
Alo. 이몸 부활!
시험 끝난 직후에 바로 정리해볼까 했는데, 앞에서 그랬던 것처럼 미리 앞 내용을 들어 놓은 상태에서 정리해야 더 깊이 이해가 되는 것 같아 살짝 미뤘다. 미룬다는게 그만,, 예상보다 일주일 정도 더 밀렸지만.
앞선 CPU Virtualization 강의에서 각각의 실행 중인 프로그램을 프로세스라는 단위로 추상화해서 다루어 봤는데, 이번에는 프로세스가 한 순간에 여러 지점(PC)을 실행하는 단위인 Thread에 대해 배울 것이다.
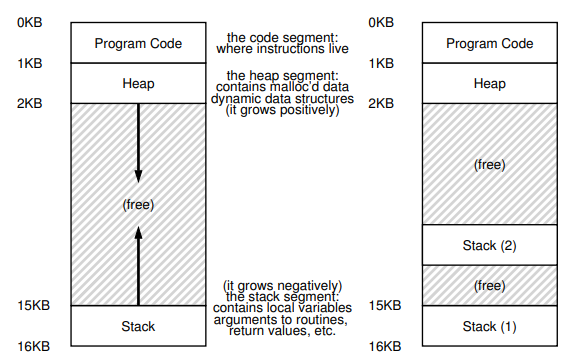
프로세스 각각이 서로 독립적인 단위이므로 프로세스끼리 상태를 주고 받기 위해 별도의 외부 요소가 필요했다면, 프로세스에 소속되는 쓰레드들은 각각의 PC, 스택 영역들은 각자 가지고 있지만 힙 영역을 공유할 수 있으므로 별도의 요소 없이 데이터를 공유할 수 있다. 대신 쓰레드끼리도 프로세스에서 그랬던 것처럼 서로 번갈아가며 실행해야 하기 때문에 Context switching시 PC, 레지스터 상태 등을 TCB(Thread Control Block)에 저장할 수 있어야 한다.
26.1. Why Use Threads?
"쓰레드를 왜 쓰는가?"
글쎄, 굳이 같은 작업을 나눠서 하는데 프로세스에 해당하는 메모리 영역을 몽땅 점유할 필요가 없을 수도 있고, 프로세스로 작업을 나누는 순간 힙이든 스택이든 코드든 죄다 Context switching시 일괄적으로 Store/Restore 되어야 하고, 위에서 얘기했듯이 프로세스는 서로 독립적으로 작동하기 때문에 서로를 연결하기 위한 부가적인 장치가 또 필요해진다.
반면 쓰레드를 사용하면? 메모리야 재귀 함수를 어ㅓㅓㅁ청나게 많이 호출하지 않는 이상 어지간하면 프로세스에 주어진 메모리만으로 보통은 충분할 것이고, 전체 주소 공간을 Store/Restore하는 것이 아니기 때문에 Context switching에도 비교적 적은 비용이 들며, 결정적으로 공유할 수 있는 메모리 공간이 있기 때문에 작업을 분할해서 수행하는데 훨씬 적합하다. 어떤가!
#include <stdio.h>
#include <assert.h>
#include <pthread.h>
#include "common.h"
#include "common_threads.h"
void *mythread(void *arg) {
printf("%s\n", (char *) arg);
return NULL;
}
int main(int argc, char *argv[]) {
pthread_t p1, p2;
int rc;
printf("main: begin\n");
Pthread_create(&p1, NULL, mythread, "A");
Pthread_create(&p2, NULL, mythread, "B");
// join waits for the threads to finish
Pthread_join(p1, NULL);
Pthread_join(p2, NULL);
printf("main: end\n");
return 0;
}다 좋은데, 이 쓰레드를 사용하려면 해결해야 하는 몇 가지 복잡한 문제들이 더 생긴다. 이전에도 비슷한 예제를 살펴봤는데, 위 예제는 그냥 두 쓰레드를 생성해서 인자로 주어진 문자열을 출력하는 코드이다. 뜯어보자!
Pthread_create(&p1, NULL, mythread, "A");- 여기서 첫 번째 인자 &p1은 위에서 쓰레드와 통신하기 위한 API로 사용하는 pthread_t 객체를 넘겨 실행할 쓰레드를 생성한 것이고,
- NULL 자리에는 쓰레드를 생성할 때 별도의 옵션을 주지 않고 OS가 알아서 제어하도록 한다는 의미이며,
- mythread는 해당 쓰레드가 수행할 작업을 함수로 넘겨준 것이다. (함수의 이름을 넘겨준다는 것은 함수의 명령어가 저장된 코드 영역의 주소를 반환하는 것이고, void * 로 표시된 반환형과 arg의 자료형은 C언어에서 표현할 수 있는 가장~~ 일반화된 자료형이어서 위와 같이 함수 안에서 적절히 Casting해서 사용할 수 있게된 것이다.)
