
이전에 Paging을 사용한 Memory virtualization 기법에 대해 공부할 때, 모든 주소 변환 정보(PTE)를 메모리 위에 있는 Page table에 저장하여 모든 메모리 액세스마다 한 번씩 탐색을 수행해야 하기 때문에 Base & Bound 기법이나 Segmentation보다 매우 느릴 수 밖에 없음을 발견했다.
이걸 개선하기 위해 일종의 cache memory인 TLB(Translation-Lookaside Buffer)를 MMU에 추가하여 자주 사용되는 가상 주소 <-> 물리 주소 변환 정보를 더 빠르게 알아낼 수 있도록 할 수 있다. VPN을 PFN으로 변환해야 하는 요청이 발생하면 일단 TLB에 변환 정보가 있는지 확인해보고, 없으면 전에 배운 대로 주소 변환을 수행하면 되니까 기존의 메커니즘에서 달라질 것도 없다.
19.1. TLB Basic Algorithm

다른 부분은 다 같은데, TLB에 관련된 부분이 좀 더 붙었다. 한 줄씩 살펴보자.
VPN = (VirtualAddress & VPN_MASK) >> SHIFT이전과 동일하게 가상 주소로부터 VPN 값을 뽑아 오는 코드이다.
(Success, TlbEntry) = TLB_Lookup(VPN)추가된 부분인데, Page Table을 몽땅 뒤져서 VPN과 연결된 PFN을 찾는데 시간이 오래 소요되니, 접근 속도가 빠른 TLB를 먼저 Lookup해서 연결 정보가 있는지 먼저 확인하는 코드이다.
TLB는 새로 배우는 개념이니까 TLB Lookup에 실패한 경우, 그러니까 Success가 False인 경우부터 생각해보자. (이 상황을 TLB Miss라 한다.)
else // TLB Miss
PTEAddr = PTBR + (VPN * sizeof(PTE))
PTE = AccessMemory(PTEAddr)
if (PTE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else if (CanAccess(PTE.ProtectBits) == False)
RaiseException(PROTECTION_FAULT)
else
TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
RetryInstruction()TLB에 원하는 연결 정보가 없는걸 확인했으니, 이전에 했던 대로 Page table로부터 원하는 PTE를 찾아 Valid, Protection bit를 확인하는 부분까지는 같다.
그런데! 맨 아래 else 블럭이 심상치 않다. 자세히 보자.
else
TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
RetryInstruction()위의 Segmentation fault, Protection fault를 모두 피하고 나서 그냥 얻어온 PTE를 가지고 실제 물리 메모리를 계산하면 될 것 같은데, TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)와 RetryInstruction()만 덜렁 남겨져 있다.
왜인고 하니,, 어셈블리어(기계어) 수준에서는 C언어 같은 고수준 언어와 달리 이 '주소 변환'이라는 루틴의 중간으로 돌아가서 명령어를 다시 실행하는게 너무 복잡하기 때문에, 일단 TLB에 변환 정보를 넣어 놓고 메모리 접근 루틴을 통째로 다시 수행(RetryInstruction)하는게 더 간단하기 때문이다. 이때 만약 TLB Insert를 수행하는데 TLB가 꽉 차있다? 그럼 기존에 들어 있던 TLB를 빼내고 새로 insert해주어야 하는데, 이 정책은 뒤에서 배운다.
ㅇㅋ 그럼 [TLB Lookup 실패 -> 힘들게 PTE 가져오기 -> TLB에 넣어놓기] 까지 완료했으니까, 시키는대로 메모리 접근 루틴의 맨 앞으로 다시 돌아가보자.
