
이전 몇 장에 걸쳐 Lock과 Condition variable을 활용한 동기화 기법에 대해 공부했다.
이번 장에서는 희대의 괴물 에츠허르 다익스트라가 고안한 동기화 기법인 Semaphore에 대해 공부해볼 것이다.
31.1 Semaphores: A Definition
세마포어는 기본적으로 정수 타입의 상태값을 가지는 객체로써, 아래와 같이 초기화한다.
#include <semaphore.h>
sem_t s;
sem_init(&s, 0, 1);sem_init의 첫번째 인자는 세마포어를 조작하기 위해 선언한 객체, 두번째 인자는 여타 다른 system call과 유사하게 실행 옵션(0인 경우 프로세스 내의 스레드 간에 세마포어를 공유), 마지막 인자는 위에서 얘기한 세마포어의 상태값을 의미한다.
이렇게 초기화된 세마포어는 sem_wait, sem_post를 통해 조작할 수 있다.
int sem_wait(sem_t *s) {
decrement the value of semaphore s by one
wait if value of semaphore s is negative
}
int sem_post(sem_t *s) {
increment the value of semaphore s by one
if there are one or more threads waiting, wake one
}직역하자면 sem_wait은 세마포어의 값을 1 내린 다음 그 값이 음수인 경우 wait 상태에 들어가며, sem_post는 세마포어의 값을 1 올려준 다음 대기중인 스레드가 있으면 그중 하나를 깨워주는 역할을 한다고 적혀 있다. 그리고 (지금은) 이 두 함수들 사이에 race condition이 발생하지 않는, atomic하게 실행됨이 보장된다고 생각하자.
참고로 여기서 sem_wait에 의해 wait 상태에 들어갈 때 앞에서 배운 spin을 쓰든, sleep 방식을 쓰든 상관이 없다. '기다리게 한다'는 기능에만 일단 집중하고 넘어가는게 오히려 좋을 것 같아서 굳이 한 번 더 남긴다!
둘째로 특정 시점에 세마포어 value를 조회했을 때 이 값이 음수 -k라면, 현재 wait 상태에 들어가 있는 스레드가 k개 존재하는 것과 같다. 이것도 위 단락과 비슷한 맥락으로 일단 머릿속에 넣어 놓고 시작하면 좋을 것 같다. 세마포어 자체가 Semaphore value에 의해 실행 흐름을 제어하는 것이라서 (공부하다보니까) 오히려 이걸 추상화해서 이해하는 것보다는 값을 기준으로 흐름을 따라가는게 오히려 쉽다.
마지막으로 세마포어를 사용한 프로그램의 thread trace를 하다보면 쉽게 잊을 수 있는 사실인데, 위의 단락에서의 설명처럼 우리야 종이에 Semaphore value를 눈으로 봐가며 쓱싹쓱싹 종이에 쓸 수 있지만 세마포어를 사용하는 프로시저 입장에서는 이 Semaphore의 value를 직접적으로 확인할 수 있는 방법이 없다. 그냥 wait/post를 호출할 뿐!
뒤쪽에서 이러한 blackbox스러운 특성 때문에 발생하는 문제가 있으므로, 지금은 까먹어도 되지만 나중엔 아차! 하고 떠올랐으면 좋겠다.
31.2 Binary Semaphores (Locks)
여기까지 읽어봤다면 알겠지만 뭔가 이전과 달리 세마포어 자체는 붕 뜬 느낌이 있다. 값을 올리고 내리고,, 스레드를 재우고 깨우고,, 나는 세마포어의 쓰임새가 한 번에 확 와닿지는 않았다.
그것도 그럴 것이 세마포어 자체는 딱 위에서 얘기한 기능만을 수행할 수 있는 무언가이고, 이걸 적절하게 사용함으로써 멀티 스레드 프로그래밍 환경에서 발생할 수 있는 여러 문제들을 해결하기 위해 탄생한 것이기 때문이다.
세마포어로 해결할 수 있는 첫번째 문제로 Binary semaphore를 살펴보자. 이름이 이렇게 되어 있어서 벌써 쫄리는 사람 좀 있을 것 같은데 그냥 기능적으로는 Lock과 동일하다고 생각해도 좋다. (이름에 대한 설명은 잠시 미룬다.)
sem_t m;
sem_init(&m, 0, 1);
sem_wait(&m);
// critical section here
sem_post(&m);그냥 바로 써놓긴 했는데, 세마포어를 초기화할 때 value를 1로 설정했다는 점이 가장 중요하다.
Lock과 같은 역할을 한다고 했으니 두 스레드가 critical section에 진입하려는 상황을 가정해보면 쉽게 이해할 수 있을 것 같다.

