
아쉽게도! 와 진짜 너무너무 아쉽게도!
강의 중에 다루는 Concurrency 관련 내용 중 가장 마지막 주제에 이르렀다.
워낙 오래되고 어려운 문제인만큼 이런저런 주제들이 넘치지만, 일단은 살기가 너무 팍팍해서(...) 여기까지만 살펴보고 뒷쪽 내용은 나중에 살펴보려고 한다. Event loop라든가,, 흥미로운 주제가 많이 남았다.
32.1 What Types Of Bugs Exist?
이번 장에서는 Concurrent한 프로그램을 작성하며 어떤 문제들이 발생할 수 있는지 공부해볼 것이다. 자료부터 볼까?

위 표는 사람들이 많이 쓰는 오픈소스 소프트웨어에서 발생하는 concurrency 관련 이슈들을 세어서 정리한 것이다. MySQL은 오라클로 넘어갔는데,, 쳐줘,,?
여하튼 보면 알겠지만 Non-Deadlock, 그러니까 deadlock과 관련 없는 문제들이 deadlock과 관련된 문제보다 무려 2배나 많았다고 한다. 그러니까,, 사람이 뭔가 실수해서 발생한 문제들이 대부분이었다는거지,, 😢
32.2 Non-Deadlock Bugs
Deadlock과 관련된 문제보다 2배 가량 더 자주 발생하는 Non-deadlock 문제를 먼저 분석해보겠다.
Atomicity-Violation Bugs
기본적인 요소를 어겼달까,, 실행 흐름이 여기저기 옮겨다니다보니까 깜빡하고 공동 자원에 대한 mutual exclusion이 제대로 보장되지 않은 사례이다.
Thread 1::
if (thd->proc_info) {
fputs(thd->proc_info, ...);
}
Thread 2::
thd->proc_info = NULL;여기서 공동 자원은 thd->proc_info인데, 만약 아래와 같이 각 스레드들이 스케줄링 된다면 프로그램이 실행되다 말고 쭉 뻗어버릴 것이다. (먼저 잠깐 고민해보자!)
- 아래 실행 흐름이 실행되기 이전에는
thd->proc_info가 NULL이 아니었다고 가정한다. if (thd->proc_info) {
따라서, T1에 해당하는 위의 조건문은 참이 된다. 여기서 T2로 context switching이 발생하면?thd->proc_info = NULL;
엇? 느낌이 쎄하다. 위의 단계 1에서thd->proc_info가 NULL이 아니므로 어떤 작업을 수행하려고 했었던 것 같은데, T2에서 이 값을 NULL로 바꿔버렸다. 여기서 다시 T1으로 전환되면,,,fputs(thd->proc_info, ...);
쾅! 여기서fputs함수가 예기치 못한 인자인 NULL을 전달받아 오류가 발생한다.
Lock/Condition variable, semaphore 등으로 해결했었어야 할 전형적인 mutual exclusive하게 실행될 문제였지만,, 이게 제대로 지켜지지 않아 문제가 발생했다. 이젠 이런 문제쯤은 능숙하게 해결할 수 있따! 함 해보자!
pthread_mutex_t proc_info_lock = PTHREAD_MUTEX_INITIALIZER;
Thread 1::
pthread_mutex_lock(&proc_info_lock);
if (thd->proc_info) {
fputs(thd->proc_info, ...);
}
pthread_mutex_unlock(&proc_info_lock);
Thread 2::
pthread_mutex_lock(&proc_info_lock);
thd->proc_info = NULL;
pthread_mutex_unlock(&proc_info_lock);다른건 다 같은데, thd->proc_info에 접근하는 코드를 atomic하게 실행할 수 있도록 lock/unlock으로 감싸 critical section으로 만들었다. ezez,,
Order-Violation Bugs
또 다른 문제로 Ordering-violation, 그러니까 스레드들이 기대한대로/예상치 못한 흐름으로 실행되는 경우가 발생할 수 있다.
Thread 1::
void init() {
mThread = PR_CreateThread(mMain, ...);
}
Thread 2::
void mMain(...) {
mState = mThread->State;
}분위기를 보니까 T2가 T1에 의존(T1이 먼저 실행되어야 T2가 제대로 실행될 수 있는 상황)하고 있는 것 같은데, 만약 T2가 T1보다 먼저 실행되면 mThread가 아직 초기화되지 않은 상황이므로 NULL Pointer exception 비슷한게 발생할 것이다.
