Django Celery - 효과적인 디버깅 & 모니터링: Logging + Flower + Prometheus + Grafana(with Loki & Promtail)
Django Basic to Advanced

[ 글의 목적: 메시징 방식 비동기 작업 특성상 디버깅이 쉽지않아 모니터링 & 디버깅에 대한 고찰과 기록, 더 확장해 web stack에 대한 monitoring 고찰 ]
Celery Debugging & Monitoring
celery를 활용하다 보면 디버깅이 쉽지 않다. sentry integration은 논외로 하고, celery의 전체 모니터링 - status, num of executing task, avg task runtime, prefetch time, num of prefetched task, success, filure를 체크하고 분산된 log를 한 곳에서 보면서 디버깅 고도화를 해보자. 각 하나 하나를 depth있게 들어가기 보단, devOps로 활용하는 것에 초점이 맞춰져 있다.
우선 등장하게 될 예제는 https://github.com/Nuung/django-all-about 레포 기준으로 진행한다.
전체적으로 celery json type logging + flower + Prometheus + Grafana(with Loki & Promtail) 의 흐름으로 살펴보자. linux의 system log자체에 대한 정보는 리눅스 로그 에 대한 글에서 확인이 가능하다.
celery json logging
1. logging format json으로 하기
-
🔥 log file을 수집하고 search & query 등을 위해서는 모든 로깅을 하나의 format으로 맞추는게 관리하기 편하고 유리하다. 해당하는 logging 설정들은 모두 django 설정 파일과 관련되어 있다. (django + celery...). python logging을 좀 더 알고 싶으면 해당 글을 참조하길 바란다!
-
🔥 Python logging 모듈에 대한 정보는 해당 글을 참조하길 바란다!, 만약 python logging module에 익숙하지 않으면 꼭 먼저 살펴보길 추천한다!
-
🔥 JSON-log-formatter 활용하여 django에서 logging되는 formatter 자체를 편하게 바꿀 수 있다. django에서는
config(디렉토리명은 다를 수 있다) > settings에서LOGGING값을 활용해서 전역 로깅을 컨트롤 한다.

- JSON-log-formatter 라이브러리의 docs를 활용해 custom logging formatter를 만들고,
formatters > json을 추가해서 해당 포메터를 매핑하면 된다. 상세 사항은 사실 django logging docs를 보는 것이 훨씬 낫다.
DEVELOP_LOGGING = {
"version": 1,
"disable_existing_loggers": False,
"root": {"level": "INFO", "handlers": ["file"]},
"formatters": {
"default_formatter": {
"format": (
"%(asctime)s [%(levelname)-8s] " "(%(module)s.%(funcName)s) %(message)s"
),
"datefmt": "%Y-%m-%d %H:%M:%S",
},
"json": {
"()": CustomisedJSONFormatter,
},
},
"handlers": {
"console": {
"level": "INFO",
"class": "logging.StreamHandler",
"formatter": "default_formatter",
},
"file": {
"level": "INFO",
# 'filename': BASE_DIR / 'logs/django_all_about.log',
"class": "logging.handlers.TimedRotatingFileHandler",
"when": "midnight",
"interval": 1,
"formatter": "json",
"encoding": "utf-8",
},
},
"loggers": {
"django": {
"handlers": ["console", "file"],
"level": "INFO",
"propagate": False,
}
},
}2. celery signal 활용, logger 변경하기
- 우리가 확실하게 고민해 볼 점은 위에서 본 django에서 로깅포멧팅을 한 것이 아니라, django base로 돌아가는 celery logging에 대한 고민을 할 필요가 있다. (게시글 최상단에 설명 기준이 되는 project-repo가 있다. 해당 부분에서 docker compose file 보면 더 빠르게 이해가 된다.)
- django base image로 container 만들어서 돌아가는 celery가 쓸모없는 장고 로깅까지 중복으로 만드는 것은 아닌가?
- 뿐 아니라 celery-beat 까지 포함해서 로깅 파일이 분산 저장, 중복 저장에 대한 리스크는 없을까?
- celery와 django의 logging 되는 형태와 메세지 타입도 다르다. 해당 부분은 django와 공통된 json formatter 를 사용할 수 없다. 그러면 djanog config를 손대야 하는가?
- 사실 celery logging을 따로 해야하고, 쓸모없는 logging 방지를 위해 한 곳 몰빵이 좋다. celery는 celery 본인만, celery beat는 beat본인 로그만 만들 수 있도록, 세팅하는게 좋다. 물론 이건 infra를 어떻게 가져가느냐에 따라 굉장히 다르다. 특히 AWS EB와 같은 PaaS는 더욱 더 다를 것이다.
1) 우선 가장 기본적으로 celery 전용 json formatter 만들기
- django에서 활용한 JSON-log-formatter를 그대로 활용해 또 다른 json formatter를 만든다.
class CeleryJSONFormatter(CustomisedJSONFormatter):
def json_record(self, message: str, extra: dict, record: logging.LogRecord) -> dict:
extra = super().json_record(message, extra, record)
# Update task info.
task = get_current_task()
if task and task.request:
extra["task_id"] = task.request.id
extra["task_name"] = task.name
else:
extra["task_id"] = None
extra["task_name"] = None
return extra- celery log 자체에 대한 depth있는 정보는 공식 홈페이지를 꼭 참조하길 바란다.
2) celery app을 "만들때" 포메팅 설정하기
- 해당 json-formatter가 django에서 celery app을 런타임에 올릴 때 필요하다. 보통
config > celery.py에 celery 관련 설정 파일을 만들어 둔다. 해당 파일에서 celery가 제공하는 데코레이터를 활용하면 편하다. 다양한 셀러리 로깅 전략은 이 글에서 확인할 수 있다.
@after_setup_logger.connect
@after_setup_task_logger.connect
def setup_logger(
sender=None,
logger=None,
loglevel=None,
logfile=None,
format=None,
colorize=None,
**kwargs,
):
from django.conf import settings
formatter = CeleryJSONFormatter()
# Console
stream_handler = logging.StreamHandler()
stream_handler.setFormatter(formatter)
# File
celery_log_path = (
str(settings.CELERY_BEAT_LOG_PATH)
if settings.CELERY_BEAT_FLAG
else str(settings.CELERY_LOG_PATH)
)
file_handler = TimedRotatingFileHandler(
filename=celery_log_path, when="D", interval=1, backupCount=5, encoding="utf-8"
)
file_handler.setFormatter(formatter)
# Set Handler
celery_log_level = logging.getLevelName(settings.CELERY_LOG_LEVEL)
# Replace default Celery console handler to avoid duplicated console log message.
logger.handlers[0] = stream_handler
logger.addHandler(file_handler)
logger.setLevel(celery_log_level)-
TimedRotatingFileHandler를 로깅 핸들러로 사용하고, 우리가 만들어둔 custom formatterCeleryJSONFormatter를 포메터로 사용한다. 핵심은@after_setup_logger.connect와@after_setup_task_logger.connect데코레이터를 사용하는 것이다. -
그리고 django config를 가져와 beat와 celery logging을 분기하는데, 해당 값은 "우리가 container 내부에서 실행하는 환경변수 컨트롤 + django config file 설정" 을 활용한다.
-
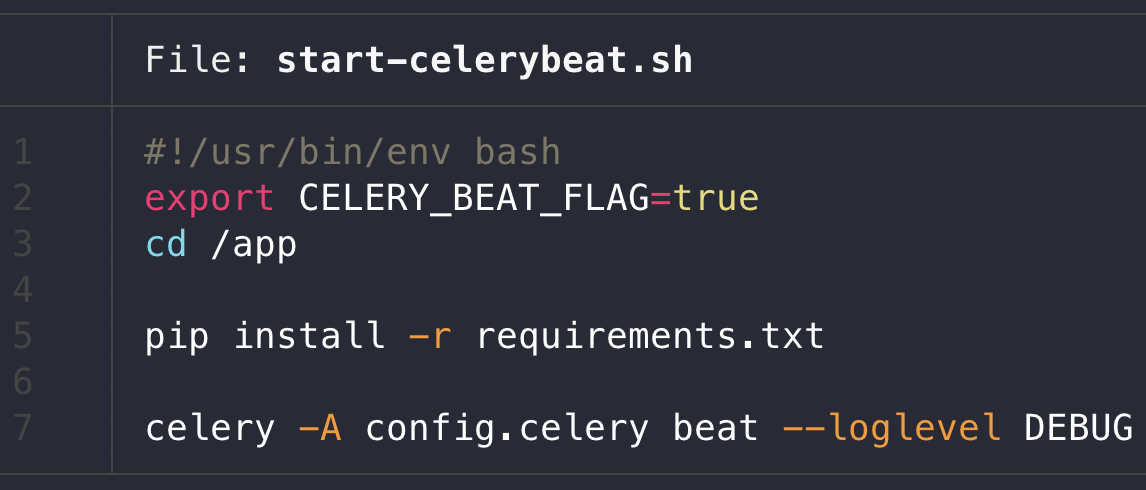
config > settings에서 아래와 같이 세팅하고, celery worker start shell은 다음 첫 번째 사진, beat는 그 다음 사진과 같이 start shell script를 세팅하면 편하다.
