JCF
정의
JCF는 Java Collections Framework의 약어로, 다수의 데이터를 쉽고 효과적으로 처리할 수 있는 표준화된 방법을 제공하는 클래스의 집합
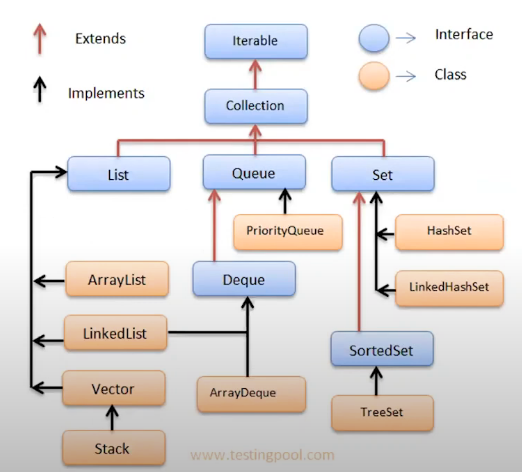
List
- 순서가 있으며, 중복 허용
| ArrayList | LinkedList | Vector | |
| 특징 | 배열 기반으로 구현된 동적 크기의 리스트 데이터가 추가되면 배열 크기를 자동으로 늘려주지만, 배열의 크기 조정 작업은 비용이 높음 |
이중 연결 리스트(Double Linked List)로 구현 각 노드가 데이터와 함께 이전 및 다음 노드의 참조를 가짐 |
배열 기반으로 구현된 동적 크기의 리스트 ArrayList와 유사하지만, 스레드 안전(Thread-safe) 모든 메서드에 동기화(synchronized) 처리 |
| 장점 | 인덱스를 사용한 검색 속도가 빠름 (O(1)) 데이터 추가나 삭제가 배열의 끝에서 이루어질 경우 빠름 (O(1)) |
중간에서 데이터 추가/삭제가 빠름. (O(1) 링크 조정만 수행) 크기 조정이 필요하지 않으므로 메모리 낭비가 적음 |
스레드 안전하여, 멀티스레드 환경에서 안전하게 사용 ArrayList와 동일한 방식으로 작동하므로, 배열 기반의 장점을 공유 |
| 단점 | 중간에서 데이터 추가/삭제 시, 배열 요소를 이동해야 하므로 성능이 저하(O(n)) 크기를 동적으로 늘리기 위해 새로운 배열을 생성하고 데이터를 복사하는 비용이 발생 |
인덱스를 사용한 검색이 느림 (O(n)) 처음 노드부터 순차적으로 탐색 노드의 포인터 관리로 인해 메모리 사용량이 더 많음 |
동기화 처리가 되어 있어, 단일 스레드 환경에서 성능이 느림 최근의 멀티스레드 환경에서는 Collections.synchronizedList()로 동기화된 ArrayList를 사용하는 것이 더 일반적 |
| 사용사례 | 데이터를 자주 검색하거나 순차적으로 추가/삭제하는 경우 적합 | 데이터의 중간에 추가/삭제 작업이 빈번하게 발생하는 경우 적합 | 멀티스레드 환경에서 리스트를 사용해야 하는 경우 적합 |
import java.util.*;
public class Example {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
System.out.println(list); // [A, B, C]
list.remove(1); // "B" 삭제
System.out.println(list); // [A, C]
LinkedList<String> list = new LinkedList<>();
list.add("X");
list.add("Y");
list.add("Z");
System.out.println(list); // [X, Y, Z]
list.add(1, "A"); // "A" 추가
System.out.println(list); // [X, A, Y, Z]
Vector<Integer> vector = new Vector<>();
vector.add(10);
vector.add(20);
vector.add(30);
System.out.println(vector); // [10, 20, 30]
vector.remove(1); // "20" 삭제
System.out.println(vector); // [10, 30]
}
}
Queue
- FIFO 구조, 우선순위 큐 지원
| Stack | Queue | |
| 정의 | LIFO (Last In, First Out) 구조: 마지막에 추가된 요소가 가장 먼저 제거 | FIFO (First In, First Out) 구조: 먼저 추가된 요소가 가장 먼저 제거 |
| 주요 메서드 | push(item): 스택에 아이템 추가 pop(): 스택에서 가장 최근에 추가된 아이템 제거 및 반환 peek(): 스택의 최상단 아이템을 확인 (제거하지 않음) isEmpty(): 스택이 비어있는지 확인. |
add(item) 또는 offer(item): 큐에 아이템 추가 remove() 또는 poll(): 큐에서 가장 먼저 추가된 아이템 제거 및 반환 peek() 또는 element(): 큐의 첫 번째 아이템 확인 (제거하지 않음) isEmpty(): 큐가 비어있는지 확인 |
| 사용 사례 | 재귀 호출의 처리 브라우저의 뒤로 가기/앞으로 가기 괄호 검사(유효성 확인) DFS(깊이 우선 탐색) |
작업 스케줄링 BFS(너비 우선 탐색) 프로세스/스레드 관리 |
import java.util.*;
public class Example {
public static void main(String[] args) {
Stack<Integer> stack = new Stack<>();
stack.push(10);
stack.push(20);
stack.push(30);
System.out.println(stack.pop()); // 30