Critical section에 진입하려는 스레드 자체는 2개가 있는데 운좋게 race condition 없이 T0가 일단 다 실행해버리는 상황이다.
값을 보면 알겠지만 일단 T0가 sem_wait을 호출해 값을 먼저 내려주고 그 값이 음수가 아니므로(0) wait하지 않고 바로 반환된다. 한발짝 떨어져서 실눈 뜨고 바라보면 이전의 lock을 얻으려 대기하지 않고 바로 실행될 수 있는 상황이 연상된다.
그럼 뭐 별탈없이 lock을 얻었으니 critical section에 해당하는 코드를 모두 실행해주고, 할 일을 다 마쳤으면 lock을 풀어줘야겠지?
이때 T0가 sem_post를 호출해 일단 값을 올려주고(1) 대기중인 스레드가 있는지 확인해본 결과 어떤 스레드도 sem_wait에 의해 기다리고 있지 않으므로, 추가 작업 없이 반환하면 된다.
이해하기 쉽게 하려고 lock acquire/free의 관점에서 설명했는데, Semaphore와 lock을 같은 것으로 생각하기보다는 semaphore가 lock을 구현하는데 사용할 수도 있다고 받아들였으면 좋겠다. Semaphore 자체는 그냥 값을 1씩 올리고 내리며, 조건부로 호출자 스레드를 대기시키거나 대기중인 스레드를 깨우는 기계적인 역할만을 할 뿐이다.
위 예제에서는 운좋게 T0가 실행되는 동안 T1으로 context switching 되지 않았지만, 이번에는 T0가 실행되고 있는 도중에 T1도 동일한 critical section에 진입하려는 상황을 생각해보자.

우선 이전과 동일하게 T0가 먼저 실행되어 sem_wait을 호출하는데, 위에서 semaphore의 두 연산이 atomic하게 실행됨을 가정했으므로 문제 없이 값을 0으로 내린 후 대기 없이 lock을 걸어 놓고 critical section에 진입한 상황까지는 동일할 것이다.
그렇게 T0가 critical section을 룰루랄라 실행하고 있는 도중에,, OS에 의해 interrupt가 걸려 T1으로 갑자기 context switching이 발생했다!
그럼 이 T1도 T0와 동일한 critical section에 mutual exclusive하게 진입하고 싶어 하므로 sem_wait을 호출한다. 그러나 이전과 달리 semaphore value를 1만큼 내리고 나니 값이 -1이 되어 T1이 wait 상태(앞으로 sleep으로 가정)에 진입했으므로 T0으로의 context switching이 발생했다! (만약 spin 방법을 골랐다면 주어진 time slice만큼 마저 실행되었겠지?)
그럼 다시 실행 흐름을 돌려받은 T0가 마저 critical section을 모두 실행해준 다음, lock을 풀기 위해 sem_post를 호출하자 -1이었던 값이 0이 되며, 잠들어 있는 스레드(T1)가 있으므로 이걸 깨워서 Ready Queue에 넣어주었음을 확인할 수 있다.
이젠 T1도 깨어 있는 상태이므로 스케줄러의 선택을 받아 다시 실행될 수 있는데, 다시 실행되는 시점이 곧 sem_wait이 반환하는 부분이 되어 결과적으론 lock을 얻고 critical section을 실행하는 꼴이 된다.
다 쓰고나면? 다른 스레드도 위와 동일한 과정을 수행할 수 있도록 semaphore value를 1로 다시 올려주면 된다! (잠들어 있는 스레드가 없으니 따로 깨우는 작업을 하지는 않는다.)
..
여기까지 읽었다면 슬슬,, 두 부류로 나뉠 것 같다.
첫째로 '엥 그냥 lock이네? 배운걸 왜 또 배운담?' 하고 넘길 사람들, 둘째로 '그래서 왜 이걸 binary semaphore라고 부르는거야?' 하고 생각하는 사람들. 한방에 다 이해한 부류는 사람 취급 안해줄거다.
첫번째 부류라면 좀 더 semaphore value를 중심으로 아래 나올 예제들을 읽어보면 좋을 것 같다. 세마포어 자체는 주어진 단순한 작업만을 기계적으로 수행할 뿐이라는 점을 옆에 적어놓고 왔다갔다 쳐다보면서 공부하면 아마 포스트 끝날 때쯤에는 키보드를 타악! 하고 치게 될 것이다.
두번째 부류라면 이 semaphore를 사용해서 표현할 수 있는 상태가 두개임을 다시 생각해보면 이해가 될 것 같다. 내가 처음에 그랬던 것처럼 '또잉? 값은 1, 0, -1로 3개가 있을 수 있는거 아닌가?' 하고 생각할 수도 있는데, 이것도 마찬가지로 실눈뜨고 보면 Lock/Unlock의 두가지 상태만을 표현할 수 있으므로 Binary semaphore라 부른다고 생각하자.