# celery logging
CELERY_LOG_LEVEL = "INFO"
CELERY_LOG_PATH = f"{BASE_DIR}/logs/daa-celery.log"
CELERY_BEAT_LOG_PATH = f"{BASE_DIR}/logs/daa-celery-beat.log"
CELERY_BEAT_FLAG = env.bool("CELERY_BEAT_FLAG", False)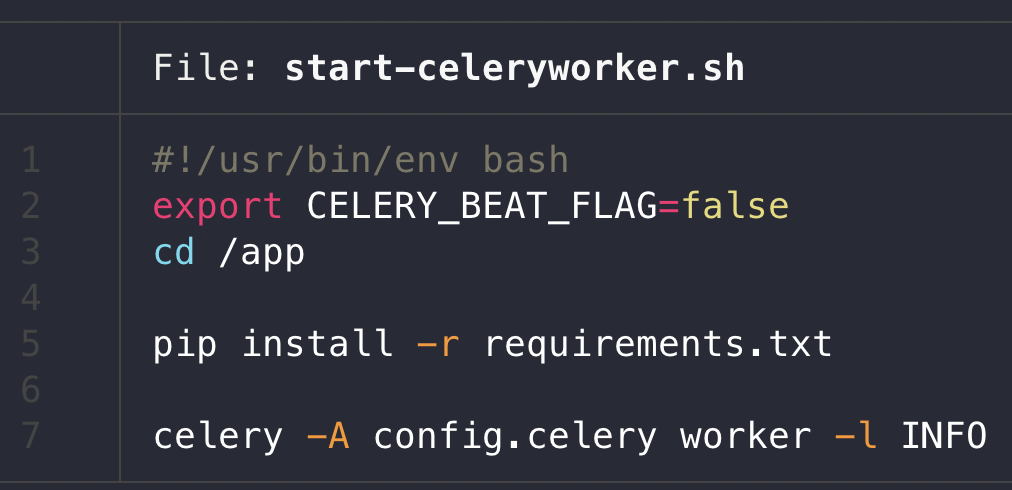
- 더 이상 깊게들어가면 python 자체의 Logging system을 체크하게 된다,, 다음으로 넘어가자.
Flower
celery의 아주 기본적인 task monitoring GUI tool이다. 한 번에 전체적인 task를 살펴볼 수 있다. 앞 글에서 사진으로 잠깐 살펴봤다.
1. 제공하는 기능

-
공식홈페이지에서 더 자세한 내용을 살펴볼 수 있다. 핵심 활용기능은 전체 task 진행 사항과 M.Q에 대한 health check도 가능하다. 당장 돌아가는 상태를 real-time으로 체크할 수 있다.
-
그리고 metrics를 API로 제공해 해당 데이터로 prometheus와 바로 연동해 grafana까지 확장해 real-time 시각화가 가능해서 당장의 bottleneck, memory usage, pre-fetch, pre-fork time등 바로 확인이 가능하다.
2. celery에 flower 연동하기
- 간단하다!
pip install flower로 설치 후 celery cli로 바로 실행이 가능하다.
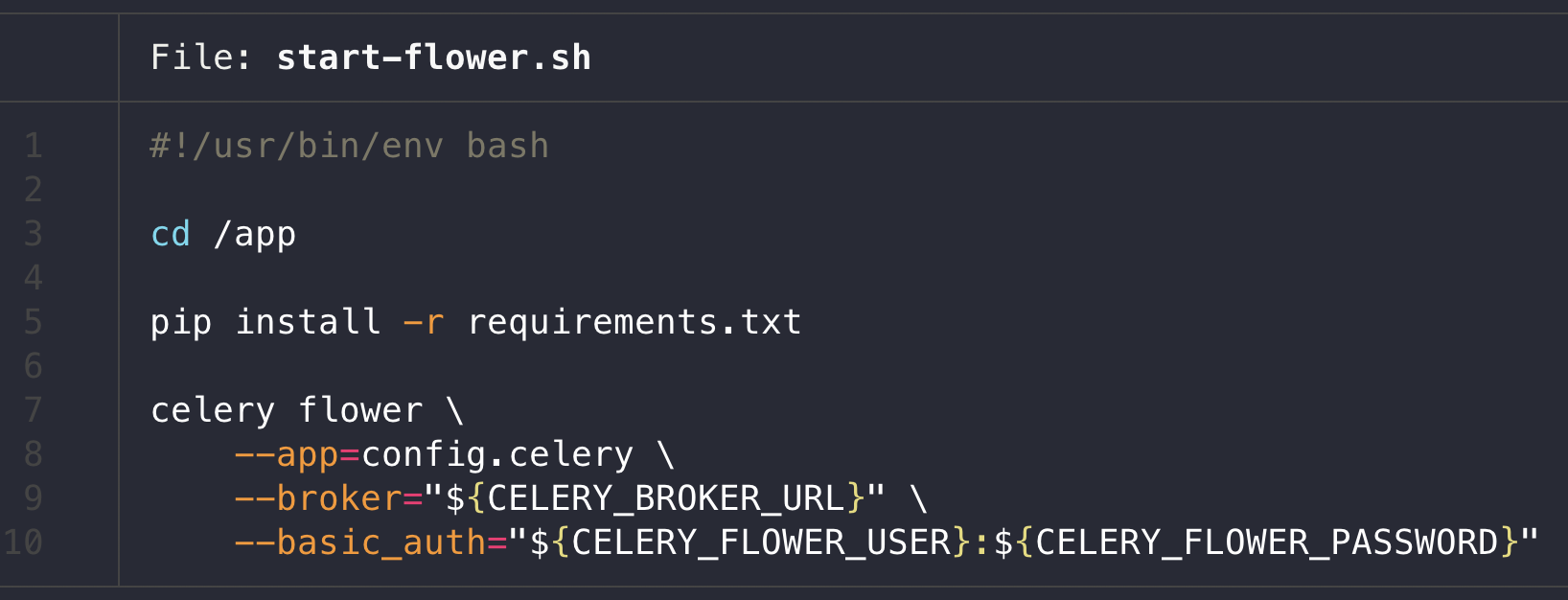
broker만 세팅하면 바로 사용가능하며, http basic auth도 제공하기 때문에 가능하면 최소한의 암호화는 해두는게 좋다.
3. flower 툴 활용하기
- 원래 celery는 자체 "모니터링 툴"을 제공했다. 하지만 https://github.com/mher/flower/issues/1107 에서 보면 모니터링 탭을 없앳다는 것을 볼 수 있다. 그래서 진짜 시각화와 모니터링은 다음 섹션에서 살펴보자.
1) 메인화면에서 바로 celery cluster (worker 그룹) 확인 가능

- celery app 몇 개인지, 어떤 cluster로 돌아가는지 (hostname), 해당 app의 load average는 어떤지, celery 앱을 가동 한 뒤, async task들의 status (Active, Processed, Failed, Succeeded, Retried)를 바로 확인할 수 있다.
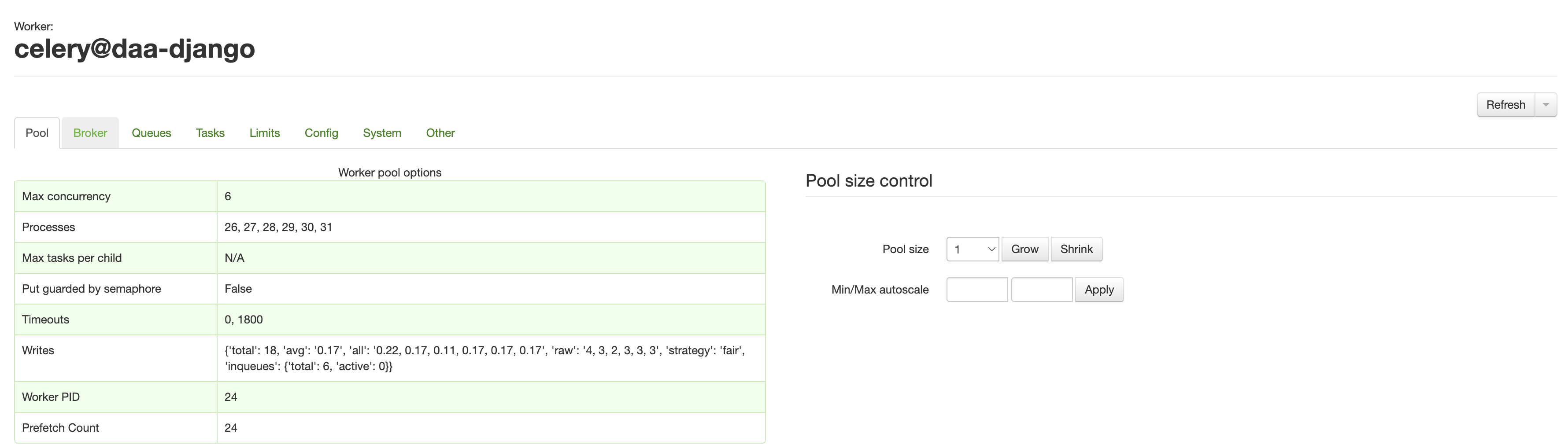
- 그리고 celery app을 클릭해서 들어가면 세부설정과 Broker (M.Q)에 대한 정보도 설정값과 함께 바로 확인이 가능하다. 초기 세팅하고 설정값이 제대로 박혔는지 체크할 때 아주 유용하게 활용할 수 있다. ssh로 붙어서 celery app 자체의 logging을 보거나 shell에 붙어 config 를 찍으면서 확인할 필요가 없다!! 더불어 내가 놓친 설정이 없는지 (특히 timezone) 바로 확인도 가능하다.
