V.D v2
velog dashboard 를 살려주세요..! 로 부터 다시 시작된 velog dashboard project v2, (이하 V.D v2) 베타 버전 오픈이 되었습니다!!
빨리 접속하기: https://velog-dashboard.kro.kr/
1. 벨로그 대시보드 v2 소개
-
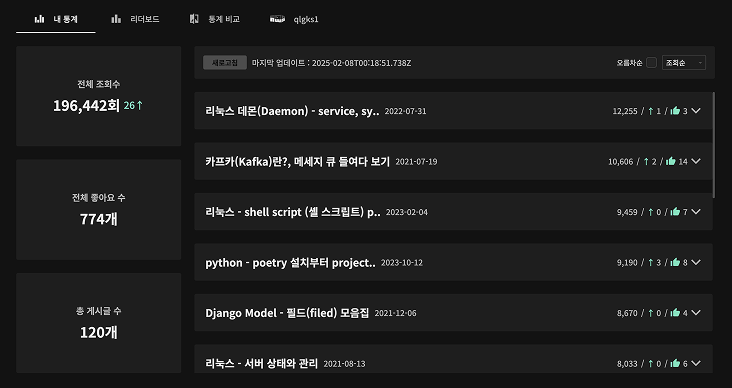
벨로그 통계를 한 번에 보기 편하게 보고 싶다는 욕구에서 시작했던, 개인 사용 목적으로 만들었던 프로젝트를 23년 11월 말에 오픈했었습니다!
-
오픈 1주일만에 신규 유저 분들이 daily 로 10명, 50명 씩 들어오셔서 확실히 공통의 pain point 가 있었구나! 를 많이 느꼈지만!! [ "velog 쪽 통계 API" 에 부하 -> DBMS 부하 -> 특정 DBMS timeout 에러를 유발하는 (벨로그쪽) 크리티컬한 이슈를 일으켜서 ] 2주 정도만에 바로 stop 된 프로젝트입니다 ㅎ : 벨로그야 미안하다!! / velog dashboard 제작기 (3) - frontend & 이슈 & 앞으로
-
velog 가 이제 daily 를 없애고 total 만 보여주고, 그에 따라 cache 나 CDN 활용, p95, p99 개선을 포함해 훨씬 통계쪽에서도 많은 최적화를 보여줬고(주관적인 해석...), 그에 따라 daily 는 사이드프로젝트가 저장하고 total 만 이용하는 방식으로 해서 velog dashboard v2 를 기획했습니다.
1) 사용하기!
https://velog-dashboard.kro.kr/ 로 오셔서
access_token과refresh_token을 입력해주시면 모든 것이 끝입니다!!
-
혹시나 해당 값을 어디서 가져오지?! 라고 생각이 되신다면! https://youtu.be/Ab8c4kmGhQA (예전 버전 기준이긴 하지만 로직은 동일!) 영상을 통해서 1초만에 접근이 가능합니다!!
-
[1줄 요약] velog 접속 > 개발자 도구 > 애플리케이션 > 쿠키 > 토큰 확인

- 로그인 없이 테스트 계정도 있으니! 트라이트라이~
(1) UI 가 유려해졌습니다!!
- VD2 를 보고 이전 버전 급한 퍼블리싱 페이지가 얼마나 조악했는지 알 수 있었습니다 ㅎㅎ
- 왼쪽 nav bar 가 아니라 상단 핵심 메뉴 고정, 왼쪽 한 눈에 보는 통계, 세부 통계 아티클 섹션!
- 그리고 무한스크롤!!
