Pandas란?
Python에서 R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈로 단일 프로세스에서는 최대 효율을 가지고 있다.
코딩이 가능하고 응용 가능한 엑셀로 받아들여도 무관해 누군가는 스테로이드를 맞은 엑셀이란 표현을 하기도 한다.
Pandas가 인기있는 이유
- 간편한 문법 (낮은 진입장벽)
- 다양한 기능
- 뛰어난 성능 (대용량 데이터 처리 가능)
- 다양한 포맷/데이터베이스와 연동 지원
- 지속적인 개선, 업데이트
Pandas의 데이터 구조
-
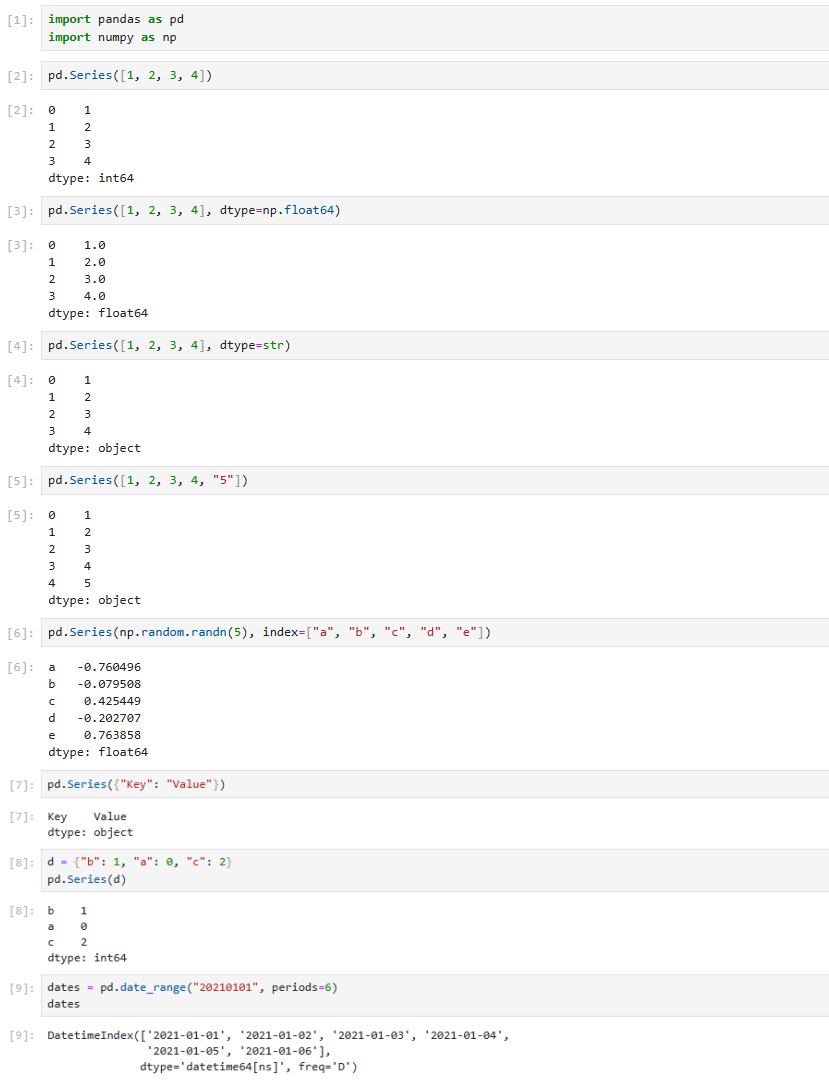
Series
- 모든 데이터를 보유할 수 있는 1차원 레이블이 지정된 배열
- s = pd.Series(data, index=index)