마찬가지로~~ 우리는 이전에 이러한 문제를 condition variable을 사용해 해결했었다. 어떻게?!
pthread_mutex_t mtLock = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t mtCond = PTHREAD_COND_INITIALIZER;
int mtInit = 0;
Thread 1::
void init() {
...
mThread = PR_CreateThread(mMain, ...);
// signal that the thread has been created...
pthread_mutex_lock(&mtLock);
mtInit = 1;
pthread_cond_signal(&mtCond);
pthread_mutex_unlock(&mtLock);
...
}
Thread 2::
void mMain(...) {
...
// wait for the thread to be initialized...
pthread_mutex_lock(&mtLock);
while (mtInit == 0)
pthread_cond_wait(&mtCond, &mtLock);
pthread_mutex_unlock(&mtLock);
mState = mThread->State;
...
}요렇게~~
당연히 condition variable에 접근하는 부분은 atomic하게 수행되어야 하므로 critical section으로 만들어주었고, status variable에 해당하는 mtInit을 두어 이 변수가 1이 될 때까지 T2가 아까 문제를 일으켰던 mState = mThread->State; 코드를 실행하지 않도록 보장했다. ezez!
32.3 Deadlock Bugs
이제까지 배워왔던 문제들로 ice breaking을 했으니까, 인제 살짝 매운 맛을 좀 보자.
Deadlock! 이름부터 살벌하다. deadlock의 사전적인 정의를 다시 한 번 떠올려보면 좀 덜 무서울까?
교착 상태(膠着狀態, 영어: deadlock)란 두 개 이상의 작업이 서로 상대방의 작업이 끝나기 만을 기다리고 있기 때문에 결과적으로 아무것도 완료되지 못하는 상태를 가리킨다.
으흠, 사전에서는 서로가 서로의 작업이 끝나기만을 기다리고 있느라 둘 다 더이상 실행되지 못하는 상태를 deadlock이라 정의하고 있다. 이를테면 아래와 같은 상황에서 발생하는 것이라 할 수 있겠다.
Thread 1: Thread 2:
pthread_mutex_lock(L1); pthread_mutex_lock(L2);
pthread_mutex_lock(L2); pthread_mutex_lock(L1);한발짝 떨어져서 보면,, T1과 T2가 L1/L2 lock을 얻는 순서가 서로 엇갈려 있음을 확인할 수 있다. 이렇게 lock을 얻는 순서가 꼬여버리면
- T1이 L1을 얻는다.
- T2가 L2를 얻는다.
- T1이 L2를 얻으려 시도하는데, T2가 쥐고 있으므로 sleep한다.
- T2가 L1을 얻으려 시도하는데, T1이 쥐고 있으므로 sleep한다.
- T1과 T2 둘 다 잠들어버렸다.
위와 같은 deadlock이 발생할 수 있다.
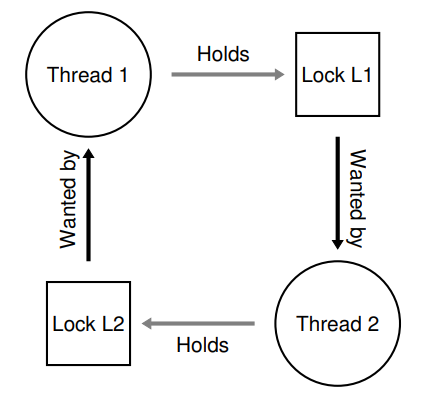
지난 장에서 배운 Dining philosophers 문제가 새록새록 떠오르는데,, 보다시피 이 Thread/Lock을 node로 하는 graph의 cycle이 존재하여 발생한 문제라고 할 수도 있겠다. 그럼 이걸 어떻게 해결한다,,?
Why Do Deadlocks Occur?
지피지기 백전불태. 문제를 해결하기에 앞서 이 deadlock이 발생하는 이유를 좀 더 자세히 정리해보자.