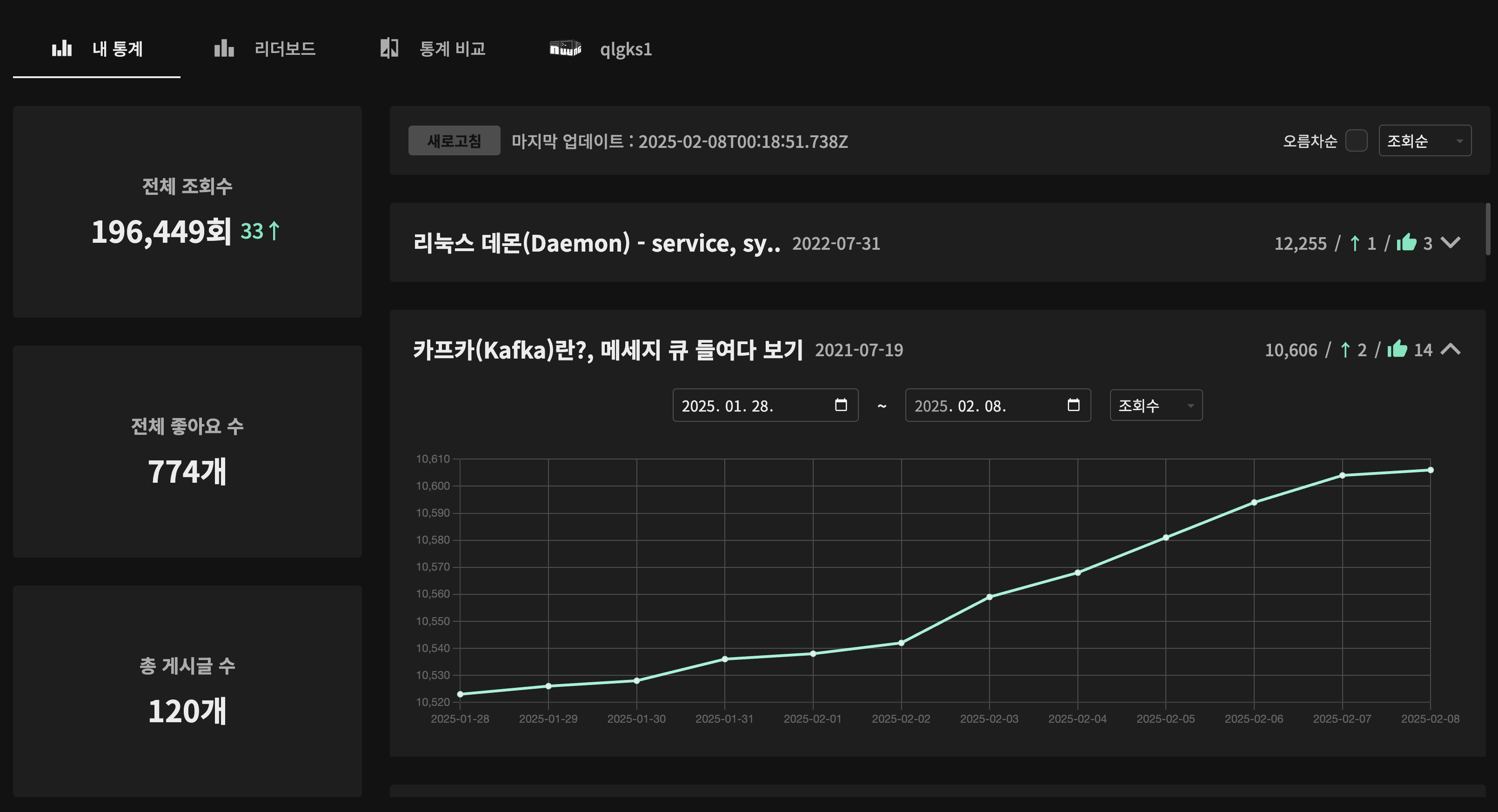
(2) UX 가 심플하고 빨라졌습니다!!
- 그냥 보자마자 설명없이 "익숙한 대로 사용 가능한" 형태에요!
- "날짜 구간 조회" 가 가능하고, 구간 조회 속도가 빨라요!! (Timescale DB 덕분에 ㅎㅎ)
(3) 혹시나 모를 오퍼레이션을 대비해 back-office가 생겼습니다!!
- django base 로 modeling 을 하고, 이를 바탕으로 back-office 를 구성했고, 물론 public 공개가 아니라 철저한 private 접근 입니다!
- 수동 배치는 admin action 을 통해 처리하려고 하고, 앞으로 internal 지표 분석을 위해서도 사용해 보려고 합니다 :)
(4) 30분당 업데이트가 유저수에 따라 흔들리지 않기 위해 분할되고 동시성 성격이 좋아졌습니다!
