
1. 추정
-
추정(estimation) : 모집단의 모수를 모를 경우 표본으로 추출된 통계량을 모집단의 근사값으로 사용하는 것을 추정이라고 함
-
추정량(estimator) : 표본 평균으로 모평균을 추정할 때 표본 평균을 모평균에 대한 추정량이라고 함
-
모수를 추정 하는 방법에는 점추정(point estimation) 과 구간 추정(interval estimation)이 있음
- 점추정: 모수를 하나의 특정값으로 추정 하는 방법
- 구간 추정: 모수가 포함될 수 있는 구간을 추정하는 방법

-
점추정의 대표적인 성질
- 일치성(Consistency)
표본의 크기가 모집단의 크기에 근접해야 함
표본이 크기가 크면 클수록(모집단에 가까울 수록) 추정량의 오차가 작아짐 - 불편성(unbiased estimator)
추정량이 모수와 같아야 함
모수가 이고 추정량이 라고 정의하면, 이고, 이를 불편 추정량 이라고 함
즉, 일때의 추정량을 불편 추정량이라고 하고, 같지 않다면 편의(biased) 있다고 함 - 유효성(efficiency)
추정량의 분산이 최소값이어야 함
모수에 대한 추정량의 분산이 작을 수록 추정량이 효율적이다는 의미임
만약 모수 의 불편 추정량이 , 이라면 이면, 효율적인 추정량임 - 평균오차제곱(Mean Squared Error, MSE)
평균오차제곱이 최소값이어야 함
이 최소이어야 함
- 일치성(Consistency)
-
구간추정: 모수가 포함될 수 있는 구간을 추정하는 방법
-
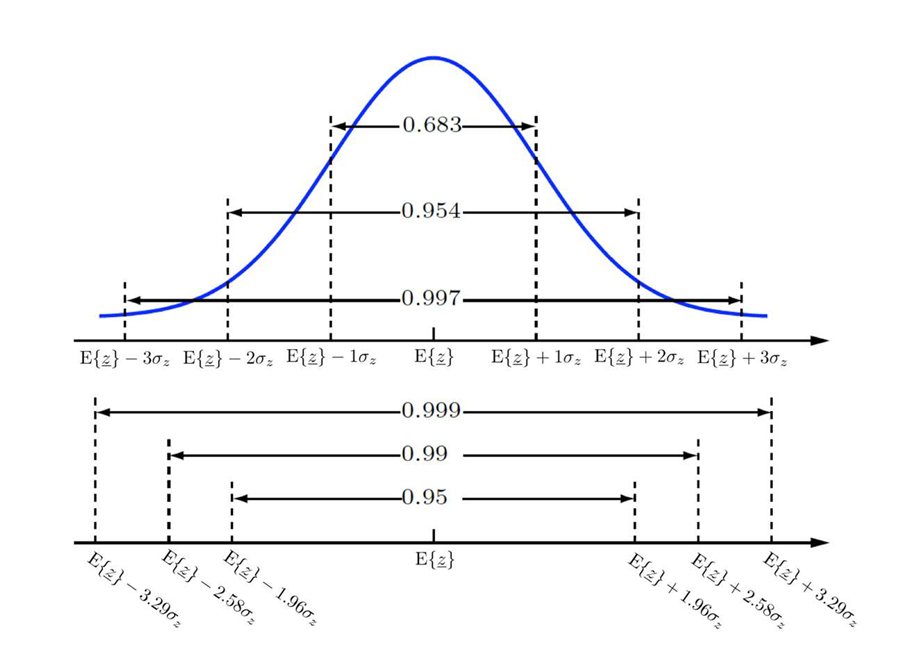
신뢰구간(confidence level)
추정값이 존재하는 구간에 모수가 포함될 확률- 신뢰 수준은 로 계산 하며, 는 오차 수준임
- 신뢰 수준 95%라는 것은 구간 추정된 값의 오차가 발생할 확률이 5%라는 것을 의미함
- 이 오차를 유의 수준(significant level)이라고 하며, p= 0.05라고 함
- 신뢰구간은 신뢰 하한, 신뢰 상한으로 표시하며 아래와 같은 수식으로 표현 (추정하는 모수가 )
- 만약, 모평균 를 추정한다면, 표본평균이 이고 표준오차가 라고 하면 신뢰구간은 아래와 같음
-
모평균의 구간 추정
-
모집단의 분산을 아는 경우
-
모집단의 분산을 모르는 경우
-
표본의 크기 결정
허용오차(permissible error) : 추정한 값이 틀려도 허용할 수 있는 오차
정규분포의 신뢰구간을 통해 허용 오차를 계산
, : 허용오차
2. 모비율 추정
-
모비율의 점추정
비율에 대한 추정으로 우리가 원하는 속성(class)에 속하면 ‘1’ 아니면 ‘0’일 때, 1의 속성을 갖는 것의 개수를 X라고 하면 X ~ B(n,p) 임
이 때 모비율의 점추정량을 표본 비율(sample proportion)이라고 함 (),
-
모비율의 구간 추정
모비율 구간 추정에서 정규분포의 근사가 가능한 대표본은 보통 np>5, n(1-p)>5 를 동시에 만족 해야 함
N이 충분히 크면 C.L.T에 의해서 -
모평균 차이의 추정(점추정)
-
모평균 차이의 추정(구간추정: 대표본)
-
모평균 차이의 추정(구간추정: 소표본, 모분산을 모르는 경우)
두 모집단의 분산을 아는 경우에는 대표본과 동일하게 추정 가능하지만 모르는 경우에는 등분산 가정이 필요 (두 모집단의 분산이 같다는 가정이 필요 )합동 분산 추정량(pooled variance estimator) : 공통 분산의 추정량
-
모비율 차이의 추정(점추정)
-
모비율 차이의 추정(구간추정)