세번째 부류는,,

왜 아직 안갔냐.
31.3 Semaphores For Ordering
세마포어는 또한 스레드의 실행 순서를 제어하는데 사용할 수도 있다.
즉, condition variable로써 기능할 수도 있다.
코드로 직접 까보기 전에 잠깐 생각해보자. 대강 어떻게 기능할까?
스레드 간의 실행 순서를 제어한다는 것은 어떤 스레드가 다른 스레드의 실행 완료를 기다리고, 기다리던 스레드가 모두 실행되면 대기를 멈추고 실행됨을 의미한다.
여기에 condition variable을 얹어보면? 기다리고 있는 스레드는 그냥 무한정 기다리는게 아니라 특정 조건을 만족할 때까지 codition variable 줄에 서서 기다리는 것이고, Semaphore에서는 값을 기준으로 특정 상태를 만족할 때까지 기다리는 것이므로 뭔가 비슷한 기능을 할 수 있을 것만 같다. 이제 코드를 놓고 다시 생각해보자.
...
예제는 우리가 여태껏 봐왔던, parent -> child -> parent 순서대로 실행됨을 보장해야 하는 상황을 그대로 가져다 쓰겠다. 이전에 이 문제를 lock과 condition variable로 해결했던 기억이 잘 나질 않는다면 꼭 이전 포스트를 다시 한 번 보고 오자.
sem_t s;
void *child(void *arg) {
printf("child\n");
sem_post(&s); // signal here: child is done
return NULL;
}
int main(int argc, char *argv[]) {
sem_init(&s, 0, 0);
printf("parent: begin\n");
pthread_t c;
Pthread_create(&c, NULL, child, NULL);
sem_wait(&s); // wait here for child
printf("parent: end\n");
return 0;
}끼약! 이번엔 왜 또 Semaphore value가 0이지?
책에선 이유부터 설명했는데, 개인적으론 실행 흐름을 먼저 보는게 더 좋을 것 같다.

첫번째 상황이다. 당연히 parent가 먼저 실행되어 child thread를 만들어주고, 이어서 sem_wait을 호출함으로써 parent thread가 기다려야 할지, 아니면 그냥 쭉 실행해도 될지 판단해야 한다.
값을 기준으로 이어서 보자면, sem_wait의 호출에 의해 semaphore value의 값을 0에서 -1로 내려주었으므로 이어지는 조건문에 의해 parent thread가 sleep 상태가 되었다. 따라서? 이전에 생성되어 대기중이던 child thread가 스케줄링되므로 쭉쭉 주어진 작업을 실행해준 다음 잠들어 있는 parent thread를 깨우기 위해 sem_post를 호출한다.
이때 semaphore value를 1 올려주면 다시 값이 0으로 복구되며, 이어서 잠들어있던 parent thread가 깨어난다. 그럼 이제 parent thread는 sem_wait에서 반환되어 다음 작업을 실행, 결과적으론 우리가 원하는 parent -> child -> parent의 실행 흐름이 보장되었음을 확인할 수 있다. 통과!
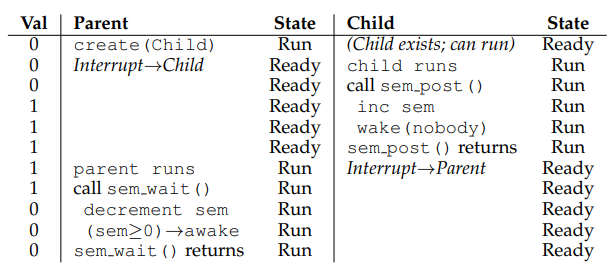
위 상황은 위와 달리 아직 parent가 sleep 상태에 들어가기 전에 child가 먼저 스케줄링 되는, 어떻게 보면 멀티 스레드 개념을 배우기 전의 우리가 생각 없이 바랐던 상황으로 볼 수 있겠다.
이때 child thread가 먼저 실행되니까 할거 다 해주고 sem_post를 호출하면 semaphore value가 0에서 1로 증가하며, 잠들어 있는 스레드가 없으므로 그냥 아무것도 하지 않고 바로 반환된다.
다음으로 parent thread가 스케줄링되어 sem_wait을 호출하면? Semaphore 값을 1 내리고 보니 0으로 음수가 아니기 때문에 대기 없이 바ㅏㅏ로 실행될 수 있다. 그럼 결과적으론 이전 케이스와 마찬가지로 parent -> child -> parent의 실행 흐름이 보장되었음을 확인할 수 있다. 마찬가지로 통과!