2) task 상세 정보
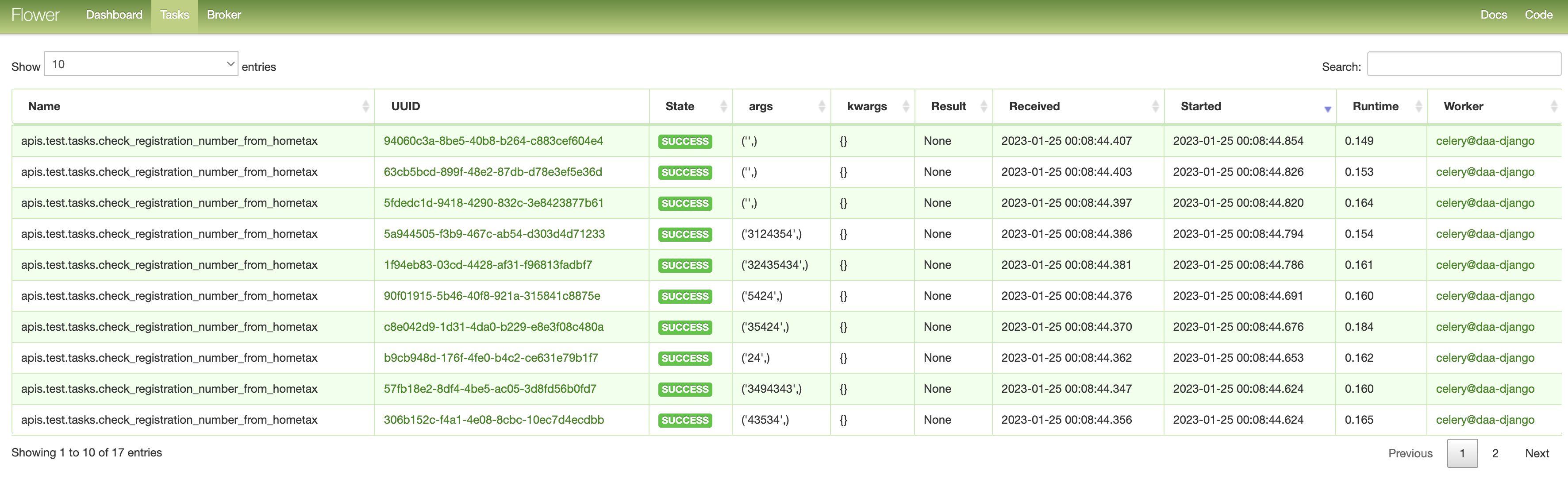
- 상단 nav-bar에서 Tasks Tab에서는 실시간으로 처리중인 async task를 바로 확인할 수 있다.
Received가 Broker로 부터 작업을 하달 받은 최초 시간이다.Runtime과 넘겨준 인자값, 키워드값 모두 확인이 가능하며, return값이 있으면 따로 처리하지 않았어도 Result를 확인할 수 있다.
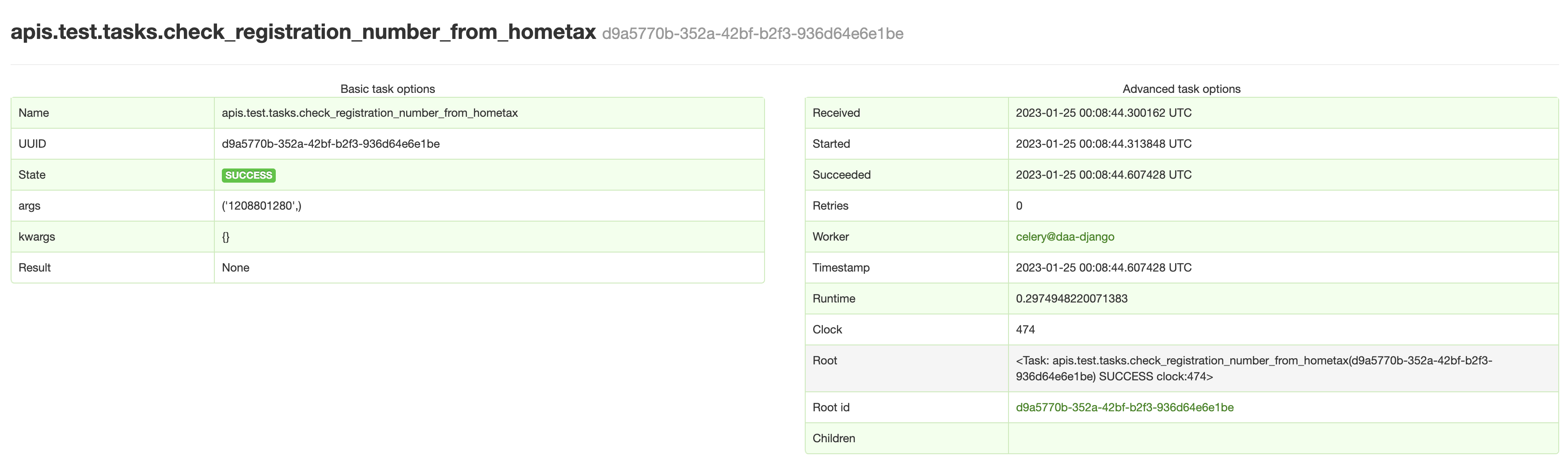
- uuid를 클릭하면 더 세부 정보를 확인할 수 있다. 만약 Root가 따로 있다면 (group, chain 등에서) root uuid 를 바로 확인 가능하고, 해당 task 세부정보로 바로 이동도 가능하다.
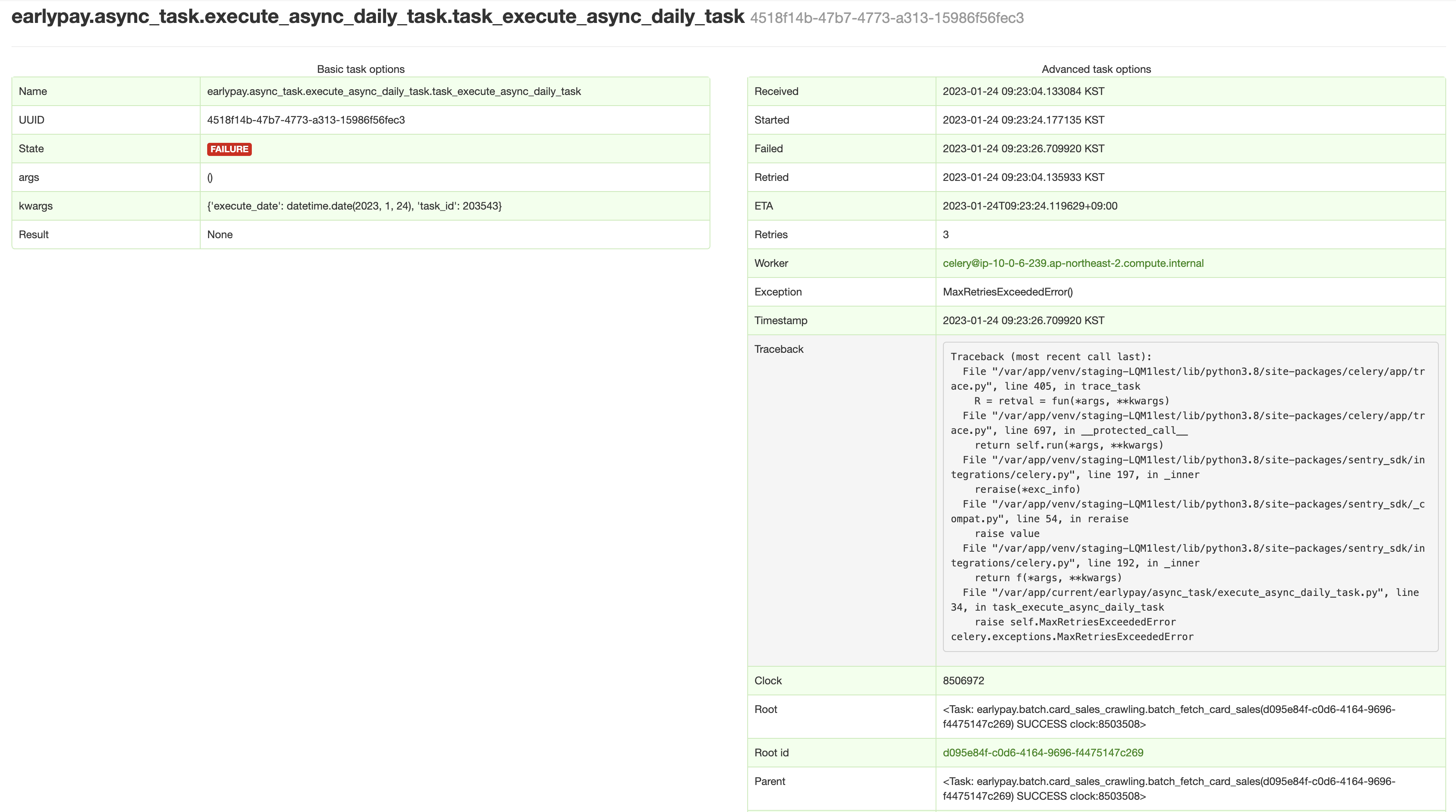
- 만약 이슈가 있으면
Traceback도 바로 확인할 수 있다. 그리고 상세한 디버깅과 추적을 위해서는 이 task id, uuid 값으로 grafana와 loki + promtail를 활용해 log를 수집해 task id를 query 때리면 바로 찾을 수 있다.