VPN = (VirtualAddress & VPN_MASK) >> SHIFT
(Success, TlbEntry) = TLB_Lookup(VPN)VPN을 계산하는 부분이야 똑같고, 이번엔 아까 TLB에 확실히 연결 정보를 넣어 주었으니 Success가 True, TlbEntry도 빠르게 얻어냈을 것이다! (이 상황을 TLB Hit라 한다.)
if (Success == True) // TLB Hit
if (CanAccess(TlbEntry.ProtectBits) == True)
Offset = VirtualAddress & OFFSET_MASK
PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
Register = AccessMemory(PhysAddr)
else
RaiseException(PROTECTION_FAULT)이제 PTE를 빠르게 받아 왔으니까, 유효한 접근이라는 가정 하에(CanAccess(TlbEntry.ProtectBits) == True) 이전에 했던 대로 Offset과 PFN을 합쳐 실제 물리 메모리 상의 위치를 얻어낼 수 있다. 와!
여기서 요점은 TLB Hit, Miss 각각의 경우에 소요되는 시간이 정말 많이 차이가 나기 때문에, TLB Miss를 최대한 피하는 것이 메모리 접근 시간에 도움이 된다는 것이다.
19.2. Example: Access An Array
int sum = 0;
for (i = 0; i < 10; i++) {
sum += a[i];
}배열에 저장된 값들을 변수 sum에 저장하는 위 코드를 통해 이 TLB의 작동 흐름을 좀 더 자세히 살펴보자.
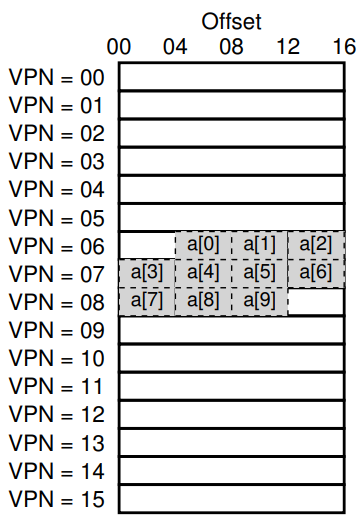
이때 각각의 요소는 위와 같이 분포되어 있다고 가정하고, i와 sum에 대한 메모리 접근은 생략하고 배열 a에 대한 메모리 접근만 고려하자.
a[0]의 경우 VPN 06의 4byte 위치에 있으므로, 가상 주소의 16*6 + 4 = 100Byte에 위치해 있음을 알 수 있다.
이때 TLB가 텅 비어 있을 것이므로 TLB Miss가 발생하면, Page Table을 뒤져 VPN이 어떤 PFN에 연결되어 있음을 나타내는 PTE를 받아 TLB에 Insert 해주고, 다시 메모리 액세스 루틴을 실행해 TLB Hit되어 a[0]에 빠르게 접근할 수 있다.
Retrial 때문에 같은 일을 두 번 하는 것 같지만, a[1], a[2]은 a[0]이 포함된 VPN 06에 같이 포함되어 있기 때문에 TLB Hit가 되어 굳이 Page Table을 돌아 보지 않더라도 VPN 06이 어떤 PFN에 연결되어 있는지 알기 때문에 빠른 시간 안에 주소 변환을 수행할 수 있다.
그런데 a[3]의 경우,, VPN 06이 아닌 VPN 07에 포함되어 있기 때문에 일단 TLB Miss가 발생하고, VPN 06을 Page Table로부터 검색해 연결 정보를 TLB에 Insert, Retrial한 후에야 a[3]~a[6]에 걸쳐 TLB Hit가 발생한다.
a[7]도 마찬가지로, TLB Miss가 한 번 발생한 다음 a[7]~a[9]에 대한 TLB Hit가 발생한 후에 해당 코드 부분이 종료된다.
위에선 Retrial을 강조하기 위해 맨 처음 TLB Miss가 발생한 후에 TLB Hit가 발생하는 것도 각각 1회씩 발생하는 것으로 쳐줬는데, TLB Miss가 발생하면 TLB Hit에 비해 매우 긴 시간이 소요되므로 그냥 TLB Miss 한 번으로 치면 아래와 같이 TLB가 작동한다고 할 수 있다.
Miss(0), Hit(1), Hit(2), Miss(3), Hit(4), Hit(5), Hit(6), Miss(7), Hit(8), Hit(9)
10번중 7번이 Hit, 총 70%의 TLB Hit율을 보이고 있다. 좀 극단적이기는 한데 TLB Hit시 1ms, TLB Miss시 100ms만큼 시간이 소요된다고 하면, TLB가 없을 때에는 10*100ms = 1000ms가 소요되는 반면 TLB가 있을 때에는 7*1ms + 3**100ms = 307ms로 실행 시간 측면에서 매우 큰 차이가 날 것을 예상할 수 있다.
