이번 시간에는 퀵 정렬에 대해 알아보겠다.
퀵 정렬 알고리즘의 개념 요약
-
‘찰스 앤터니 리처드 호어(Charles Antony Richard Hoare)’가 개발한 정렬 알고리즘
-
퀵 정렬은 불안정 정렬 에 속하며, 다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬 에 속한다.
-
분할 정복 알고리즘의 하나로, 평균적으로 매우 빠른 수행 속도를 자랑하는 정렬 방법
- 합병 정렬(merge sort)과 달리 퀵 정렬은 리스트를 비균등하게 분할한다.
-
분할 정복(divide and conquer) 방법
- 문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략이다.
- 분할 정복 방법은 대개 순환 호출을 이용하여 구현한다.
과정 설명
-
리스트 안에 있는 한 요소를 선택한다. 이렇게 고른 원소를 피벗(pivot) 이라고 한다.
-
피벗을 기준으로 피벗보다 작은 요소들은 모두 피벗의 왼쪽으로 옮겨지고 피벗보다 큰 요소들은 모두 피벗의 오른쪽으로 옮겨진다. (피벗을 중심으로 왼쪽: 피벗보다 작은 요소들, 오른쪽: 피벗보다 큰 요소들)
-
피벗을 제외한 왼쪽 리스트와 오른쪽 리스트를 다시 정렬한다.
-
분할된 부분 리스트에 대하여 순환 호출 을 이용하여 정렬을 반복한다.
-
부분 리스트에서도 다시 피벗을 정하고 피벗을 기준으로 2개의 부분 리스트로 나누는 과정을 반복한다.
-
-
부분 리스트들이 더 이상 분할이 불가능할 때까지 반복한다.
- 리스트의 크기가 0이나 1이 될 때까지 반복한다.
- 리스트 안에 있는 한 요소를 선택한다. 이렇게 고른 원소를 pivot(피벗) 이라고 한다.