Prometheus
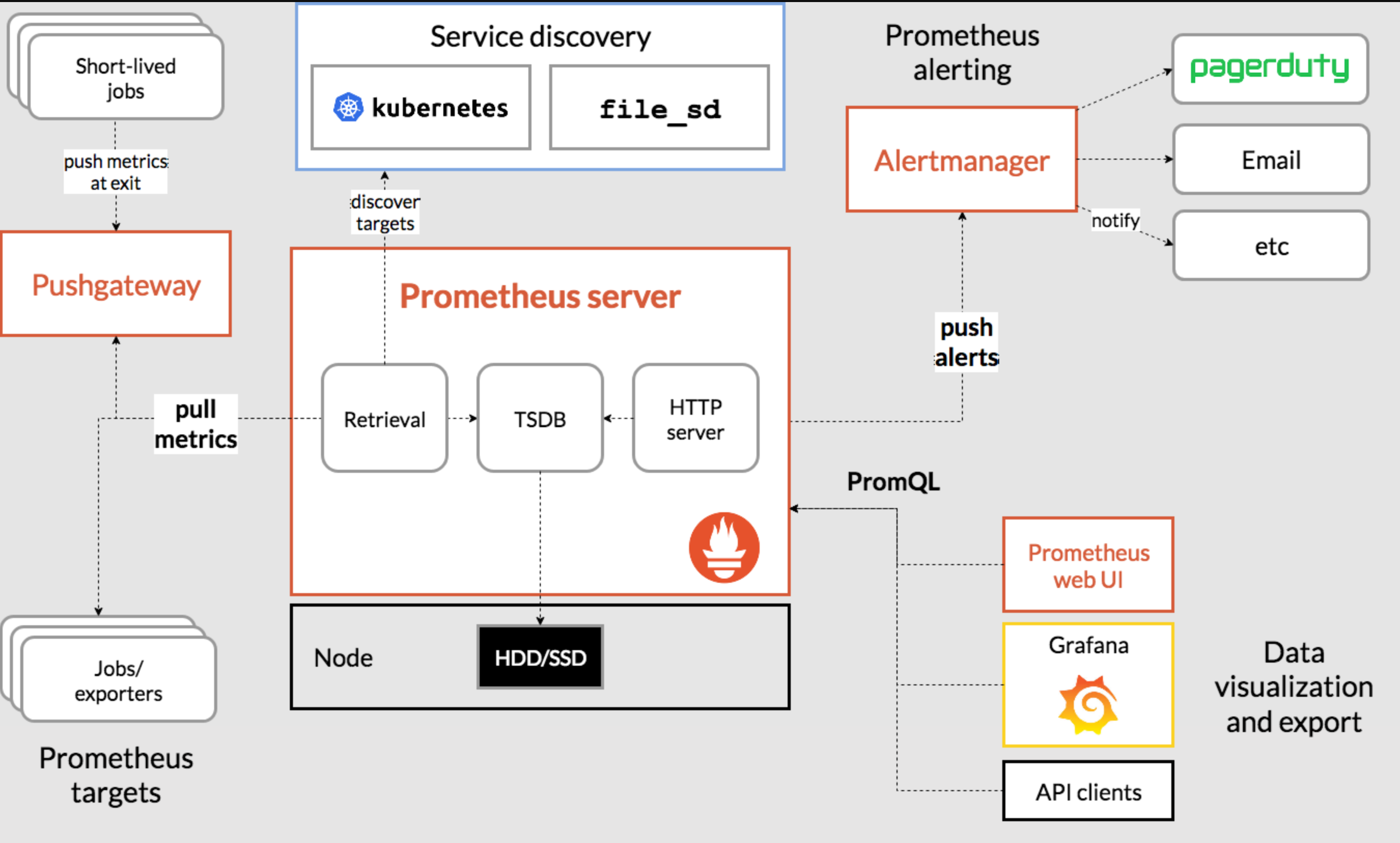
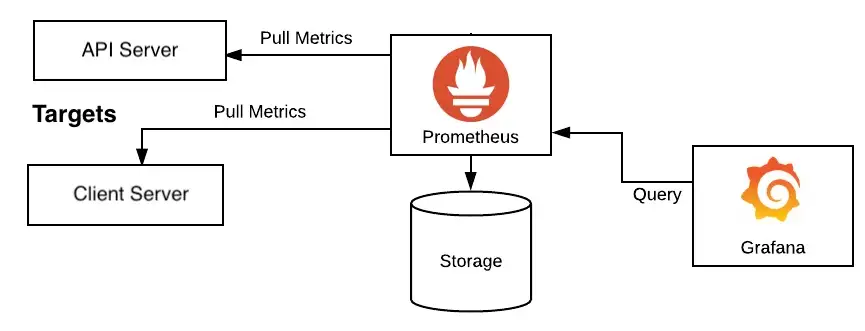
1. prometheus란
- 너무 depth있게 살펴보지 말고, 활용을 위한 전체 그림을 살펴보자
메트릭 수집 부분, Exporters
-
prometheus는 기본적으로 수집하려는 target server(system)에서 메트릭(Metric) 정보를 수집한다. 일반적으로 agent형식으로 target server에 있다.
-
Target System에서 메트릭을 수집하는 방식은 pulling 방식을 사용한다. 프로메테우스가 주기적으로 Exporter(agent)로 부터 메트릭 읽어와서 수집한다. 보통 모니터링 시스템의 에이전트 들은 에이전트가 "모니터링 시스템으로 메트릭을 보내는 pushing 방식"을 사용한다. 특히 푸쉬 방식은 서비스가 오토 스켈링등으로 가변적일 경우에 유리하다.
-
pulling 방식의 경우 모니터링 대상이 "가변적으로 변경될 경우(cloud 환경에서 host ip가 같은 네트워크 내부에서 DHCP 등에 의해 바뀌는 경우)", 모니터링 대상의 IP 주소들을 알 수 가 없기 때문에 어려운 점이 있다.
-
예를 들어 웹서버 VM 2개의 주소를 설정 파일에 넣고 모니터링을 하고 있었는데, 오토 스케일링으로 인해서 VM이 3개가 더 추가되면, 추가된 VM들은 설정 파일에 IP가 들어 있지 않기 때문에 모니터링 대상에서 제외 된다.
-
이러한 문제를 해결하기 위한 방안이 서비스 디스커버리 라는 방식인데, 특정 시스템이 현재 기동중인 서비스들의 목록과 IP 주소를 가지고 있으면 된다. 예를 들어 앞에서 VM들을 내부 DNS에 등록해놓고 새로운 VM이 생성될때에도 DNS에 등록을 하도록 하면, DNS에서 현재 기동중인 VM 목록을 얻어와서 그 목록의 IP들로 풀링을 하면 되는 구조이다.
-
Exporter 는 단순히 HTTP GET으로 메트릭을 텍스트 형태로 프로메테우스에 리턴 한다. 요청 당시의 데이타를 리턴하는 것일뿐, Exporter 자체는 기존값(히스토리)를 저장하는 등의 기능은 없다.
서비스 디스커버리 (Service discovery), Retrieval
-
Service discovery 개념은 MSA와 같은 분산 환경에서 서비스 클라이언트가 서비스를 호출할때 서비스의 위치 (즉 IP주소와 포트)를 알아낼 수 있는 기능 을 말한다. 더 자세한 내용은 이 글로 대체 하겠다.
-
그래서 프로메테우스도 서비스 디스커버리 시스템과 통합을 하도록 되어 있다. 앞에서 언급한 DNS나, 서비스 디스커버리 전용 솔루션인 Hashicorp사의 Consul 또는 쿠버네티스를 통해서, 모니터링해야할 타겟 서비스의 목록을 가지고 올 수 있다.
-
서비스 디스커버리 시스템으로 부터 모니터링 대상 목록을 받아오고, Exporter로 부터 주기적으로 그 대상으로 부터 메트릭을 수집하는 모듈이 프로메테우스내의 Retrieval 이라는 컴포넌트이다.
저장, serving
-
수집된 정보는 프로메테우스 내의 메모리와 로컬 디스크에 저장 된다. 뒷단에 별도의 데이타 베이스등을 사용하지 않고, 그냥 로컬 디스크에 저장하는데, 그로 인해서 설치가 매우 쉽다는 장점이 있지만 반대로 스케일링이 불가능하다는 단점 을 가지고 있다. 대상 시스템이 늘어날 수 록 메트릭 저장 공간이 많이 필요한데, 단순히 디스크를 늘리는 방법 밖에 없다.
-
저장된 메트릭은 PromQL 쿼리 언어를 이용해서 조회가 가능하고, 이를 외부 API나 프로메테우스 웹콘솔을 이용해서 서빙이 가능하다. 또한 그라파나등과 통합하여 대쉬보드등을 구성하는 것이 가능하다.
2. flower의 지표를 prometheus로 연계
-
flower는 3-party exporter 없이 자체적으로 metric 정보를 제공한다. 공식 홈페이지 에서도 prometheus와 integration 가이드도 제공한다.
-
localhost:5555/metrics에 (celery flower host에) curl 또는 http get 때려보면 엄청난 메트릭 지표를 던져준다. 그 지표를 prometheus가 polling만 하면 되기 때문에 설정이 아주 간단하다. -
prometheus official docker image를 사용하면 아주 쉽게 활용할 수 있다. 여기 docker compose file 을 살펴보자.
volumes으로 잡아주는 config 파일이 아래와 같다.
# prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['dda-prometheus:9090']
- job_name: flower
static_configs:
- targets: ['dda-flower:5555']global값으로 pulling 주기와 target server에 대한 config를job_name하위로쭉 해주면 된다.
basic_auth:
username: "flower"
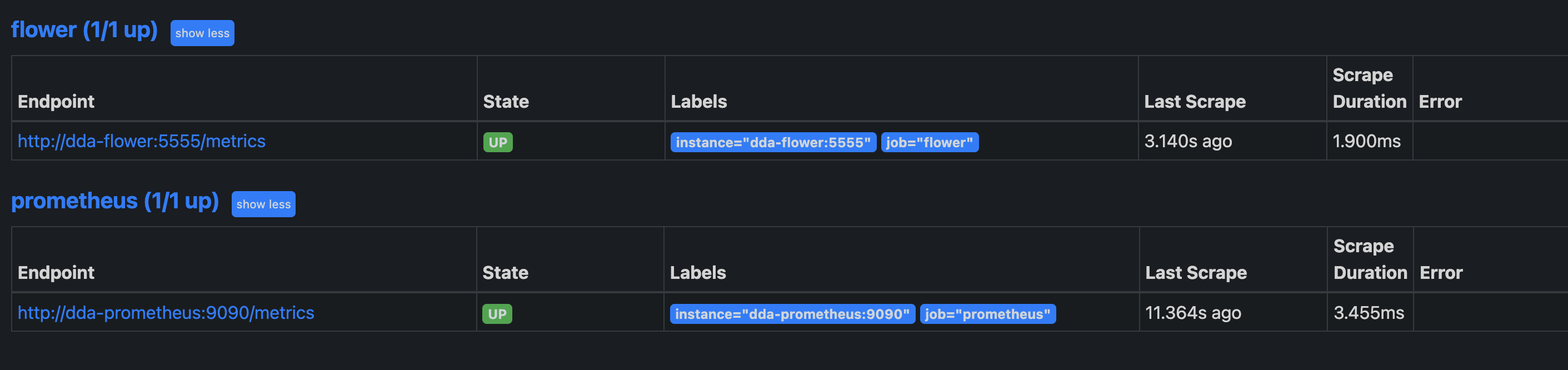
password: "flower"flower에 basic auth (Http auth)를 해 두었으면 위와 같은 값을 추가하면 된다. 그리고localhost:9090에 접속해서 상단바Status > Targets에 아래와 같이 뜬다면 성공이다.
