
절망의 시작 Paging,,
그전까지만 해도 10시쯤 학과 공부 끝마치고 나서 꼬박꼬박 웹 공부를 조금씩 계속 하고 있었는데, Paging쯤부터 슬슬 속썩다가 멘탈이 와장창! 깨져서 Velog에 정리하면서 공부해봐야겠다고 결심했던 기억이 난다. 그래봐야 2주정도 전이지만 ㅋㅋ
쫄지 말고! 오늘은 못해도 Paging Introduction이랑 TLB까진 꼭 정복해봐야겠다. 간다! 와!
Review
Memory Virtualization에 대한 주제를 다루며 살펴본 전체적인 흐름을 정리해보자면 아래와 같다.
- 논의의 단순화를 위해 물리 메모리를 연속적으로 빈틈없이 배열된 구간의 나열로 본다. (15장)
- 1에서 발생하는 Internal fragmentation을 해결하기 위해 주소 공간을 Segment라는 단위로 나누어 관리한다. (16장)
- 그런데 이 Segmentation 방법에서 External fragmentation이 발생함을 발견했다. (16장)
오,,케이 여기까진 좋은데, 이번에 배울 Paging은 또 Segmentation과 달리 메모리 공간을 동적으로 크기를 자유롭게 조절해서 할당해주는게 아니라 고정된 크기의 조각으로 메모리 공간을 나누어 관리한다고 한다.
이렇듯,, 운영체제 과목이든, 컴퓨터 공학이든, 아니면 공학 전반이든, 모든 문제에 항상 최적의 솔루션이 있을 수 있는 것도 아닐 뿐더러 가능한 답안들의 장단점을 잘 파악하고, 적절한 선을 찾아나가는 감이 참 중요한 것 같다. 나중에는 이 두 가지 방법을 적절히 혼합하는 방법도 나오거든!
...
각설하고, 이번에 살펴볼 Paging 기법의 장점으로 크게 두 가지를 들 수 있을 것 같다.
첫째로, 뭔가 다시 되돌아가는 느낌이지만 물리 메모리를 고정 크기로 나누기 때문에 Segmentation과 달리 External fragmentation이 발생하지 않는다.
둘째로, Segmentation에서 각각의 segment를 Code, Heap, Stack으로 나누고, Segment별 bound니 뭐니 하며 이것저것 주소 변환에 신경써야 할 것들이 확 줄어든다는 장점이 있다.
여기서 이 고정된 크기의 가상 메모리 조각을 Page라 하고, 이에 일대일로 대응하는 물리 메모리 상의 공간을 Page Frame이라 부른다. 물론 Page Frame 역시 크기가 고정되어 있을 것이고.
18.1. A Simple Example And Overview
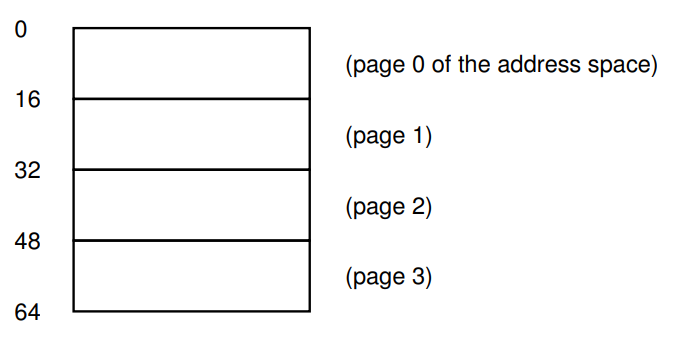
예제를 통해 Paging 개념과 좀 더 친해져보자.
위 그림은 총 크기가 64Byte이고, 이 64B를 4개의 16B짜리 페이지로 분할한 주소 공간이다.