- pivot을 기준으로 pivot보다 작은 요소들은 모두 pivot의 왼쪽으로 옮기고 pivot보다 큰 요소들은 모두 pivot의 오른쪽으로 옮긴다.
- pivot을 제외한 왼쪽 리스트와 오른쪽 리스트를 다시 정렬한다.
3-1) 분할된 왼쪽 리스트와 오른쪽 리스트도 다시 pivot을 정하고 pivot을 기준으로 2개의 부분리스트로 나눈다.
3-2) 재귀를 사용하여 부분 리스트들이 더이상 분할이 불가능 할 때까지 반복한다.
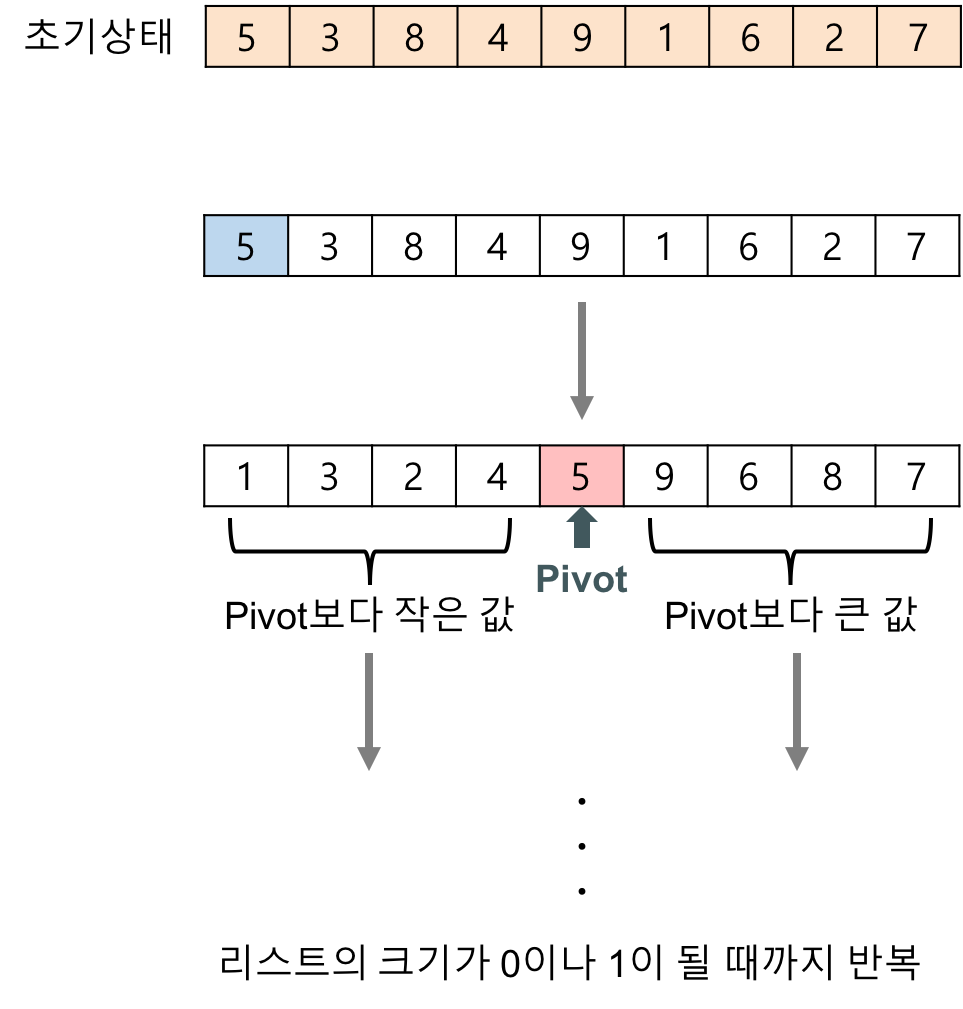
퀵 정렬(quick sort) 알고리즘의 구체적인 개념
- 하나의 리스트를 피벗(pivot)을 기준으로 두 개의 비균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법이다.
퀵 정렬은 다음의 단계들로 이루어진다.
-
분할(Divide): 입력 배열을 피벗을 기준으로 비균등하게 2개의 부분 배열(피벗을 중심으로 왼쪽: 피벗보다 작은 요소들, 오른쪽: 피벗보다 큰 요소들)로 분할한다.
-
정복(Conquer): 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출 을 이용하여 다시 분할 정복 방법을 적용한다.
-
결합(Combine): 정렬된 부분 배열들을 하나의 배열에 합병한다.
-
순환 호출이 한번 진행될 때마다 최소한 하나의 원소(피벗)는 최종적으로 위치가 정해지므로, 이 알고리즘은 반드시 끝난다

퀵 정렬(quick sort) 알고리즘의 예제
배열에 5, 3, 8, 4, 9, 1, 6, 2, 7이 저장되어 있다고 가정하고 자료를 오름차순으로 정렬해 보자.