첫째로 소프트웨어를 개발하다보면 이런 저런 요소들이 서로 상호작용하기 위해 공동의 자원에 접근하는데, 그러다보면 실행 흐름을 한 눈에 파악하기 어려워 위와 같은 의존성 순환이 발생하여 deadlock이 발생할 수 있다.
둘째로, 앞의 어느 장에서 얘기했던 것도 같은 주제인데 소프트웨어 개발을 하다보면 세부 구현을 완전히 모르더라도 가져다 쓸 수 있는 encapsulation(abstraction)이 대체로 권장되는 편이다. 그렇다보니 내부적으로 lock을 사용하여 thread-safe함을 보장하는지 등의 세세하지만 중요한 사항을 간과하여 종종 concurrency가 제대로 구현되지 않음은 물론 심각한 경우 deadlock까지 발생할 가능성이 높다고 한다.
Conditions for Deadlock
위에서 상대적으로 high-level에서의 deadlock 발생 원인을 생각해보았으니, 이번엔 좀 더 저수준에서의 deadlock 발생 조건을 정리해보자.
다행히도! 진짜 다행히도! 아래 네 조건을 동시에 만족하지 않는다면 deadlock은 발생하지 않는다.
- Mutual exclusion
각 스레드는 스레드가 얻으려는 자원에 대한 제어권을 한 순간에 혼자만 사용하기를 요청한다.
(lock을 얻는다던지,,) - Hold-and-wait
각 스레드는 자신에게 이미 할당된 자원(이미 acquire한 lock 등)을 가지고 있는 상태로 또다른 자원(이어서 얻기를 원하는 lock)을 얻기 위해 대기할 수 있다. - No preemption
(lock 등의) 자원을 쥐고 있는 스레드로부터 해당 자원을 강제로 빼앗을 수 없다. - Circular wait
각 스레드는 체인에 소속된 다음 스레드가 요청한 하나 이상의 자원(lock 등)을 가지고 있는 circular chain에 소속되어 있다.
내가 영어가 좀 짧아서(...) 특히 네번째 조건의 번역이 좀 이상한데 번역본에도 비슷하게 나와 있다. 이건 서로 순환적으로 의존하고 있는 dining philosophers 문제를 떠올리면 될 것 같다.
하여튼! 만화에 나오는 사천왕 정복하는 기분으로 하나씩 조건을 깨가며 deadlock 문제를 해결해보자.
격파: Circular wait
각 스레드는 체인에 소속된 다음 스레드가 요청한 하나 이상의 자원(lock 등)을 가지고 있는 circular chain에 소속되어 있다.
앞장의 Dining philosophers 문제에서는 맨 마지막 철학자는 왼쪽이 아니라 오른쪽 포크부터 집도록 함으로써 문제를 해결했었다. 이걸 좀 더 일반화해보자면,,
첫째로, 공동의 자원(여기서는 lock)을 얻는 순서를 강제하는 것이다. 두 개의 lock만 놓고 생각해보자면, L1을 L2보다 항상 먼저 얻게 함으로써 아까와 같이 lock을 얻는 순서가 꼬이는 일을 방지하는 것이라 할 수 있겠다.
여기까진 쉬운데 L1, l2, .. , L100까지 넘어가면 연상하기가 힘들어질 것 같다. 그럴 때에는 다시 Dining philosophers 문제를 떠올리면 좋을 것 같다. 포크를 쥐는 순서를 정해서 철학자들에게 강제한다면 당연히 해당 포크를 집을 철학자가 먼저 식사를 할 수 있겠지? 이렇게 모든 lock acquire order를 저장하는 방법을 total ordering이라 한다.
근데 굳~~이 저 L1~L100까지의 순서를 한 번에 저장하지 말고 나눠서 저장하면 안될까?
된다! 예를 들어 여기서는 L1->L2, L2->L3, ... 와 같이 ordering의 일부만 저장해놓는 partial ordering을 사용할 수도 있다.