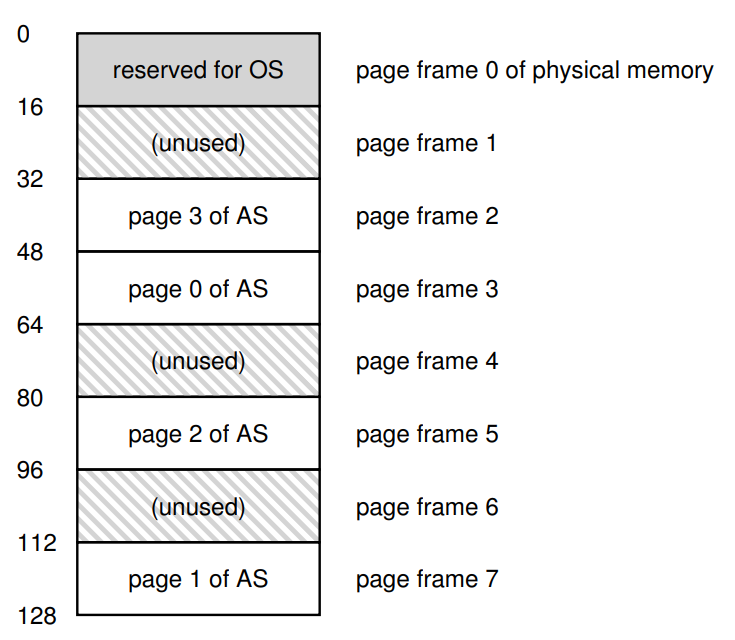
여기에 대응되는 128KB짜리 물리 메모리는 위와 같이 표현할 수 있는데, 잘 보면 0~16KB에 해당하는 페이지 프레임은 OS에게, 16~32KB, 64~80KB, 96~112KB는 미사용, 32~48KB, 48~64KB, 80~96KB, 112~128KB는 맨 위에서 보여준 64KB짜리 주소 공간에 점유되어 있다.
보면 알겠지만 Segmentation 방법과 달리 메모리를 딱히 Code, Heap, Stack과 같이 역할에 따라 나누지 않았기 때문에 페이지 간에 특성 차이가 없어 상대적으로 유연하고, 전에 Splitting이니, Coalescing이니, Best/Worst/First/Next Fit, Buddy Allocation과 같은 복잡한 빈 공간 관리 정책도 필요 없이 그냥 Free list에서 메모리 할당 요청이 들어올 때마다 노드를 통째로 떼어서 주기만 하면 되므로 단순하다.
메모리를 할당해준다는 것을 Base & Bound에서는 Base, Bound Register로 표현했고, Segmenation에서는 Segment bit를 통해 각 Segment를 구분해가며 복잡하게 표현했다.
그럼 Paging에서는? 이러한 연결 관계를 프로세스마다 Page table이라는 것을 두어 관리하도록 구현한다. 이전처럼 수식만을 사용해서 주소 변환을 수행하는게 아니라, 그냥 Page Table에 저장된 {가상 페이지 번호 <-> 물리 프레임 번호} 정보를 사용해서 각각의 가상 주소를 물리 메모리로 주소 변환한다.
여기서 '프로세스마다 Page Table이 존재한다'는 말이 중요한데, 전에 살짝 얘기한 Code 영역의 공유같은 예외적인 상황을 제외하면 마치 namespace처럼 각각의 프로세스가 서로 간섭하지 않는, 간섭할 수 없는 환경을 만들어주어야 하는 것은 이젠 너무 당연하기 때문에 더 자세히 설명하지는 않겠다.
Paging에서의 주소 변환
그럼 이제 실제로 Paging에서의 주소 변환을 직접 한 번 해보자. 형식은 대강 아래와 같다.
movl <virtual address>, %eax위 명령어는 <virtual address>에 들어 있는 데이터를 %eax 레지스터에 올려 놓는다.
주소 변환을 위해 우선 저 Virtual address를 VPN(Virtual Page Number)과 Offset으로 분할해야 한다. 무슨 말인지 잘 모르겠지?! 그림으로 보자.
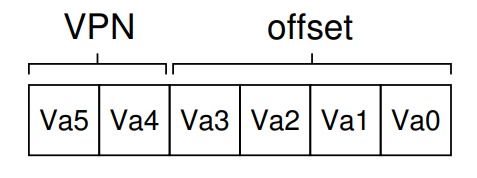
Va5~Va0은 각각이 0이나 1의 값을 가지는 비트를 의미하는데, 가상 주소 공간의 크기가 2^6=64B이기 때문에 이를 표현하기 위해 6자리의 비트가 필요한 것이다.
이때 각각의 페이지 크기를 64B를 4분할한 16B=2^4B로 정했으므로, 페이지 내에서 메모리 주소를 표현하기 위한 Offset bit가 4비트, 각각의 4=2^2페이지를 구별하기 위한 VPN은 2bit로 자연스럽게 정해진다.