- 마지막으로 주어진 인자는 mythread에 전달할 인자, 그러니까 쓰레드가 출력할 문자열이다.
이 부분을 공부할 때 "Pthread_create도, Pthread_join도 쓰레드의 시작을 의미하는 것이 아니다."라는 말이 참 헷갈렸었다.
Pthread_join은 p1, p2를 만든 Main thread가 해당 코드 부분을 PC로 가리키게 되면 그 쓰레드가 끝날 때까지 머물러서 기다린다는 의미라는데, 그럼 어디서 시작한다는 말인가? p1과 p2의 선언 부분?
정답은 "아무도 모른다" 였다. 왜냐? 아래의 가능한 실행 순서(Thread trace)를 보면 알 수 있다.

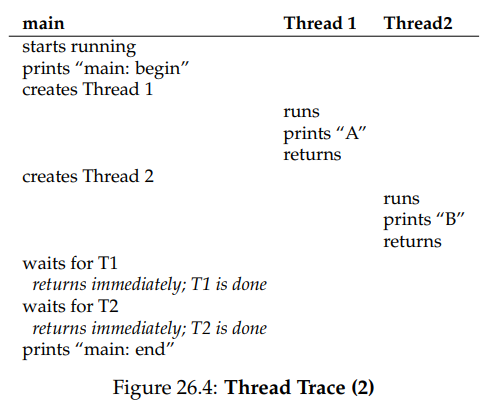
읽어보면 알겠지만 위 Thread trace 전부 가능한 시나리오이다.
starts running, main: begin까지는 모두 같으나 26.3에서는 Thread 1이 만들어진 다음 Thread 1이 아닌 Main Thread가 스케줄러로부터 선택받아 Thread 2를 만들게 된 것이고, 이후 Pthread_join(p1, NULL);에 도달해 T1이 끝날 때까지 기다리는 상태에서 Thread 1으로 Context switching이 발생했다. 그 다음으로 Thread 1이 할 일을 마친 뒤에 Main Thread로 제어권이 넘어가 이번엔 Pthread_join(p1, NULL);에 도달했고, 마찬가지로 Thread 2가 할 일을 마친 뒤 혼자 남은 Main Thread에게로 제어권이 다시 돌아가 프로그램이 최종적으로 종료되었다.
반면 26.4에서는 Thread 1이 만들어진 직후에 스케줄러로부터 선택받아 할 일을 마친 뒤 먼저 종료(반환)되어 버리고, 이어서 Thread 2가 만들어지자마자 할 일을 마친 뒤 Main Thread에게로 제어권이 돌아갔기 때문에 T1과 T2를 기다리는데 시간을 소요하지 않고 바로 Main Thread가 종료되었다.

심지어 Thread 1이 먼저 생성되었음에도 Thread 2가 먼저 선택받을 수 있으므로 A B가 아니라 B A 순서대로 출력될 수도 있는데, 이렇듯 시스템의 상태에 따른 스케줄러의 작동 결과에 따라 실행 순서도 달라져버리니 전체적인 실행 결과를 예측할 수 없는 것은 당연하다.
26.3. Why It Gets Worse: Shared Data
쓰레드를 사용했을 때의 이점으로 별도의 장치 없이 쓰레드들이 공유하는 힙 영역의 데이터에 마음껏 접근할 수 있다는 점을 꼽았었는데, 이게 보기보다 엄청 골치아픈 문제를 일으킨다.
#include <stdio.h>
#include <pthread.h>
#include "common.h"
#include "common_threads.h"
static volatile int counter = 0;
// mythread()
//
// Simply adds 1 to counter repeatedly, in a loop
// No, this is not how you would add 10,000,000 to
// a counter, but it shows the problem nicely.
//
void *mythread(void *arg) {
printf("%s: begin\n", (char *) arg);
int i;
for (i = 0; i < 1e7; i++) {
counter = counter + 1;
}
printf("%s: done\n", (char *) arg);
return NULL;
}
// main()
//
// Just launches two threads (pthread_create)
// and then waits for them (pthread_join)
//
int main(int argc, char *argv[]) {
pthread_t p1, p2;
printf("main: begin (counter = %d)\n", counter);
Pthread_create(&p1, NULL, mythread, "A");
Pthread_create(&p2, NULL, mythread, "B");
// join waits for the threads to finish
Pthread_join(p1, NULL);
Pthread_join(p2, NULL);
printf("main: done with both (counter = %d)\n", counter);
return 0;
}휴! 코드 참 길다.