- 지금은 그룹을 3개로 크게 묶어뒀지만, 컴퓨팅 퍼포먼스만 있다면 1천개 "그룹"을 병렬로 돌릴 수 있게 고려를 미리 해뒀습니다!! (ps. 사용자는 1~1000 사이 그룹 랜덤 배정)
async def main() -> None:
"""3개의 동시성 작업으로 유저 그룹 처리"""
group_ranges = [
range(1, 334),
range(334, 667),
range(667, 1001),
]
scrapers = [Scraper(group_range) for group_range in group_ranges]
await asyncio.gather(*(scraper.run() for scraper in scrapers))- 물론 batch 를 최대한
stand-alone으로 가동 가능하게 했고, 지금의 최소 의존성은django만 있습니다!
2) 히스토리와 배포 인프라 소개!
-
velog dashboard 를 살려주세요..! (수정됨) 글을 통해 정말 감사히도 꽤 많은 분들이 관심 가져주셔서 해당 프로젝트를 action 할 수 있게 되었고, 제 목적과 취지에 맞게 최대한 0년차와 주니어 분들만으로 구성했습니다!
-
Product North Star 만 잡아두고 모든 기획과 과정, 기술 스택은 열어두고 정했고, 크게 3가지 덩어리로 구성되었습니다!!