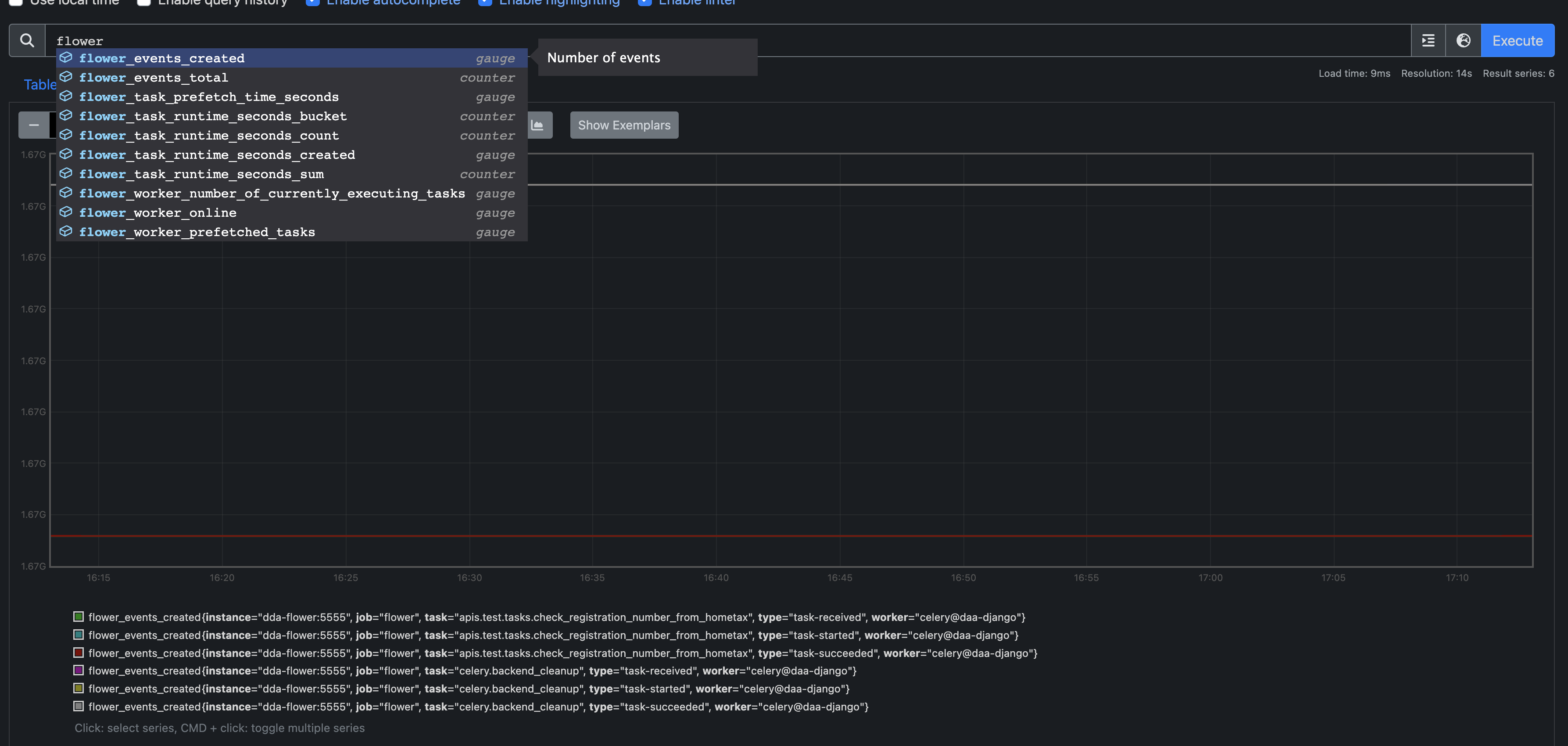
- 그리고 main search 화면에서 flower와 관련된 값을 검색하면 저렇게 검색가능한 metric 정보가 뜨고, graph로 볼 수 있다. 이 때 사용하는 Search query 방식을
PromQL이라고 한다. 나중에 살펴볼Grafana도 이PromQL과 비슷한 방식으로Loki에게 질의한다.
3. Django 지표를 prometheus로 연계 & 모니터링, 그에 따른 서버 모니터링
-
django 자체도 모니터링을 해보자. django host의 exporter가 필요하다. 그래서 django-prometheus 라는 라이브러리를 활용한다.
INSTALLED_APPS,MIDDLEWARE,url & path만 추가해주면 바로 기본적인 metric 정보를 수집가능하다. -
그리고 위 (2. flower) 세팅에서 했듯이,
prometheus.yml에 아래 job만 추가해주면 바로 수집이 가능하다. 더 다양한 metric 수집과 정보는 위 해당 라이브러리 깃허브 페이지에서 확인하길 바란다.
- job_name: django
static_configs:
- targets: ['daa-django:8000']
Grafana (with Loki & Promtail)
-
아주 간단하게 말하면 Grafana 자체는
Data Visualization Tool이다. 쉽고, 가볍고, 사용하기 편하다. 그래서 kibana와 같은 heavy 한 tool에 비해 light한 사용으로 매우 각광받고 있다. 시계열 매트릭 데이터를 시각화 하는데 가장 최적화된 대시보드를 제공해주는 오픈소스이다! -
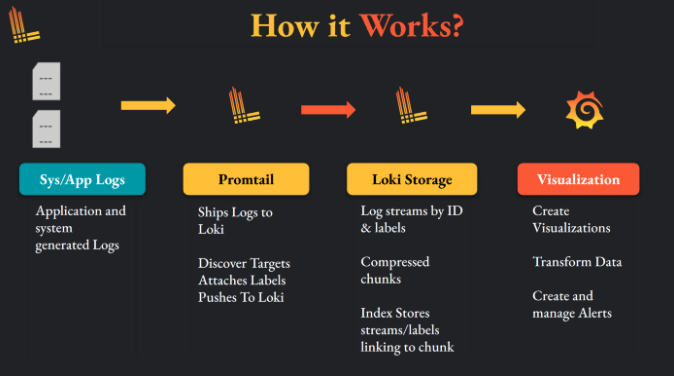
하지만 Grafana만 사용할 것은 아니다, django + celery + celery beat + nginx(web server) + redis ... 등 다양한 stack으로 구성된 web stack에서 발생하는 아주 다양한 log를 수집하고 (loki + promtail) 다시 grafana로 대시보드 세팅을 할 수 있다.
- Loki: simple logging db, like ES
- LogQL: Loki에 저장된 데이터를 조작하기 위한 Query이다.
- Promtail: simple logging agent, like logstash or fluented -> 얘는 수집 대상이 되는 서버에 설치가 되고 가동되어야 한다.
1. Prometheus 단계에서 연계된 prometheus의 지표 값을 grafana로 모니터링
-
위에서 다양한 metric 정보를 prometheus에 저장했다. 우린 그 저장된 지표와 정보를 가지고 grafana를 활용해 "시각화 & 대시보드" 구성만 하면 된다.
-
심지어 official docker image를 활용하면 매우 기본 세팅하기도 쉽다. 여기 docker compose 예시 파일을 체크해 보자. 그리고 grafana에 접속해
왼쪽 navbar > Dashboards > import로 간다.
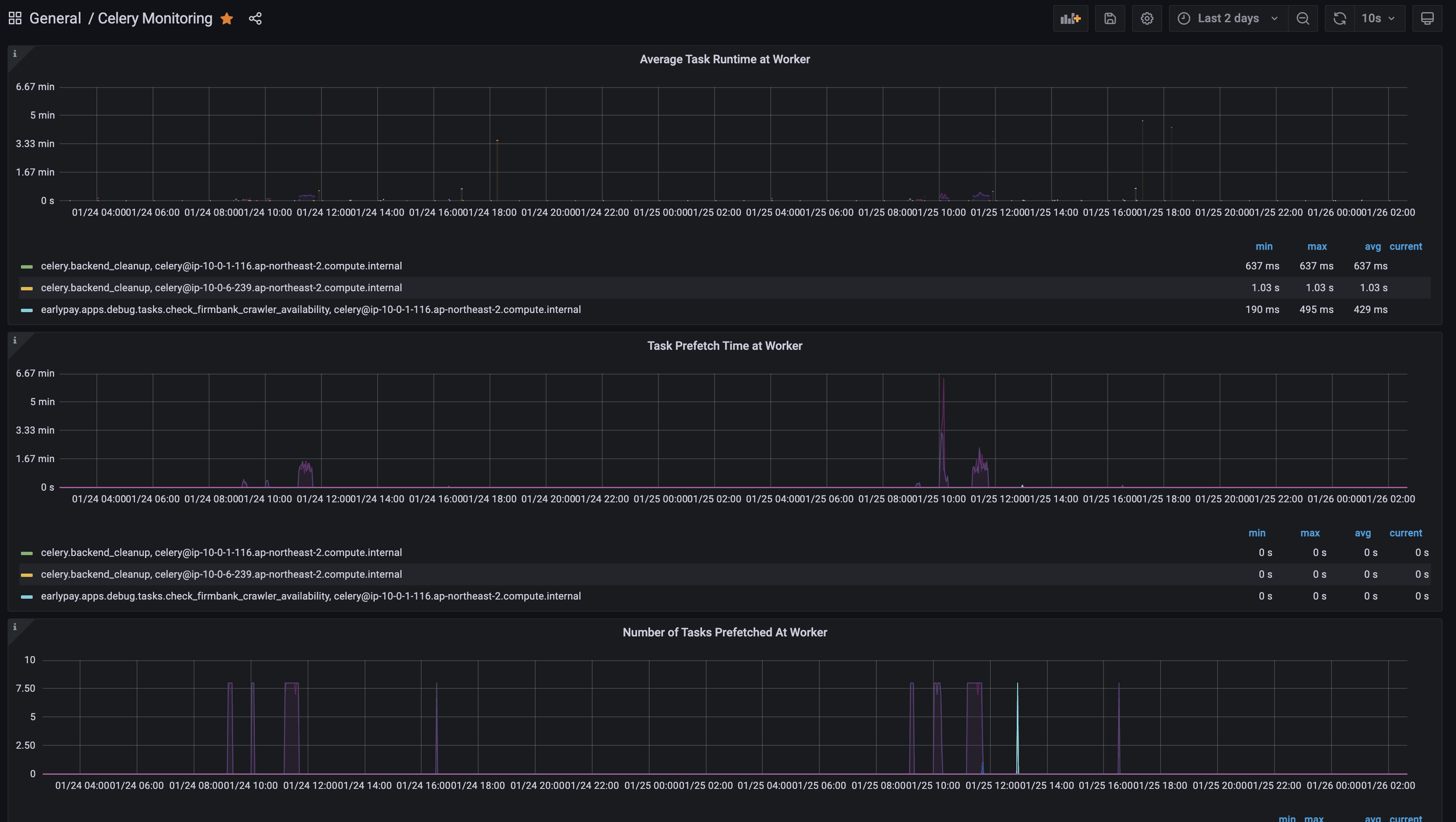
flower monitoring dashboard
-
https://github.com/mher/flower/blob/master/examples/celery-monitoring-grafana-dashboard.json
-
위 json을 그대로 copy & page 때려주고 아래 사진과 같이 세팅해준다. UID값과 NAME은 아마 사진과 다를 것이다!