머리가 굳어서 처음에는 Offset에 의해 VPN이 그냥 막 조정되는거라고 생각했었는데, 여기서 거꾸로 페이지 크기가 아니라 페이지 갯수를 먼저 4분할이 아니라 그 두 배인 8분할로 바꿔주면 페이지 식별을 위해 3비트가 필요하고, 페이지의 분할이 두 배로 늘었으니 자연스럽게 페이지의 크기도 반으로 줄어 16B에서 8B, 비트로는 하나가 감소한 3비트로 Offset을 표현하게 되는, 이 관계를 잘 알고 있어야 한다.
...
오케! 그럼 이제 실전으로 한 번 들어가보자.
movl 21, %eax위의 규칙에 의하면, 가상 주소 21에 있는 데이터를 레지스터 %eax에 올려 놓는다는 의미이다.
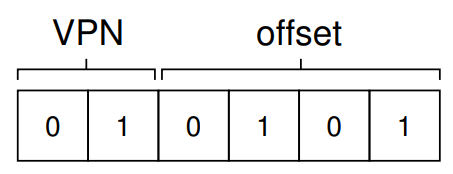
그럼 이 가상 주소 21을 2진수로 변환하면 010101이 되는데, 이를 VPN과 Offset으로 분리하면 위와 같이 나눌 수 있게 된다. 이는 곧 1번째 페이지 내의 5번째 주소를 가리킨다는 의미라 할 수 있겠다.
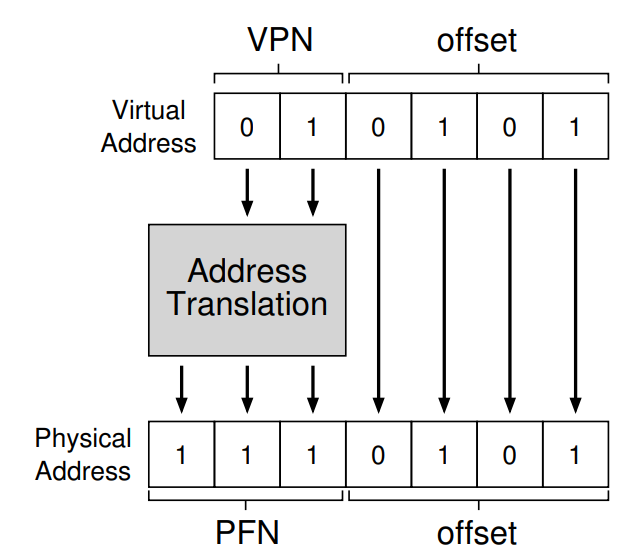
이때! 이 VPN과 Offset을 실제 물리 메모리 주소로 주소 변환하기 위해 필요한 것이 바로 Page Table이 되는 것이다.
이 경우 VPN 01이 PFN(Physical Frame Number), 그러니까 실제 물리 메모리에서의 특정 프레임을 가리키는 번호 중 111로 변환되어 페이지 프레임의 시작점으로부터 5B만큼 떨어진 위치에 실제로 접근하게 된다. 가상 주소가 21로 표현되었듯, 물리 메모리 위의 물리 주소에 해당하는 1110101 역시 십진수 117로 표현할 수 있다.
18.2. Where Are Page Tables Stored?

지금까지 주소 변환에 관련된건 CPU 내부에 있는 MMU(Memory Management Unit)에서 모두 처리한다고 했는데, 이 프로세스마다 존재하는 {가상 주소 <-> 물리 주소}의 연결 정보를 모두 MMU에 저장할 수는 있는 걸까?
어림잡아 한 페이지가 4KB=2^12B인 32bit 주소 공간의 경우 Offset이 12비트이므로 VPN은 20비트가 된다. (헷갈리면 위의 설명을 천천히 다시 읽어보자.) 이 2^20=1,048,576개에 해당하는 연결 정보를 싹 저장하려면,,? 각각의 연결 정보 묶음(PTE, Page table entry) 하나당 4Byte가 필요하다고 가정했을 때 총 2^(20+2)Byte=4MB가 필요하다.
이건 하나의 프로세스에 대한 계산이고, 예를 들어 100개의 프로세스가 실행된다면 이 주소 변환 정보에만 무려 400MB가 쓰여야 한다. 말이 안된다! 이걸 CPU 안에 욱여 넣는다고?
그래서 메모리 쪽으로 눈을 돌려서, 일단은 저 거대한 Page Table이 MMU가 아니라 물리 메모리에 저장된다고 일단은 가정하자.