이렇듯 서로 인접해있는 데이터들이 한 프레임 안에 속해 있어 TLB Hit의 이점을 보는 상황을 Spatial Locality(공간 지역성)이라고 한다. 만약 같은 지점에서 배열이 시작하는데 페이지 크기가 두배였다면? a[0]에서 Miss 한 번이 발생한 후 a[2]~a[6]까지는 TLB Hit, a[7]에서 Miss 한 번, a[8], a[9]에서 Miss가 발생해 아래와 같이 TLB가 작동했을 것이다.
Miss(0), Hit(1), Hit(2), Hit(3), Hit(4), Hit(5), Hit(6), Miss(7), Hit(8), Hit(9)
아까와 같은 상황이라 가정하고 총 소요 시간을 계산해보면, Miss 2번에 Hit 8번이므로 총 208ms, 페이지 크기가 증가함에 따라 공간 지역성의 이득을 더 볼 수 있게 된다.
또, 위의 코드가 만약 아래와 같이 작성되어 있었다면 어떤 양상을 보일까?
int sum1 = 0;
int sum2 = 0;
for (i = 0; i < 10; i++) {
sum1 += a[i];
}
for (i = 0; i < 10; i++) {
sum2 += 2 * a[i];
}위에서는 아까와 마찬가지로 sum1에 배열 a의 모든 요소들을 더해주고, 이어서 sum2에 모든 요소들의 두 배에 해당하는 값을 더해주도록 수정되었다.
이때 TLB가 없었더라면, 배열 a에 두 배 많이 접근하기 때문에 당연히 2*10*100ms=4000ms가 소요되었을 것이다.
그런데 만약 TLB가 도입된다면? 맨 처음 나타난 a[0], a[3], a[7]의 TLB Miss를 제외하면 나머지 모든 메모리 접근이 TLB Hit가 된다. 아래와 같이!
Miss(0), Hit(1), Hit(2), Miss(3), Hit(4), Hit(5), Hit(6), Miss(7), Hit(8), Hit(9) // sum1
Hit(0), Hit(1), Hit(2), Hit(3), Hit(4), Hit(5), Hit(6), Hit(7), Hit(8), Hit(9) // sum2
20번중 Miss가 3번, Hit가 17번이므로 총 317ms, 무려 10배 이상 소요 시간이 단축되었다. 만약 이 코드의 뒤에서 또 배열 a에 접근한다? 그럼 TLB에 이 연결 정보가 저장되어 있기 때문에 전체적으로 더 빠르게 프로그램을 실행할 수 있게 될 것이다.
이를 Temporal Locality(시간 지역성)이라 하는데, 한 번 참조된 프레임이 짧은 시간 내에 다시 한 번 참조되는 것을 의미하며 같은 메모리에 대한 접근 횟수가 늘어날수록 더욱 부각될 것이다.
이렇듯 TLB를 비롯한 모든 Caching 기법들은 이 Spatial Locality와 Temporal Locality를 통해 성능 향상을 꾀한다고 할 수 있겠다. 다만 저번에 배운 Fragmentation 문제와 마찬가지로, 시스템을 구축하는 시점에 이러한 지역성을 고려하는 것이 불가능하기 때문에 가능하면 일반적으로 최대한 잘 맞아떨어질 것 같은 상황을 유지시키는게 핵심이고, 그렇기에 위에서 얘기한 TLB 교체 정책이 중요한 것이다. 자주 쓰일 것 같은 Entry를 TLB에 남겨 놓는게 이득이니까.
19.3. Who Handles The TLB Miss?
이 TLB Miss는 어디서 처리하는 걸까? HW? SW?
Hardware-managed TLB Miss Handling
둘 다 가능한데, HW가 처리해야 하는 경우 두 가지 정보를 정확하게 HW가 알고 있어야 한다.