-
호준 님이 back-office 메인을 담당해 주셨고, 하온 님이 api 를 메인 담당해주셨고, 마지막으로! 기준 님이 fe 를 메인 담당해 주셨습니다!!
-
저는 그냥 수저 세팅,, 잔반 리필,, 물 떨어지면 다시 떠오는 그런 느낌?.. 호준님, 하온님, 기준님 세 분이 너무 열심히 잘 만들어 주셨습니다!!
-
(상대적으로 최근은 유했지만) 초반에는 굉장히 치열한 P.R 과 code review rule 기반으로 저희 네명이 모든 P.R 에 대해 [ Bad thing & Good thing ] 기반으로 엄격하게 리뷰잉 했습니다!!
절대 LGTM 금지 -
그리고 호준님, 하온님, 기준님 velog page 를 가보시면 아시겠지만! 회고 역시 빡세게 했다는 점!!
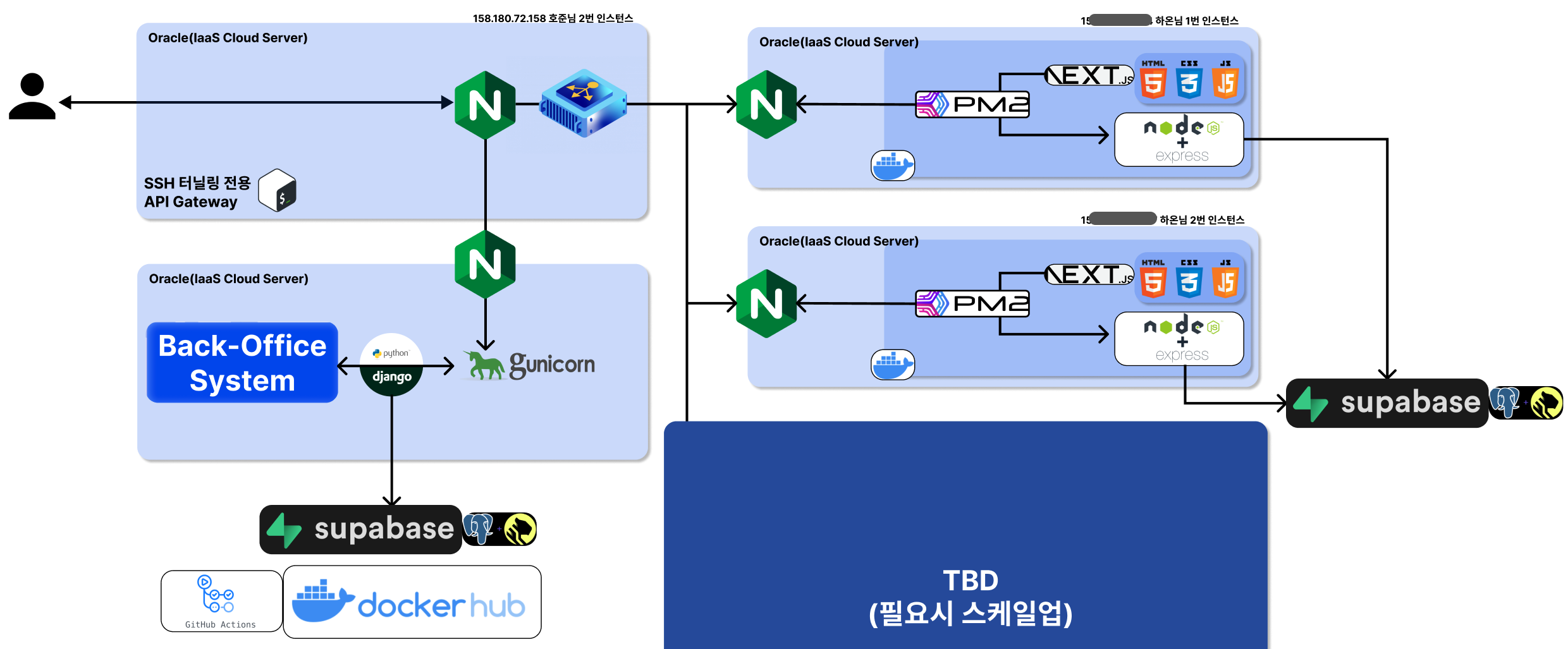
-
전체
infra의 심플한 개괄도는 위와 같아요! 전체적으로L7계층에서LB역할을 해주는 서버 하나, 그에 따라[ api + fe ]덩어리는 같이 도커라이징 된 형태로 서빙되고 있습니다! -
역시 사용자 분들의 token 은 저희가 handling 하는 DBMS 에 저장하지 않고, 양방향 암호화 되어서, 심지어 그룹마다 salt 값이 다른 형태로, 암호화된 값이 table 에 저장됩니다!
-
그리고 재미있는 부분이