또 요즘은 64bit 주소 공간을 많이 사용하는데, 똑같이 한 페이지의 크기를 4KB로 잡으면 Offset이 12비트이므로 VPN은 52비트이므로 한 프로세스당 4Byte짜리 PTE가 18,014,398,509,481,984B=16,384 테라바이트가 필요하다는 이야기이다.
이 수준까지 올라가면 사실상 메모리에도 올릴 수 없고, 그보다 더 큰 디스크나 그 이상의 가상화가 필요하게 되겠지만 지금은 그냥! 위의 그림과 같이 PFN 0에 해당하는 위치 내부에 Page Table이 존재한다고만 생각하고 넘어가자. 자세한건 나중에 배운다.
18.3. What's Actually In The Page Table?
PTE를 그냥 {가상 주소 <-> 물리 주소}의 연결 정보라고 뭉뚱그려서 얘기하기는 했는데, 실제로 이를 관리하기 위한 Page table과 PTE 그 자체는 어떤 조건을 만족해야 할지 생각해보자.
일단 PTE를 저장하기 위한 Page table은 Free list에서 그러했듯 기능만 제대로 작동한다면 어떤 자료 구조를 사용해도 무방한데, 가장 간단한 형태로 Linear Page Table, 그러니까 VPN<->PFN 연결 정보를 저장한 일종의 배열을 사용한다고 생각하자.

이제 PTE를 파보자면,, 책에서 가장 많이 접하고 있는 x86 아키텍처에서는 PFN 말고도 이것저것 뭐가 많다. (위에 이것저것 약어로 쓰여져 있기는 한데, 저 상대적인 위치나 약어를 외울 필요까지는 없고 그냥 이런 비트가 이런 목적으로 사용된다~~ 정도만 알고 있으면 충분할 것 같다.)
- Valid Bit
해당 프레임이 현재 실제로 사용중인지 표시하기 위한 비트이다. 만약 해당 프레임이 예를 들어 Heap과 Stack 사이에 낑겨 있는 Internal fragment이라면,, 해당 비트가 0으로 표시되어 있을 것이므로 만약 이 영역에 접근하려는 시도를 감지할 경우 OS에서 트랩이 발생해 프로세스를 종료시키던가 할 것이다.
꽤 핵심적인 역할을 하는데, 만약 이 Valid bit가 없었다면 메모리를 사용하고 있든 말든 그냥 전부 물리 메모리의 프레임들을 점유하고 있었을 것이다. 반대로 메모리를 더이상 사용하지 않게 되면 그냥 이 비트만 0으로 전환해 Invalid하다고 표시해주면 되니까 간편하기도 하고.
- Protection Bit
이전에 Segmentation에서 다룬 Protection 기능과 동일한데, 해당 프레임에 읽기(r), 쓰기(w), 실행(x) 중 어떤 작업이 가능한지를 명시해 허가되지 않은 접근이 있을 경우 마찬가지로 트랩을 발생시킨다.
- Present Bit
지금은 모르고 넘어가도 될 것 같은데, 간단하게 설명하자면 MMU에 Page table을 저장할 수 없어 메모리에 저장했던 것과 마찬가지로 메모리조차 부족해지면 디스크의 특정 영역에 메모리에 올려야 할 데이터를 저장해놓고 필요할때 가져다 쓰는데(swap), 이때 해당 데이터가 현재 메모리에 올라와있는지, 아니면 디스크에 있어 메모리로 끌어 올려와야 하는지를 표시하기 위한 비트이다.
- Dirty Bit
위의 Present bit의 연장선상에 있는 비트인데, 해당 프레임의 데이터가 메모리에 올라온 이후에 내용이 변경되었는지를 표시하기 위한 비트이다. 만약 내용이 변경되지 않았다면 굳이 디스크에 값을 덮어쓸 필요 없이 언제든 그냥 메모리에 데이터를 올려서 쓸 수 있겠지만, 메모리에서 값이 변경되었다면 디스크에도 이 내용을 반영해주어야 하기 때문에 필요하다. (마찬가지로 나중에 이해해도 된다.)
- Reference Bit
이건 페이지 교체에 대해 공부할 때 자세히 배우게 되는데, 메모리 공간은 유한한 반면 메모리에 상주하고 싶어하는 프로세스는 넘쳐나므로, 어쩔 수 없이 기존에 있던 메모리를 다시 디스크의 swap 영역을 내려놓아야 할 때 사용하게 될 비트이다. (나중에 이해해도 된다.)
Offset은 왜 없냐고? Offset은 Page table에 저장될 데이터가 아니다!