퀵 정렬에서 피벗을 기준으로 두 개의 리스트로 나누는 과정(c언어 코드의 partition 함수의 내용)
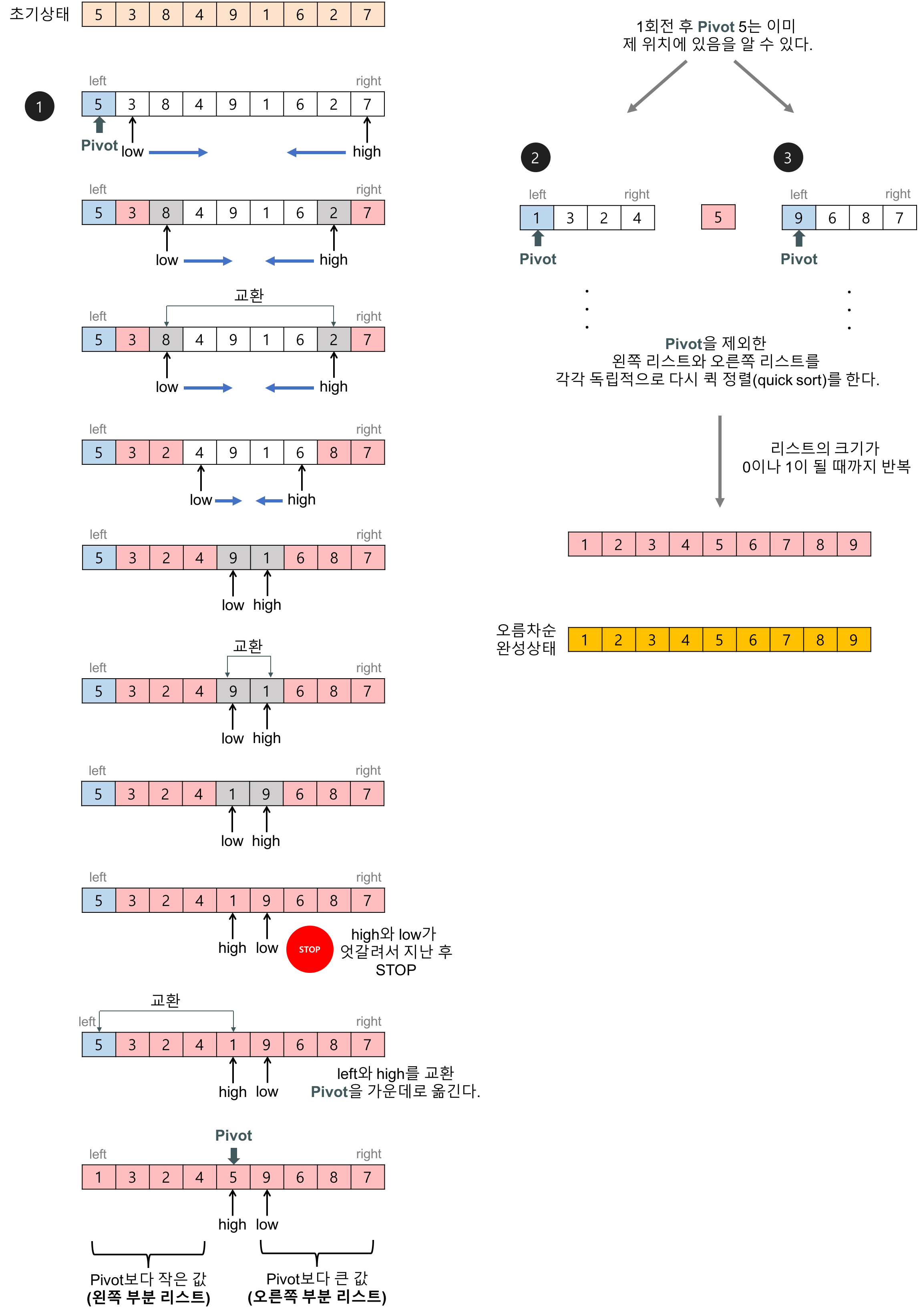
-
피벗 값을 입력 리스트의 첫 번째 데이터로 하자. (다른 임의의 값이어도 상관없다.)
-
2개의 인덱스 변수(low, high)를 이용해서 리스트를 두 개의 부분 리스트로 나눈다.
-
1회전: 피벗이 5인 경우,
- low는 왼쪽에서 오른쪽으로 탐색해가다가 피벗보다 큰 데이터(8)을 찾으면 멈춘다.
- high는 오른쪽에서 왼쪽으로 탐색해가다가 피벗보다 작은 데이터(2)를 찾으면 멈춘다.
- low와 high가 가리키는 두 데이터를 서로 교환한다.
이 탐색-교환 과정은 low와 high가 엇갈릴 때까지 반복한다.
-
2회전: 피벗(1회전의 왼쪽 부분리스트의 첫 번째 데이터)이 1인 경우,
- 위와 동일한 방법으로 반복한다.