31.4 The Producer/Consumer (Bounded Buffer) Problem
이어서 이전 장에서도 봤었던 Producer/Consumer 문제(= 유한 버퍼 문제)를 Semaphore로 해결해보자.
int buffer[MAX];
int fill = 0;
int use = 0;
void put(int value) {
buffer[fill] = value; // Line F1
fill = (fill + 1) % MAX; // Line F2
}
int get() {
int tmp = buffer[use]; // Line G1
use = (use + 1) % MAX; // Line G2
return tmp;
}위의 put/get 함수의 구현을 보면 알겠지만, 크기가 MAX로 설정된 circular queue를 그대로 사용해 최대 MAX개의 값이 버퍼에 남아있을 수 있도록 하는 상황을 가정한다.
First Attempt
sem_t empty;
sem_t full;
void *producer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&empty); // Line P1
put(i); // Line P2
sem_post(&full); // Line P3
}
}
void *consumer(void *arg) {
int tmp = 0;
while (tmp != -1) {
sem_wait(&full); // Line C1
tmp = get(); // Line C2
sem_post(&empty); // Line C3
printf("%d\n", tmp);
}
}
int main(int argc, char *argv[]) {
// ...
sem_init(&empty, 0, MAX); // MAX are empty
sem_init(&full, 0, 0); // 0 are full
// ...
}으윽,, 이전 구현과 비슷한데 뭔가 세마포어가 들어가니까 뒷맛이 좀 찝찝하다.
이전에 그랬던 것처럼 버퍼의 크기가 1(MAX=1)인 상황부터 thread trace를 해보자.
| Empty Val | Full Val | Producer | Producer State | Consumer | Consumer State | Comment |
|---|---|---|---|---|---|---|
| 1 | 0 | ready | ... | running | consumer가 먼저 실행됨 | |
| 1 | -1 | ready | sem_wait(&full) | sleep | 버퍼가 비어 있으므로 버퍼가 다시 차기를 기다림 | |
| 0 | -1 | sem_wait(&empty) | running | sleep | 버퍼가 비어 있으므로 기다리지 않음 | |
| 0 | -1 | put(i) | running | sleep | 버퍼에 값을 채움 | |
| 0 | 0 | sem_post(&full) | running | wake(ready) | 버퍼에 값을 채웠으므로 consumer를 깨움 | |
| 0 | 0 | for | running | ready | 다시 버퍼에 값을 넣는 시도를 함 | |
| -1 | 0 | sem_wait(&empty) | sleep | ready | 버퍼가 차있으므로 버퍼가 다시 비기를 기다림 | |
| -1 | 0 | sleep | tmp = get() | running | 버퍼로부터 값을 빼서 읽음 | |
| 0 | 0 | wake(ready) | sem_post(&empty) | running | 버퍼에서 값을 뺐으므로 producer를 깨움 | |
| 0 | 0 | ready | while | running | 다시에 버퍼에서 값을 빼는 시도를 함 | |
| 0 | -1 | ready | sem_post(&full) | sleep | 버퍼가 비어 있으므로 버퍼가 다시 차기를 기다림 | |
| 0 | -1 | put(i) | running | sleep | 버퍼에 값을 채움 | |
| ... | ... | ... | ... | ... | ... | 반복 |
규칙만 잘 지킨다면 깔끔하게 딱 떨어지는 것 같아서 더 설명하지 않겠다.
다음으로 여기서 확장해서 버퍼의 크기를 10(MAX=10)으로 확장해서 thread tracing을 해보자.
| Empty Val | Full Val | Producer_A (Pa) | Pa State | Producer_B (Pb) | Pb State | Consumer | Consumer State | Comment |
|---|---|---|---|---|---|---|---|---|
| 9 | 0 | sem_wait(&empty) | running | ready | ready | 버퍼에 값을 넣을 수 있으므로 wait하지 않음 | ||
| 8 | 0 | ready | sem_wait(&empty) | running | ready | 버퍼에 값을 넣을 수 있으므로 wait하지 않음 | ||
| 8 | 0 | put 호출 | running | ready | ready | Pa와 Pb가 거의 동시에 put 호출 | ||
| 8 | 0 | ready | put 호출 | running | ready | Pa와 Pb가 거의 동시에 put 호출 | ||
| 8 | 0 | buffer[fill] = value | running | ready | ready | fill=0, buffer[0]=0 | ||
| 8 | 0 | ready | buffer[fill] = value | running | ready | fill=0, buffer[0]=0 | ||
| 8 | 0 | fill = (fill + 1) % MAX | running | ready | ready | fill <- 1 | ||
| 8 | 0 | ready | fill = (fill + 1) % MAX | running | ready | fill <- 1 |
아맞다! 값을 채워주고 circular queue 내의 fill index를 업데이트 하는 과정이 mutual exclusive하게 실행되도록 보장하는 과정을 깜빡했다! 마찬가지로 2개의 Consumer가 잇는 경우에도 이와 같은 race condition을 겪는 상황이 발생할 수 있다. 고쳐보자.