요약하자면, 아까와 마찬가지로 두 스레드 p1, p2를 생성한 다음 각각의 스레드가 힙 영역에 있어 공유되는 전역 변수 counter에 1씩 더해주는(counter = counter + 1;) 코드이다.
다만 각각의 스레드가 10의 7승이나 되는 꽤 큰 횟수만큼 counter에 1을 더해주는 상황인데,, 앞에서 A와 B의 시작/종료 시작이 스케줄러의 작동에 의해 결정되므로 비결정적인건 그렇다 치더라도 결과로 2 * 10^7이 출력되어야 할 것 같은데 이에 못미치는 경우가 훨씬 많을 것이다.
보통 프로그래밍을 하다가 뭔가가 잘못되면 컴퓨터가 잘못한게 아니라 멍청한 사람이 잘못한 것이다. 무슨 잘못을 저지른건지,, 까보자,,
26.4. The Heart Of The Problem: Uncontrolled Scheduling
Python이나 Java 같은 managed language에 비해 처음 접하는 사람들은 공감이 안될 수도 있겠지만, C언어도 나름 기계어/어셈블리어에 비하면 사람이 사용하는 자연어에 가까운 고오급 언어이기 때문에 결국은 기계가 알아들을 수 있는 기계어/어셈블리어로 번역(Compile) 되어야 한다.
애초에 고급 언어와 저급 언어 사이에 간극이 좁았다면 기계어로 코딩했겠지? 이 고급 언어가 저급 언어와 statement 단위로 일대일 매칭이 되는게 아니라서, C언어로 한줄짜리 코드가 컴파일 해놓고 보면 2개 이상의 명령어로 구성되는 경우가 매우 많다. 아래와 같이!
mov 0x8049a1c, %eax
add $0x1, %eax
mov %eax, 0x8049a1cx86에서 counter = counter + 1;에 해당하는 부분을 어셈블리어로 번역하면 위와 같다.
맞는 해석인지 모르겠는데, 영어에서 보통 from A to B,, 이런 식으로 많이 쓰니까 mov 명령어의 인자도 mov A, B가 from A, to B로 외워버렸다.
그럼? 맨 윗줄은 메모리 어딘가(0x8049a1c)의 값을 범용 레지스터에 해당하는 %eax에 쓴 다음(1), 이 값에 1($0x1은 상수!)을 써주고(2), 다시 %eax의 값을 원래 있던 메모리 위치(0x8049a1c)에 써주는(3) 작업이라 할 수 있겠다.
각각의 명령어가 몇바이트 단위로 위치해 있어서 CPU의 PC가 이걸 하나씩 가리켜가며 한 틱마다 실행시키다보니까,, 예상과 달리 한 time slice 안에 mov, add, mov가 전부 실행되지 않고 mov나 add까지만 실행했는데 갑자기 다른 쓰레드로 뿅! 하고 넘어가버릴 수가 있다.
이게 왜 문제가 되느냐? 0x8049a1c가 Heap 영역에 들어 있는 count 전역 변수라 하고, 아래와 같은 순서로 스케줄링되어 각각의 스레드가 독립적으로 작업했다고 생각해보자. 당연히 T1과 T2가 한 루프만큼 돌면 count에 값이 1씩 누적되어 값이 50이었으면 쓰레드당 1씩 총 2씩 증가, 결과가 52가 되리라 기대했을 것이다.
| 실행중인 스레드 | count(0x8049a1c) | T1 상태 | T1의 %eax | T2 상태 | T2의 %eax |
|---|---|---|---|---|---|
| T1 | 50 | mov 0x8049a1c, %eax | 50 | ready | 49 |
| T2 | 50 | ready | 50 | mov 0x8049a1c, %eax | 50 |
| T1 | 50 | add $0x1, %eax | 51 | ready | 50 |
| T2 | 50 | ready | 51 | add $0x1, %eax | 51 |
| T1 | 51 | mov %eax, 0x8049a1c | 51 | ready | 51 |
| T2 | 51 | ready | 51 | mov %eax, 0x8049a1c | 51 |
엥? T1 T2를 번갈아가면서 실행한 것 뿐인데 값이 52가 아니라 51이 되었다!
T1이 값을 쓰기 전에 T2도 같은 값을 레지스터에 저장해 놓았는데, T1이 값을 쓴 것을 T2는 따로 알 수 없기 때문에 마찬가지로 50에 1을 더한 51을 그냥 count에 덮어썼기 때문이다.