-
3회전: 피벗(1회전의 오른쪽 부분리스트의 첫 번째 데이터)이 9인 경우,
- 위와 동일한 방법으로 반복한다.
[코드]
#include <stdio.h>
int number = 10;
int data[10] = { 1, 10, 5, 8, 7 ,6 ,4 ,3, 2 ,9 };
void quickSort(int* data, int start, int end)
{
if (start >= end)
{//원소가 하나인 경우
return;
}
int key = start; // 키는 첫번째 원소
int i = start + 1;
int j = end;
int temp; //값을 바꾸기 위해 임시 변수 선언
while (i <= j) //엇갈릴때까지 반복한다. 왼쪽에서 출발한 것이 오른쪽에서 출발한 것보다 더 작을 경우에
{//엇갈리게 되면 이 부분을 탈출한다. // 엇갈리지 않을 때 까지 반복
while (data[i] <= data[key]) // 키 값보다 큰 값을 만날때 까지 오른쪽으로 이동
{
i++;
}
while (data[j] >= data[key] && j > start)//키 값보다 작은 값을 만날때까지 반복
{
// j > start를 넣는 이유는 1보다 작은 값을 고른다고 해보자. 9부터 출발했을때 있는가?
// start까지만 갈 수 있게끔 걸어주는 것.
//오른쪽에는 왜 안걸어줌? // 키 값을 교체하기 때문에 설정하지 않았다.
j--;
}
if (i > j) //엇갈렸다면 key값을 교체 end와 key값을 교체
{
temp = data[j];
data[j] = data[key];
data[key] = temp;
}
else //엇갈리지 않았다면 큰 값과 작은값을 change
{
temp = data[j];
data[j] = data[i];
data[i] = temp;
}
}
quickSort(data, start, j - 1);
quickSort(data, j + 1, end);
}
int main()
{
quickSort(data, 0, number - 1);
for (int i = 0; i < number; i++)
{
printf("%d", data[i]);
}
}
//퀵 정렬은 정렬 part중에 중요한 부분이다.
// 이론
// 1단계
// 3 7 8 1 5 9 6 10 2 4이 있다고 가정하자.
// 처음에 피벗 값은 3이 된다.[초기 값]
// 3을 기준으로 큰 값을 탐색하고
// 4를 기준으로 3보다 작은 값을 탐색한다.
// 3 -> 7이 탐색되고 | 2가 바로 탐색됐다.
// 7과 2 자리를 change 한다.
// 3 2 8 1 5 9 6 10 7 4
// 2단계
// 3 -> 8이 탐색됐고 | 1이 탐색됐다.
// 3 2 1 8 5 9 6 10 7 4 가 나왔다.
// 여기서 다시 탐색하게 된다면 3 -> 2 -> 1 -> 8 || 4에서 1까지 탐색된다. 즉 엇갈린다.
// 이럴 땐 pivot값과 값을 교체한다.
// 1 2 3 8 5 9 6 10 7 4
//3단계
// 3를 기준으로 1 2는 정렬 되어 있고 8를 기준으로 정렬한다.
// 이 또한 2단계 매커니즘을 그대로 응용한다.
//4단계
1 2 3 8 5 9 6 10 7 4
->8보다 큰 값인 9와 8보다 작은 값 4를 바꿔준다. 8보다 큰 값 10과 작은 값 7를 바꾸어준다.
->1 2 3 8 5 4 6 10 7 9
->1 2 3 8 5 4 6 7 10 9
10과 7이 엊갈려서 왼쪽 8과 바뀐다.
1 2 3 7 5 4 6 8 10 9
1 2 3 7 5 4 6 8 10 9
7은 작은 것을 고른다. -> 6 6&7change
1 2 3 6 5 4 7 8 10 9 ==> 그 값을 기준으로 왼쪽과 오른쪽이 나뉘어진다.
//구현 두 가지로 나눌 수 있다.