A Solution: Adding Mutual Exclusion
void *producer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&mutex); // Line P0 (NEW LINE)
sem_wait(&empty); // Line P1
put(i); // Line P2
sem_post(&full); // Line P3
sem_post(&mutex); // Line P4 (NEW LINE)
}
}
void *consumer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&mutex); // Line C0 (NEW LINE)
sem_wait(&full); // Line C1
int tmp = get(); // Line C2
sem_post(&empty); // Line C3
sem_post(&mutex); // Line C4 (NEW LINE)
printf("%d\n", tmp);
}
}
int main(int argc, char *argv[]) {
// . . .
sem_init(&empty, 0, MAX);
sem_init(&full, 0, 0);
sem_init(&mutex, 0, 1);
// . . .
}짠! 좋았어 완벽해! wait/post를 통째로 lock(binary semaphore) 안에 넣어 놨으니까 제대로 돌아갈거야!

아ㅏ아아ㅏㅏㄱ! 안돼! 왜안되는거야아ㅏ악!!!!
Avoiding Deadlock
위의 구현으로는 아래와 같은 Deadlock이 발생할 수 있다. 멀리 갈 것도 없이 MAX=1인 상황을 생각해보자.
(아래 thread trace는 국민대학교 황선태 교수님께서 강의 중에 예로 들어주신 상황을 참고했다!)
| Mutex Val | Empty Val | Full Val | Producer | P State | Consumer | C State | Comment |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | ready | for | running | ||
| 0 | 1 | 0 | ready | sem_wait(&mutex) | running | consumer lock acquired | |
| 0 | 1 | -1 | ready | sem_wait(&full) | sleep | 버퍼가 비어 있음 | |
| 0 | 1 | -1 | for | running | sleep | ||
| -1 | 1 | -1 | sem_wait(&mutex) | sleep | sleep | consumer가 lock을 가지고 있음 |
맨 마지막 행을 보면 producer/consumer 모두 잠들어버린 deadlock이 발생했음을 확인할 수 있다.
이 deadlock은 왜 발생한걸까?
앞에서 보았듯 잠들 스레드(consumer)가 global lock(mutex)을 들고 있는 상태로 잠들었기 때문에 다른 스레드가 이 영역에 접근할 수 없어 발생한 문제인데, 이전의 condition variable을 사용하는 solution에서는 sleep 상태에 들어가기 전에 쥐고 있던 mutex를 인자로 넘겨줌으로써 deadlock을 해결했었다.
그럼 semaphore만으론 이 문제를 해결할 수 없는걸까? 정말?
At Last, A Working Solution
다시 강조하자면 위 문제는 잠드는 스레드가 global lock을 풀어주지 않고 잠들어서 발생한 것이므로, 그럼 처음부터 global lock을 잠들지 말지 모르는 상태에서는 걸어놓지 않으면 될 일 아닐까?
void *producer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&empty); // Line P1
sem_wait(&mutex); // Line P1.5 (MUTEX HERE)
put(i); // Line P2
sem_post(&mutex); // Line P2.5 (AND HERE)
sem_post(&full); // Line P3
}
}
void *consumer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&full); // Line C1
sem_wait(&mutex); // Line C1.5 (MUTEX HERE)
int tmp = get(); // Line C2
sem_post(&mutex); // Line C2.5 (AND HERE)
sem_post(&empty); // Line C3
printf("%d\n", tmp);
}
}보다시피 global lock(mutex)가 full/empty에 대한 wait/post 호출 안쪽으로 들어가 critical section이 짧아졌다. 이 상태에서의 thread trace를 다시 해보자!
| Mutex Val | Empty Val | Full Val | Producer | P State | Consumer | C State | Comment |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | ready | for | running | ||
| 1 | 1 | -1 | ready | sem_wait(&full) | sleep | 버퍼가 찰 때까지 대기 | |
| 1 | 1 | -1 | for | running | sleep | ||
| 1 | 0 | -1 | sem_wait(&empty) | running | sleep | 버퍼가 비어 있으므로 대기 X | |
| 0 | 0 | -1 | sem_wait(&mutex) | running | sleep | Lock 획득 | |
| 0 | 0 | -1 | put(i) | running | sleep | (Critical section) | |
| 1 | 0 | -1 | sem_post(&mutex) | running | sleep | Lock 해제 | |
| 1 | 0 | 0 | sem_post(&full) | running | wake(ready) | 버퍼가 찼음을 알림 | |
| 1 | 0 | 0 | for | running | ready | ||
| 1 | -1 | 0 | sem_wait(&empty) | sleep | ready | 버퍼가 차있으므로 대기 | |
| 0 | -1 | 0 | sleep | sem_wait(&mutex) | running | Lock 획득 | |
| 0 | -1 | 0 | sleep | int tmp = get() | running | (Critical section) | |
| 1 | -1 | 0 | sleep | sem_post(&mutex) | running | Lock 해제 | |
| 1 | 0 | 0 | sleep | sem_post(&empty) | running | 버퍼가 비었음을 알림 |
짠! 이렇게 critical section을 적절히 잡아줌으로써 deadlock을 피했다. 만세!