Page table은 VPN과 PFN을 변환하기 위한 연결 정보, 그러니까 공간과 공간을 연결하기 위한 정보를 저장할 뿐 공간 내의 특정 지점을 가리키기 위한 Offset은 저장하지 않는다.
18.4. Paging: Also Too Slow
아까 페이지 테이블을 그냥 Linear한 배열에 저장하는 것으로 생각했는데, 그렇게 되면 테이블의 크기가 커질 때마다 선형적으로 주소 변환 속도 역시 같이 반비례하여 느려질 수밖에 없고, 말고도 변환 매커니즘이 좀 더 복잡해졌기 때문에 처리 속도 역시 태생적으로 더 느리다.
movl 21, %eax아까 뭉뚱그려서 살펴봤던 위 명령어에서 발생하는 주소 변환 과정을 자세히 살펴보자.
프로세스별 주소 변환 정보인 Page table의 시작 주소를 메모리에 어딘가에 저장한다고 했는데, 이걸 구체적으로 MMU의 PTBR(Page Table Base Register)이라는 레지스터에 저장해놓았다고 가정해보자. (2^6 = 64Byte의 주소 공간을 상정한다.)
VPN = (VirtualAddress & VPN_MASK) >> SHIFT
PTEAddr = PageTableBaseRegister + (VPN * sizeof(PTE))그럼 이때 위와 같이 원하는 PTE가 저장된 위치를 얻어올 수 있다.
이전에 Segmentation bit를 얻어내는 과정에서 비슷한 연산을 했는데, VPN_MASK(110000)과의 & 연산을 통해 VPN에 해당하는 비트를 제외하고 모두 0으로 바꿔준 다음, SHIFT(4)만큼 우로 bit shift 연산을 수행해 VPN을 먼저 얻는다. 그럼? 여기서 VPN은 아까 구했듯 01임을 구할 수 있다.
그 다음으로 MMU의 PTBR로부터 PTE의 크기만큼 VPN번 떨어진 곳의 위치를 계산해보면, 그 지점이 바로 원하는 연결 정보가 들어 있는 PTE의 시작 주소가 됨을 알 수 있으므로 이로부터 PFN을 추출할 수 있다.
offset = VirtualAddress & OFFSET_MASK
PhysAddr = (PFN << SHIFT) | offsetoffset도 VPN과 같은 방법으로 Masking을 통해 구해주고, 이번엔 위에서 구한 PFN과 offset을 합쳐 실제 물리 메모리의 특정 주소에 접근할 수 있는 PhysAddr를 구해 주소 변환을 끝낸 다음 메모리에 접근하여 레지스터에 값을 얹어주면 끝!
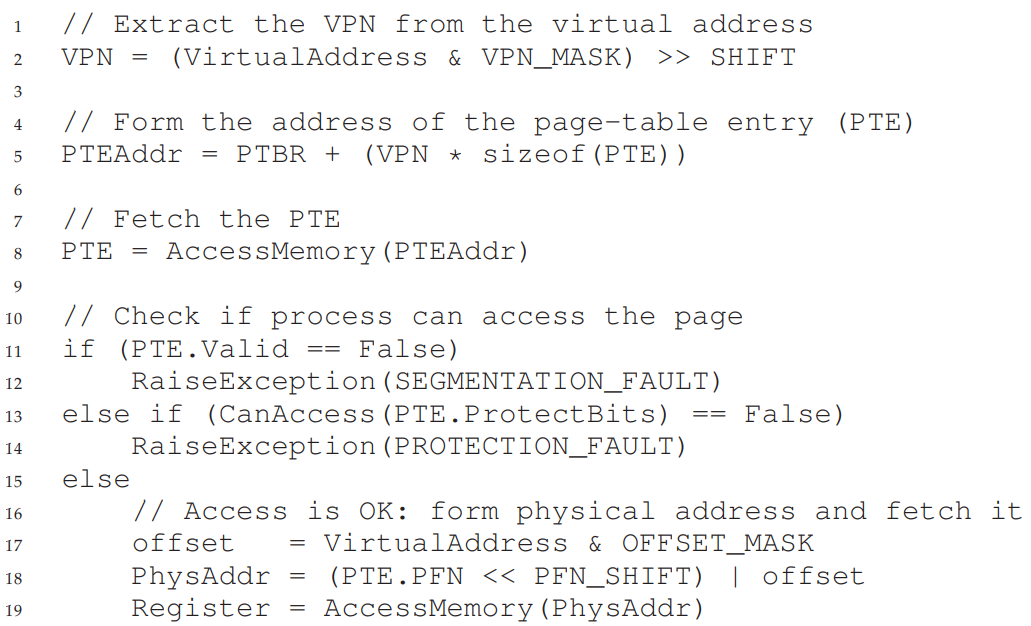
어우, 여기까지만 해도 복잡한데, 11~12행에서 PTE의 Valid bit를 검사해 사용중인 프레임이 아닌데 접근을 시도했을 경우 Segmentation fault를, 13~14행에서 허가된 접근이 아님을 감지한 경우 Protection fault를 발생시키는 코드까지 포함하면 이전의 Base & Bound나 Segmentation과 달리 이것저것 처리해주어야 할 것들이 정말 많다.