// 포인트는 엇갈리는 것을 어떻게 코드로 표현 할 것인가? 이다.
// 3을 start 로 설정하고 4를 end로 설정하자.
// 총 3가지의 변수가 필요하다
//[변수 설명] key[pivot] = start | j = end | i = start + 1
// while(i <= j) // 엇갈리지 않을 때 까지 큰 반복문 설정
// 1.
// 3부터 -> 이 방향으로 탐색하는 조건 3보다 큰 값을 찾아야 한다! 이것은 탈출조건이고
// 반복조건으로 다시 얘기한다면,
// while( data[i] <= data[key])
// i++
// 2.
// while(data[i] >= data[key] && j > start)
// j--;
// 3. 엇갈린다면 if( i > j)
// -> swap 진행
// -> temp = data[j] 1 //작은 값을 temp에 담는다.
// -> data[j] 1 = data[key] 3 // 기존에 있던 끝 값을 -> key에 넣는다. 즉 정렬했을 때 작은 값
// -> data[key] = temp 1
//3 2 1 8 5 9 6 10 7 4
//-> 여기서 다시 큰 값과 작은 값을 찾는 과정을 살펴보면
//-> 8 | 1이다. ->8과 1은 엊갈렸다.즉 작은 값의 인덱스가 큰 값의 인덱스보다 더 작은 것.
//4.
// 그게 아니라면 두 변수만 교환을 진행한다.
// temp = data[j];
// data[j] = data[i];
// data[i] = temp
//5.
// 마지막 재귀함수로 정렬을 한다.
// quickSort(data, start, j - 1); 7 5 4 6 | 8까지 j-1