- index와 value로 이루어져 있다
- 한 가지 데이터 타입만 가질 수 있다
-
DataFrame
- 다음과 같은 열을 가진 레이블이 지정된 2차원 데이터 구조- Dict of 1D ndarrays, lists, dicts, Series,
- 2D numpy.ndarray,
- Structured or record ndarray,
- A Series,
- Another DataFrame)
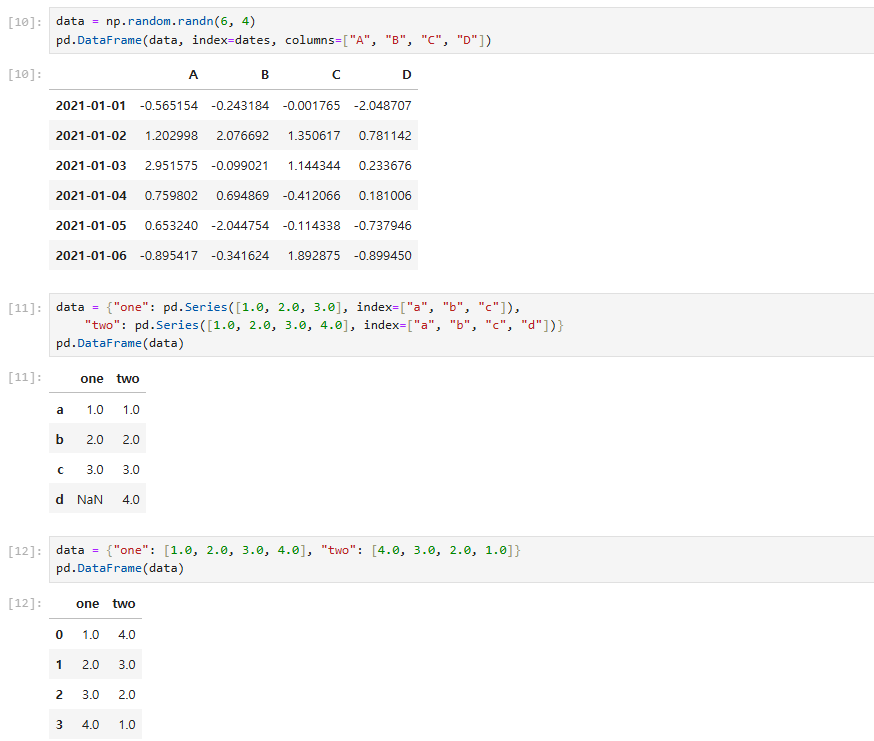
데이터 프레임 정보 탐색
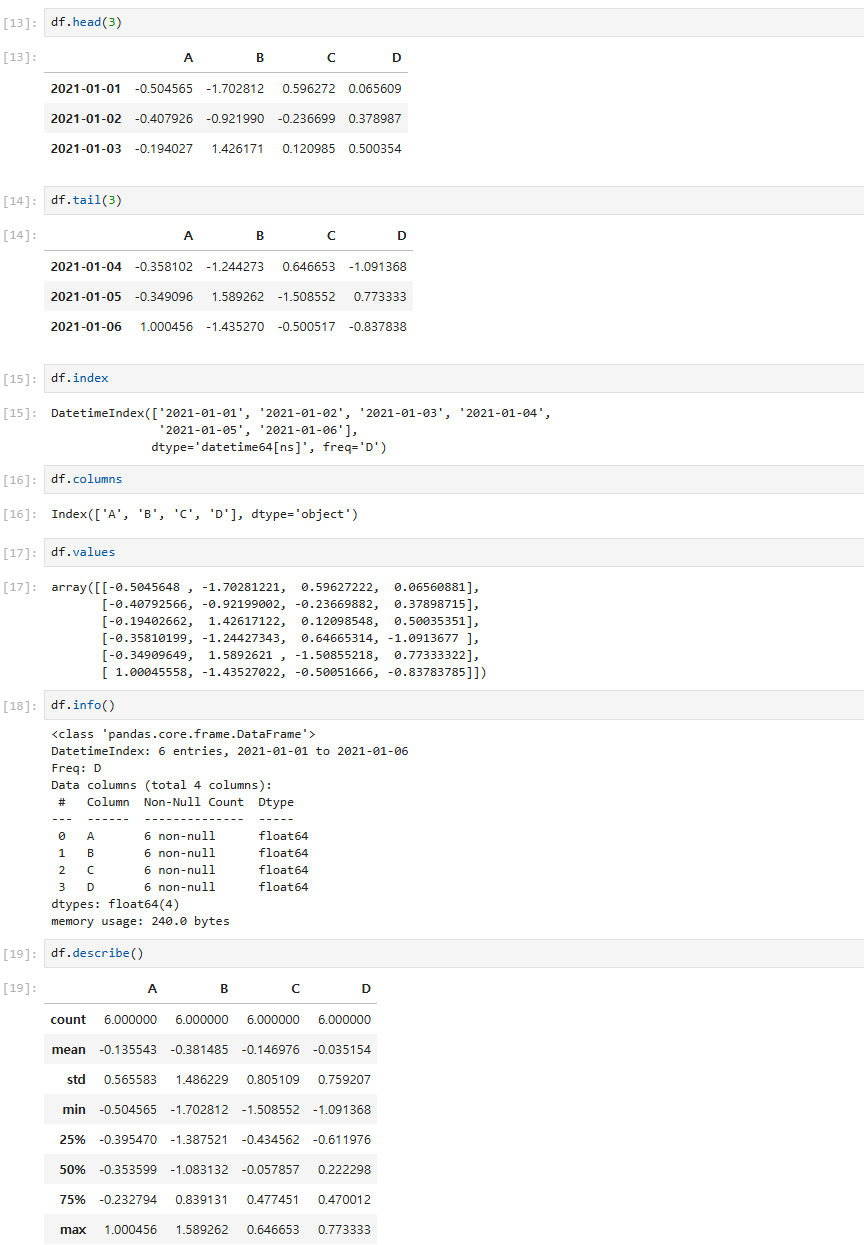
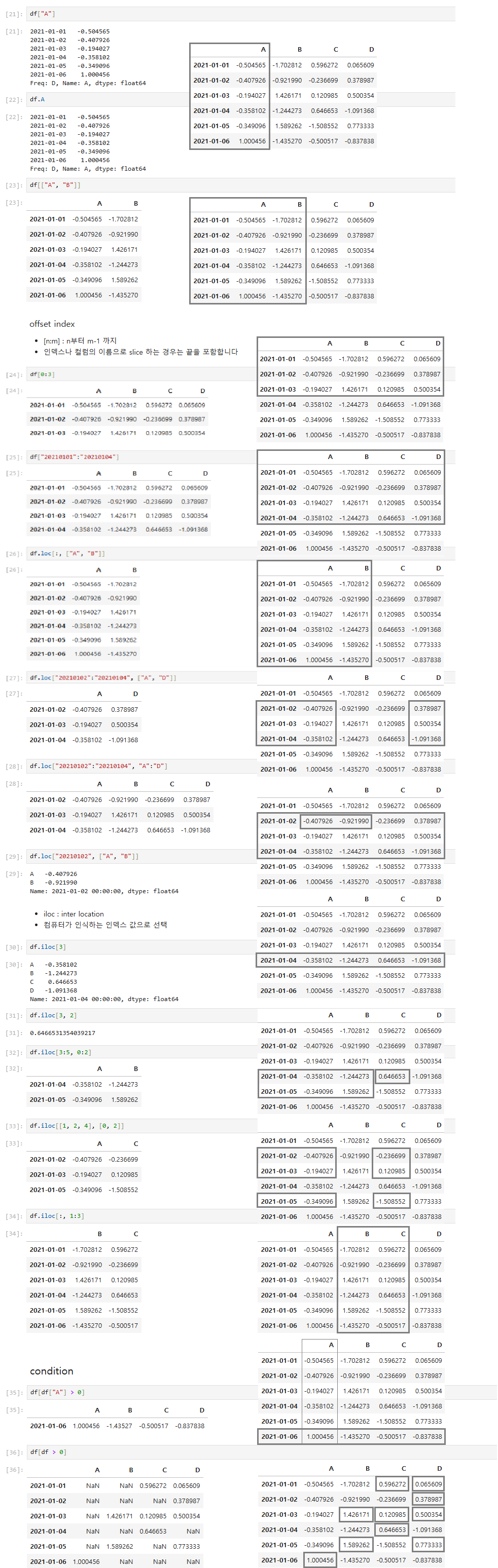
데이터 선택