django monitoring dashboard
-
위 flower 했던 것과 똑! 같이 진행하면 된다.
2. Django & Celery & Gunicorn [optional] & Nginx(webserver) [optional] 에서 만들어지는 log 수집하기.
- 여기가 핵심이다. loki를 통해 django, celery, nginx에서 저장되는 Json type의 log 데이터를 모두 수집해 보자! 우선
loki는 여기 docker compose file 를 확인해 보자.
django & celery 관련 log 수집하는 promtail
- 우리가 모니터링을 위해 가장 처음에 했던 접근이 log를 json type으로 만드는 것이었다. 이제 json type의 log를 "Loki" 로 수집해 보자. Loki(like elsatic)는 로그 저장에 특화된 저장소다. ELK vs PLG stack에 대한 간소한 비교표는 다음과 같다.
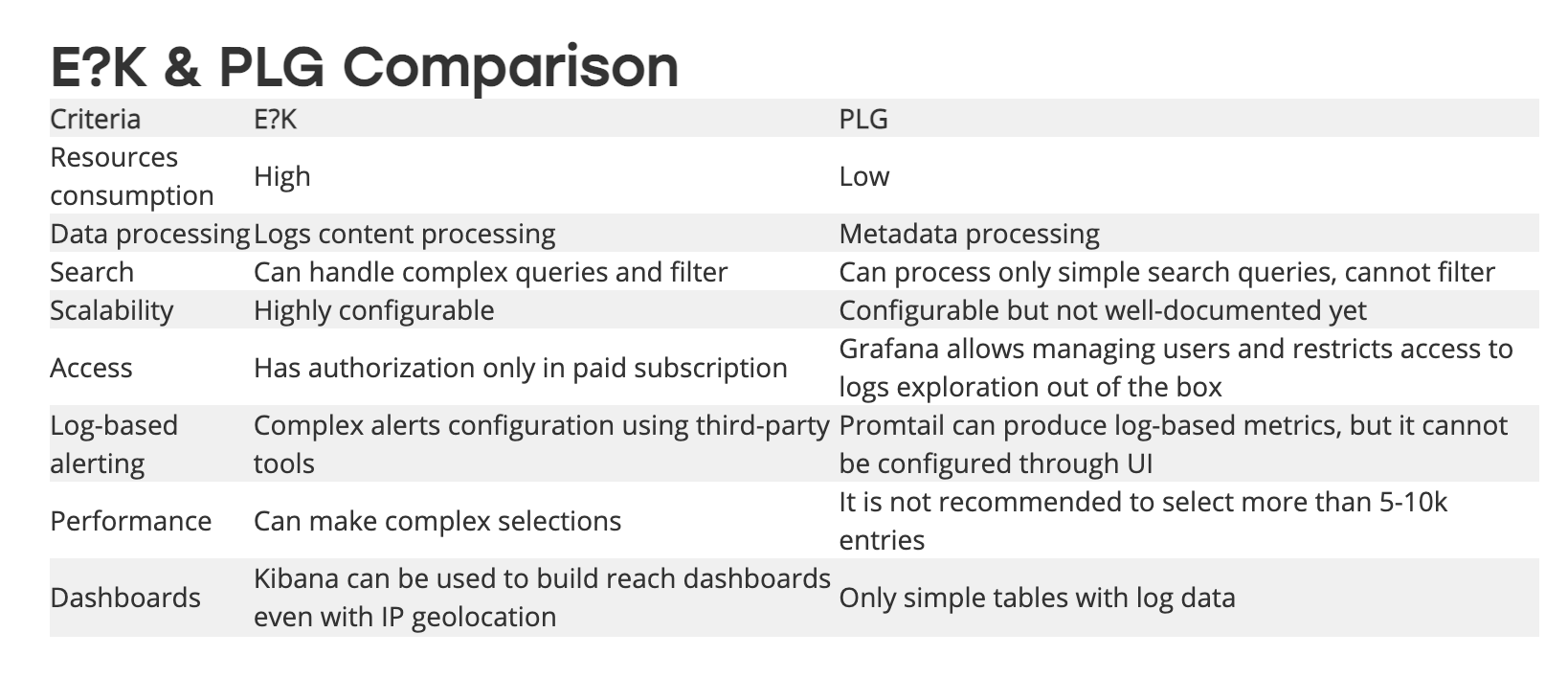
-
자세한 사항은 이미지 출처에서 꼭 읽어보길 바란다.
-
우선 Loik에게 로그를 전달해줄, 위에서 소개한 prometheus의 exporter 의 역할과 같이, server에서 발생되는 "log를 전달해줄 agent가 필요" 하다. 이 agent는 server에 붙어서 log file을 계속 look-up 하면서 loki로 전달한다. fluented, logstash 등이 비슷한 역할을 할 수 있다.
아마 DevOps에 대한 공부나 k8s에 대한 모니터링을 고민해본 분들이라면 바로 이해할 수 있을 것이다. -
여기서 계속 예제로 가져가는, django project의 경우 django 내부에서 결국 django, celery, celery beat 등이 다 만들어지게 되어있다. 가장 쉽게하는 선택은 "django docker image에 포함시키는 것" 이다.
-
Dockerfile 내부를 보자.
...
# promtail install & run
RUN wget https://github.com/grafana/loki/releases/download/v2.2.1/promtail-linux-amd64.zip \
&& unzip promtail-linux-amd64.zip \
&& rm promtail-linux-amd64.zip
...
- 위 부분이 promtail의 releases version을 wget으로 download 받고, unzip까지 하는 과정이다. 그리고 django start를 하는 shell에 아래 내용을 추가하면 사실 끝이다!
...
# promtail run
nohup /promtail-linux-amd64 -config.file=/promtail/config/config.yml > /dev/null 2>&1 &
...- 이렇게 하고 동적으로 config를 가져가고 싶으면 docker-compose.yml file에
volumes를 잡아주면 된다.
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /promtail/positions.yaml
clients:
- url: http://daa-loki:3100/loki/api/v1/push
scrape_configs:
- job_name: daa-django
static_configs:
- targets:
- localhost
labels:
job: djangolog
__path__: "/app/logs/daa-django.log"
- targets:
- localhost
labels:
job: celerylog
__path__: "/app/logs/daa-celery.log"
- targets:
- localhost
labels:
job: celerybeatlog
__path__: "/app/logs/daa-celery-beat.log"-
django log&celery log&celery beat log까지 모두 target으로 잡아주면 된다. promtail이 host에 agent로 상주하니 localhost에서 가져오면 그만이다. 사실 promtail이 굉장히 light하고 오롯이 저 역할에 특화되어 있어서 server에 붙이는게 전혀 부담스럽지 않다. 더 자세한 설정 값들은 공식 홈페이지에서 확인할 수 있다. -
위 client가 우리가 target에서 수집한 log를 전달받을, 즉 loki의 url이 되고, 기본적으로
/loki/api/v1/pushend point로 전달하면 된다. 사실 빡센건 loki쪽 config이다.
수집된 log 특화 보관소 loki 설정
- 우선 loki는 굉장히 경량화 되어 있고, 메타정보만 인덱스하도록 강제되어 있어, 전체를 설정을 통해 구성하는 elasticsearch에 비해 빠르고 간결하며 적은 저장소를 필요로 하는 구조를 갖는다.
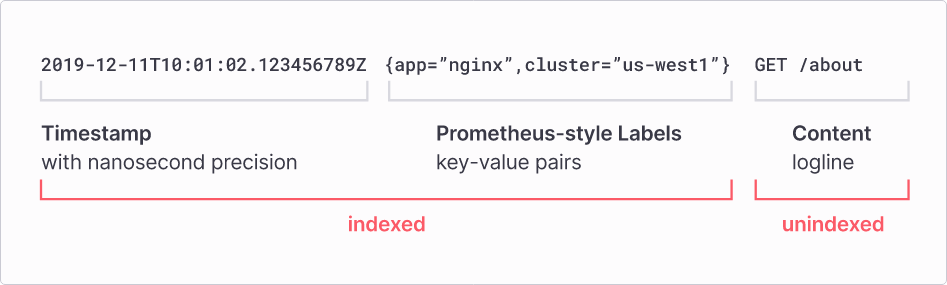
-
docker-compose file에서 loki container를 만들고 config만
volumes로 잡아주면 기본적인 사용 준비는 끝이다. 문제는 loki config가 간단하면 간단하고, 복잡하면 복잡하다. local-config.yaml file 로 loki config file을 만들었다. -
설정은 크게
server,ingester,schema_config,storage_config,compactor,limits_config,chunk_store_config,table_manager,ruler정도를 가지며 각 항목의 세부 설정 값에 대한 설명은 공식 홈페이지 docs에 자세하게 나와 있다 -
모두 default값으로 가져가며,
ingester부분에서 청크 사이즈나, 청크 캐시에 대한 설정값,chunk_store_config에서 log query가 가능한 time, 즉 영구 보관 기간을 얼마나 세팅할지, 그리고 각 port 와 domain, host에 대한 config만 주의깊게 하면 된다.