'주소 변환'이라는 연산 한 번에 비용이 이렇게 많이 들어가는데, 심지어 명령어 Fetch든, 메모리 접근 명령이든 최소 한 번씩은 이 과정을 거쳐야 하기 때문에 프로세스가 2배 이상 느려진다고 한다.
정리하자면, Paging 기법이 다 좋은데 Page table 자체의 크기가 너무 커지는 문제와, 주소 변환에 시간이 너무 오래 소요되는 시공간 양쪽 측면의 한계가 분명하다고 할 수 있겠다.
18.5. A Memory Trace
뭐든 뭉뚱그려서 겁먹기보다는, 솔루션의 한계를 계량화하여 문제점을 정확히 인지하는 것이 훨씬 낫다.
int array[1000];
...
for (i=0; i<1000; i++)
array[i] = 0;위의 프로그램 array.c의 일부는 별거 없고, 그냥 길이 1000짜리 배열을 선언한 다음 모든 요소를 0으로 초기화해주는 단순한 코드이다. 이를 컴파일한 후, Linux의 objdump 등의 명령어를 통해 disassemble해주면 아래와 같은 코드가 된다.
1 0x1024 movl $0x0, (%edi, %eax, 4)
2 0x1028 incl %eax
3 0x102c cmpl $0x03e8, %eax
4 0x1030 jne 0x1024쫄거없다! 위에서부터 천천히 해석해보자. 참고로 맨 왼쪽의 숫자는 그냥 명령어의 순서를 나타내기 위해 표기한 것이고, 두번째는 명령어가 저장된 위치(명령어가 4byte라서 각각 4byte씩 차이가 난다.), 세번째는 어셈블리 명령어, 그 뒤는 명령어의 인자(?) 쯤 된다.
- 0x1024 movl $0x0, (%edi, %eax, 4)
$0x0은 값 0($0x0) = 0을 의미하는 상수로, 이 값이 저장될 위치는 (%edi, %eax, 4), 그러니까 %edi의 값을 %eax의 4배에 더해서 계산한 위치인 %edi + (%eax + 4)가 된다.
여기서 %edi를 배열의 시작 주소(array)라 하고 %eax가 배열의 인덱스 값인(i)라 하면, for문을 돌면서 i값을 1씩 증가시켜 int의 크기인 4byte씩만큼씩 올려가며 array의 연속된 정수 값 요소에 접근하는 코드가 되는 것이다.
정리하자면, 현재 가리키고 있는 배열의 위치 array[i]의 요소에 접근하여 해당 위치의 값으로 상수 0을 써주는 명령어라 할 수 겠다.
- 0x1028 incl %eax
간단하게 %eax에 저장된 값을 1만큼 올려주는 코드인데, %eax를 인덱스 변수 i라 했으니 C 코드의 i++에 해당하는 명령어에 해당한다.
- 0x102c cmpl $0x03e8, %eax
여기서는 십진수 1000 = 0x03e8에 해당하는 값과 %eax에 저장된 값이 같다면 cmpl 명령어에 의해 변경되는 특수한 레지스터의 값을 1로 변경해주고, 그렇지 않은 경우 0으로 변경해준다. i<1000 부분에 대응된다고 할 수 있다.
- 0x1030 jne 0x1024
마지막으로, 위의 cmpl 명령어를 통해 변경한 특수한 레지스터 값을 확인하여 만약 값이 1인 경우(%eax에 저장된 값이 1000인 경우) 루프를 빠져나오고, 그렇지 않은 경우 다시 0x1024, array[i]에 0을 저장해주는 코드로 다시 이동한다.
후! 컴퓨터 구조 강의때 그래도 슬쩍 배워놔서 그렇게 어렵지 않아 다행이다.