첫째로 Page Table의 위치를 의미하는 PTBR, 그리고 Page Table의 정확한 형태의 두 가지를 알고 있어야 하는데, 이 정보를 통해 아래의 과정을 거쳐 TLB Miss를 처리한다.
- Page Table의 위치를 알고 있으므로, Page Table을 순회한다.
- 원하는 PTE를 찾으면, 이를 PFN으로 적절히 변환해준다.
- 이 PTE를 TLB에 Insert(Update)해주고,
- 다시 메모리 액세스 루틴을 처음부터 실행해준다.
이런 방법을 사용하는 부류를 CISC(Complex-instruction set computers)라 하는데, 예나 지금이나 콤퓨타 만지는 사람들 중에 요상한 사람들이 많았는지 HW 설계자들이 OS 개발자를 못믿어서(...) HW가 복잡한 명령어를 통해 TLB Miss를 처리하도록 설계한 것이라고 한다.
Intel x86 CPU가 HW로 관리되는 TLB의 대표적인 예인데, 이런 단순한 TLB가 아니라 다음 장에서 배울 Multi-Level page table을 사용한다고 한다.
Software-managed TLB Miss Handling
SW, 그러니까 OS로도 TLB Miss의 handling이 가능하다.
CISC보다 상대적으로 최근에 나왔고, 덜 복잡한 RISC(Reduced instruction set computers)에서 SW 기반 TLB Miss handling을 사용한다고 한다.

위와 같이 작동하는데, 일단 TLB Miss가 발생하면 RaiseException(TLB_MISS)를 통해 Trap을 발생시킨다. 그 다음으로는 다른 Trap handling 과정과 거의 유사하다.
- TLB Miss Trap이 발생하면, OS는 User mode를 Kernel mode로 전환한다.
- Kernel mode로 전환되었으므로, 사전에 HW에 알려놓은 Trap handler를 실행한다.
- 이 Trap handler가 Page table 검색을 수행하여 원하는 PTE를 찾는다.
- PTE를 기반으로, TLB 접근이 가능한 Privileged instruction을 사용해 TLB를 갱신한 후 반환한다.
- 다시 user mode로 전환하고, 아까 실행에 실패한 명령어를 다시 실행한다.
- TLB Hit!
여기서 좀 특이한게, 다른 Trap handler와 달리 TLB Miss trap handler는 핸들링 후에 PC값이 다음 명령어로 넘어가는게 아니라 어딘가에 저장해 두었다가 다시 그 명령어를 실행하도록 되어 있다는 점이다.
방금 알게된건데, 재채기가 나오던 도중에 혀를 깨물면 재채기가 멎는다.
어떻게 알았냐고? 알고 싶지 않았다..
푸에ㅔㅅ취!
또 다른 신선한 문제점이 있는데, TLB Miss handler 자체에 접근하려는데 TLB Miss가 나버리면? TLB Miss를 해결하기 위해 TLB Miss Handler를 찾으려 하고, TLB Miss Handler가 없으니 TLB Miss가 나고, ... 이걸 무한히 반복하게 될지도 모른다.
두 가지 해결 방안이 있는데, 첫째로 TLB Miss handler의 위치를 가상 주소가 아니라 반드시 물리 주소로 표현하는 방법이 있다. VPN-PFN 연결 관계를 없앴다고 해서 이를 unmap이라 하는데, unmap되어 있어 PFN을 그대로 가지고 있으면 주소 변환을 거칠 일이 없으니 TLB Miss Handler의 TLB Miss에 대해서는 걱정할 필요가 없다.
둘째로 TLB의 일부를 아예 손댈 수 없는 영역으로 못박아놓고 교체되지 못하도록 막아 이 안에 TLB Miss Handler를 넣어 놓는 방식인데, 이걸 wired 되었다고 한다. 이렇게 하면 적어도 TLB Miss Handler가 저장된 위치는 훼손될 일이 없으니, 항상 TLB Hit가 됨을 보장 받을 수 있게 된다.