System.out.println(stack.peek()); // 20
Queue<Integer> queue = new LinkedList<>();
queue.add(10);
queue.add(20);
queue.add(30);
System.out.println(queue.poll()); // 10
System.out.println(queue.peek()); // 20
}
}Set
- 순서가 없으며, 중복 허용하지 않음
HashSet LinkedHashSet TreeSet 특징 중복을 허용하지 않음
순서를 보장하지 않음
해싱(Hashing) 기법을 사용하여 빠른 검색, 삽입, 삭제를 지원 (O(1))중복을 허용하지 않음
삽입 순서를 유지
내부적으로 HashSet과 LinkedList를 조합하여 구현중복을 허용하지 않음
요소를 정렬된 상태로 유지
내부적으로 이진 탐색 트리(레드-블랙 트리)로 구현되어 삽입/삭제/검색이 모두 O(log n)사용사례 중복 제거, 빠른 검색이 필요한 경우 중복 제거와 동시에 순서가 중요한 경우 정렬된 데이터 저장 및 중복 제거가 필요한 경우
import java.util.*;
public class Example {
public static void main(String[] args) {
HashSet<String> hashSet = new HashSet<>();
hashSet.add("A");
hashSet.add("B");
hashSet.add("A"); // 중복 제거
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add("A");
linkedHashSet.add("B");
linkedHashSet.add("A"); // 중복 제거
TreeSet<String> treeSet = new TreeSet<>();
treeSet.add("B");
treeSet.add("A");
treeSet.add("C");
System.out.println(hashSet); // 순서 보장 없음
System.out.println(linkedHashSet); // 삽입 순서 유지
System.out.println(treeSet); // 정렬 순서
}
}
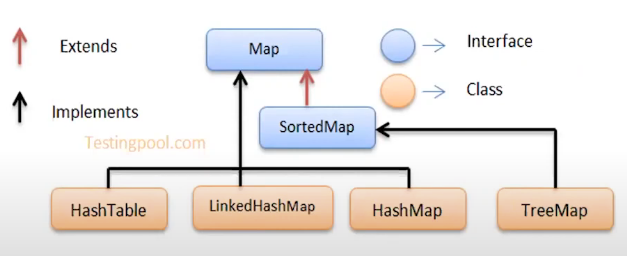
Map
- Key와 그에 대응되는 Value의 쌍으로 구성되는 객체들을 모아 놓은 구조
| HashMap | TreeMap | LinkedHashMap | |
| 특징 | 키-값(Key-Value) 쌍으로 데이터를 저장 해싱(Hashing) 기법을 사용하여 빠른 검색, 삽입, 삭제를 지원 (O(1)) 키의 순서를 보장하지 않음 |
키-값 쌍으로 데이터를 저장하며, 키를 정렬된 상태로 유지 내부적으로 이진 탐색 트리(레드-블랙 트리)로 구현 (O(log n)) |
키-값 쌍으로 데이터를 저장하며, 삽입 순서를 유지 내부적으로 HashMap과 LinkedList를 조합하여 구현 성능은 HashMap과 비슷하지만, 순서를 유지하는 데 약간의 오버헤드 발생 |
| 사용사례 | 빠른 데이터 검색이 필요한 경우 | 정렬된 데이터가 필요하거나 키 범위 검색이 필요한 경우 | 삽입 순서를 보존하면서 데이터 관리가 필요한 경우 |
import java.util.*;
public class Example {
public static void main(String[] args) {
HashMap<String, Integer> hashMap = new HashMap<>();
hashMap.put("B", 2);
hashMap.put("A", 1);
hashMap.put("C", 3);
TreeMap<String, Integer> treeMap = new TreeMap<>();
treeMap.put("B", 2);
treeMap.put("A", 1);
treeMap.put("C", 3);
LinkedHashMap<String, Integer> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("B", 2);
linkedHashMap.put("A", 1);
linkedHashMap.put("C", 3);
System.out.println(hashMap); // 순서 보장 없음
System.out.println(treeMap); // 키 정렬 유지
System.out.println(linkedHashMap); // 삽입 순서 유지
}
}
참고
https://steady-coding.tistory.com/354
https://dodo-factory.tistory.com/entry/JAVA-Java-Collection-Framework-JCF%EC%9D%98-%EC%9D%B4%ED%95%B4
https://velog.io/@chocochip/JCF-Java-Collection-Framework
https://mungto.tistory.com/465

BackEnd developer