세요.
- '자치구' Column(열)은 gu_list 순서 그대로 정렬해주세요.
- '구분' Column(열)은 cat_list 순서 그대로 정렬해주세요.
- '사고유형' Column(열)은 type_list 순서 그대로 정렬해주세요.
- 정렬 우선순위는 '자치구' Column(열)이 우선이고, '자치구' Column(열)이 같다면 '사고유형' Column(열), '사고유형' Column(열)이 같다면 '구분' Column(열) 순서로 정렬해주세요.
- 위의 결과 DataFrame 예시를 참고해주세요.
-
조건8: Column 순서는 ['자치구', '사고유형', '구분', '2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020', '2021']로 해주세요.
-
조건9: 숫자 Data의 Type은 float이어야 합니댜.
- 단, Column(열)명의 Data Type은 str입니다.
-
조건10: Index는 Reset하고, 기존 Index는 삭제(drop)해 주세요.
-
조건11: 상기 조건 이외의 Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건12: 'df_result' 변수에 결과 DataFrame을 할당하세요.
-
참고: 문제 2-1과는 결과 DataFrame 예시, 조건3~5의 예시, 조건1, 조건7만 다릅니다.
-
-
완료 후 결과 DataFrame 변수(df_result)를 check_02_02 함수에 입력하여 채점하세요.
# 2-2
gu_list = ['서울시', '종로구', '중구', '용산구', '성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구',
'도봉구', '노원구', '은평구', '서대문구', '마포구', '양천구', '강서구', '구로구', '금천구', '영등포구',
'동작구', '관악구', '서초구', '강남구', '송파구', '강동구']
cat_list = ['인구 만명당 발생건수', '인구 만명당 사망자수', '인구 만명당 부상자수',
'인구밀도당 발생건수', '인구밀도당 사망자수', '인구밀도당 부상자수',
'차량통행속도당 발생건수', '차량통행속도당 사망자수', '차량통행속도당 부상자수']
type_list = ['합계', '차대사람', '차대차', '차량단독', '건널목']
years = [str(y) for y in range(2013, 2022)]
def compute_rate(df, divisor, prefix):
result = df.copy()
for year in years:
result[year] = df[year].astype(float) / divisor[year].astype(float)
if prefix == '인구 만명당':
result[year] *= 10000
result['구분'] = prefix + ' ' + result['구분'].astype(str)
return result
acc_pop_rates = []
acc_den_rates = []
acc_spd_rates = []
for gu in gu_list:
acc_gu = df_target[(df_target['자치구'] == gu) & (df_target['구분'].isin(['발생건수', '사망자수', '부상자수']))].copy()
pop_gu = df_target[(df_target['자치구'] == gu) & (df_target['구분'] == '인구')].iloc[0, 3:]
den_gu = df_target[(df_target['자치구'] == gu) & (df_target['구분'] == '인구밀도')].iloc[0, 3:]
spd_gu = df_target[(df_target['자치구'] == gu) & (df_target['구분'] == '차량통행속도')].iloc[0, 3:]
acc_pop_rate = compute_rate(acc_gu, pop_gu, '인구 만명당')
acc_den_rate = compute_rate(acc_gu, den_gu, '인구밀도당')
acc_spd_rate = compute_rate(acc_gu, spd_gu, '차량통행속도당')
acc_pop_rates.append(acc_pop_rate)
acc_den_rates.append(acc_den_rate)
acc_spd_rates.append(acc_spd_rate)
df_result = pd.concat(acc_pop_rates + acc_den_rates + acc_spd_rates, axis=0)
df_result['구분'] = pd.Categorical(df_result['구분'], categories=cat_list, ordered=True)
df_result['사고유형'] = pd.Categorical(df_result['사고유형'], categories=type_list, ordered=True)
df_result = df_result.sort_values(by=['자치구', '사고유형', '구분']).reset_index(drop=True)
df_result[years] = df_result[years].astype(float).round(2)
df_result = df_result[['자치구', '사고유형', '구분'] + years]
df_result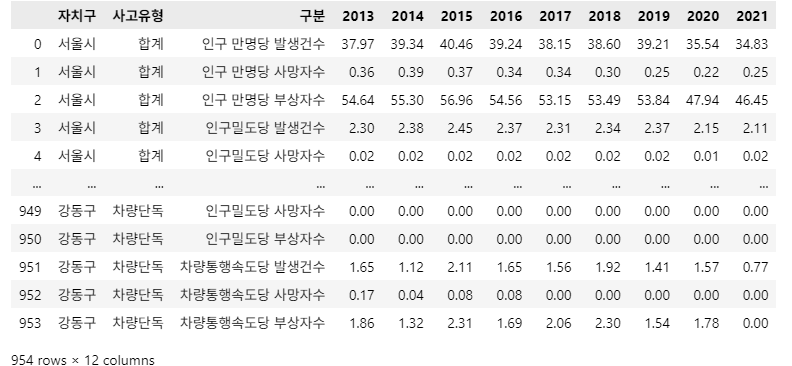
3단계: 원하는 정보 얻기
문제 3) 원하는 정보 얻기 - 연도별 최대값 구하기 (20점)
-
'사고유형'이 '합계'인 Data 중에서, 각 '구분'별 및 '연도'별로 값이 최대인 자치구/값을 구하고자 합니다.