// quickSort(data, j + 1, end); 8 -> 10 9 자리조정
// 1 2 3 7 5 4 6 8 10 9
퀵 정렬(quick sort) 알고리즘의 특징
장점
-
속도가 빠르다.
-
시간 복잡도가 O(nlog₂n)를 가지는 다른 정렬 알고리즘과 비교했을 때도 가장 빠르다.
-
추가 메모리 공간을 필요로 하지 않는다.
-
퀵 정렬은 O(log n)만큼의 메모리를 필요로 한다.
단점
-
정렬된 리스트에 대해서는 퀵 정렬의 불균형 분할에 의해 오히려 수행시간이 더 많이 걸린다.
-
정렬의 불균형 분할을 방지하기 위하여 피벗을 선택할 때 더욱 리스트를 균등하게 분할할 수 있는 데이터를 선택한다.
EX) 리스트 내의 몇 개의 데이터 중에서 크기순으로 중간 값(medium)을 피벗으로 선택한다.
퀵정렬의 시간복잡도
최선의 경우
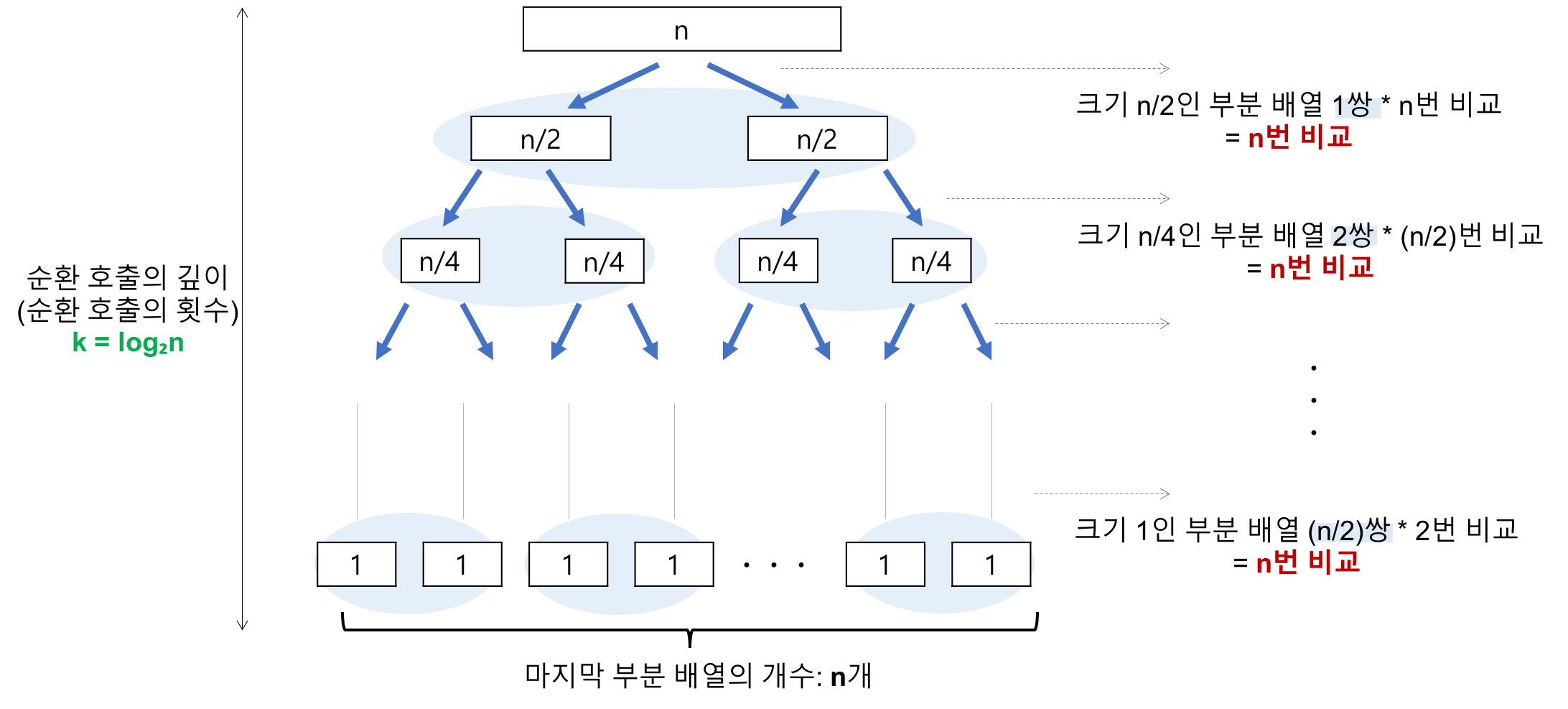
순환 호출의 깊이
레코드의 개수 n이 2의 거듭제곱이라고 가정(n=2^k)했을 때, n=2^3의 경우, 2^3 -> 2^2 -> 2^1 -> 2^0 순으로 줄어들어 순환 호출의 깊이가 3임을 알 수 있다. 이것을 일반화하면 n=2^k의 경우, k(k=log₂n)임을 알 수 있다.
k=log₂n
각 순환 호출 단계의 비교 연산
각 순환 호출에서는 전체 리스트의 대부분의 레코드를 비교해야 하므로 평균 n번 정도의 비교가 이루어진다.
평균 n번
순환 호출의 깊이 * 각 순환 호출 단계의 비교 연산 = nlog₂n
이동 횟수
비교 횟수보다 적으므로 무시할 수 있다.