HW managed vs SW managed
CISC 방식의 HW-managed TLB Miss handling과 달리, RISC 방식에서는 HW에 루틴을 미리 납땜으로 박아 놓은게 아니라 부팅시 Trap handler를 등록해 놓는 구조이기 때문에 Page table을 구현하기만 한다면 원하는 자료구조를 HW 변경 없이 사용할 수 있으며(flexibility), handling의 주체 역시 HW가 직접 뭘 처리하는건 없고 OS의 TLB Miss handler 코드가 이를 처리한다(simplicity)는 차이점이 있다. HW의 작동도 수도 코드로 표현해서 차이점이 살짝 미묘한데,, 잘 짚고 넘어가자.
19.4. TLB Contents: What's In There?
HW TLB를 좀 더 자세히 들여다 보자.
일반적으로 TLB는 32, 64, 128개의 TLB를 포함하며, Fully Associative 방식으로 설계된다. Fully Associative가 뭔지 잘 모르겠다고? 엄청 잘 설명되어 있는 좋은 글을 발견해서 링크를 걸어놓겠다. 머싯따,,! 이 Fully Associative 방식을 대충 쉽게 설명하자면 그냥 보통 생각하는 배열처럼 TLB를 놓고, 넣고 싶은 위치에 PTE를 그냥 넣으면 되는 것이다.
또한 TLB에 원하는 요소가 있는지 VPN으로 검사하는 과정을 Page Table을 하나하나 뒤지는 것처럼 수행하는게 아니라, 병렬적으로 검색할 수 있게 만들어져 있다고 한다. 그래서 빠른거구나!
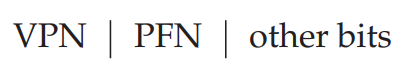
TLB의 각 요소는 위와 같은 구조를 가지고 있는데, VPN-PFN이야 익숙하지만 other bits는 또 무엇이란 말인가!
이 other bits에는, 해당 연결 정보가 유효한지 표시하기 위한 Valid bit, 페이지에 어떤 접근이 허용되는지 표시하기 위한 Protection bit, 이외에도 해당 PTE가 어느 프로세스에 종속되어 있는지 나타내기 위한 ASID(Address-space Identifier), Dirty Bit 등이 저장되어 있다고 한다. 다음 절에서 좀 더 자세히 살펴보자.
19.5. TLB Issue: Context Switches
지금까지는 하나의 프로세스에 대한 TLB 이슈만 다루었는데, 당연히 여러 개의 프로세스에 대해서도 잘 작동할 수 있어야 한다. 즉, Context switching이 발생할 때 TLB의 관리를 어떻게 해야 할지 생각해두어야 한다.
각각의 프로세스는 (Code 등을 제외하면 일반적으로) 서로 겹치지 않는 독립적인 주소 공간을 가지고 있기 때문에 TLB도 당연히 독립적으로 운영되어야 한다. 따라서 두 프로세스의 주소 공간은 마치 해당 프로세스가 시스템 전체를 점유하고 있는 것처럼 착각하고 있기 때문에, 두 프로세스 1, 2가 VPN 10을 사용할 수도 있다.
ASID
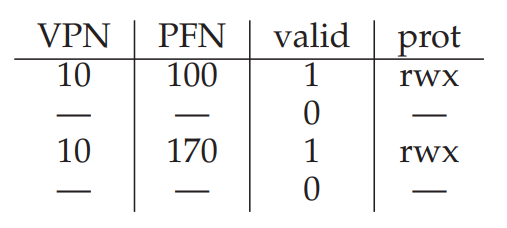
예를 들어 위와 같이 프로세스 1의 VPN 10이 PFN 100에, 프로세스 2의 VPN 10이 PFN 170에 연결되어 있다면, 프로세스 1에서 사용하던 TLB를 프로세스 2에서도 사용할 수 있을까?
⚡ 아 그전에, 교수님께서 강조하셨던 내용인데 TLB의 Valid bit와 Page Table의 Valid bit가 이름이 같다고 해서 같은 값이라고 절대 혼동해서는 안된다.