격파: Hold-and-wait
각 스레드는 자신에게 이미 할당된 자원(이미 acquire한 lock 등)을 가지고 있는 상태로 또다른 자원(이어서 얻기를 원하는 lock)을 얻기 위해 대기할 수 있다.
pthread_mutex_lock(prevention); // begin acquisition
pthread_mutex_lock(L1);
pthread_mutex_lock(L2);
...
pthread_mutex_unlock(prevention); // end어떤 lock을 들고 있는 상태로 다른 lock을 얻으려 하는 작업을 atomic하게 만들어줌으로써 hold-and-wait 문제를 해결했다! 와!
다만,, 앞서 언급했듯 이렇게 구현해버리면 외부에서 이런 lock-acquire 매커니즘을 모르는 상태에선 제대로 사용할 수 없으며, 또한 필요한 시점에 lock을 얻는 것이 아니라 한 번에 일단 다 얻어 놓기 때문에 살짝 뭉툭하게 비효율적인 느낌도 좀 있다.
격파: No Preemption
(lock 등의) 자원을 쥐고 있는 스레드로부터 해당 자원을 강제로 빼앗을 수 없다.
개인적으로 lock을 얻는 순서를 강제하는 듯한 이미지 때문에 이 조건이 Hold-and-wait과 좀 헷갈렸었다.
top:
pthread_mutex_lock(L1);
if (pthread_mutex_trylock(L2) != 0) {
pthread_mutex_unlock(L1);
goto top;
}위의 코드는 아래와 같이 작동한다.
1. 일단 L1을 얻는다. 여기서 실패하면? 다른 스레드가 L1을 먼저 쥔 것이다.
2. 다음으로 L2를 얻으려 시도하는데, 이때 성공하면 0이 아닌 값을 반환한다.
3. L2를 얻는데 성공하면 L1과 L2를 온전히 얻은 것이므로 그냥 반환하면 된다.
4. 만약 실패했다면, 쥐고 있던 L1을 다시 내려놓고 top으로 돌아가 단계 1부터 다시 실행한다.
Hold-and-wait 문제가 lock을 교차로 얻으려 해서(T1이 L1을 쥐고 L2를 기다리는 동시에 T2도 L2를 쥐고 L1을 기다리는 문제) 발생했으므로 이를 해결한 것이라면, No Preemption 문제는 deadlock이 발생할 수 있는 타이밍에 강제로 쥐고 있던 lock을 뱉게 함으로써 해결되었다,, 정도로 생각한다. 어유 난 모르겠서,,
그런데 만약 다른 스레드가 아래와 같은 코드로 L1과 L2를 얻으려 하면 어떻게 될까?
top2:
pthread_mutex_lock(L2);
if (pthread_mutex_trylock(L1) != 0) {
pthread_mutex_unlock(L2);
goto top2;
}다른건 다 동일한데 이번엔 L2를 먼저 얻도록 구현되어 있음을 알 수 있다.
보면 알겠지만 위 코드의 각 명령어가 atomic하게 실행되는 것이 보장되지는 않기 때문에 두 스레드가 저 각각의 lock acquire 코드로 L1과 L2를 얻으려 하면 서로 각자 L1과 L2를 쥐었다가, 놓았다가만 영원히 반복하는 livelock 문제가 발생할 수도 있다.
그럼? 임의로 저 반복문 안에다가 랜덤하게 지연 시간을 넣어서 살짝 엇갈리게 만드는 식으로 livelock의 발생 확률을 좀 낮출 수는 있긴 하다고 한다. 호오,,
마지막으로 goto문의 특징상 저 코드를 통째로 캡슐화해서 사용하는 경우 호출 스택이 깊은 곳에서도 문제 없이 작동할 수 없도록 구현하는 작업이 매우 어렵다는 점,, 깊이 새기며 넘어가자.
격파: Mutual Exclusion
문제가 발생하지 않게 막으려면 아예 처음부터 싹을 자르는게 가끔은 나을 때도 있다.
Deadlock 자체가 보통 critical section과 함께 발생하니까, 아예 없애버리면 되지 않을까,,?
ㅋㅋ 어림도 없다. 가능은 한데 어렵다. 그게 쉬웠으면 처음부터 그 방법을 배웠겠지?
이쯤되면 살짝 치트키 느낌이 나는데,, Herlihy라는 분이 아예 명시적으로 lock을 쓸 필요가 없는 빵빵한 기계어 instruction을 사용하는 wait-free한 자료구조를 제안한 적이 있다고 한다.