-
위 2-2에서 만든 DataFrame(df_result)을 이용하여 아래 조건에 맞는 DataFrame을 만들어 주세요.
-
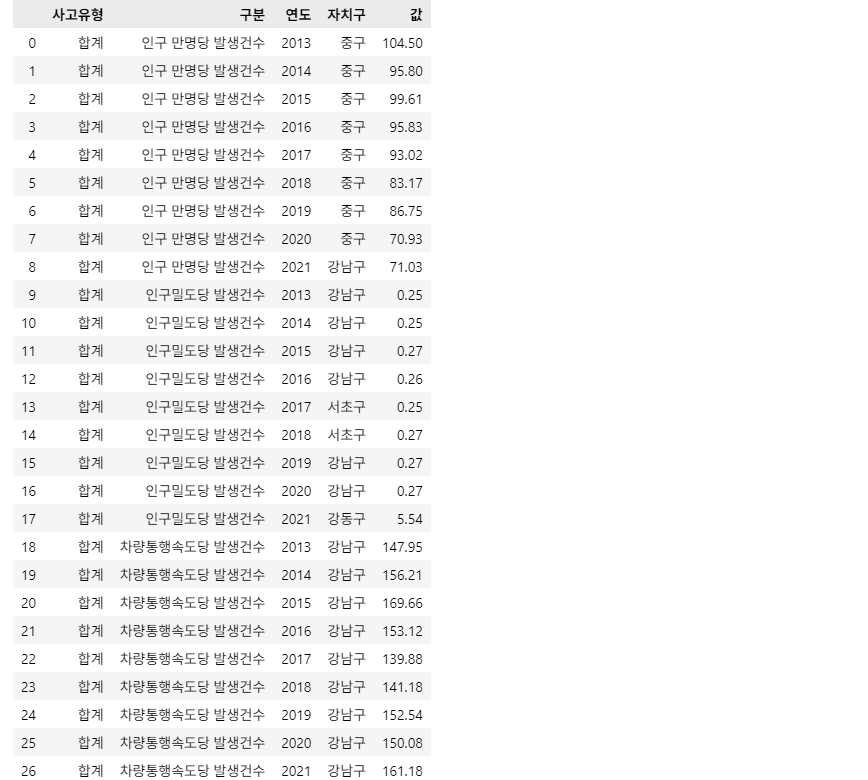
결과 DataFrame 예시: df_answer, '자치구'에 '**구' - '값'에 0 입력

-
조건1: '사고유형' Column(열) Data 중 '합계'가 대상입니다.
-
조건2: 결과 DataFrame의 Column(열)은 ['사고유형', '구분', '연도', '자치구', '값'] 입니다.
- 위의 결과 DataFrame 예시 및 아래 셀의 columns를 참고하세요.
-
조건3: 결과 DataFrame의 '구분' Column(열) Data는 ['인구 만명당 발생건수', '인구밀도당 발생건수', '차량통행속도당 발생건수'] 중 하나를 입력하세요.
- 위의 결과 DataFrame 예시 및 아래 셀의 cat_list를 참고하세요.
-
조건4: 결과 DataFrame의 '연도' Column(열)에는 ['2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020', '2021'] 중 하나를 입력하세요.