코드는 이해되었으니, 이제 코드가 실행되는 환경을 가정해보자.
프로세스가 사용할 가상 주소 공간의 크기를 64KB=2^(6+10)B, 페이지 크기는 1KB=2^10B로 하여 총 2^6=64개의 페이지로 분할한다고 가정하자.
주소 변환을 위해 필요한 선형 구조의 Page table이 저장된 위치인 PTBR을 알아야 하는데, 여기서는 물리 주소의 1KB=1024B에 저장되어 있다고 하자.
다음으로 주소 변환의 대상을 크게 '명령어 자체'와 '실제 접근할 데이터'로 나누어 생각해보면,,
일단 위의 Diassemble 결과에서 봤다시피 0x1024에 우리가 관심을 가지고 있는 첫 명령어가 저장되어 있는데, 한 페이지가 1024B이므로 첫 번째 페이지인 VPN=0은 [0B, 1023B]에 해당되니 모든 명령어가 VPN 1에 해당하는 위치에 저장되어 있고, 이 VPN 1이 PFN 4에 저장되어 있다고 가정할 수 있다.
다음으로 배열 그 자체의 경우 (4*1000)Byte = 4000Byte의 데이터가 가상 주소의 40000~44000Byte 구간에 걸쳐 저장되어 있다고 가정한다면, 1024*39=39936, 1024*40=40960, ... , 1024*42=43008, 1024*43=44032이므로 이 범위에 해당하는 VPN은 39, 40, 41, 42이다. 그리고 이 VPN을 각각 <39, 7>, <40, 8>, <41, 9>, <42, 10>과 같이 PFN으로 Mapping 해주자.
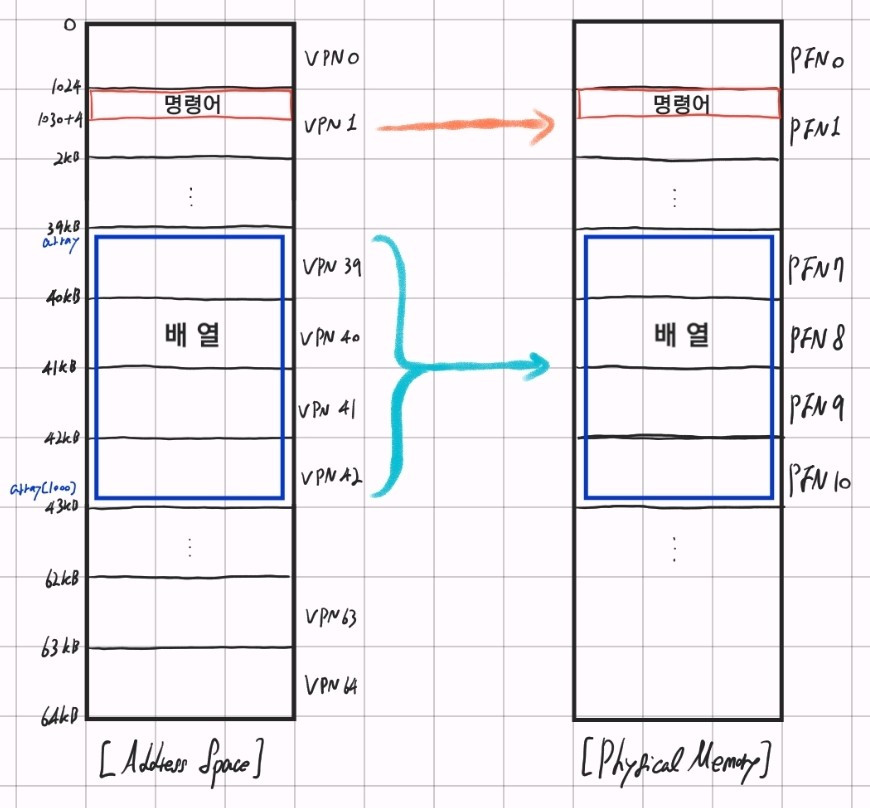
,,어우 줄글로만 보니까 솔직히 눈아플 것 같아서 직접 그냥 그렸다. 대강 위와 같다.