💡 Page Table에서 Valid bit가 0인 경우 해당 VPN을 가지는 가상 주소 공간이 사용되고 있지 않음을 의미하고, TLB의 Valid bit가 0인 경우에는 TLB에 올라가있는 해당 연결 정보가 유효하지 않음을 의미한다.
두 가지 해결 방안이 있다.
첫 번째는 Context switching이 발생할 때마다 TLB의 Valid bit를 싹 0으로 밀어 버리는 것이다.
TLB의 Valid bit가 0이면 해당 PTE를 사용하지 않는다는 의미이므로 빈 칸처럼 취급되어 다른 프로세스가 TLB Miss를 일으키면 그냥 그 위치에 PTE를 덮어 써주면 된다.
그러나 이 작업도 공짜로 수행되는게 아니기 때문에, Context switching이 발생할 때마다 모든 Entry의 Valid bit를 0으로 밀어버리는 것도 꽤 큰 부담이 될 수 있다.
따라서, 아예 처음부터 ASID(Address Space Identifier)를 두어 해당 TLB Entry가 어느 프로세스에 소속되어 있는 정보인지를 기록하면, Context switching이 발생할 때마다 valid bit를 싹 0으로 밀어주는 작업을 할 필요가 없다. 만약 현재 실행중인 프로세스의 ASID가 아닌 다른 Entry를 발견하면 valid이든 말든 그냥 덮어 써버려도 상관 없으니까!
대신 PID(Process Identifier)가 32bit로 너무 길기 때문에, TLB에서는 이걸 8bit로 줄인 ASID를 사용한다. 이 ASID까지 TLB에 추가하면 아래와 같이 구성될 것이다.

이제는 VPN이 같더라도 ASID 필드가 다르기 때문에, 서로 다른 프로세스에 종속된 변환 정보임을 제대로 식별할 수 있게 되었다.
TLB Entry 공유
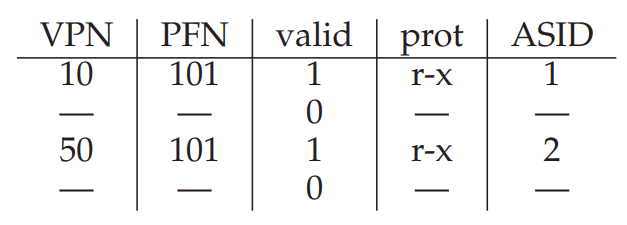
반대로 이번엔 서로 다른 프로세스에 종속된 VPN이 Code와 같은 공통의 PFN을 가리킬 수 있다면 어떨까?
Segmentation에서 비슷한 사례를 보았듯 공간 측면에서 효율적일 것이다. 왜냐? 중복된 데이터를 굳이 두 번 저장하지 않으니까!
19.6. Issue: Replacement Policy
아까 잠깐 얘기했었는데, Caching의 이점은 크게 Spatial Locality, Temporal Locality 두 관점에서 취하는 것이라 할 수 있다.
그러나 시스템을 만드는 시점에서 이 두 관점에서 최적의 결과를 내는 것은 불가능하므로 일반적으로 잘 먹힐만한 전략을 세우는 것이 중요한데, 이중 Temporal locality의 경우 자주 접근되는 데이터는 계속 TLB에 남아 있으면 좋다고 달리 말할 수 있겠다.
즉 TLB의 크기가 한정되어 있기 때문에 TLB_Insert가 수행될 때 어떤 TLB Entry를 끌어내려야 할지 결정하는 Cache Replacement 정책을 잘 결정해야 한다는 것인데, 예전부터 사용되어 왔던 흔한 방법으로 LRU(Least-Recently Used)가 있다.
이름에서 알 수 있듯 최근에 가장 덜 사용된 Entry를 교체하겠다는 정책으로, 이는 사용되지 않은 Entry가 앞으로도 사용될 가능성이 적으므로 다른 Entry로 대체되는 것이 TLB Hit ratio에 도움이 될 것이라는 가정에 근거한다.
또 랜덤하게 교체할 Entry를 정하는 정책을 선택할 수도 있는데, 재밌게도 LRU처럼 합리적인 정책으론 해결하기 어려운 상황을 무작위성을 통해 쉽게 해결할 수도 있다.