supabase를 사용했는데Timescale-dbextension 을 제공하더라고요! 그래서 DBMS 는 우선적으로PaaS형태supabase선택! -
LB서버와Back-office를 제외하면 모든 부분이 scale-out/up 에 굉장히 유리하게 세팅되어 있습니다!라고 하지만 대부분이 실전에서 뚜드려 맞져ㅎㅎ -
추가로 "extension" 있는데 아직 구글 심사 중입니다... 구글아 빨리 내놓아라! 해당 익스텐션은 페이지 오지 않고, 바로 프로필 아래에, 아래 사진과 같이 한 눈 통계를 보여주는 feature 가 핵심입니다!
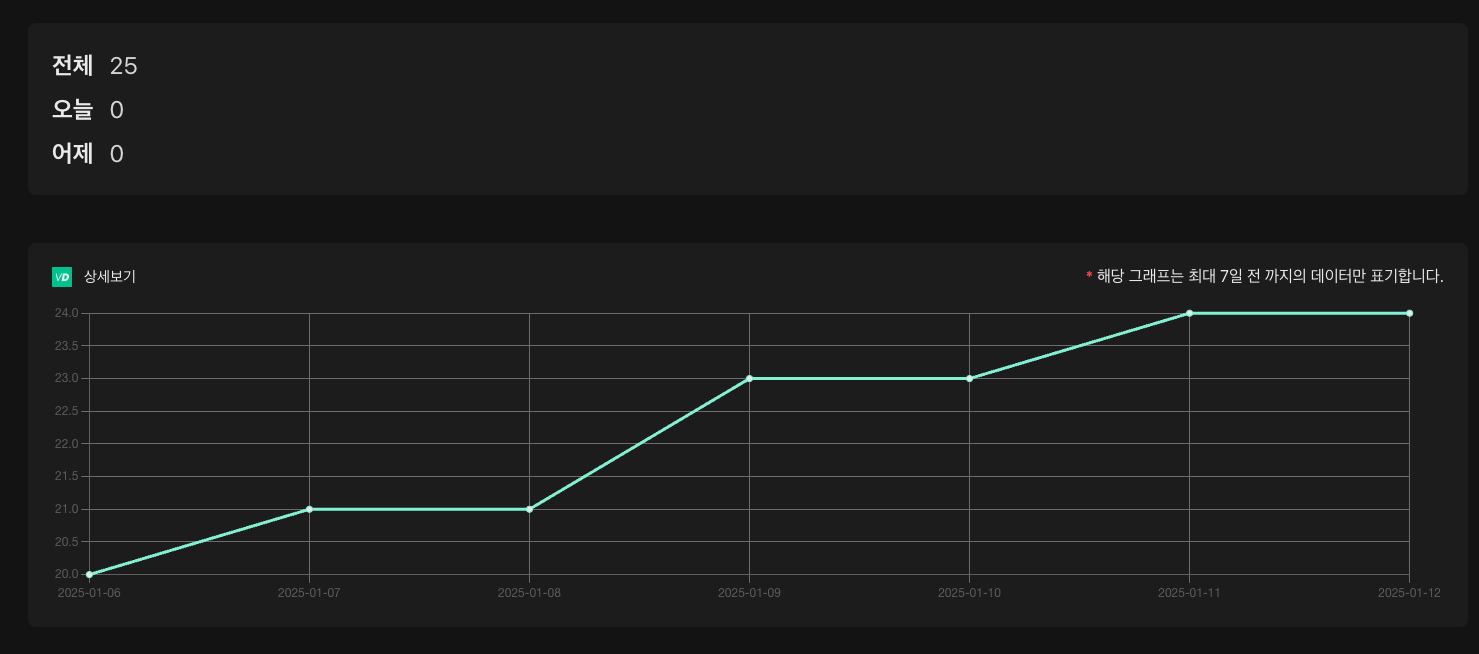
- 그리고 사라진 velog-daily 통계를 아래와 같이 대신 채워드리죠 ㅎㅎㅎ
2. 각 repo 체크
1) api repo
- 런타임: node v23+
- 패키지매니저:
pnpm - 핵심라이브러리 & 프레임워크:
typescript+express+class-transformer & validator - 계층 분리에 신경을 많이 썻고, layered architecture pattern "지향" 했습니다!
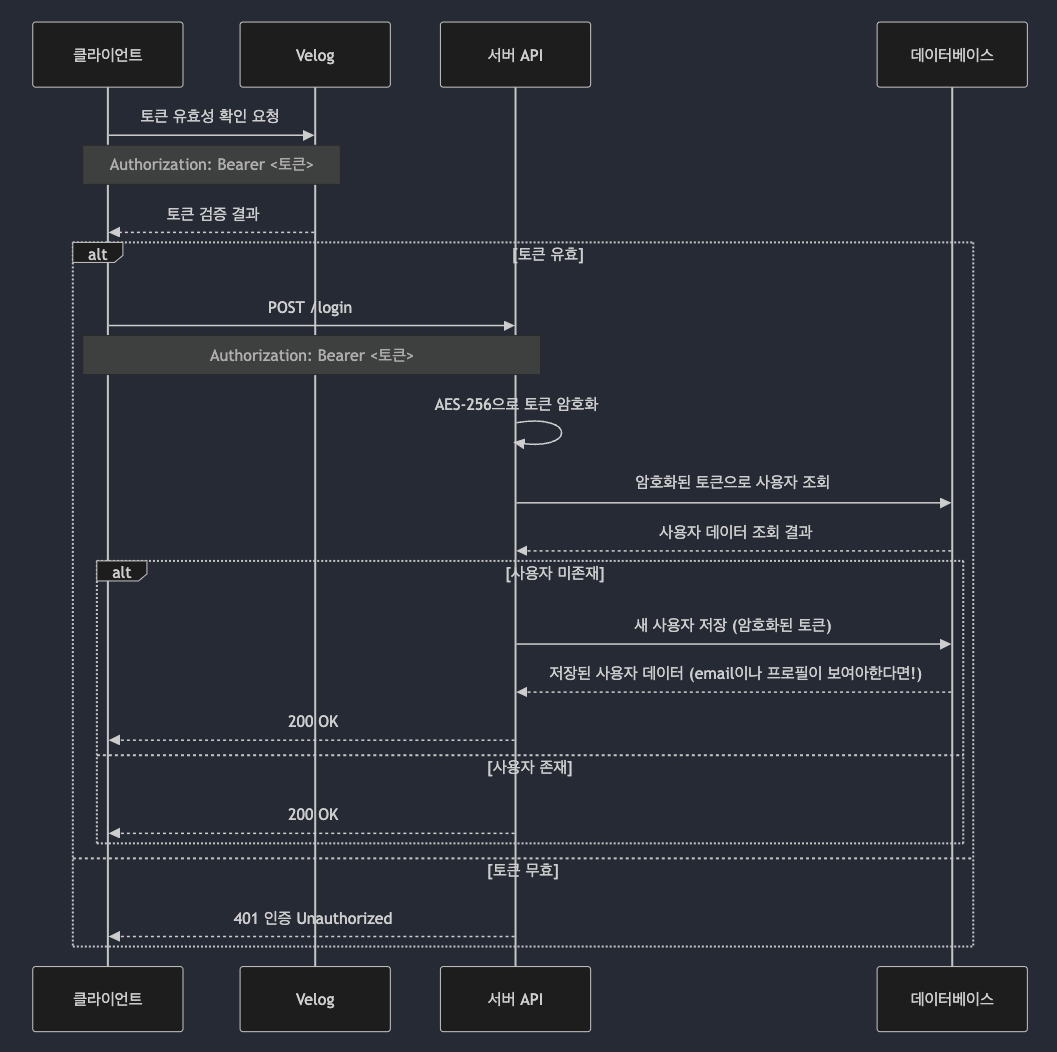
- 가장 신경을 많이 쓴 token 입력 후 검증과 회원가입 또는 로그인 로직!