31.5 Reader-Writer Locks
이전의 Producer/Consumer 문제에서 버퍼 하나에 값을 쓰거나 같은 버퍼로부터 값을 빼서 읽어오는 과정에서 문제가 발생했다면, 이번 장에서는 리스트의 상태(요소)가 변경될 수 있는 상황에서 안전하게 병렬적으로 삽입/조회 연산을 수행할 수 있도록 보장해야 하는 문제를 해결해보자.
이전 Concurrent data structure에서 배웠던 흐름과 비슷한 맥락에서, 삽입 연산 자체는 당연히 데이터를 동시에 수정하려 하는 race condition이 발생하면 문제가 생기지만 조회 연산은 삽입 연산이 없다는 보장만 있으면 당연히 한 번에 병렬적으로 조회 연산을 수행할 수 있다!
이러한 상황을 고려하여 좀 더 효율적으로 개선된 reader-writer lock은 아래와 같이 구현할 수 있다.
typedef struct _rwlock_t {
sem_t lock; // binary semaphore (basic lock)
sem_t writelock; // allow ONE writer/MANY readers
int readers; // #readers in critical section
} rwlock_t;
void rwlock_init(rwlock_t *rw) {
rw->readers = 0;
sem_init(&rw->lock, 0, 1);
sem_init(&rw->writelock, 0, 1);
}
void rwlock_acquire_readlock(rwlock_t *rw) {
sem_wait(&rw->lock);
rw->readers++;
if (rw->readers == 1) // first reader gets writelock
sem_wait(&rw->writelock);
sem_post(&rw->lock);
}
void rwlock_release_readlock(rwlock_t *rw) {
sem_wait(&rw->lock);
rw->readers--;
if (rw->readers == 0) // last reader lets it go
sem_post(&rw->writelock);
sem_post(&rw->lock);
}
void rwlock_acquire_writelock(rwlock_t *rw) {
sem_wait(&rw->writelock);
}
void rwlock_release_writelock(rwlock_t *rw) {
sem_post(&rw->writelock);
}휴! 뭔진 모르겠는데 드럽게 복잡해보인다. 하나씩 끊어서 생각해보자,,
typedef struct _rwlock_t {
sem_t lock; // binary semaphore (basic lock)
sem_t writelock; // allow ONE writer/MANY readers
int readers; // #readers in critical section
} rwlock_t;
void rwlock_init(rwlock_t *rw) {
rw->readers = 0;
sem_init(&rw->lock, 0, 1);
sem_init(&rw->writelock, 0, 1);
}일단 rwlock_t의 멤버 변수부터 뜯어보자!
- lock: Binary semaphore로 구현된 lock으로써, 연산을 atomic하게 수행하기 위해 기본적으로 필요하다.
- writelock: 쓰기 작업은 병렬 실행이 불가능하지만, 조회 작업은 한 번에 여러 스레드가 접근할 수 있도록 만들어주는데 필요한 lock이다.
- readers: 현재 읽기 작업을 수행중인 reader thread의 갯수를 의미한다.
이렇게만 보면 특히 writelock이랑 readers가 어디 쓰이는지 와닿질 않는데,,
void rwlock_acquire_writelock(rwlock_t *rw) {
sem_wait(&rw->writelock);
}
void rwlock_release_writelock(rwlock_t *rw) {
sem_post(&rw->writelock);
}데이터를 갱신(write)하기 위한 writelock과 관련된 부분은 뭐 더 볼 것도 없이 단순하게 생겼다. 그냥 write 하기 전에 다른 스레드가 접근할 수 없도록 막아주고, write이 끝나면 다른 스레드가 다시 접근할 수 있도록 풀어주면 되니까!
읽기 작업을 수행할 때 호출해야 할 readlock이 좀 복잡하게 생겼는데, 사실 별거 없다.
void rwlock_acquire_readlock(rwlock_t *rw) {
sem_wait(&rw->lock);
rw->readers++;
if (rw->readers == 1) // first reader gets writelock
sem_wait(&rw->writelock);
sem_post(&rw->lock);
}일단 read 작업이 발생할 때마다 읽으려는 스레드가 있음을 표시(rw->readers++)해주는 것으로 시작한다.