3. Grafana에서 수집한 log dashboard 만들기
- 위 (2) 에서 loki에서 수집한 log data를 이제 시각화만 하면 된다. 또는 loki 대상으로 바로 query를 할수도 있다! 아주 간편한 log setting 부터 해보자! 새로운 dash board 만들기 >
Add a new panel로 판넬을 추가하면 다음 사진들 처럼 넘어갈 것이다.
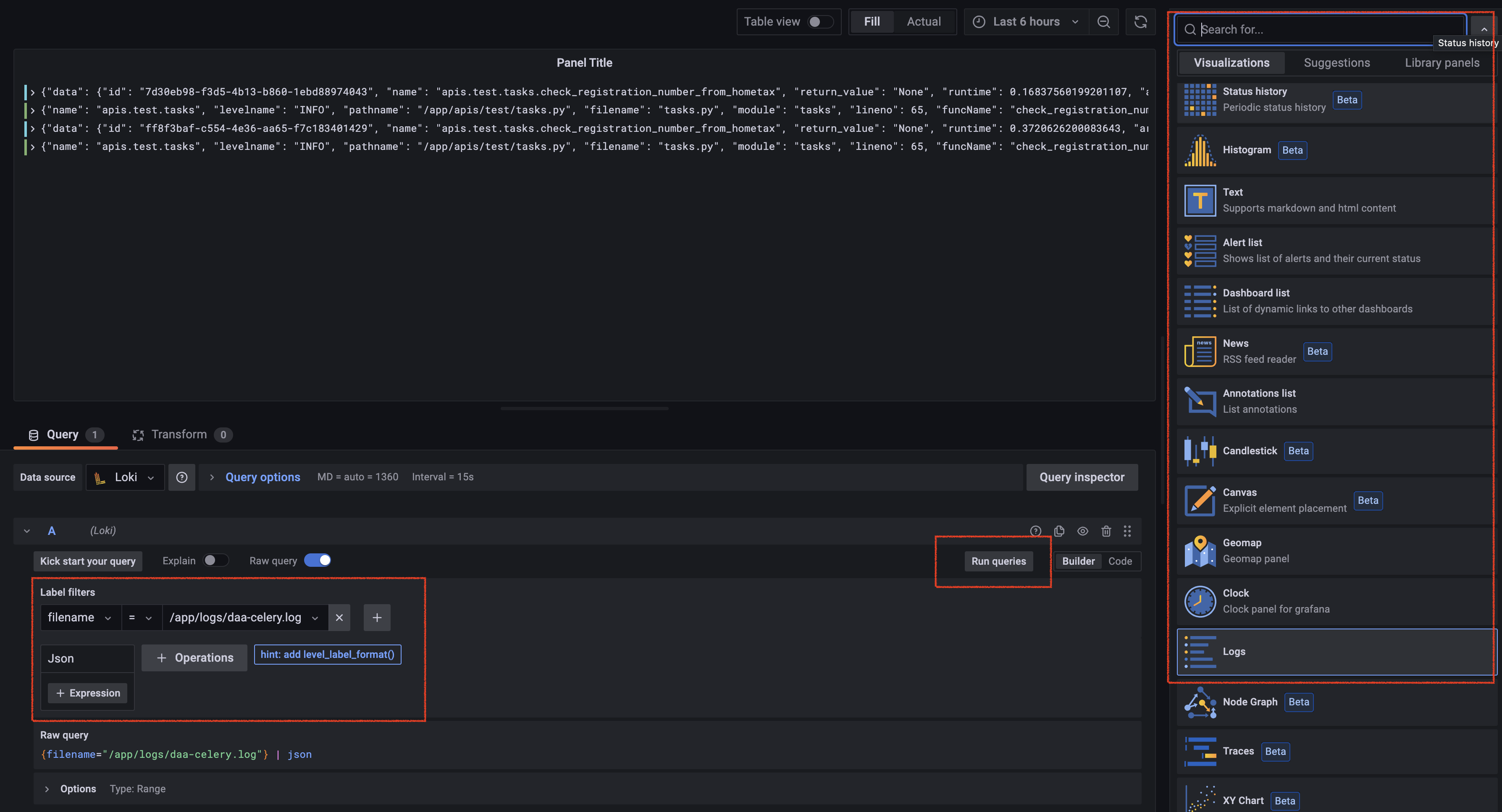
- 빨간 박스와 같이 세팅한 부분만 해도 바로 로그에 대한 전체 결과값을 보기 쉽고, 바로 query 가능한 형태의 panel로 세팅할 수 있다. 그리고 우측의
Visualizations에서 log를 선택한 후 아래 설정값들을 주면 다음 사진과 같은 화면을 볼 수 있다.
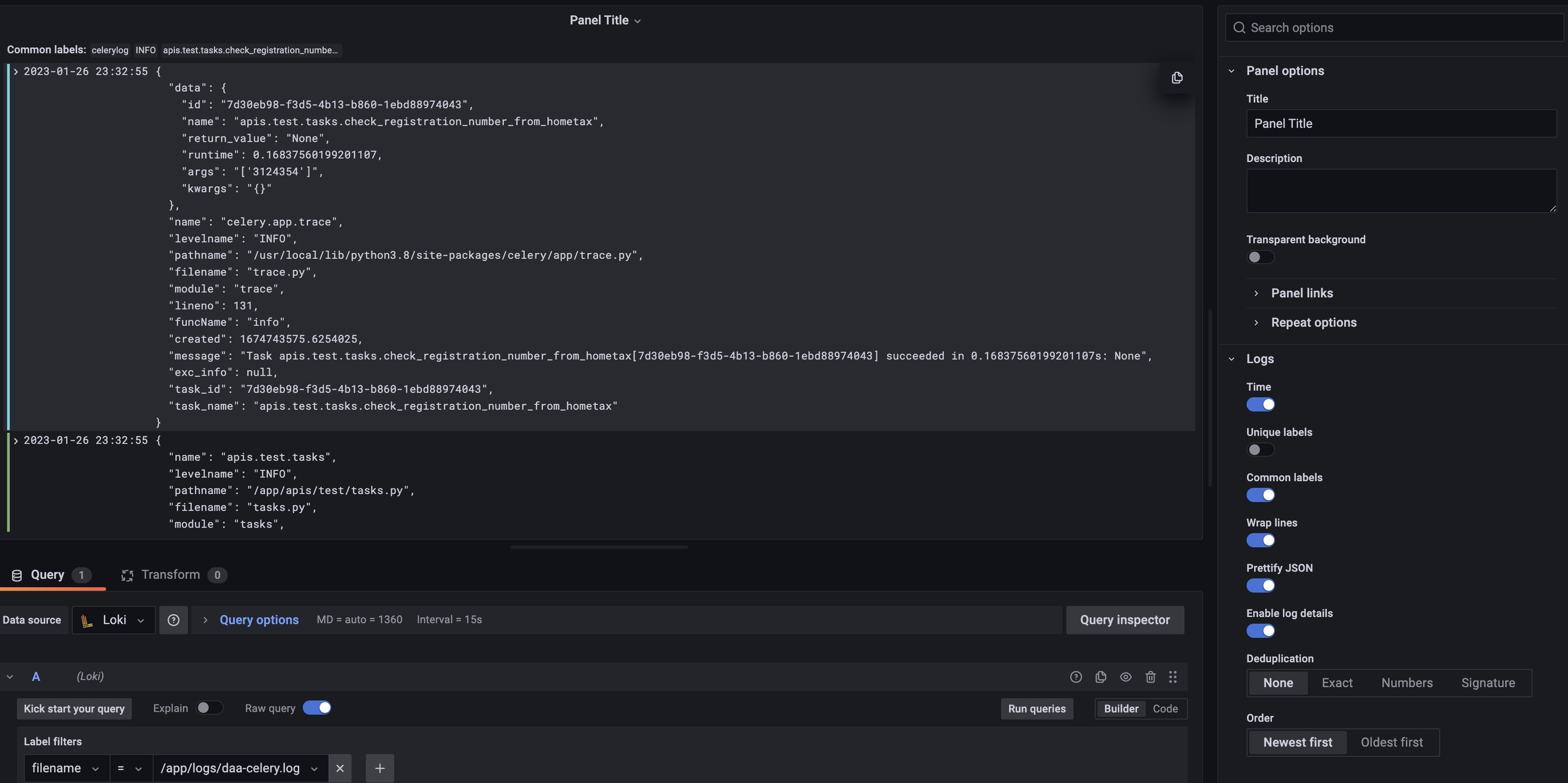
- 여기서 더 팁이 있다. 처음하면 생각보다 panel을 setting하는게 마음대로 되지 않을 것 이다. 기본적인 Query setting과 Transform 세팅을 아래 처럼 follow 해보자
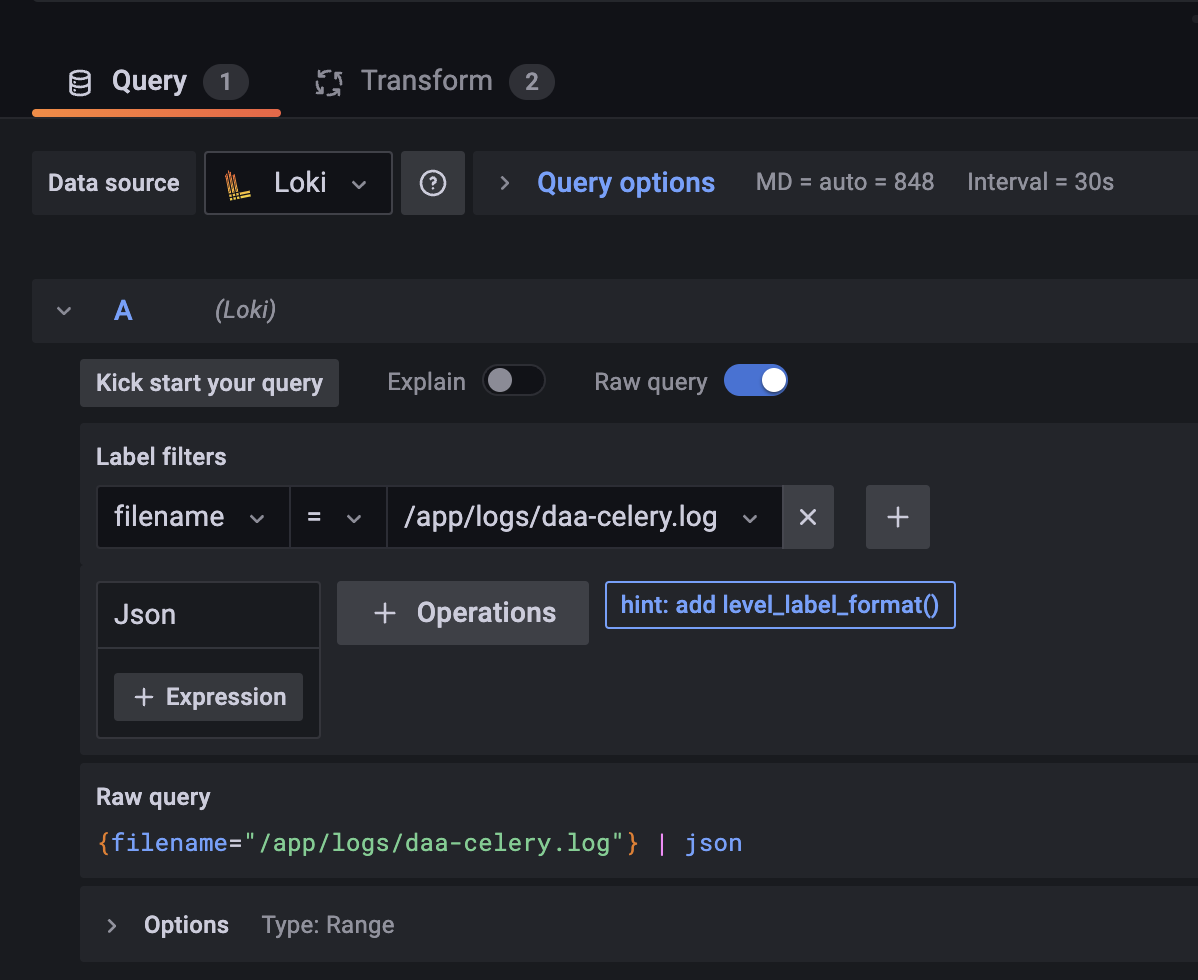
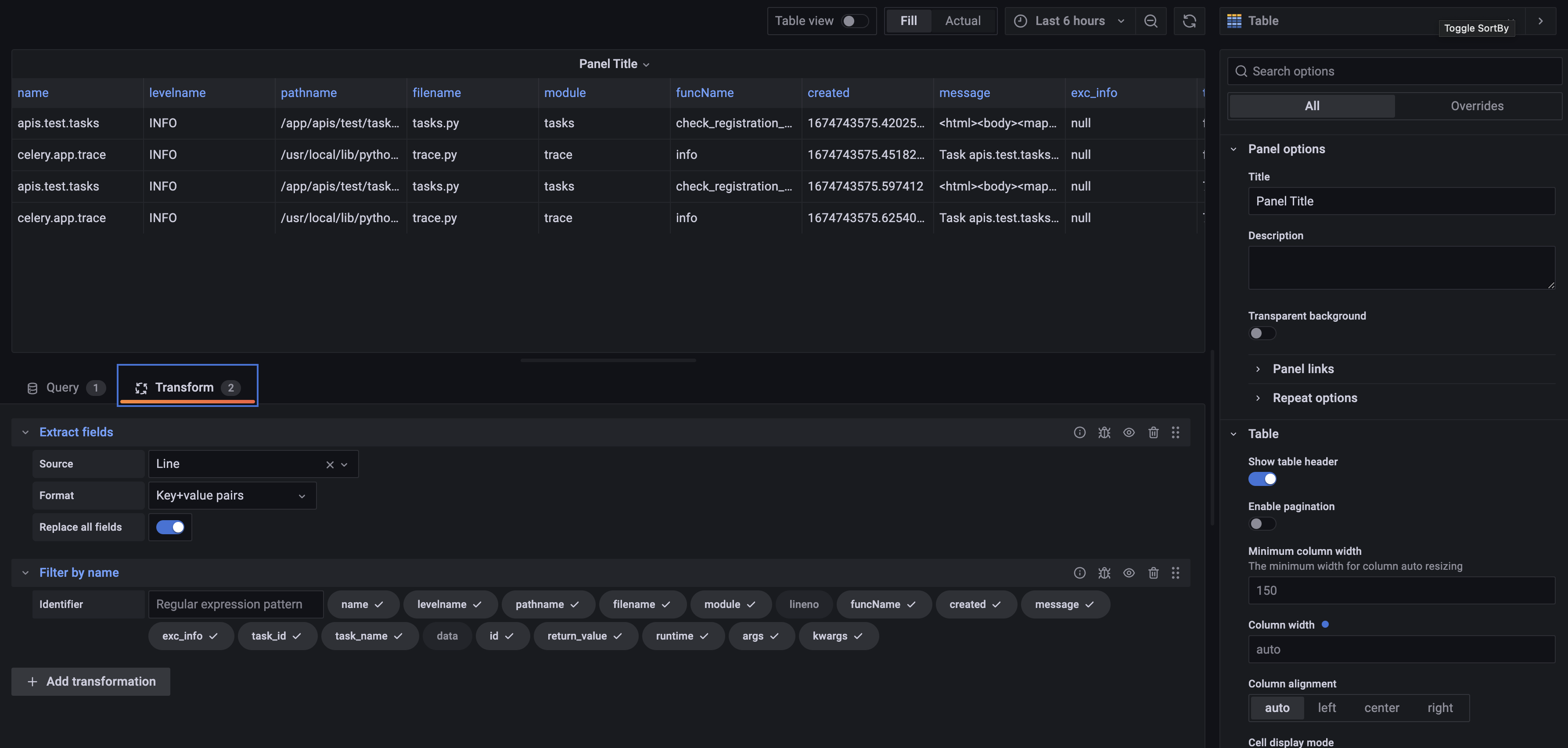
-
가장 먼서 json parsing을 하고,
table로 세팅한 뒤에 "Transform" 을 잘 활용해 보자. 먼저Extract fields로 Line 자체를key + valueExtract 해버리고, Extract 된 field 대상으로 Filter를 걸어버려서 쓸모없는 key들 (lineno, data) 을 제껴주자! -
기본적으로 log file 대상으로 이렇게 세팅해두면 message 만 보고 싶을 때나, error 만 check 하고 싶을 때나, query를 던질때 simple 해 진 상태에서 시작할 수 있다.
마무리
-
debugging 보다는 distributed monitoring system 에 더 치중되어서 조금 아쉽다. debugging은 celery에 초점을 맞춰서 optimization 하는 방법을 위 monitoring을 기반으로 해서 진행하려고 한다. (시리즈 내의 celery section 글로 이어질 예정)
-
꼭 flower + prometheus + grafana(with loki & promtail) stack (flower + PLG stack)을 활용해야하는 것은 아니다. devOps가 고도화 되면서 좋은 엔터프라이즈급 솔루션도 굉장히 많아졌다. 특히 이런 monitoring tool은 cloud 환경, k8s 등을 접목할때 더욱 더 절실하게 필요성을 느끼게 된다.