이렇게 Flow Chart 또는 Sequence Diagram 을 먼저 만들고 작업하려고 합니다!!
2) fe repo
- 런타임: node v23+
- 패키지매니저:
pnpm - 핵심라이브러리 & 프레임워크:
typescript+nextjs+tanstack-query+tailwindcss - 확장 프로그램 프레임워크:
typescript+react+tanstack-query - SSR의 장점을 최대한 얻기 위해 노력하고 있으며, velog에서도 velog dashboard의 데이터를 사용할 수 있게 확장 프로그램을 개발 중에 있습니다!!
- rendering test case 를 MSW 도 활용하여 다양한 테스트 시나리오도 만들어보고, 리더보드 페이지와 통계 비교 페이지, 안정적이고 여러 케이스를 고려하는 테스트라는 과제가 남았습니다!

3) back-office repo
- 런타임: python v3.13+
- 패키지매니저:
poetry+pyenv - 핵심라이브러리 & 프레임워크:
django v5+,aiohttp,asyncio - ETC: 린팅은
ruff, 테스팅pytest,mypy도 사용! - 아래와 같이 비동기쪽 퀄리티와 안정성을 80% -> 99% 까지 높이기 위해 아직! 갈 길이 많이 남았습니다!

- 그리고 배치 성격을 가지는 task 처리, ops 기능을 위한 back-office feature 강화라는 큰 과제가 있습니다!!
- 핵심 배치 로직의 전체 flow 는 아래와 같습니다 :) (사실 자질구래한 부분이 더 있는데,, 이는,, 첫 flow 에 step 만 추가되는 느낌이라 시퀀스 다이어그램이 없다..!는!!)
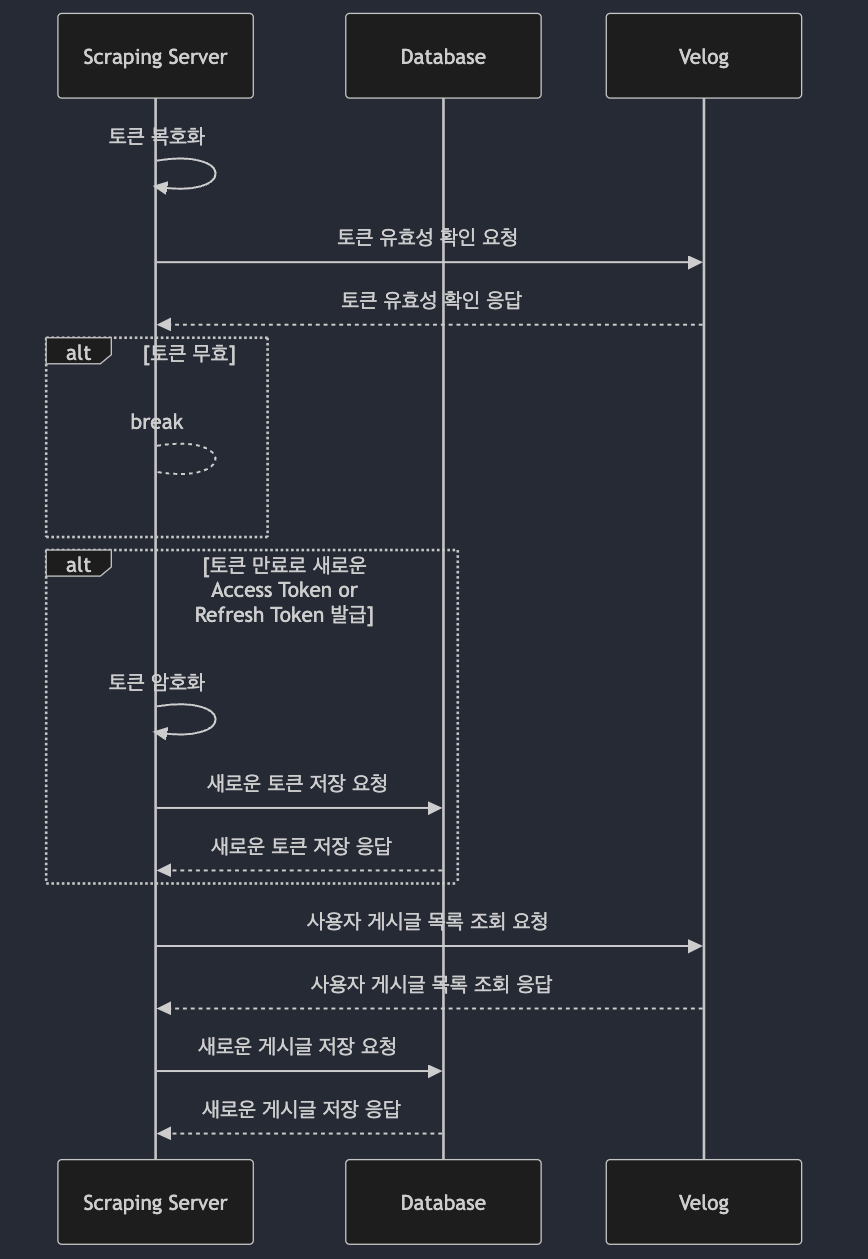