아까 read를 하는 도중에는 write가 발생하면 안된다고 했으므로, 아무도 읽기 작업을 수행하고 있지 않은 상황에서 어떤 reader thread가 읽기를 요청하면 rw->readers가 1이 되며 이 경우 write 연산이 수행될 수 없도록 sem_wait(&rw->writelock)를 호출해준다. 끝! 간단하지 않은가?
void rwlock_release_readlock(rwlock_t *rw) {
sem_wait(&rw->lock);
rw->readers--;
if (rw->readers == 0) // last reader lets it go
sem_post(&rw->writelock);
sem_post(&rw->lock);
}Readlock을 해제해주는 과정도 어렵지 않다. 읽기 작업을 마칠 때 lock을 놔주는 것이므로 rw->readers--해주고, 방금 lock을 놓은 스레드가 읽기 작업을 수행하고 있던 마지막 스레드이면 다시 쓰기 작업이 수행될 수 있도록 writelock을 놔주면 된다(sem_post(&rw->writelock)).
천천히 흐름을 따라가다 보면 알겠지만, 문제 조건상 write에게 박하고 read에겐 좀 널널하도록 구현된 느낌이 좀 있다.
만약 Read thread들이 writelock을 걸어 놓고 읽기 작업을 수행하고 있다가 write thread가 들어오면 rwlock_acquire_writelock을 요청해봤자 이미 read thread들에 의해 lock이 걸려 있으므로 sleep 상태에 들어가게 된다.
그런데 이 상황에서 write thread에 앞선 read thread들뿐만 아니라 뒤따라서 들어오는 read thread들이 막 앞의 read thread가 끝나기 직전에 교묘하게 껴들어서 readers 값이 0까지 떨어지지 않도록 막아선다면? write의 Response time이 한도 끝도 없이 커지는 starvation이 발생하게 될 것이다.
또한,, lock을 여러개 쓰기 때문에 실수할 여지도 많고 overhead 역시 그만큼 증가하므로 쓰기 전에 이것저것 cost를 따져보고 사용할 수 있어야 한다.
...
책에는 나와 있지 않지만 교수님께서 이 writer thread starvation 문제를 writer thread에 우선순위를 주는 방식으로 해결할 수 있다고 소개해주셨는데, 예를 들어 방금 제시한 상황과 다른건 다 동일한데 만약 writer thread가 쓰고 있거나 기다리고 있는 경우 reader thread가 중간에 들어와도 바로 병렬 실행 시켜주지 않고 깨워줄 때까지 기다리도록 함으로써 writer thread의 response time을 짧게 만들어줄 수 있다.
물론~~ 실행되고 있던 마지막 write thread가 writelock을 unlock해줄 때에 read thread들만 sleep 상태에 있다면 이 read thread들은 병렬 실행이 가능하므로 한번에 다 깨워서 동시에 실행시켜줄 수도 있으니 거시적으로 보면 read thread 입장에선 그렇게 큰 손해도 아닐 것 같다. 굳굳,,
31.6 The Dining Philosophers
빰,, 이번 절에서는 컴퓨터 과학을 좀 파봤다면 어디선가 우스갯소리로라도 들어봤을법한, "식사하는 철학자 문제"와 그 해결법에 대해 공부해볼 것이다.
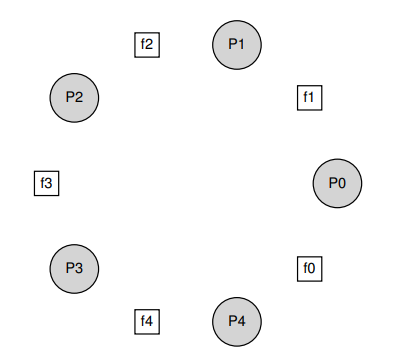
빰,, 위 그림에서 P는 철학자(Phiilosopher), f는 포크(fork)를 의미한다. 철학자가 원탁에 둘러 앉아 있고 그 사이에 포크를 하나씩 놓은 상황인데, 철학자들이 음식을 먹기 위한 일련의 과정들을 pseudo code로 쓰면 아래와 같을 것이다.
while (1) {
think();
get_forks(p);
eat();
put_forks(p);
}철학자가 뭔가 생각하고 있는 동안(think())에는 밥을 먹지 않고 그냥 생각만 하며, 식사를 하기 위해서는 자기 양 옆에 놓인 포크를 모두 들고(get_forks(p)), 식사를 마친 후(eat())에는 다시 포크를 있던 자리에 내려 놓으면(put_forks(p)) 된다.
저 포크를 집는 과정도 pseudo code로 써보면..
int left(int p) { return p; }
int right(int p) { return (p+1) % 5; }이렇게 표현할 수 있다.