-
그러 ELK는 별로인가? 위에서 E?K stack vs PLG stack에 대한 비교표가 있다. PLG는 진짜 중소규모 project에 초점이 맞춰져 있다. 사실 분당 트래픽이 몇천, 몇만 단위 이상으로 튀는 system, 그리고 pod가 막 수분 수초 단위로 processing 되는 환경에는 PLG stack에는 아쉬움이 많을 수 있다.
-
핵심은 전체적인 구조를 생각을 계속 해야하는 것이다. [ "log 가 모이는 stream" + "stream에서 multi processing + queue 관리, 저장 (영속성 등을 보장)" + "분산된 데이터 보관소 대상 전체 질의 가능, 시각화 가능" ] 이 기본 전체 구조이며 사실 이 뒷단에 다양한 stack이 붙을 수 있다.
-
Big data를 위한 DW, ETL 등의 Hadoop, Spark ... 으로 이어진다. 그 뒤는 이제 modeling이라고 볼 수 도 있다. data가 모이면 새로운 인사이트가 폭발할 수 도 있다.
결국 개발은 점을 찍으면서 계속 선이 만들어지게 되는 것 같다. -
그리고 이러한 stack을 SaaS가 아닌 직접 서버에 OnPromise로 올리는 것까지는 문제가 없겠지만, 해당 stack의 설정과 해당 stack의 유지보수, 지속적인 관리는 무조건 필요하다. 그런 측면에서 또 리소스가 든다고 생각되면, 무조건 오버엔지니어링을 피하고 선택과 집중을 하라고 하고싶다.
출처
- 문자열링크되어 있는 다양한 참고 자료
- https://www.distributedpython.com/2018/08/28/celery-logging/
- https://docs.celeryq.dev/en/stable/userguide/monitoring.html
- https://velog.io/@sensemint_/1
- https://velog.io/@idnnbi/Loki-Promtail-Grafana
- https://raw.githubusercontent.com/grafana/loki/v2.7.0/production/docker-compose.yaml
- https://flower.readthedocs.io/en/latest/prometheus-integration.html
- https://github.com/danihodovic/celery-exporter

좋은 글 감사합니다!