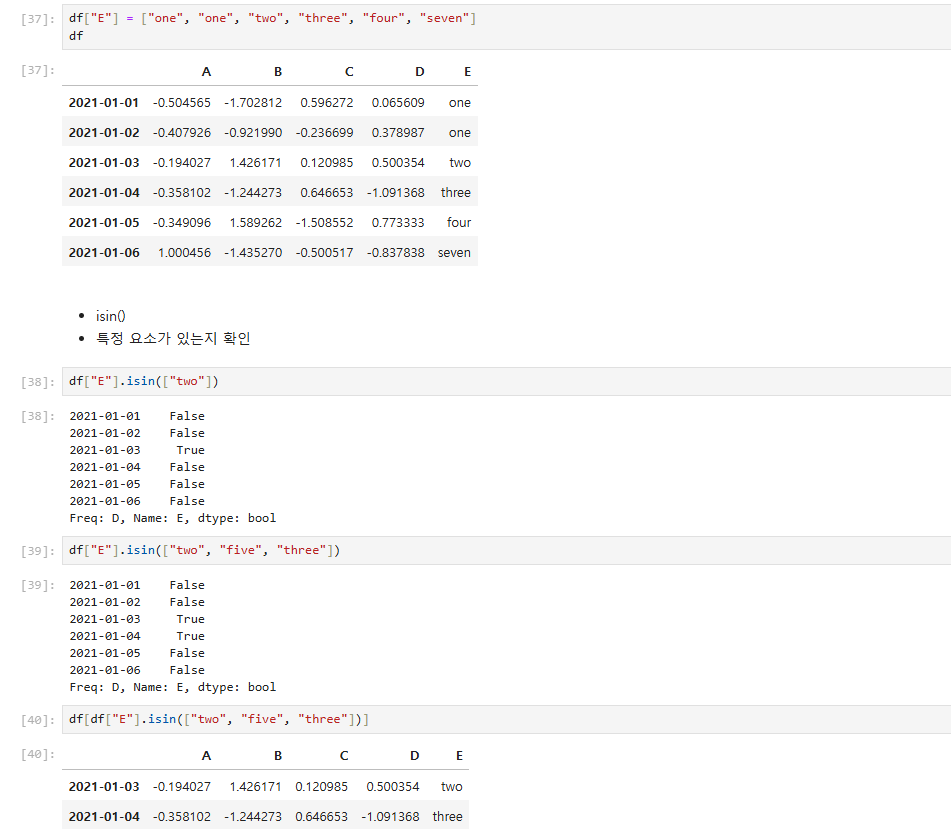
컬럼 추가
- 기존 컬럼이 없으면 추가
- 기존 컬럼이 있으면 수정
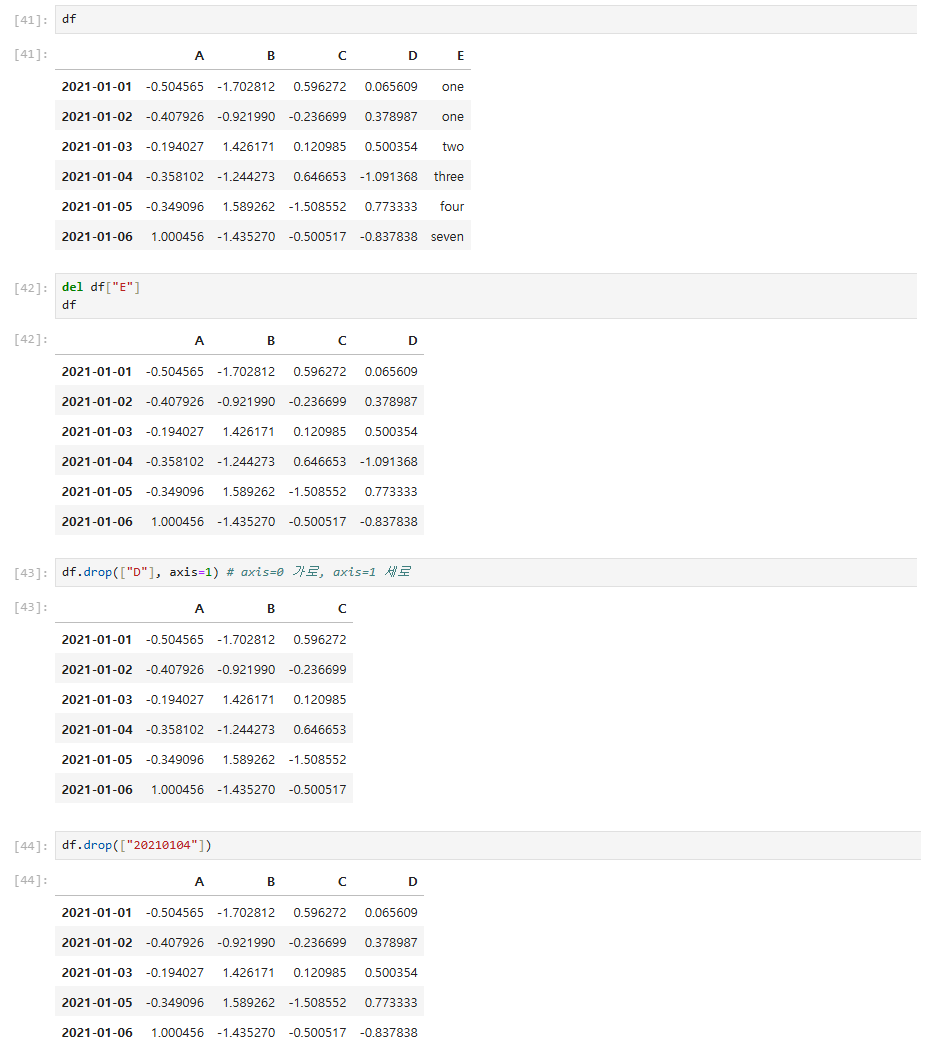
특정 컬럼 제거
- del
- drop
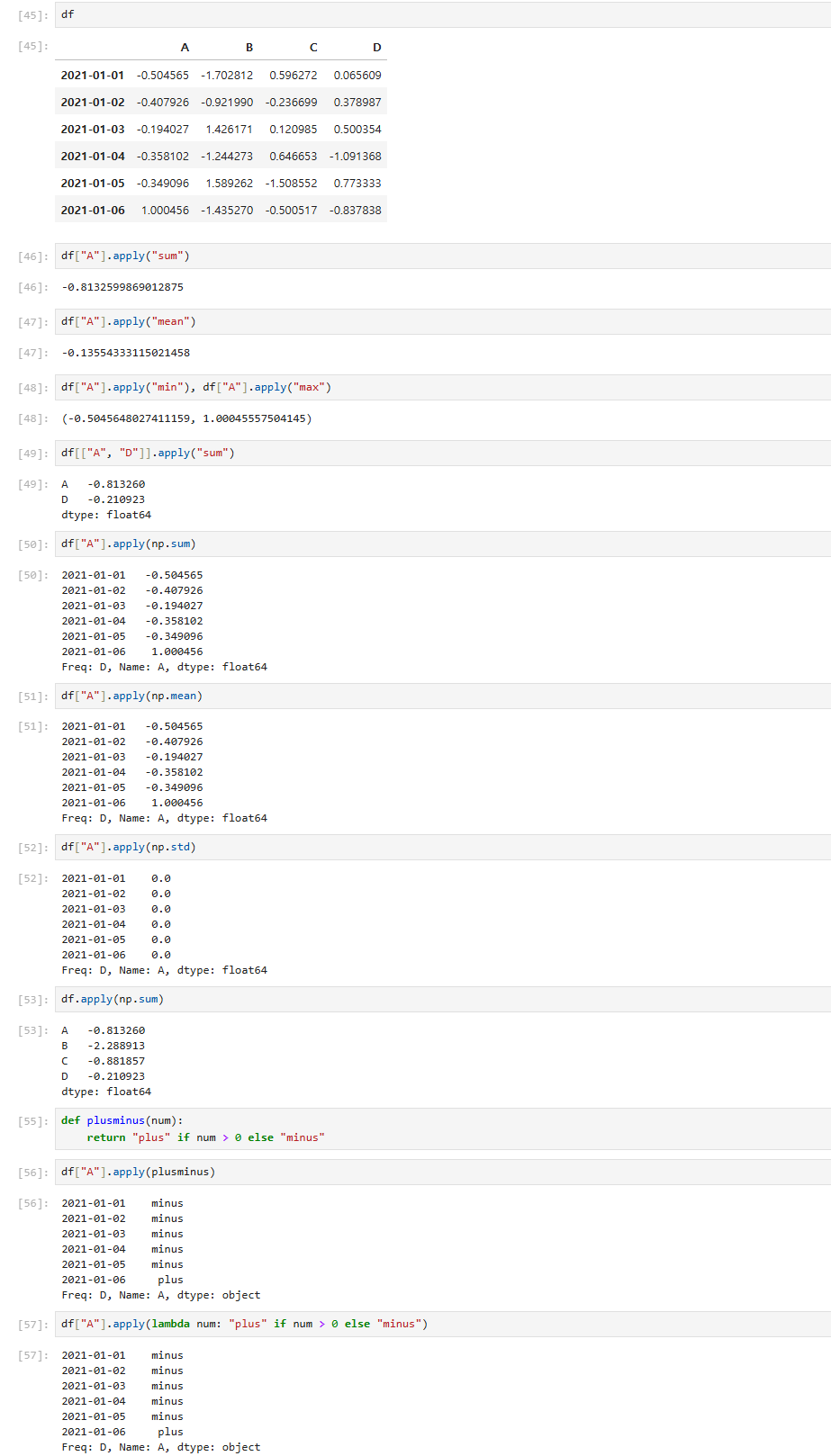
apply()
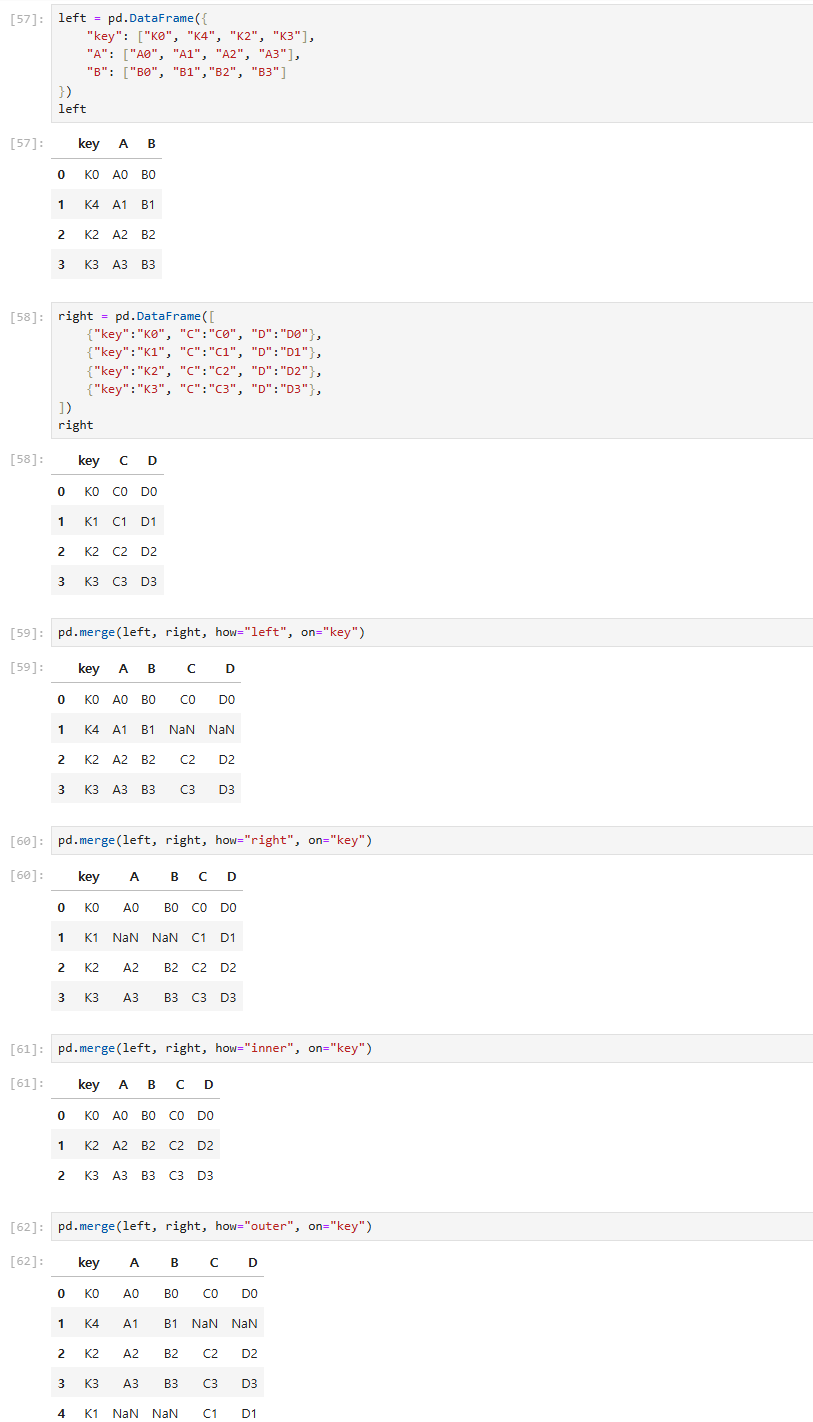
Pandas에서 데이터 프레임을 병합하는 방법
- pd.concat()
- pd.merge()
- pd.join()
pd.merge()
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키값이라고 합니다
- 기준이 되는 키값은 두 데이터 프레임에 모두 포함되어 있어야 합니다