예를 들어 크기가 N인 TLB를 가지고 N+1 페이지에 한 번씩 접근하는 반복문을 여러번 실행한다면?
맨 처음 TLB Miss가 발생해 TLB Insert를 기껏 해놨는데, 다음에 해당 변수에 접근하려고 하면 다른 Entry들에 밀려서 또다시 TLB Miss가 반드시 발생하는 최악의 상황을 맞이하게 될 것이다.
이에 비해 랜덤하게 교체할 Entry를 정한다면, 시행 횟수가 충분히 많다는 가정 하에 평균적으로 어느정도 쓸만한 성능을 보여줄 것이다.
이에 대한 자세한 내용 역시 다음에 배울 것이므로, 지금은 오~~ 하고 넘겨도 된다. 오~~
19.7. A Real TLB Entry
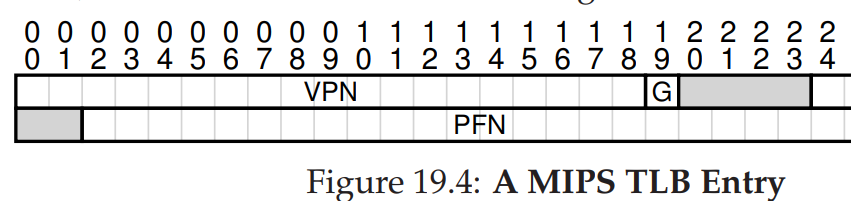
기운이 달려서 강의 시간에 말씀해주신 부분에 대한 설명만 남긴다. 후더ㅏㄹ덜,,
위에서 볼 수 있듯 MIPS(MIPS R4000)의 TLB Entry에서는 32bit 주소 공간에 4KB 크기의 페이지를 지원하는데, 32bit로 표현할 수 있는 가상 주소 중 2^(2+10), 12bit를 페이지 내의 Offset을 표현하기 위해 사용하므로 20bit를 사용해 총 2^20개의 VPN을 가질 수 있을 것으로 예상할 수 있다.
그런데 MIPS R4000에서는, 19bit만 VPN을 표현하는데 사용하고, 주소 공간의 절반은 사용자 프로세스가 아니라 커널이 사용하도록 한다고 한다. 신기해라,,
마무리
지난 장에서 배운 Paging 기법의 최대 단점인 느린 속도를 해결하기 위한 TLB 기법에 대해 공부했다.
속도 측면에서는 해결했지만, 몇 가지 흥미로운 이슈들이 아직 남아있다.
아까 공부하다가 특히 좀 걸리적거린 부분인데, TLB Miss가 발생하면 TLB_Insert 후 다시 명령어를 실행하는 짧은 틈새 동안에 너무 많은 프로세스들이 TLB에 우루루 Miss/Insert/Retry를 수행해 정작 다시 돌아왔을 때 내가 방금 넣어 놓은 TLB Entry가 존재하지 않는다면? 예상한 것보다 훨씬 많은 TLB Miss가 발생해 성능에 문제가 발생할 것이다. 이런 상황을 TLB Converage를 벗어난 상황이라고 하며, 더 큰 페이지 크기를 지원하도록 하여 해결하는 방법을 다음 장에서 배운다.
두 번째로 나와 있는 내용은 사실 무슨 말인지 못알아들어서(...) 그냥 Copy&Paste 해놓겠다. 이쪽에 관심이 많다면 읽어보는 것도 좋겠다.
One other TLB issue worth mentioning: TLB access can easily become a bottleneck in the CPU pipeline, in particular with what is called a physically-indexed cache. With such a cache, address translation has to take place before the cache is accessed, which can slow things down quite a bit. Because of this potential problem, people have looked into all sorts of clever ways to access caches with virtual addresses, thus avoiding the expensive step of translation in the case of a cache hit. Such a virtuallyindexed cache solves some performance problems, but introduces new issues into hardware design as well. See Wiggins’s fine survey for more details [W03].

잘보고 있습니다.. 도움이 많이 되고 있어요 감사합니다~