- 위의 결과 DataFrame 예시 및 아래 셀의 cat_list를 참고하세요.
-
조건5: 결과 DataFrame의 '자치구' 및 '값' Column(열)에는 해당 Row(행)의 '사고유형'(='합계'), '구분', '연도'의 최대값인 '자치구' 및 해당 '값'을 입력하세요.
- 단, '자치구' Column(열)의 Data 중 '서울시'는 제외하세요.
- 예시
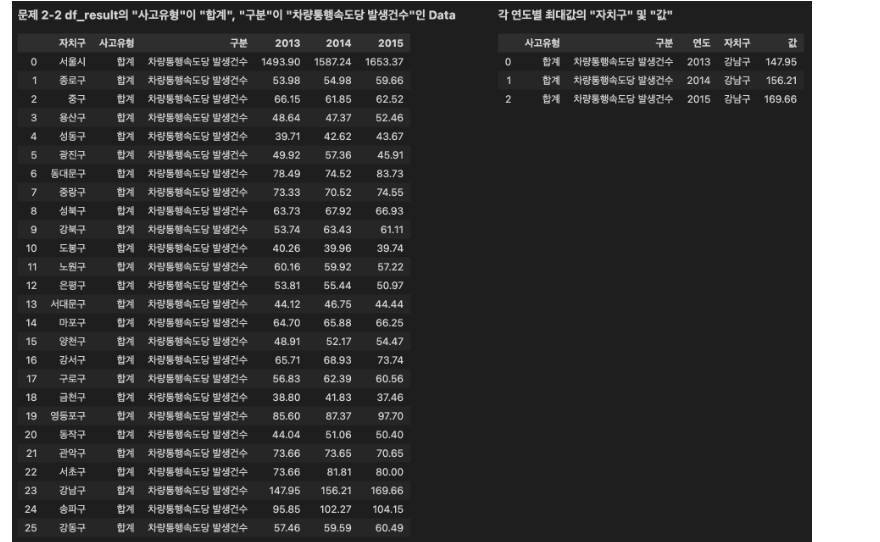
-
조건6: DataFrame을 정렬하고자 합니다.
- 아래 셀의 cat_list를 참고해주세요.
- '구분' Column(열)은 cat_list 순서 그대로 정렬해주세요.
- '연도' Column(열)은 오름차순으로 정렬해주세요.
- 정렬 우선순위는 '구분' Column(열)이 우선이고, '구분' Column(열)이 같다면 '연도' Column(열) 순서로 정렬해주세요.
- 위의 결과 DataFrame 예시를 참고해주세요.
-
조건7: '연도' Column(열) Data의 Type은 str, '값' Column(열) Data의 Type은 float이어야 합니댜.
-
조건10: Index는 Reset하고, 기존 Index는 삭제(drop)해 주세요.
-
조건11: 상기 조건 이외의 Index, Column 순서 또는 Data 순서(정렬)는 변경하지 마세요.
-
조건12: 'df_answer' 변수에 결과 DataFrame을 할당하세요.
-
-
완료 후 결과 DataFrame 변수(df_answer)를 check_03 함수에 입력하여 채점하세요.
# 3
columns = ['사고유형', '구분', '연도', '자치구', '값']
cat_list = ['인구 만명당 발생건수', '인구밀도당 발생건수', '차량통행속도당 발생건수']
years = [str(y) for y in range(2013, 2022)]
df_filtered = df_result[(df_result['사고유형'] == '합계') & (df_result['자치구'] != '서울시')]
df_filtered = df_filtered[df_filtered['구분'].isin(cat_list)]
max_rows = []
for cat in cat_list:
df_cat = df_filtered[df_filtered['구분'] == cat]
for year in years:
max_val = df_cat[year].max()
max_gu = df_cat[df_cat[year] == max_val]['자치구'].values[0]
max_rows.append(['합계', cat, year, max_gu, float(round(max_val, 2))])
df_answer = pd.DataFrame(max_rows, columns=columns)
df_answer['구분'] = pd.Categorical(df_answer['구분'], categories=cat_list, ordered=True)
df_answer['연도'] = df_answer['연도'].astype(str)
df_answer.sort_values(by=['구분', '연도'], inplace=True)
df_answer.reset_index(drop=True, inplace=True)
df_answer