3. 배포, 운영 그 이후
1) 앞으로는,,
-
저도 아직 많이 부족하지만, 다양한 규모의 회사와 초기 스타트업에서
0 to 1을 경험하며,0 to 1뿐 아니라1 to 10또한 그에 준하게 정말 중요하다는걸 많이 느꼈습니다. -
특히
product side에서요! 본격적인 찐 개발은1 to 10에서 더 복합적으로 많이 이뤄지는 것을 느꼈고, 아주 재미있고 해결할게 많이 남아있습니다!!

-
당장 개발 생명주기에서 CI/CD 구성, Ops 기능들, 무중단 배포를 위한 blue-red 등, 이 서비스가 사용자가 많지 않아도 실무, 현업에서 필수로 갖춰야 하는 것들이 많이 기다리고 있을 것 같습니다!
-
사실 실제 운영 서비스라면 당연히
product중심 사고,비즈니스 중심으로 평가하고 측정해야겠지만, 사이드 프로젝트인 만큼 낭만있게 철저한 테크니컬 완성도 중심 사고 로 가져가고 싶습니다 ㅎ
2) 그래서, 구인!
- (이전에 있던 내용을 지우고 업데이트 한 부분 입니다.)
- 25.02.17 이후로 해당 구인 폼은 닫았습니다 :) 🙏🙏🙇🏻♂️


17개의 댓글





V.D v2 개발에 들인 노고에 진심으로 감사드립니다. 특히 세련된 UI와 빠른 UX로 일반적인 문제점들을 해결해 주신 점이 정말 좋았습니다. 예전에 Snow Rider 3D를 플레이했을 때가 생각나네요. 단순하면서도 매끄러운 게임플레이 덕분에 불필요한 복잡함 없이 즐거운 경험을 할 수 있었습니다. 마찬가지로, 이렇게 깔끔한 대시보드 덕분에 중요한 부분에 집중하기가 더 쉬워졌습니다. 앞으로도 좋은 작업 부탁드립니다. 프로젝트가 더욱 발전하는 모습을 기대하겠습니다!
(테스트 계정) 다들 전체 통계 체크해보세요!! :)