이 자료구조를 구현하기 위해 필요한 빵빵한 기계어 Instruction은 대강 다음과 같이 표현할 수 있다.
int CompareAndSwap(int *address, int expected, int new) {
if (*address == expected) {
*address = new;
return 1; // success
}
return 0; // failure
}헷갈리지 말자! C언어 코드가 아니라 pseudo code로 작성된 기계어 instruction이다!
즉, 해당 명령어는 atomic하게 값을 두 값을 비교해서, 만약 *address가 가리키는 위치의 값이 expected와 같은 경우 해당 위치에 값 new를 써주고, 그렇지 않으면 그냥 아무것도 안하고 반환하는 역할을 수행한다. 이걸 어떻게 써먹냐면,,
void AtomicIncrement(int *value, int amount) {
do {
int old = *value;
} while (CompareAndSwap(value, old, old + amount) == 0);
}위 코드는 atomic하게 value가 가리키는 값을 atomic만큼 올려준다.
즉, 해당 함수가 호출된 시점의 value가 가리키던 값이 CompareAndSwap을 호출하는 시점에도 같은 경우에만 값을 amount만큼 올려주기 때문에 thread-safe하게 값을 올려주는 역할을 수행할 수 있는 것이다. Lock 없이!
...
이전까진 Lock을 사용해서 해결했던 다른 문제를 마찬가지로 짱쌘 CompareAndSwap 명령어로 해결해보자.
void insert(int value) {
node_t *n = malloc(sizeof(node_t));
assert(n != NULL);
n->value = value;
n->next = head;
head = n;
}Linked list에 새 노드를 삽입하는 코드이다. 만약 이렇게 구현되어 있다면,, 리스트의 맨 앞 노드인 head에 새 노드를 연결하는 과정에서 race condition이 발생하겠지?
void insert(int value) {
node_t *n = malloc(sizeof(node_t));
assert(n != NULL);
n->value = value;
pthread_mutex_lock(listlock); // begin critical section
n->next = head;
head = n;
pthread_mutex_unlock(listlock); // end critical section
}Lock을 사용하면 위와 같이 새 노드를 생성하는 부분을 제외한 삽입 부분을 critical section으로 만들어 해결할 수 있다. lock 없이는 해결할 수 없는걸까?
void insert(int value) {
node_t *n = malloc(sizeof(node_t));
assert(n != NULL);
n->value = value;
do {
n->next = head;
} while (CompareAndSwap(&head, n->next, n) == 0);
}아니! 요렇게 해결할 수 있다!
위의 코드에서는 일단 새 노드의 다음 노드로 기존의 head 노드를 연결해본 다음, CompareAndSwap 호출 시점에도 아까 새 노드의 뒷 노드로 연결한 노드가 여전히 head 노드인 경우(= 중간에 다른 노드가 삽입하지 않은 경우)에만 삽입을 수행한다고 생각하면 되겠다.
실패했으면? 그새 head가 대체되었다는 의미이므로 새로 만들어진 노드의 뒷 노드로 다른 스레드에 의해 갱신된 head를 연결해주면 될 것이다.
Deadlock Avoidance via Scheduling
위에서 애초에 deadlock이 발생할 수 없도록 싹을 잘라놓는 Deadlock 예방 기법에 대해 공부했다.
다만 각각의 예방 기법들을 구현하는 과정에서 구현이 복잡해지거나 성능이 약간 떨어지는 문제가 발생했었으므로, 외부의 어떤 부가적인 장치를 통해 단독 코드만으론 deadlock 자체가 발생할 수 있는 상황을 회피하도록 하는 방법을 채택하는게 가끔은 나을 수도 있다.
다시 묻겠다. Deadlock은 왜 발생하는가? Cicular wait, Hold-and-Wait, No Preemption, Mutual exclusion의 네 가지 조건을 만족하는 경우 발생한다고 대답할 수 있겠다.
그럼 저 네가지 상황은 왜 발생하는가?! 동시에 여러 스레드가 같은 자원에 접근하려는 Race condition이 발생하기 때문에 발생한다.
그럼 Race condition은 왜 발생하는가?!!??!?!