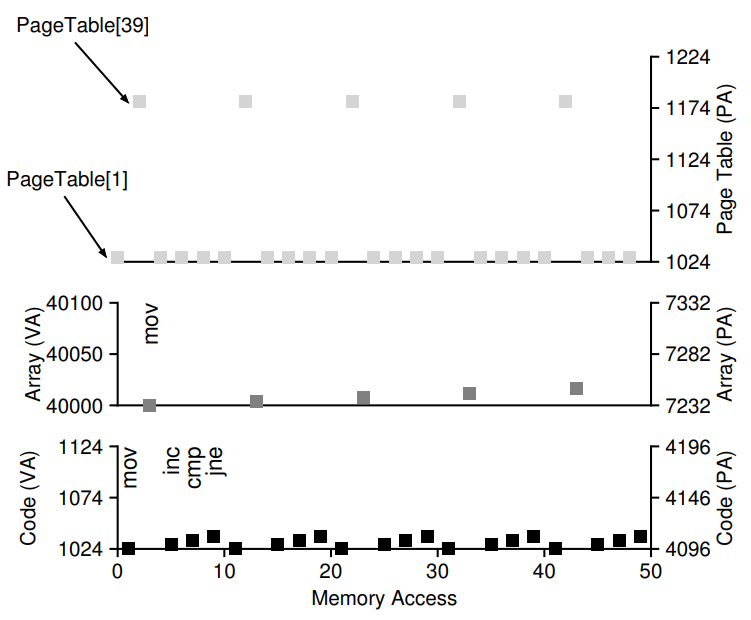
그럼 이 명령어 fetch와 실제 movl 명령어에 의한 메모리 접근이 발생할 때 메모리 액세스가 어떻게 일어나는지 그래프를 통해서 관찰해보자.
일단 모든 명령어에 대해서, 0x1024 등의 가상 주소로 가리켜지는 명령어가 물리 메모리의 실제 어느 부분에 들어 있는지 확인하기 위해 한 번, 그리고 얻어낸 VPN-PFN 변환 정보를 사용해 실제 명령어 자체를 읽어오기 위해 한 번, 총 두 번의 메모리 접근은 무조건 발생한다.
movl 명령어를 예로 들어 자세히 설명하자면, 일단 PTBR에 기록된 Physical Address 1024에 접근하여(가상 주소가 아니다!) Page Table에 접근(1회째, 맨 위 그래프), 얻어낸 PTE를 사용해 movl 명령어가 저장된 VPN을 PFN으로 변환해주고, 이 PFN을 가지고 실제 명령어가 저장된 물리 메모리에 접근(2회째, 맨 아래 그래프)하여 명령어를 CPU로 Fetch한 것이다.
다음으로 movl의 경우 array 자체에 접근해야 하기 때문에 array의 시작 주소가 실제로 저장된 위치를 알아내기 위해 array[0]이 포함되어 있는 Page table의 39번째 PTE에 접근(3회째, 가상 주소 공간이 Page Table과 일대일 대응하므로), 마지막으로 실제 array[0]이 저장된 물리 메모리를 찾아가 액세스하는데 한 번까지 총 4회의 메모리 액세스가 발생한다.
(아, 만약 인덱스가 증가해서 VPN 39의 범위를 넘어가게 되면 그때는 맨 위 그래프의 PageTable[39]가 PageTable[40], PageTable[41], PageTable[42]의 순서로 증가하게 될 것이다. 운좋게도 PFN이 VPN에서 그랬던 것처럼 연속적으로 연결되어있어 아래서 두 번째 그래프는 선형적으로 증가할 것이고!)
이외의 inc, cmp, jne 명령어는 명령어 fetch 이외에는 따로 메모리에 액세스하지 않으므로 각각의 명령어에 공통되는 메모리 액세스 2회씩 4회 + movl에서 사용되는 메모리 액세스 2회 = 총 10회의 메모리 액세스가 루프의 한 단계를 처리하는데 발생한다. 간단한 연산인데도 이렇게 많은 메모리 액세스가 필요하니 느릴 수밖에 없는 것이다 ㅠ
마무리
Base & Bound, Segmentation에 이어 Paging 방식의 Memory virtualization을 공부했다.
메모리를 고정된 크기의 구간인 Page로 나누어 프로세스에게 주는 것까지는 유연성, 단순함 측면에서 좋았는데, 앞의 두 방식과 달리 Page table이 주소 변환에 필요하게 되어 공간을 너무 많이 차지하게 되고, 또한 주소 변환 과정이 상대적으로 복잡한데다 메모리 액세스까지 중복해서 너무 많이 발생한다는 문제점이 잇음을 발견했다.
이어지는 두 장을 통해 이 문제들을 개선해볼 것이다. 저녁 먹고 마저 써야지. 와!