최선의 경우 T(n) = O(nlog₂n)
최악의 경우
리스트가 계속 불균형하게 나누어지는 경우 (특히, 이미 정렬된 리스트에 대하여 퀵 정렬을 실행하는 경우)
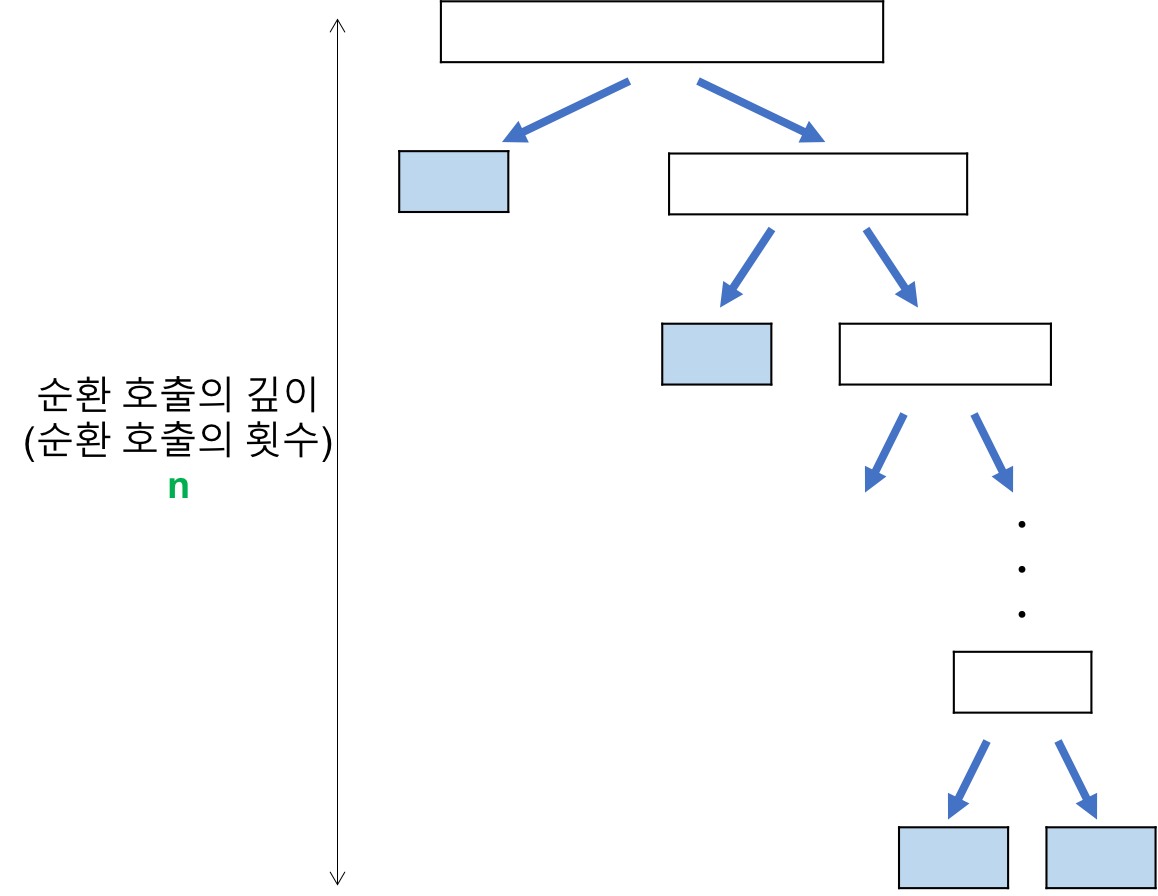
비교 횟수
순환 호출의 깊이
- 레코드의 개수 n이 2의 거듭제곱이라고 가정(n=2^k)했을 때, 순환 호출의 깊이는 n임을 알 수 있다.
- n
각 순환 호출 단계의 비교 연산
-
각 순환 호출에서는 전체 리스트의 대부분의 레코드를 비교해야 하므로 평균 n번 정도의 비교가 이루어진다.
-
평균 n번
-
순환 호출의 깊이 * 각 순환 호출 단계의 비교 연산 = n^2
이동 횟수
- 비교 횟수보다 적으므로 무시할 수 있다.
- 최악의 경우 T(n) = O(n^2)
평균
-
평균 T(n) = O(nlog₂n)
-
시간 복잡도가 O(nlog₂n)를 가지는 다른 정렬 알고리즘과 비교했을 때도 가장 빠르다.
-
퀵정렬이 불필요한 데이터의 이동을 줄이고 먼 거리의 데이터를 교환할 뿐만 아니라, 한 번 결정된 피벗들이 추후 연산에서 제외되는 특성 때문이다
출처 | https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html