이렇듯 같은 메모리에 다수의 프로세스가 접근하려는 상황을 Race condition이라 하고, Race condition이 발생한 구간의 코드에 해당하는 저 세 줄을 Critical Section이라고 한다.
방금 배운 용어로 상황을 정리하자면, T1과 T2가 count = count + 1;에 해당하는 Critical section에 동시에 접근하는 Race condition이 발생해 원하는대로 결과가 나오지 않는, Indeterminate한 상황이라 할 수 있겠다.
해결책 자체는 쉽게 떠올릴 수 있는데, T1이 해당 critical section에 접근할 때는 T2가 접근하지 못하게 막고, T2가 접근할 때는 T1이 접근하지 못하도록 하면 되지 않을까?
Critical section에 한 번에 한 쓰레드만 접근할 수 있도록 하는 성질을 Mutual Exclusion(상호 배제)라 하며, 이것이 보장되어야 우리가 원하는 결과를 얻을 수 있다.
여기 나온 용어들은 그 유명한 다익스트라님께서 처음 만들어 사용하셨다고 한다. 이걸로 튜링상을 받으셨다고,,,
26.5. The Wish For Atomicity
위의 Race condition 문제가 왜 발생한걸까?
화두에 C언어 한 줄이 기계어 여러 줄로 번역되어서라고 했으니까, C언어 한줄이 기계어 한줄에 대응되도록 처음부터 명령어를 만들면 될 일 아닌가?!
memory−add 0x8049a1c, $0x1이러한 명령어를 Atomic하다고 한다. DB에서도 그렇고, 보통 컴퓨터과학에서 더이상 쪼갤 수 없는 성질을 말할 때 자주 쓰는 단어같다.
이는 말 그대로 더이상 쪼갤 수 없는 명령어의 단위이므로, 위의 상황과 달리 명령이 실행되다 말고 다른 쓰레드로 넘어갈 수 있는 가능성 자체가 없어졌음을 의미한다. 실행되거나, 아예 실행이 안되거나 둘 중 하나라는거지.
근데 기계어 명령어 셋(ISA, Instruction Set Architecture)을 만들면서 어떤 상황에서 어떤 Race condition이 발생할줄 알고 그걸 미리 다 준비할 수 있겠는가? 만약 가능하다고 하더라도,, 저번 학기에 크게 고통받은 B Tree의 삽입/삭제 명령을 Atomic하게 만든다? 말도 안될 일이다. 어우 그걸?
그렇기 때문에 ISA를 정의할 때에는 Synchronization primitives라는, 병렬 실행에 필수적인 기능을 구현하는데 필요한 명령어만 만들어놓고 이를 처리할 수 있도록 해두었다. (다음에 배운다!)
26.6. One More Problem: Waiting For Another
26.5절에서 같은 메모리에 동시에 접근하는 문제를 발견했는데, 그런 경우 말고도 어떤 쓰레드가 I/O 등의 다른 작업을 마칠 때까지 다른 쓰레드들이 일괄적으로 대기해야 하는(sleep) 경우에 대해서도 고려해야 한다.
마무리
휴! Concurrency에 대한 주제로 OS 공부를 다시 시작하게 되었다.
정리하자면 별도의 외부 요소 없이 작업을 분할해서 실행하기 위해 프로세스 내부에 쓰레드라는 것을 만들어서 병렬적으로 실행할 수 있도록 할 수 있는데, 이때 별도의 조치 없이는 쓰레드 간의 실행 순서를 보장할 수 없고, 공동의 자원에 접근했을 때 의도한 대로 작동하지 않을 수 있으며, 다른 쓰레드가 작업을 마칠 때까지 일괄적으로 기다릴 수 있는 기능 또한 필요하다고 할 수 있겠다.
그나저나 지난 중간 시험때 친구가 누가 정리해둔 글을 보면서 OS 시험 공부를 하고 있었다는데, 내용도 같은 교수님 강의 듣는 것 같고 글머리나 사진들이나 닉네임이나 어디서 많이 본 것 같아서 설마 하고 아이디를 확인했더니 짜잔,, 나였다고 했다. ㅋㅋㅋㅋㅋㅋ 그렇게 티가 많이 나나,,? 야! 박가야! 보고있냐?
혼자 공부하려고 남기고 있었는데, 누가 포스트를 읽고 도움을 받았다고 하니까 두배로 보람차다. 되는대로 OS 말고 요즘 공부하고 있는 Spring이라던지, 다 까먹은 것 같은 Django라던지 이것저것 정리해봐야겠다.