Broken Solution
포크를 쥔다는 것은 자기 말고 다른 누구도 그 포크를 사용할 수 없음을 의미하므로, 그 자체로 lock을 걸어 놓는 것과 같다고 생각할 수 있겠다.
그럼 여기서 sem_t 타입으로 포크를 표현하고, sequential하게 포크에 번호가 매개져 있으니 포크를 얻는 과정인 get_forks와 놓는 과정인 put_forks는 아래와 같이 표현할 수 있을 것이다.
void get_forks(int p) {
sem_wait(&forks[left(p)]);
sem_wait(&forks[right(p)]);
}
void put_forks(int p) {
sem_post(&forks[left(p)]);
sem_post(&forks[right(p)]);
}이런 식으로 구현하면 왼쪽 포크 다음 오른쪽 포크든, 오른쪽 포크 다음 왼쪽 포크든 딱 정해진 루틴대로만 포크를 잡거나 놓으려 할 것이다.

위의 짤에서는 젓가락으로 표현되어 있는데, 위와 같이 구현하게 되면 모든 철학자들이 자기 왼쪽에 있는 포크를 집고 나면 당연히 모든 철학자들이 오른쪽 포크를 얻을 수 없기 때문에 아무도 저녁을 먹을 수 없는 바보같은 deadlock이 발생한다.
A Solution: Breaking The Dependency
이는 0번 철학자가 1번 철학자에게, 1번 철학자는 2번 철학자에게, ... 4번 철학자는 다시 0번 철학자에게 의존하는 의존성 순환 때문에 발생하는 문제이므로, 이 고리를 끊어주면 되지 않을까?
void get_forks(int p) {
if (p == 4) {
sem_wait(&forks[right(p)]);
sem_wait(&forks[left(p)]);
} else {
sem_wait(&forks[left(p)]);
sem_wait(&forks[right(p)]);
}
}..바로 이렇게!
보면 알겠지만 맨 마지막 철학자는 다른 철학자들과 달리 왼쪽 포크가 아니라 오른쪽 포크부터 잡으려 시도한다. 만약 맨 마지막 철학자가 오른쪽 포크를 먼저 잡으면 그 오른쪽에 앉아 있던 맨 첫 철학자가 왼쪽 포크를 잡지 못하므로 마지막 철학자가 식사를 마칠 때까지 맨 첫 철학자가 기다리고, 만약 맨 마지막 철학자가 오른쪽 포크를 잡는데 실패했다면 그 오른쪽에 앉아 있던 맨 첫 철학자가 왼쪽 포크를 먼저 잡은 것이므로 이번엔 반대로 맨 마지막 철학자가 기다리면 된다.
31.7 Thread Throttling
끼악! 오늘도 분량이 좀 되는 것 같다. 마지막으로 lock과 condition variable을 사용해서 구현된 Zemaphore의 구현체를 살펴보자.
typedef struct __Zem_t {
int value;
pthread_cond_t cond;
pthread_mutex_t lock;
} Zem_t;
// only one thread can call this
void Zem_init(Zem_t *s, int value) {
s->value = value;
Cond_init(&s->cond);
Mutex_init(&s->lock);
}
void Zem_wait(Zem_t *s) {
Mutex_lock(&s->lock);
while (s->value <= 0)
Cond_wait(&s->cond, &s->lock);
s->value--;
Mutex_unlock(&s->lock);
}
void Zem_post(Zem_t *s) {
Mutex_lock(&s->lock);
s->value++;
Cond_signal(&s->cond);
Mutex_unlock(&s->lock);
}이 Zemaphore는 Semaphore와 유사하게 value, condition variable, lock을 멤버로 가지고 있는 구조체로, 초기화 과정 역시 비슷하다.
다만 맨 앞에서 Semaphore value가 음수라면 이 값에 마이너스를 곱한 값이 현재 대기중인 스레드라고 했던 것과 달리, Zemaphore에서는 이 값이 0보다 작아질 수 없는 구조이다. 근데 Zem_wait의 while문 조건식은 일종의 안전장치로 <= 연산자를 썼나보다,,,
마무리
이전에 Condition variable과 lock으로 멀티 스레드 프로그래밍을 위한 제어 기법을 구현했다면, 이번에는 Semaphore를 사용해 같은 문제를 해결하는 방법을 배웠다.
사실 아침부터 이거 다시 이해하는데 매달려 있느라 뇌에 바람이 다빠져가지고,, 추가 코멘트는 못하겠다,,
오늘은 Semaphore의 아버지이자 희대의 괴수 다익스트라님의 주옥같은 명언으로 마치겠다. 안녕!
“If debugging is the process of removing software bugs,
then programming must be the process of putting them in.”