바로 서로 의존 관계가 있는 여러 스레드가 실행되는 상황을 고려해야 하므로 발생하는 것이다!
달리 말하자면 스레드가 서로의 상황을 제대로 고려하지 않고 실행되기 때문에 발생한다고도 할 수 있겠다.
그럼 (Lock 없이) 이해 관계가 얽혀 있는 스레드들은 동시에 실행될 수 없도록 막고, 병렬적으로 실행될 수 있는 스레드는 한꺼번에 실행시킬 수 있도록 CPU를 여러개 사용하면 어떨까? 물론 이걸 달성하려면 위에서 지적한 스레드 사이의 관계를 무언가가 이해하고 가운데서 조율해주어야 할 것이다.

예를 들어 위와 같이 T1이 L1, L2를, T2가 L1, L2를, T3가 L2만을 필요로 하며 T4는 어떠한 lock도 필요로 하지 않는다 상황을 생각해보자.
그냥 무지성으로다가 두 CPU에 스레드를 스케줄링해버리면 당연히 deadlock이 발생할 여지가 남아 있겠지만, 똑똑한 스케줄러는 아래와 같이 스케줄링해서 deadlock을 원천봉쇄할 수도 있을 것이다.
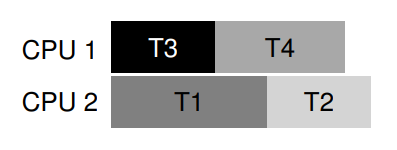
짠! T3는 L2만을 원하므로 T1과 병렬 실행되어도 deadlock이 발생하지 않고(T1이 먼저 얻으면 T3가 기다리고, T3가 먼저 얻으면 T1이 기다리면 된다. 의존 관계가 없으니까!), T4는 어떠한 lock도 원하지 않으므로 모든 lock을 원하는 T1과 병렬 실행할 수 있다.
다른 예제를 보자.

이번엔 T3가 좀 더 욕심을 내서 L2뿐만 아니라 L1까지 원하는 상황을 가정해 보겠다.
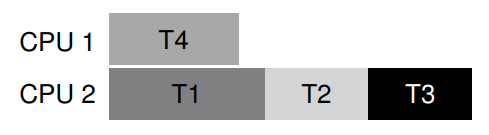
그럼 T1, T2, T3와 서로 병렬 실행 가능한 스레드가 T4밖에 남지 않았으므로, 어쩔 수 없이 CPU 2에 대한 병목이 발생해 성능이 좀 떨어질 것이다.
이런 문제를 좀 더 효율적으로 해결하기 위해 또익스트라 선생님께서 고안한 Banker's Algorithm 같은게 있는데, 요건 여백이 부족해서 따로 더 적지는 않겠다.
Detect and Recover
에라! 모르겠다! 일단 deadlock이 발생하도록 냅두는 대신 발생하면 알아채고 다시 복구해주면 되지 않나?!
이런 대응은 저ㅓㅓㅓㅓㅓㅇ말 희박하게 deadlock이 발생해서 무시할 수 있을 정도로 피해가 미미하거나, DB처럼 deadlock이 치명적인, 신뢰성이 매우 중요한 소프트웨어에 적용할 수 있다.
마무리
재밌는 주제였다! 특히 Detect and Recover 부분에 적혀 있는 Tip이 가장 인상깊다.
Soul of a New Machine 의 저자 Tom West라는 분께서 아래와 같은 명언을 남기셨다고 한다.
“Not everything worth doing is worth doing well”
일을 대충 하라는게 아니라, 매우 희박하게 발생하는 문제를 해결하기 위해서 불필요하다 싶을만큼 많은 노력을 들일 필요가 없다는 의미이다.
평소에 '소프트웨어는 무조건 최선의 방법으로 완벽하게 작동할 수 있고, 그래야만 한다'고 생각해왔던지라 남들 생각하기에 사소하다 싶은 부분에 몰두해 있다보면 가끔 비슷한 말을 하는 동료들이 있었는데, 컴퓨터 과학의 꽃이라 불리는 만큼 항상 최적의 solution이 있을 것이라 생각했던 OS를 공부하면서 오히려 이런 고정 관념이 조금씩 허물어지는 것 같아서 좀 신기하다.
